【Keras图像分类】搭建卷积神经网络(CNN)和使用迁移学习(Transfer Learning)实现图片识别
1. 摘要
图像分类,也可以称作图像识别,顾名思义,就是辨别图像中的物体属于什么类别。核心是从给定的分类集合中给图像分配一个标签的任务。实际上,这意味着我们的任务是分析一个输入图像并返回一个将图像分类的标签。在这里,我们将分别自己搭建卷积神经网路、迁移学习分别对图像数据集进行分类。本篇使用的数据集下载地址为:
链接:https://pan.baidu.com/s/1soJXb2_UJKeHYT0mpec2Fw
提取码:rm3c
![]()
datasets文件夹底下包括两个文件夹存放各自的图片数据集。

2.搭建卷积神经网络实现图像分类
卷积神经网络与普通的神经网络的区别在于,卷积神经网络包含了一个卷积层convolutional layer和池化层pooling layer构成的特征提取器。卷积神经网路中每层卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法优化得到的。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网络能从低级特征中迭代提取更复杂的特征。池化层(Pooling layer),通常在卷积层之后会得到维度很大的特征,将特征切成几个区域,取其最大值或平均值,得到新的、维度较小的特征。
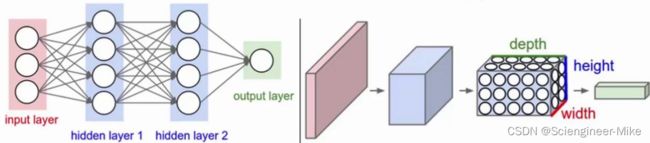
如上图左,全连接神经网络是一个“平面”,包括输入层—激活函数—全连接层,右图的卷积神经网络是一个“立体”,包括输入层—卷积层—激活函数—池化层—全连接层。卷积神经网络提取的数据量更大,因此常用在图像处理上。
接下来,我们自己搭建神经网络对上面同样的数据集进行分类
- 首先,导入相应的包
import numpy as np
from glob import glob
from keras.preprocessing import image
from sklearn.model_selection import train_test_split
from keras.utils import np_utils
from keras.layers import Conv2D,MaxPooling2D,Dense,Flatten,Dropout,GlobalAveragePooling2D
from keras.models import Sequential
from keras.callbacks import ModelCheckpoint
- 定义两类图片的标签值
y_baseji = np.zeros([209,],dtype=int)
y_pug = np.ones([200,],dtype=int)
y_data = list(y_baseji) + list(y_pug)
y_data = np.array(y_data)
y_data = np_utils.to_categorical([y_data],2).reshape(409,2)
y_data.shape
- 合并数据集X-data,方便后续处理
X_data_basenji =glob("./datasets/basenji/*")
X_data_pug = glob("./datasets/pug/*")
X_data = np.array(X_data_basenji + X_data_pug)
- 划分训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(X_data,y_data,test_size=0.25,random_state=0)
count = int(len(X_test)/2)
X_val = X_test[count:]
y_val = y_test[count:]
X_test = X_test[:count]
y_test = y_test[:count]
- 将图片路径转换为数组并且归一化,方便后须放入卷积神经网络里面
# 将图片路径转换为神经网路所需要的输入shape
def path_to_tensor(path):
img = image.load_img(path,target_size=(224,224,3))# 此处的img为PIL格式
picture = image.img_to_array(img) # picture转换成数组形式
return np.expand_dims(picture,axis=0)
def paths_to_tensor(paths):
list_of_tensors = [path_to_tensor(path) for path in paths]
return np.vstack(list_of_tensors)
Xtrain = paths_to_tensor(X_train).astype(np.float32)/255
Xtest = paths_to_tensor(X_test).astype(np.float32)/255
Xval = paths_to_tensor(X_val).astype(np.float32)/255
- 搭建卷积神经网络
model_recognition = Sequential()
model_recognition.add(Conv2D(filters=16,kernel_size=(2,2),strides=(1,1),padding="same",activation="relu",input_shape=(224,224,3)))
model_recognition.add(MaxPooling2D(pool_size=(2,2)))
model_recognition.add(Dropout(0.2))
model_recognition.add(Conv2D(filters=32,kernel_size=(2,2),strides=(1,1),padding="same",activation="relu"))
model_recognition.add(MaxPooling2D(pool_size=(2,2)))
model_recognition.add(Dropout(0.2))
model_recognition.add(Conv2D(filters=64, kernel_size=(2, 2), strides=(1, 1), padding='same', activation='relu'))
model_recognition.add(MaxPooling2D(pool_size=(2, 2)))
model_recognition.add(Dropout(0.2))
model_recognition.add(GlobalAveragePooling2D())
model_recognition.add(Dropout(0.5))
model_recognition.add(Dense(2,activation="softmax"))
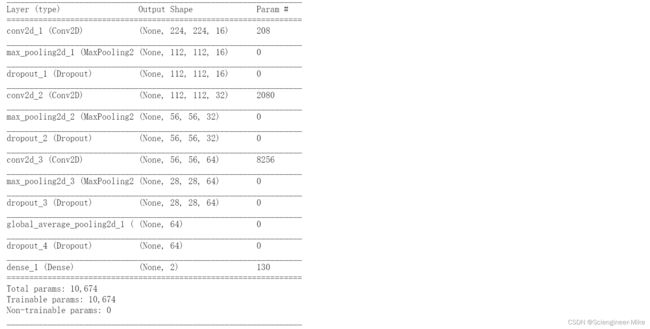
model_recognition.summary()
- 编译并训练网络
model_recognition.compile(optimizer="adam",loss="categorical_crossentropy",metrics=["accuracy"])
modelcheckpoint = ModelCheckpoint(filepath="mp.h5",verbose=1,save_best_only=True)
model_recognition.fit(Xtrain,y_train,epochs=30,validation_data=(Xval,y_val),batch_size=32,callbacks=[modelcheckpoint],verbose=1)

- 加载模型,测试训练集上的精确度
model_recognition.load_weights("mp.h5")
score = model_recognition.evaluate(Xtest, y_test, verbose=1)
print("Test {}: {:.2f}. Test {}: {:.2f}.".format(model_recognition.metrics_names[0],
score[0]*100,
model_recognition.metrics_names[1],
score[1]*100))
![]()
9. 离线情况下,进行图片分类,如下:
from keras.models import load_model
# 加载模型
model = load_model('mp.h5')
# 加载一张病理图像来测试模型精确度
test_img_path = X_test[22]
# 将图像转换成4维的NumPy数值数组
image_tensor = path_to_tensor(test_img_path)
# 归一化 转换成0到1之间的数值
image_tensor = image_tensor.astype(np.float32) / 255
# 模型预测概率
predicted_result = model.predict(image_tensor)
# 打印输出概率
print(predicted_result)
![]()
y_test[22]
![]()
3.迁移学习实现图像分类
问题来了?什么是迁移学习?迁移学习(Transfer learning) 顾名思义就是把已训练好的模型(预训练模型)参数迁移到新的模型来帮助新模型训练。考虑到大部分数据或任务都是存在相关性的,所以通过迁移学习我们可以将已经学到的模型参数(也可理解为模型学到的知识)通过某种方式来分享给新模型从而加快并优化模型的学习效率不用像大多数网络那样从零学习。其中,实现迁移学习有以下三种手段:
1.Transfer Learning:冻结预训练模型的全部卷积层,只训练自己定制的全连接层。
2.Extract Feature Vector:先计算出预训练模型的卷积层对所有训练和测试数据的特征向量,然后抛开预训练模型,只训练自己定制的简配版全连接网络。
3.Fine-tuning:冻结预训练模型的部分卷积层(通常是靠近输入的多数卷积层,因为这些层保留了大量底层信息)甚至不冻结任何网络层,训练剩下的卷积层(通常是靠近输出的部分卷积层)和全连接层。
预训练模型有很多,本文选用InceptionV3预训练模型,它是由谷歌团队从ImageNet的1000个类别的超大数据集训练而来的,表现优异,经常用来做计算机视觉方面的迁移学习研究和应用。
- 首先导入需要的包
from keras.applications.inception_v3 import InceptionV3,preprocess_input,decode_predictions
from keras.models import Model
from keras.layers import Dense,GlobalAveragePooling2D,Dropout
from keras.preprocessing import image
from keras.optimizers import SGD
from keras.callbacks import ModelCheckpoint
#导入图片数据增强器
from keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
- 定义一个类,用来训练微调后的InceptionV3模型,包括数据增强、自己定义全连接层、冻结预训练模型进行训练以及微调模型进行训练。
class InceptionV3Retrained:
#添加全连接层
def add_new_last_layers(self,base_model,num_classes):
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(1024,activation="relu")(x)
predictions = Dense(num_classes,activation="softmax")(x)
model = Model(input=base_model.input,output=predictions)
return model
# 冻结预训练模型之前的层
def freeze_previous_layers(self,model,base_model):
for layer in base_model.layers:
layer.trainable = False
model.compile(optimizer='adam',loss="categorical_crossentropy",metrics=['accuracy'])
#微调模型
def fine_tune_model(self,model):
for layer in model.layers[:172]:
layer.trainable = False
for layer in model.layers[172:]:
layer.trainable = True
model.compile(optimizer="adam",loss="categorical_crossentropy",metrics=["accuracy"])
#绘制损失值与精确值
def plot_training(self,history):
acc = history.history["acc"]
val_acc = history.history["val_acc"]
loss = history.history["loss"]
val_loss = history.history["val_loss"]
epochs = range(len(acc))
plt.plot(epochs, acc, 'r.')
plt.plot(epochs, val_acc, 'r')
plt.title('Training and validation accuracy')
# 绘制训练损失和验证损失
plt.figure()
plt.plot(epochs, loss, 'r.')
plt.plot(epochs, val_loss, 'r-')
plt.title('Training and validation loss')
plt.show()
# 训练模型
def train(self,num_classes,batch_size,epochs):
# 数据增强
train_datagen = ImageDataGenerator(preprocessing_function=preprocess_input,rotation_range=20,width_shift_range=0.2,
height_shift_range=0.2,shear_range=0.2,zoom_range=0.2,horizontal_flip=True)
valid_datagen = ImageDataGenerator(preprocessing_function=preprocess_input,rotation_range=20,width_shift_range=0.2,
height_shift_range=0.2,shear_range=0.2,zoom_range=0.2,horizontal_flip=True)
train_generator = train_datagen.flow(Xtrain,y_train,batch_size=batch_size)
valid_generator = valid_datagen.flow(Xval,y_val,batch_size=batch_size)
# 初始化inceptionV3模型,include_top=False表示初始化模型时不包含InceptionV3网络结构层中的最后的全连接层
base_model = InceptionV3(weights="imagenet",include_top=False)
model = self.add_new_last_layers(base_model,num_classes)
self.freeze_previous_layers(model,base_model)
checkpointer = ModelCheckpoint(filepath="inception_new.h5",verbose=1,save_best_only=True)
print("开始训练")
history_tl = model.fit_generator(train_generator,steps_per_epoch=Xtrain.shape[0]/batch_size,
validation_steps=Xval.shape[0] / batch_size,
epochs=epochs,
verbose=1,
callbacks=[checkpointer],
validation_data=valid_generator)
# 微调模型
self.fine_tune_model(model)
print("微调模型后,再次训练模型")
history_ft = model.fit_generator(train_generator,
steps_per_epoch=Xtrain.shape[0] / batch_size,
validation_steps=Xval.shape[0] / batch_size,
epochs=epochs,
verbose=1,
callbacks=[checkpointer],
validation_data=valid_generator)
self.plot_training(history_ft)
- 对微调后的模型进行训练50次。
batch_size = 32
epochs = 50
num_classes = 2
incepV3_model = InceptionV3Retrained()
incepV3_model.train(num_classes=num_classes,batch_size=batch_size,epochs=epochs)

- 在测试集上,测试训练结果的精确度。
# 测试模型的精确度
# 创建一个不带全连接层的InceptionV3模型
test_model = InceptionV3(weights='imagenet', include_top=False, input_shape=Xtest.shape[1:])
# 添加全连接层输出层
incepV3_model = InceptionV3Retrained()
trained_model = incepV3_model.add_new_last_layers(test_model, num_classes)
# 加载刚才训练的权重到模型中
trained_model.load_weights("inception_new.h5")
# 编译模型
trained_model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
# 评估模型
score = trained_model.evaluate(Xtest, y_test, verbose=1)
print("Test {}: {:.2f}. Test {}: {:.2f}.".format(trained_model.metrics_names[0],
score[0]*100,
trained_model.metrics_names[1],
score[1]*100))
![]()
由以上结果可以看出,微调后的模型对于测试集上的精确度达到了96.08%,比你我们自己搭建的神经网络模型(78.43%)准确了很多,表现十分优秀。