Non-Sampling Learning for Personalized Recommendation——笔记
Non-Sampling Learning for Personalized Recommendation
[参考]
- 个性化推荐系统中的非采样学习-陈冲
- B站视频 https://www.bilibili.com/video/BV1Z64y1u7GK
- 现有的将深度学习应用大推荐系统任务的工作主要集中在探索和引入不同的神经网络架构,在模型学习算法方面的研究相对较少。
- 为了优化模型,现有的工作往往使用负采样策略(Negative Sampling)进行训练。虽然负采样方便并且易于实现,但是许多最近的研究表明负采样策略的鲁棒性较差,可能会忽略掉重要的训练样例从而导致模型无法收敛到最优的状态。
- 清华大学信息检索课题组(THUIR)首次探索了将**非采样策略(Non-Sampling, Whole-data based Learning)**应用到基于神经网络的推荐系统中。
- 通过严格的数学推理,设计了一系列高效的非采样学习算法,将从整体数据中学习的时间复杂度从理论上降低了数十倍。
- 基于所设计的高效非采样算法框架,分别设计了不同应用场景下的神经网络推荐模型,并在多个现实数据集上相比于已有state-of-the-art方法在训练时间和模型表现上均取得了非常显著的效果。
填补了非采样神经网络推荐模型研究的空白
Outline
-
- background
-
- Negative-Sampling VS Non-Sampling Learning
-
- Efficient Non-Sampling Learning Method
-
- Recommendation Models with Efficient Non-Sampling Learning
-
- Discussion
1 Background
Value of Recommender System (RecSys)
- RecSys has become a major monetization tool for customer-oriented online services–RecSys已成为面向客户的在线服务的主要获利工具
- E.g., E-commerce, New Portal, Social Networks, etc.
- Some statistics:
- YouTube homepage: 60%+ clicks [Davidson et al. 2010]
- Netflix: 80%+ movie watches, 1billion+ value/year [Gomze-Uribe et al 2016]
- Amazon: 30%+ page views [Smith and Linden, 2017]
推荐系统是当前解决信息过载,最有效的方法之一。
Users’ Sparse Feedback Information-用户的稀疏反馈信息
- More commonly, users interact with items through implicit feedback(通常是隐式反馈)
- E.g., users’ viewing records and purchase history, etc.(如浏览历史、点击数据)
- It is difficult to utilize implicit feedback data as it is binary and only has positive examples
- “Negative Information” in implicit feedback
- 比如:用户点击了某个东西,可能是用户喜欢这个东西
- 但是用户没有点击,则反映出来的信息是不全面的
- 即,用户可能不喜欢某个商品,故不去点击;也可能是用户没有看过它,所以不去点击
- 所以这些商品不能笼统的被称为负样例
- 这些没有点击、没有购买过的商品占比很多,相比点击的商品 =>> 所以该数据是很稀疏的
- Users usually rate or click a small set of items compared to hundreds of millions of items in the system
2 Negative-Sampling VS Non-Sampling Learning
Utilizing Implicit Feedback Data - Negative-Sampling VS Non-Sampling Learning
Two strategies have been widely used in previous studies:
-
Negative sampling strategy that samples negative instances from unlabeled data
-
Non-Sampling (whole-data based) strategy that sees all the unlabeled data as negative
-
故在推荐系统使用隐式反馈数据时,有两种常见的学习方法来处理这两种负样例
-
负采样策略
是从所有用户中没有标记过的样例中抽取一部分作为负例:
- 如,我们认为用户所有没有购买的商品中肯定有一部分是用户不喜欢,用户对它们的偏好肯定没有买过的商品多,所以我们从里面抽取一部分
- 因为是抽取一部分,所以整体训练的sample(训练集)会比较少,因此它的训练速度会快一些
- 但是它的缺点:因为采样的随机性比较大,可能会忽略掉很多其实真正是负样例的样例
- 所以它的效果往往不是很稳定、在现实生活中往往不能达到一个最优的效果
-
非采样策略
- 就是认为用户所有没有买过的商品都有一定的负样性,都把它当作negative,会有权重
- 非采样把所有的数据都用上了,那么它可能就会有很好的coverage,
- 但是因为用了所有的数据,它的复杂度往往比较高
-
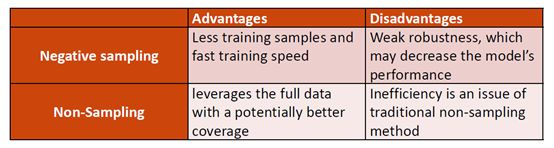
在传统的推荐方法中,如BPR(会采用一个负采样策略)、矩阵分解、WMF(加权矩阵分解,会采用非采样的策略),
- 在传统的方法中,它的复杂度往往没有非常高,所以这两种方法都可以用,
- 但是因为现在基于深度学习的方法多,但基于深度学习的方法,大家关注的点往往是模型的结构,为了比较方便的学习,大家往往采用负样例抽样的方法,
- 但是我们会觉得这样会降低模型的表现效果
Progresses and limitations in Neural RecSys Models - 神经RecSys模型的进展和局限性
但是现在将深度学习用到推荐系统任务上的工作主要集中在探索和引入不同的神经网络框架
- 为了优化模型,这些工作往往就采用负样例抽样的方法
- 负样例虽然方便易于实现,但是最近也有研究表明负样例的鲁棒性比较差
Complex Neural Network
- Exploring new deep learning architectures for Rec. Sys.
- Attention, MLP, CNN, etc
- Superior ability to complex network structures
- With substantial number of parameters
- Require expensive computations even with a sampling-based learning strategy (negative sampling)
Negative Sampling
- Not robust
- Difficult to achieve the optimal performance in practical applications
Can we find some solutions to efficiently learn a neural recommendation model without sampling?
3 Efficient Non-Sampling Learning Method
Complexity Issue of Non-sampling Learning - Non-sampling Learning的复杂性问题
为什么在现在的神经网络中没有使用非采样的方法:
- 因为采用非采样的方法往往有很高的复杂度
- In implicit data, the user-item interactions R is defined as:

稀疏矩阵,R_uv=1,表示用户u买过商品v;R_uv=0,表示用户u没有买过商品v
==>> 故这个矩阵中数值为1的数量会很少 (没买的肯定比购买的商品多得多)
- To learn model parameters, Hu et al. introduced a weighted regression loss, which associates a confidence to each prediction:
- 传统上的非采样的学习往往是采用加权的回归loss function(08年提出的加权回归)
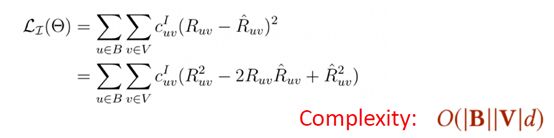
C_uv:表示权重
R_uv:表示真实的分值,0 or 1
R_uv hat:模型预测出来,0 or 1
右边是其模型的复杂度
B:batch size
V:整体是u,v(u,v往往是很大的,成千上万)
d:embading 大小
==>> 整体的复杂度会达到百万,上千万
Efficient Non-sampling Learning Theorem


Loss Inference
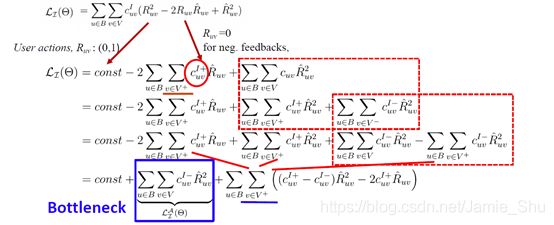
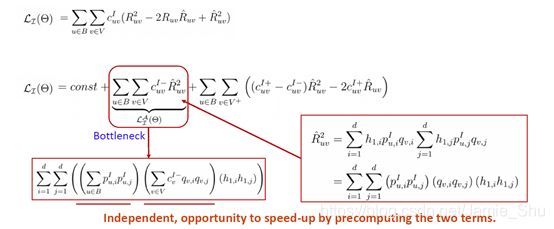

在推导中,我们并没有引入近似项,上面的Loss和下面的高效Loss,在算梯度时,得到的结果是完全一致的,即 没有做近似化的处理 ==>> 它不但简化了,而且不是近似简化
应用
将高效的非采样的算法应用到推荐场景上:
-
Plain recommendation scenario (only the ID information is utilized):
-
We propose ENMF, 5%+ better and 30+ times faster than SOTA method (TOIS accept)
-
基础场景中:只使用用户和商品id,(ENMF:高效的非采样矩阵分解框架)
比SOTA方法在推荐效果上好5%,在推荐速度上快30倍以上
-
-
Social-aware recommendation scenario:
- We propose EATNN, 4%+ better and 7+ times faster than SOTA method (SIGIR 2019 accept)
- Social-aware:用户还有社交信息;即 基于社交关系的推荐系统
-
Multi-Behavior recommendation scenario:
- We propose EHCF, 40%+ better and 10+ times faster than SOTA method (AAAI 2020 accept)
- Multi-Behavior 多种用户行为,即 用户有点击、购买、加入购物车这样的多种行为
- 高效非采样 协同过滤模型
-
Context-aware recommendation scenario:
- We propose ENSFM, 9%+ better and 5+ times faster than SOTA method (WWW 2020 accept)
- Context-aware的场景上提出了,高效非采样分解机模型
4 Recommendation Models with Efficient Non-Sampling Learning
4.1 Plain recommendation scenario
只使用用户的id信息
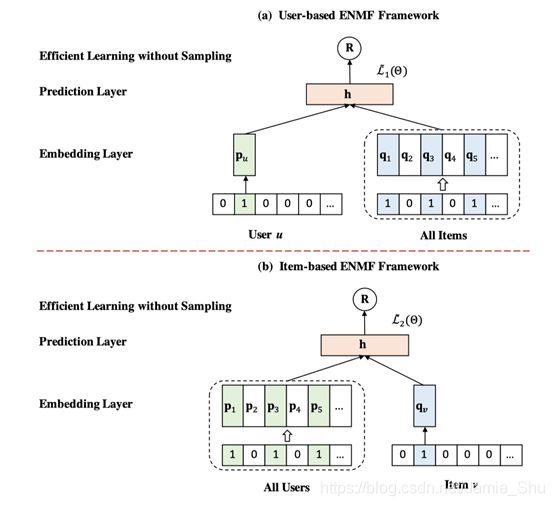
- Efficient Neural Matrix Factorization (ENMF) without sampling
- Inputs:
- User-based: a user and all his/her item interactions
- Item-based: an item with all its user interactions
主要区别:
- 每次输入都是一个user-item的pair,即 输入一个用户-商品的一个instance
- 本方法的输入是一个用户和其所有的交互商品;一个商品和其所有交互过的用户
[注]
Chong Chen, Min Zhang, Yongfeng Zhang, Yiqun Liu and Shaoping Ma. Efficient Neural Matrix Factorization without Sampling for Recommendation. ACM Transactions on Information Systems. (TOIS Vol. 38, No. 2, Article 14)
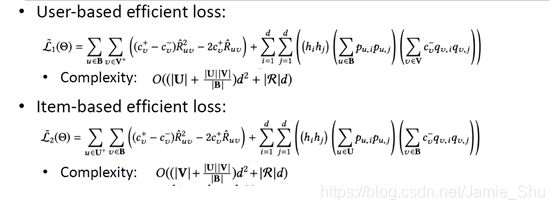
User-based:
- 以user为batch
- 为了扩展,以后的工作中可以加入更多的user信息
Item-based:
- item作为batch索引
- 为了后面加入item相关的信息(如item的feature、knowledge)
(1)Experimental settings - 实验设计
-
Datasets:
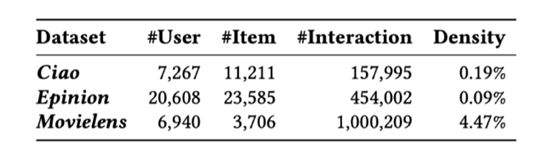
在实验中使用了3个数据集,
Ciao、Epinion、Movielens -
Baselines:(比较的baseline)
-
BPR (UAI’09)
-
WMF (ICDM’08)
-
ExpoMF (WWW’16)
-
GMF (WWW’17)
-
NCF (WWW’17)
-
ConvNCF (IJCAI’18)

MP是最基础的
传统方法:BPR、WMF、ExpoMF,这3个是非neural模型
GMF:Generalize MF
NCF:何老师17年提出;18年加上CNN后的ConvNCF
-
-
Evaluation methods: HR@K, NDCG@K, K= 50, 100, 200
两种评价方式:HR, NDCG
(2)Model Comparisons
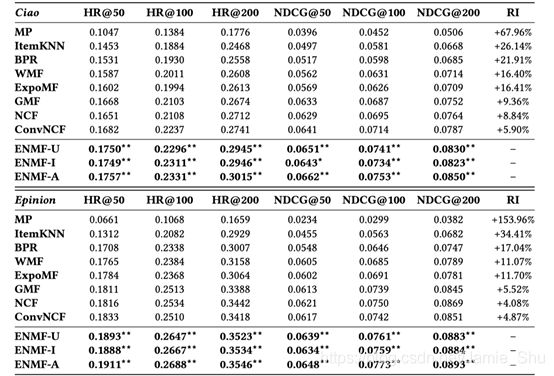
- Performance comparison on two datasets for all methods
- ENMF Consistently significantly outperforms the best baseline
- Improves more than 4%
相比于已有的方法,都更好,并且也可以看到,在传统的方法中(WMF、ExpoMF这两种是使用非采样学习,它们的学习也会比BPR更好,即在传统方法上的对比也会显示出,使用非采样学习,会比使用负采样学习的效果更好)
在神经网络中也可以看到,ENMF显著得优于这些GMF、NCF、ConvNCF,即 显示出非采样学习在神经网络中的有效性
(3)Efficiency Analysis
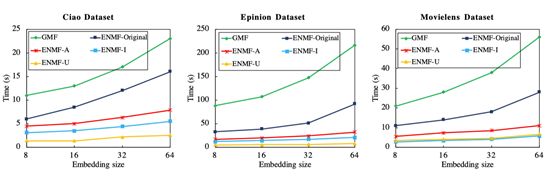
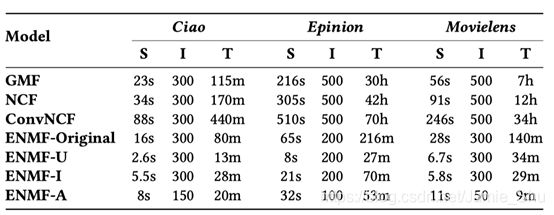
Comparison of runtime - 训练效率对比
- s: second; m: minute; h: hour; d: day
- S: training time for a single iteration;
- I: Overall iterations;
- T: Total time
10 times faster
GPU: GTX titan + 8核CPU
图1:每个epoch需要多少秒
表:这些模型在整体的数据集上训练完毕需要多少时间
- s:表示single epoch,每个epoch需要需要训练多少秒
- I:表示总共需要训练多少轮
- 非采样学习的话,学习效率会高一点,所需要的轮数也会小一些
4.2 Social-aware Recommendation Scenario
即 用户的社交信息可以用来帮助进行用户偏好建模,提高推荐的准确性
- Leveraging users’ social connections helps reduce sparsity
- Improve the performance of recommender systems
==>> Social-aware recommendation - But the preference sharing between item domain and social domain are varied for different users in real life.
提出了一个应用于社交关系的高效非采样自适应迁移网络;新框架,针对已有的迁移学习中,通常采用的是一种静态的传输方案,故在模型上加入了自适应迁移的学习机制,通过引入一个attention network,自动为每个用户分配一个个性化迁移方案;同时扩展了高效非采样算法,能够在同时支持多任务的学习。
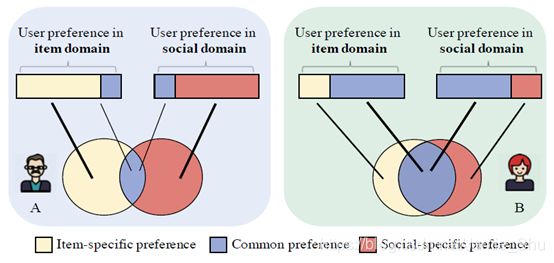
- Efficient Adaptive Transfer Neural Network (EATNN)
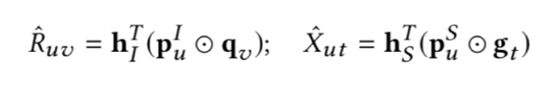
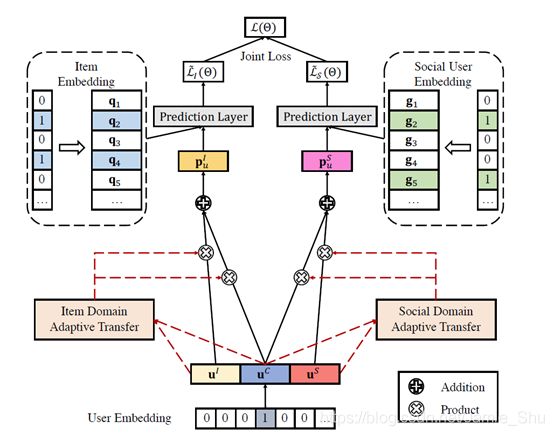
- 左边的部分是用户和商品的领域,MF的学习
- 右边是用户的social network的学习
[注]
Chong Chen, Min Zhang, Chenyang Wang, Weizhi Ma, Minming Li, Yiqun Liu and Shaoping Ma. An Efficient Adaptive Transfer Neural Network for Social-aware Recommendation. The 42th International ACM SIGIR Conference on Research and Development in Information Retrieval. (SIGIR 2019)
(1)Attention-based Adaptive Transfer
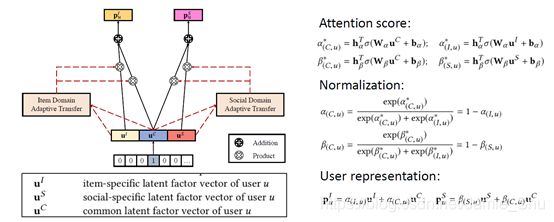
模型上的 自适应迁移学习
- 用户在不同的domain,他会有共同的偏好,如 有些用户对商品的喜好与他交朋友的喜好都比较类似;也有些用户可能表现得比较不同,比如在商品领域和朋友交往中,不相同
- ==>> 故用attention network来对其进行刻画(用得很多)
- attention network:两层神经网路,自动为一些
(2)Joint Learning
得到p_u、p_s后,之后即采用高效非采样算法,对同时对这两个任务进行高效非采样的学习,最后采用Joint Learning的方法(把两个Loss,通过一定的参数,结合在一起),进行学习
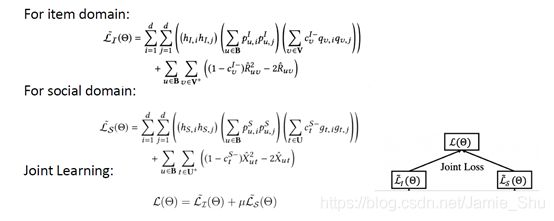
(3)Experimental settings
-
Datasets:
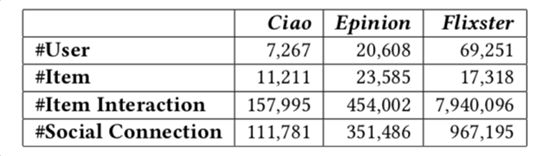
- 这3个数据集,同时有用户和商品的交互,以及用户和用户之间的交互(即用户和用户之间的social network)
-
Baselines:
-
BPR(UAI’09)
-
ExpoMF(WWW’16)
-
NCF (WWW’17)
-
SBPR (CIKM’14)
-
TranSIV (CIKM’17)
-
SAMN (WSDM’19)
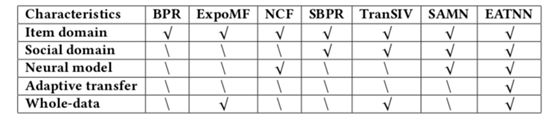
- BPR、ExpoMF、NCF 是没有使用social信息的
- SBPR:在BPR上使用了social信息
- TranSIV :非neural模型,Transform Learning是静态的,用的是全数据的
- SAMN:用neural模型,但不是非采样的
-
-
Evaluation methods: Recall@K, NDCG@K, K=10, 50, 100
(4)Model Comparisons
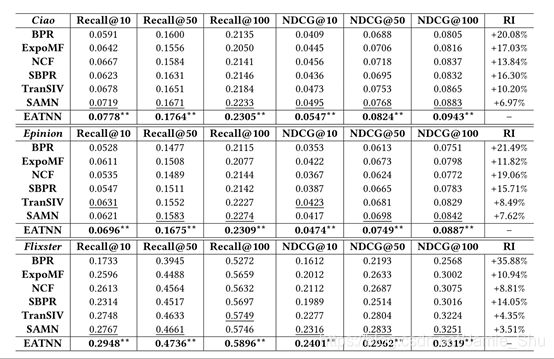
- Performance comparison on three datasets for all methods
- Best Baselines:
- TranSIV: non-Neural, whole-data
- SAMN: Neural model, sampled data
- EATNN
- Consistently significantly outperforms the best baseline
(5)Efficiency Analysis
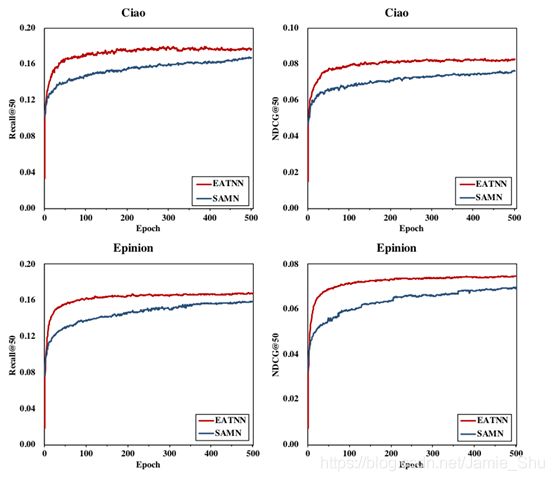
- 收敛速度快(因为在每一轮中就考虑了所有的instance)
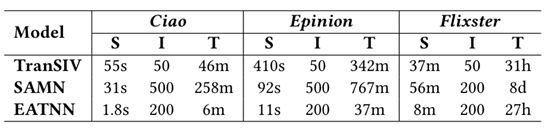
Comparison of runtime
- s: second; m: minute; h: hour; d: day
- S: training time for a single iteration;
- I: Overall iterations;
- T: Total time
4.3 Multi-Behavior Recommendation Scenario
用户对商品的多种交互信息(点击了哪些商品、看了哪些商品、把哪些商品加入购物车、最终购买了哪些商品),但现在很多没有考虑,考虑多种信息的模型比较少;也没有考虑到每种信息的transform关系
- 如,用户买的商品很有可能就是之前加入购物车的商品,用户买的商品一般情况下是他看过的商品,故在不同的信息之间可能会有不同的transform信息
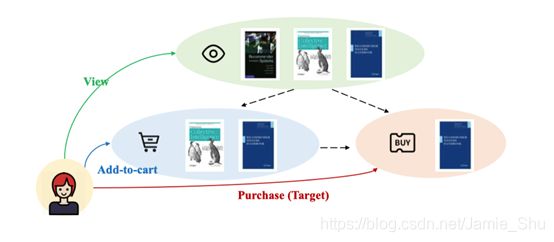
- Heterogeneous (multi-behavior) feedback (e.g., view, click, and purchase) is widespread in many online systems
- There exist strong transfer relations among different behaviors
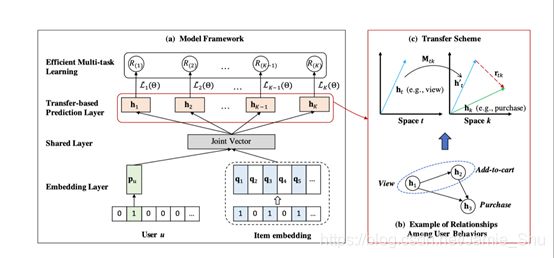
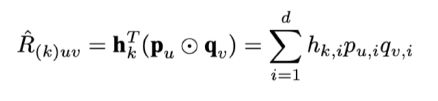
[注]
Chong Chen, Min Zhang, Weizhi Ma, Yongfeng Zhang, Yiqun Liu and Shaoping Ma. Efficient Heterogeneous Collaborative Filtering without Negative Sampling for Recommendation. The 44th AAAI Conference on Artificial Intelligence. (AAAI 2020)
(1)Behavior Transferring
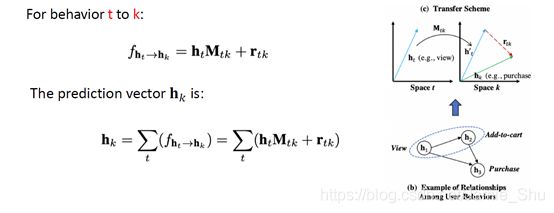
(2)Multi-task Learning

(3)Experimental settings
-
Datasets:
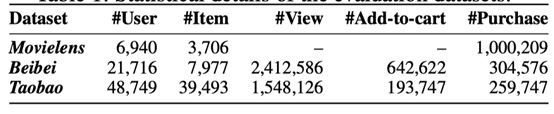
-
Baselines:
- BPR(UAI’09)
- ExpoMF (WWW’16)
- NCF (WWW’17)
- CMF (WWW’15)
- MC-BPR (RecSys’16)
- NMTR (ICDE’19, TKDE’20 ) - neural network
-
Evaluation methods: HR@K, NDCG@K, K=10, 50, 100
(4)Model Comparisons
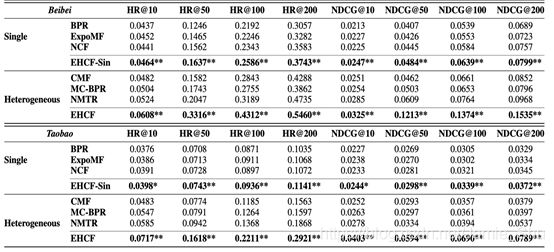
- Performance comparison on two datasets for all methods
- Improves more than 40%
- Non-sampling performs much better on multi-behavior scenario
- NMIR对每个样例都要抽样,只有正样,没有负样;每次样例带来的随机性比较大,让模型不太容易收敛
- 非采样的方法:每次输入的batch,它的Loss,有稳定的下降趋势
(5)Efficiency Analysis
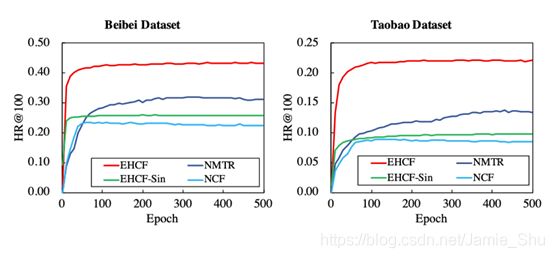
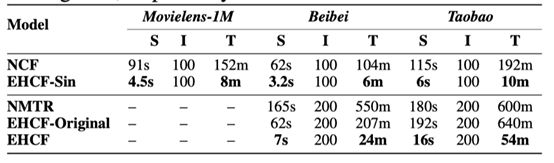
Comparison of runtime
- s: second; m: minute; h: hour; d: day
- S: training time for a single iteration;
- I: Overall iterations;
- T: Total time
10 times faster
4.4 Context-aware Recommendation Scenario
-
Leveraging contextual information
-
user demographics, item attributes, and time/location of the current transaction, etc.

-
Factorization Machines (FM) with negative sampling is a popular solution
用户会有更多的user preference,user profile,item attribute,即 用户、商品的额外信息
怎么把这些额外的信息也引入进来呢?
——分解机模型是比较好的模型
Efficient Non-sampling Factorization Machines (ENSFM)
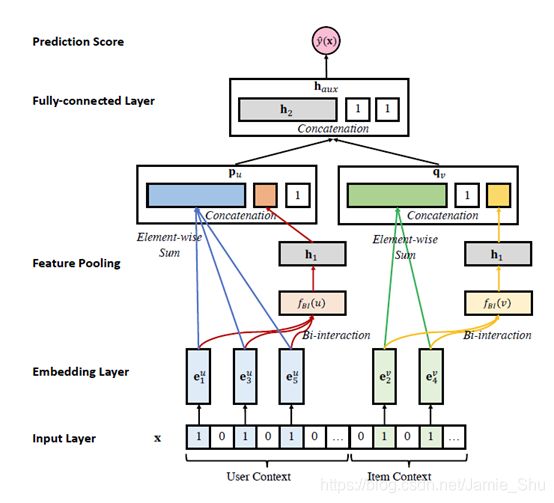

[注]
Chong Chen, Min Zhang, Weizhi Ma, Yiqun Liu and Shaoping Ma. Efficient Non-Sampling Factorization Machines for Optimal Context-Aware Recommendation. The Web Conference 2020 (WWW 2020)
(1)Proof
首先给出证明
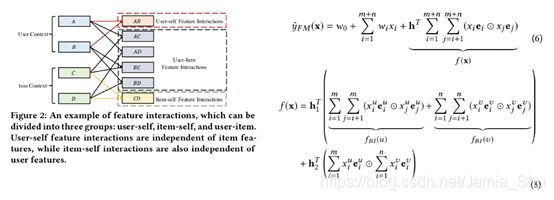
两两之间的交互可以分为
- AB:用户自己的feature交互了一下;(这部分与item无关)
- CD:是item自己的feature交互了一下;(这部分与user无关)
- AC、AD、BC、BD 就是user和item的interaction
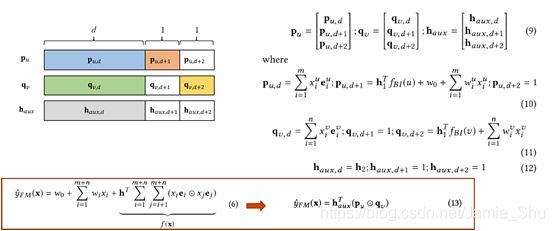
把前面的公式分解开来
证明:泛化的分解机模型可以转化为泛化的矩阵分解形式
(2)Efficient Mini-batch Learning Algorithm

Efficient Non-Sampling Learning Method就是在这种矩阵分解上做的
(3)Experimental settings
-
Datasets:
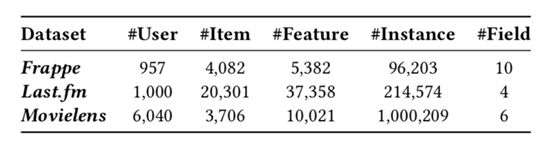
Frappe、Last.fm的数据集是与CFM这篇文章中的数据集一样,该作者把他的数据集公开在GitHub上
-
Baselines:
- FM (ICDM 10)
- DeepFM (IJCAI 17)
- NFM (SIGIR 17)
- ONCF (IJCAI 18)
- CFM (IJCAI 19)
- ENMF (SIGIR 19)
-
Evaluation methods: HR@K, NDCG@K, K=5, 10, 20
(4)Model Comparisons
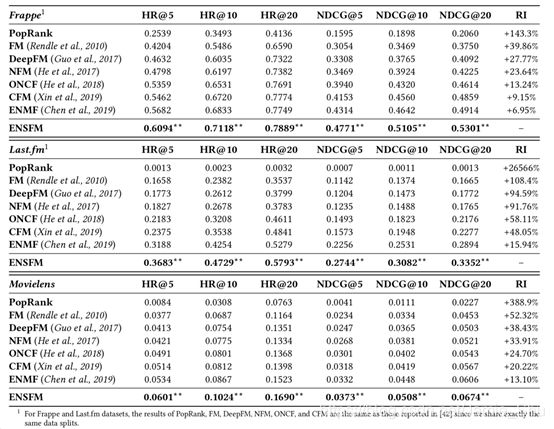
CFM:把模型做的很复杂,但在model learning上还是用negative sampling,故与non-sampling的效果差距大
- Performance comparison on three datasets for all methods
- Best Baselines:
- ENMF: whole-data
- CFM: sampled data
- ENSFM
- Consistently significantly outperforms the best baseline
(5)Efficiency Analysis
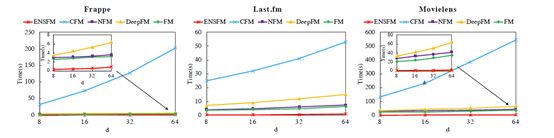
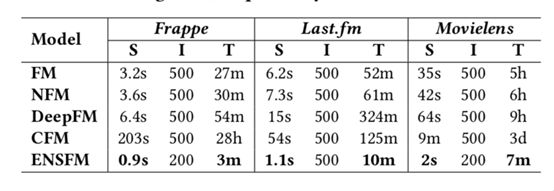
Comparison of runtime
- s: second; m: minute; h: hour; d: day
- S: training time for a single iteration;
- I: Overall iterations;
- T: Total time
5 Discussion
- Recently, there is a surge of interest in applying novel neural networks for recommendation tasks.
- More complex models do not necessarily lead to better results since they are more difficult to optimize and tune
- We empirically shows that a proper learning method is even more important than advanced neural network structures
- We expect future research should focus more on designing models with better learning algorithms for specific tasks, rather than relying on complex models and expensive computational power for minor improvements
[大佬Email]
Github:
- https://github.com/chenchongthu/ENMF
- https://github.com/THUIR/ENMF