BP神经网络预测(python)
可以参考新发布的文章
1.mlp多层感知机预测(python)
2.lstm时间序列预测+GRU(python)
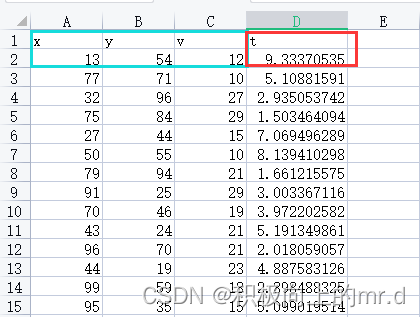
下边是基于Python的简单的BP神经网络预测,多输入单输出,也可以改成多输入多输出,下边是我的数据,蓝色部分预测红色(x,y,v为自变量,z为因变量)
数据集下载
话不多说,直接上代码
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import BPNN
from sklearn import metrics
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
#导入必要的库
df1=pd.read_excel('2000.xls',0)
df1=df1.iloc[:,:]
#进行数据归一化
from sklearn import preprocessing
min_max_scaler = preprocessing.MinMaxScaler()
df0=min_max_scaler.fit_transform(df1)
df = pd.DataFrame(df0, columns=df1.columns)
x=df.iloc[:,:-1]
y=df.iloc[:,-1]
#划分训练集测试集
cut=300#取最后cut=30天为测试集
x_train, x_test=x.iloc[:-cut],x.iloc[-cut:]#列表的切片操作,X.iloc[0:2400,0:7]即为1-2400行,1-7列
y_train, y_test=y.iloc[:-cut],y.iloc[-cut:]
x_train, x_test=x_train.values, x_test.values
y_train, y_test=y_train.values, y_test.values
#神经网络搭建
bp1 = BPNN.BPNNRegression([3, 16, 1])
train_data = [[sx.reshape(3,1), sy.reshape(1,1)] for sx, sy in zip(x_train, y_train)]
test_data = [np.reshape(sx, (3,1)) for sx in x_test]
#神经网络训练
bp1.MSGD(train_data, 60000, len(train_data), 0.2)
#神经网络预测
y_predict=bp1.predict(test_data)
y_pre = np.array(y_predict) # 列表转数组
y_pre=y_pre.reshape(300,1)
y_pre=y_pre[:,0]
#画图 #展示在测试集上的表现
draw=pd.concat([pd.DataFrame(y_test),pd.DataFrame(y_pre)],axis=1);
draw.iloc[:,0].plot(figsize=(12,6))
draw.iloc[:,1].plot(figsize=(12,6))
plt.legend(('real', 'predict'),loc='upper right',fontsize='15')
plt.title("Test Data",fontsize='30') #添加标题
#输出精度指标
print('测试集上的MAE/MSE')
print(mean_absolute_error(y_pre, y_test))
print(mean_squared_error(y_pre, y_test) )
mape = np.mean(np.abs((y_pre-y_test)/(y_test)))*100
print('=============mape==============')
print(mape,'%')
# 画出真实数据和预测数据的对比曲线图
print("R2 = ",metrics.r2_score(y_test, y_pre)) # R2
下边是神经网络内部结构,文件名命名为 BPNN.py
# encoding:utf-8
'''
BP神经网络Python实现
'''
import random
import numpy as np
def sigmoid(x):
'''
激活函数
'''
return 1.0 / (1.0 + np.exp(-x))
def sigmoid_prime(x):
return sigmoid(x) * (1 - sigmoid(x))
class BPNNRegression:
'''
神经网络回归与分类的差别在于:
1. 输出层不需要再经过激活函数
2. 输出层的 w 和 b 更新量计算相应更改
'''
def __init__(self, sizes):
# 神经网络结构
self.num_layers = len(sizes)
self.sizes = sizes
# 初始化偏差,除输入层外, 其它每层每个节点都生成一个 biase 值(0-1)
self.biases = [np.random.randn(n, 1) for n in sizes[1:]]
# 随机生成每条神经元连接的 weight 值(0-1)
self.weights = [np.random.randn(r, c)
for c, r in zip(sizes[:-1], sizes[1:])]
def feed_forward(self, a):
'''
前向传输计算输出神经元的值
'''
for i, b, w in zip(range(len(self.biases)), self.biases, self.weights):
# 输出神经元不需要经过激励函数
if i == len(self.biases) - 1:
a = np.dot(w, a) + b
break
a = sigmoid(np.dot(w, a) + b)
return a
def MSGD(self, training_data, epochs, mini_batch_size, eta, error = 0.01):
'''
小批量随机梯度下降法
'''
n = len(training_data)
for j in range(epochs):
# 随机打乱训练集顺序
random.shuffle(training_data)
# 根据小样本大小划分子训练集集合
mini_batchs = [training_data[k:k+mini_batch_size]
for k in range(0, n, mini_batch_size)]
# 利用每一个小样本训练集更新 w 和 b
for mini_batch in mini_batchs:
self.updata_WB_by_mini_batch(mini_batch, eta)
#迭代一次后结果
err_epoch = self.evaluate(training_data)
print("Epoch {0} Error {1}".format(j, err_epoch))
if err_epoch < error:
break
# if test_data:
# print("Epoch {0}: {1} / {2}".format(j, self.evaluate(test_data), n_test))
# else:
# print("Epoch {0}".format(j))
return err_epoch
def updata_WB_by_mini_batch(self, mini_batch, eta):
'''
利用小样本训练集更新 w 和 b
mini_batch: 小样本训练集
eta: 学习率
'''
# 创建存储迭代小样本得到的 b 和 w 偏导数空矩阵,大小与 biases 和 weights 一致,初始值为 0
batch_par_b = [np.zeros(b.shape) for b in self.biases]
batch_par_w = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch:
# 根据小样本中每个样本的输入 x, 输出 y, 计算 w 和 b 的偏导
delta_b, delta_w = self.back_propagation(x, y)
# 累加偏导 delta_b, delta_w
batch_par_b = [bb + dbb for bb, dbb in zip(batch_par_b, delta_b)]
batch_par_w = [bw + dbw for bw, dbw in zip(batch_par_w, delta_w)]
# 根据累加的偏导值 delta_b, delta_w 更新 b, w
# 由于用了小样本,因此 eta 需除以小样本长度
self.weights = [w - (eta / len(mini_batch)) * dw
for w, dw in zip(self.weights, batch_par_w)]
self.biases = [b - (eta / len(mini_batch)) * db
for b, db in zip(self.biases, batch_par_b)]
def back_propagation(self, x, y):
'''
利用误差后向传播算法对每个样本求解其 w 和 b 的更新量
x: 输入神经元,行向量
y: 输出神经元,行向量
'''
delta_b = [np.zeros(b.shape) for b in self.biases]
delta_w = [np.zeros(w.shape) for w in self.weights]
# 前向传播,求得输出神经元的值
a = x # 神经元输出值
# 存储每个神经元输出
activations = [x]
# 存储经过 sigmoid 函数计算的神经元的输入值,输入神经元除外
zs = []
for b, w in zip(self.biases, self.weights):
z = np.dot(w, a) + b
zs.append(z)
a = sigmoid(z) # 输出神经元
activations.append(a)
#-------------
activations[-1] = zs[-1] # 更改神经元输出结果
#-------------
# 求解输出层δ
# 与分类问题不同,Delta计算不需要乘以神经元输入的倒数
#delta = self.cost_function(activations[-1], y) * sigmoid_prime(zs[-1])
delta = self.cost_function(activations[-1], y) #更改后
#-------------
delta_b[-1] = delta
delta_w[-1] = np.dot(delta, activations[-2].T)
for lev in range(2, self.num_layers):
# 从倒数第1层开始更新,因此需要采用-lev
# 利用 lev + 1 层的 δ 计算 l 层的 δ
z = zs[-lev]
zp = sigmoid_prime(z)
delta = np.dot(self.weights[-lev+1].T, delta) * zp
delta_b[-lev] = delta
delta_w[-lev] = np.dot(delta, activations[-lev-1].T)
return (delta_b, delta_w)
def evaluate(self, train_data):
test_result = [[self.feed_forward(x), y]
for x, y in train_data]
return np.sum([0.5 * (x - y) ** 2 for (x, y) in test_result])
def predict(self, test_input):
test_result = [self.feed_forward(x)
for x in test_input]
return test_result
def cost_function(self, output_a, y):
'''
损失函数
'''
return (output_a - y)
pass
下边是我训练10000次得出的结果图
Mape=3.8747546777023055 %
R2 = 0.9892761559285088

接下来会出用LSTM,MLP以及GRU预测的代码,整理一下后续会发出来