400Gbps 网络面临的挑战
关于 TCP 与 100Gbps+ 场景的细说,参见:单流 TCP 100Gbps+ 难题的直观解释
400Gbps 网络将又是一个 “硬件准备好了,可软件没跟上” 的场景。
把一条 TCP Flow 看作一个操作系统进程,多条 Flow 共享 10Gbps 带宽和多进程被同一个 CPU 调度一样。
我们知道,SMP 场景下,应用程序和操作系统需要重新设计,将原来的大块逻辑拆得粒度更细,以便并行,同时,操作系统尽量避免争锁,比如 Linux 内核大量采用 per-cpu 变量。数据结构互不依赖,细逻辑便可自由在多个核心并行乱序执行。
但以上这段话发生地极其缓慢,从我记忆中的 2006 年开始,直到今天很多逻辑依然没有完成改造,这是 “硬件准备好了,软件没跟上” 的典型一例。
400Gbps 网络将是另外一例,不管厂商叫得多欢,软件难题依然改变不了挑战。
我来用 400Gbps 场景重写上面那段话。
我们知道,400Gbps 场景下,端到端传输协议和交换机需要重新设计,将流拆得粒度更细,以便并行传输和处理,同时,交换机尽量避免将多个流安排到同一个队列,避免 HoL。数据包 or subflow/flowlet 前后互不依赖,便可自由在多条路径乱序传输并被端主机多核资源负载均衡处理。
就差指名道姓了,说的就是传统 TCP。
先看端能力的问题。
TCP 的保序性约束同一个流不能并行传输和处理。简单算一笔账,单流 400Gbps 吞吐需要每秒收发 (400/8)10001000*1000/1460 个数据包,大致 34246575 个,即每微秒处理 34 个数据包。
大致估算一下 25Gbps 场景下 Intel® Xeon® Platinum 8260 CPU @ 2.40GHz 的收包能力,关闭 GRO/LRO,下图三栏分别为 top/iperf -s -i 1/funclantency tcp_v4_rcv 的结果:
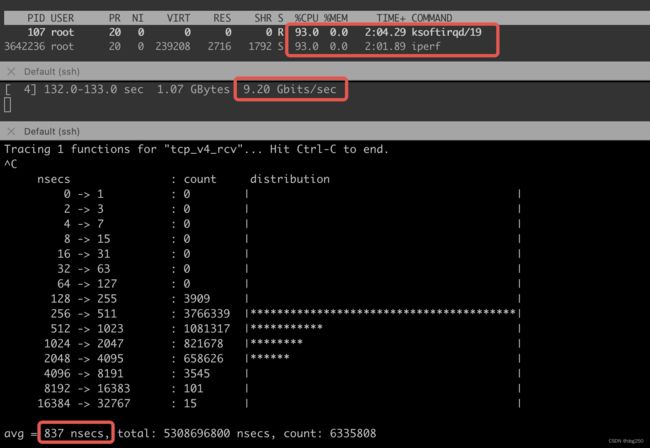
一款不错的 CPU 单核极限能力不到 10Gbps,发送端关闭 TSO/GSO,接收端 CPU 下降,但 tcp_v4_rcv 的执行能力已达上限,接收端打开 GRO/LRO,tcp_v4_rcv 开销变大,达到 1500us 以上。
双边启用硬件卸载,志强 CPU 的 TCP 单流处理极限大约在 60~80Gbps。
TCP 协议逻辑过于复杂,这意味着更多的 CPU 指令周期,难有 CPU 能支撑 20ns~30ns 处理一个 1460 字节的数据包(或者 80ns~200ns 处理一个更大的 LRO 聚合数据包)。
既然单个 CPU 不行,多个总可以。32 个 CPU 并行,妥妥 1us 处理 30+ 个数据包。但 TCP 需要保序,不允许并行处理同一条流。这便是一个简单的障碍。
如果允许乱序传输,上述瓶颈即可被打破。我说 TCP 不适合 400Gbps 网络,这话并不过分。一定是便于并行处理的乱序传输协议才更适配 400Gbps。
对于非 TCP 协议,仍然受限于 CPU 的指令周期处理极限以及内存带宽极限,越复杂的协议逻辑有效吞吐越低,虽然通过堆 CPU 核数能有所优化,但专用硬件显然更适合适配 400Gbps。
各类 Hardware offloading 方案,RDMA/RoCEv2 只是开端。
再说拥塞控制。
范雅各布森管道理论,瓶颈 buffer 等于 BDP 可在 AIMD 策略下获得最佳带宽利用率,buffer 小于 BDP - alpha 为浅队列,buffer 大于 BDP + alpha 属深队列。各类端到端拥塞控制算法孰优孰劣便围绕着 buffer 大小展开。
400Gbps,40us 链路,BDP 达 2MB,需更大 buffer 平滑统计突发,但更大 buffer 承受更大突发的同时,在大收敛比节点也要承受更大扇入,引入更大延迟,影响公平性。同时,更大的 buffer 意味着更大的成本。
虽然 PFC,ECN 机制已经可逐跳或者端到端反馈拥塞,但却不得不以额外延时为代价。即便如此,绝大多数数据都可在 1 个 RTT 无反馈传输完毕(400Gbps BDP 约 MB 级别)而无缘 ECN 之惠。
说到底,如今的拥塞控制机制几乎全依赖反馈到端执行,中间节点没有一种简单的分流能力。
比方说,一个端口发生拥塞,交换机立即将流量引导到稍微空闲的等价路径。而该机制需要不同于传统最短路径路由的新基础设施来支撑。虽然 SDN 控制器可提供支撑,但分布式方案目前尚未存在。
Google 的 PLB 提供了重新选路的思路,但依然需要将拥塞反馈到端后由端执行 re-path,考虑流的 Multi-Path,乱序传输,需要由端来综合调度拥塞信息。
由于收敛比,扇入的存在,拥塞不可避免,高吞吐与低延时看似不可兼得。但该结论显然来自传统的假设,端到端传输协议控制数据流沿着最短路径到达对端。在 400Gbps 场景,反过来更合适,即哑端专用硬件盲发数据包,数据包沿着多条路径乱序传输,转发节点以分流,反压的方式进行拥塞控制,可同时获得高吞吐和低延时。
简单举一例,一服务器网卡按照 400Gbps 发送(而不是传统单流),其中一个或几个数据包属于某类低延时敏感业务,由于途中交换机某端口拥塞,这些数据包不得不忍受排队,而对它们标记 ECN 毫无意义,因为它们属于单数据包(此类数据包非常多)。
无论对于短消息还是长流,即时处理拥塞总是低延时的最佳选择:
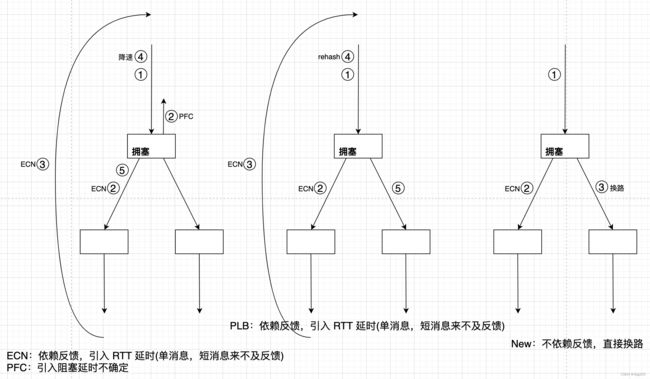 与端到端原则的 TCP/IP 协议栈相反,400Gbps 场景的传输控制协议族,复杂性从端移到了中心,第一时间处理拥塞代替反馈拥塞,这是低延时的核心。连带效果,端在传输逻辑方面的弱化也将更多资源留给了计算,端资源给计算,中心资源给传输。
与端到端原则的 TCP/IP 协议栈相反,400Gbps 场景的传输控制协议族,复杂性从端移到了中心,第一时间处理拥塞代替反馈拥塞,这是低延时的核心。连带效果,端在传输逻辑方面的弱化也将更多资源留给了计算,端资源给计算,中心资源给传输。
只要 TCP 深刻在你心里,你可能就不明白我说的 “依赖反馈” 到底意味着什么。再举一例,假设瓶颈带宽达 400Tbps (而不是 400Gbps),你要在 40us 的链路传输 100MB。简单算一下,100MB 大概需要 68493 个 1460 字节的数据包,仍假设初始窗口 10(很不合理),慢启动阶段,窗口随 RTT 倍增,大概不到 12 个 RTT 就能传完 100MB,而慢启动尚未结束,诸如 BBR 复杂的逻辑不起作用。如果初始窗口因大带宽改为 100000(很合理),一个初始窗口即可完成传输,甚至慢启动也不需要,至多一次丢包反馈后重传。
或者说就问一句,如果不依赖反馈,如何进行拥塞控制。端到端算法可榨取的收益早已捉襟见肘,需修改中心的算法才能有所改变。
400Gbps 准备好了,人们依然指望 TCP 可适配,一个进程无法充分利用 SMP,一条 TCP 也无法跑 400Gbps,人们一开始用多个进程去跑 SMP,现在人们用多条 TCP 跑满 400Gbps,显然,后者粒度太粗,正如进程粒度太粗一样。核心还是分割可并行单元,进程之外可调度更细粒度的线程,协程。同理,重写传输协议可实现消息粒度(介于数据包和传统数据流之间)并行传输和处理,当 “X程” 在多核上无阻塞调度时,消息也在网络无排队分流。
总之,无论从端能力还是拥塞控制来看,400Gbps 网络受上层逻辑约束越少越好(与直觉相反,比如,如果网卡不认识五元组,便可将每个数据包分发到不同的 CPU):
- 消息短小则数据包之间无依赖,可有效利用端主机资源并行处理。
- 消息短小则数据包之间无依赖,可有效利用多等价路径乱序传输。
- 不存在长流,交换机更看不到长流,长流要切成短消息乱序传输。
- 400Gbps 网络只管传输,不管协议逻辑。
显然,硬件准备好了,可软件还没跟上。但早晚会跟上,各类 RDMA,Homa,以及 AWS 的 SRD 已经在路上,拭目以待。
最近跟朋友聊起 100Gbps,200Gbps,400Gbps 网络,总觉得这玩意儿能跑起来吗,在协议层面尚未 ready 时,会不会造成浪费。联想修高速公路,一般双向 8 车道就顶配了,剩下的就是提升限速和提升安全车速,而不是增加车道,所以我觉得为什么不去研究空心光纤呢,将光纤传输速率提升到光速的 80%+(不细说,容易被民科)。… 想到 TCP 诞生的 1970s,网速远小于主机处理速度,它的一切协议逻辑都是合理的,适应彼时硬件的,一路发展到网卡将要逆袭 CPU,CPU 反而成了外设的当今,TCP 反而成了鸡肋,还是有点适者生存的进化理念的,什么样架构的硬件,就需要什么样的软件与之搭伴,否则硬件就是没有竞争力的。正如 CSMA/CD 搭伴了同轴电缆,迅速以简单易部署占领了市场,才发展到如今的百Gbps,软件伴随硬件的强化而升级,比较有趣,写篇随笔。
浙江温州皮鞋湿,下雨进水不会胖。