Fully Convolutional Networks for Semantic Segmentation FCN论文记录
Fully Convolutional Networks for Semantic Segmentation
文章来源:2015CVPR
一、背景
在FCN全卷积网络出现之前,之前的图像分割都是基于候选框和滑窗的CNN的语义分割算法。由于CNN网络的特殊性,所以对像素进行预测是时候是将被预测像素为中心的一小块图片作为网络输入进行预测,最后通过一些列卷积、池化、全连接,最后softmax层输出该像素的属于哪一类的概率。
这样做的缺点有:
- 需要遍历整个图片,就要一定的存储空间
- 由于CNN网络特殊性,要求输入的图像块大小固定,
- 相邻像素预测是,所输入的“小块图像”有过多的信息冗余

二、FCN网络提出的创新点
主要有这三条。
(1)构建了全卷积网络。将CNN网络中的全连接层换成了全卷积层,形成了解码-编码的网络结构。随后的基于深度学习到语义分割网络对结构大多都是基于解码编码网络来做的改进。

FCN的解码-编码网络结构

(2)接受任意大小的图片输入。也正是构建了全卷积网络,没有全连接层固定的神经元个数的限制,所以接受任意大小的输入。
(3)提出了skip architecture。该结构将深层次的特征图和不同浅层次的特征图进行叠加,将位置信息和语义信息更多的结合起来。(后面会讲到具体)。
三、FCN的网络结构设计
FCN网络前面编码阶段用的是训练好的VGG16网络的模型,通过卷积和池化操作将特征图不断的缩小,这个过程可以得到更多的语义信息,但是同时会丢失位置信息。到了解码阶段,特征图经过解码器的第三次卷积之后输出heatmap,FCN网络采用转置卷积的方式进行上采样将heatmap恢复到原来图片的大小。上采样过程就涉及到了skip architecture。
1、编码器模型的选择
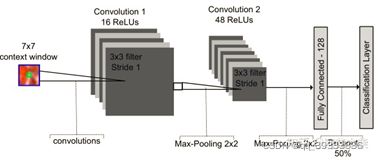
作者考虑的三种CNN模型:AlexNet、VGG net、GoogLeNet。AlexNet 是在ILSVRC12中胜出的。VGG net、GoogLeNet 在ILSVRC14中表现出色。作者将这三个网络的FC层转换为1x1卷积层,再增加一个有21个通道的1x1卷积层,对应到PASCAL VOC中的分类,最后再后接上采样层得到语义分割模型。特别的,对于GoogLeNet,仅用最后的输出层,去掉全局平均池化层(GAP)层。
各模型在PASCAL VOC上的对比结果如下:
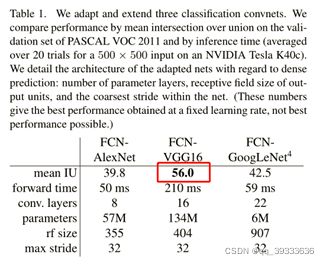
可以看出VGG16性能较佳。表格中的第一行代表均交并比,作为语义分割较为权威的评价指标。
作者还得出结论:尽管在识别上面精度相似,但是在分割方面GoogLenet和VGG16还是不能匹敌。
2、VGG-16网络详解
首先,VGG网络的有六种不同配置,常用的是16层的D配置。16层分别是13个3x3的卷积层,3个全连接层,maxpooling层不算。

说明:VGG网络中卷积核大小和个数如图中所示,stride为1。
Maxpooling窗口大小为2,stride为2。(经过maxpooling之后分辨率减小一半)
为了保证卷积前后分辨率不变,有padding的操作。有以下公式可求出Padding值。K为卷积核大小,in和out相等,s为stride。
ⅈn=(out-k+2P)/S+1
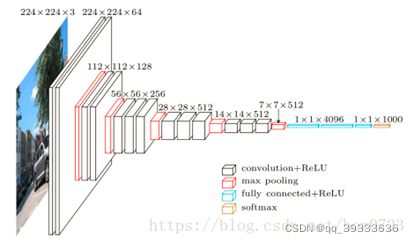
VGG网络规定输入大小224x224大小的图片。如上图所示,224x224的三通道图片输入之后,为保证卷积前后分辨率一致,先对原图进行padding操作。
在VGG网络中前面五层maxpooling的输出中,对输入图像大小分别会缩小2倍、4倍、8倍、16倍、32倍。
经计算padding值为1。经过2层3x3x64的卷积操作之后,得到224x224x64的featuremap,再进入第一个maxpooling层,该层只对图像大小作用。得到输出的图像为112x112x64.再将该featuremap输入到下一个卷积层中操作。直到第五层maxpooling输出为止,结束卷积计算。同时输出的featuremap为7x7x512大小。
经过两个1x1x4096的全连接层后(也正是因为配置好的网络的固定的4096个神经节点的限制,所以要求输入图片大小固定),在进入1x1x1000(1000是代表的分类的类别数)的全连接层,最后进入softmax层输出每一类对应的概率大小。
3、FCN网络详解
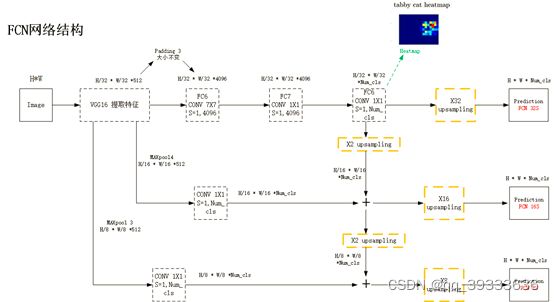
图片压缩之后看不清楚了,如有需要请访问这里,
FCN网络前面特征提取阶段和VGG16网络操作一样,所以直接从第六次卷积开始介绍。
假设输入FCN网络的图像大小为H*W,根据前面VGG-16网络的解释可以知道,第五层输出的图像大小为H/32 * W/32 * 512,第六层卷积操作中,卷积核为7x7x4096,stride为1,为了保证卷积之后输出featuremap分辨率不变,将输入特征图进行padding 3的操作,输出H/32 * W/32 * 4096大小的featuremap。然后再进行第七层的卷积操作,卷积核为7x7x4096,stride为1,输出featuremaps为H/32 * W/32 * 4096,再将该featuremap输入到最后一个卷积层中,最后一个卷积层大小为1 * 1 * num_cls(num_cls是该数据集的类别数),通过这个卷积层之后,输出的是H/32 * W/32 * num_cls的heatmap。该heatmap再经过32倍的上采样(使用转置卷积)得到了预测的输出图片。这也被作者称为FCN-32S。
如果将编码器中的Maxpooling 4层的输出(大小为H/16 * W/16 * 512)和1 * 1 * num_cls的卷积核进行操作(得到的输出也H/16 * W/16 * num_cls),将结果与第八层的heatmap经过2倍的上采样的结果相加(深层的语义信息加浅层的位置信息),然后进行16倍的上采样,得到的输出作者称为FCN-16S。
相同的,先将Maxpooling3层中的输出(大小为H/8 * W/8 * 512)和 1 * 1 * num_cls的卷积核进行操作,得到的H/8 * W/8 * num_cls的输出。将第八层输出的heatmap经过2倍上采样后的结果与maxpooling4层卷积之后的结果相加,再将该输出做2倍的上采样,最后得到的结果与maxpooling3层经过卷积的结果相加,经过8倍的上采样,得到和原图大小一样的预测图片,其中包含了更多的浅层信息,作者将其命名为FCN-8S。
四、实验相关
1、评价指标

(1)像素精度:预测正确的像素数/像素总数
(2)平均精度:各个类别的平均像素精度
(3)均交并比 (mIU,Mean Intersection over Union):
IoU=(A∩B)/(A∪B ) = Sab / (Sa + Sb - Sab),则mIU是每个类像素总数ti与预测为该类的像素总数Σjnji的IoU的均值。
(4)频率加权IU:各类加权的IoU。
2、数据集:
(1)Pascal VOC(21 labels)
PASCAL VOC 2007 和 2012 数据集总共分 4 个大类:vehicle、household、animal、person,总共 20 个小类(加背景 21 类),预测的时候是只输出下图中黑色粗体的类别

(2)NYUDv2(1449 RGB-D images,40 labels)
了解到这个数据集不仅仅有RGB信息,还加入了一种Depth信息,即两幅图像,一个是普通的RGB三通道彩色图像,另一个是深度(Depth)图像。
Depth图像:类似于灰度图像,只是它的每个像素值是传感器距离物体的实际距离。通常RGB图像和Depth图像是配准的,因而像素之间具有一对一的对应关系。下图为示例图片

RGB数据(左),深度图(中),分割图(右)
(3)SIFT Flow (2688 images,33 labels)
a、语义标签:每一个像素点用一种类别来表示,每一种类别用一个数字来表示。总共有33类,背景类用0表示。
b、几何标签:每一个像素点用一个数字来表示,注:-1表示背景,1-3表示类别。01 sky (黑色显示):(其中包括:28:sky,31:sun,16:moon)
02 horizontal 水平(红色显示):(其中包括:10:crosswalk,11:desert,14:field,21:river,22:road,24:sand,25:sea,26:sidewalk)
03 vertical 垂直(绿色表示):(其中包括:1:awning,2:balcony,3:bird,4:boat,5:bridge,6:building,7:bus,8:car,9:cow, 12:door,13:fence,15:gress,17:mountain,18:person,19:plant,20:pole,23:rock,27:sign,29:staircase,30:streetlight,32:tree,33:window)


原图 语义标签 几何标签
3、不同上采样倍数的FCN网络输出预测的对比
数据集:Pascal VOC

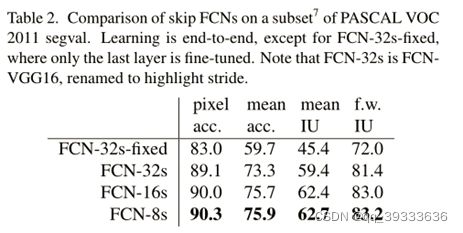
4、Pascal VOC数据集上对比
FCN-8s 与 R-CNN、SDS 的对比


可以看到FCN不仅性能大幅超过其它模型,达到了state-of-the-art ,而且推断时间大大减小。
5、NYUDv2数据集上实验结果对比(这个数据集的对比没有看太懂)
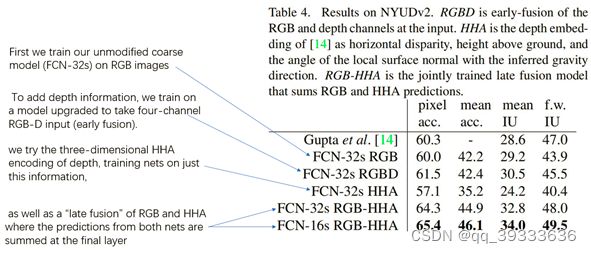
了解到在处理RGBD图像时,通常将其转换为HHA编码的图像
HHA:horizontal disparity, height above ground, and the angle the pixel’s local surface normal makes with the inferred gravity direction.
作者用了FCN-32S和FCN-16S在数据集上进行训练。
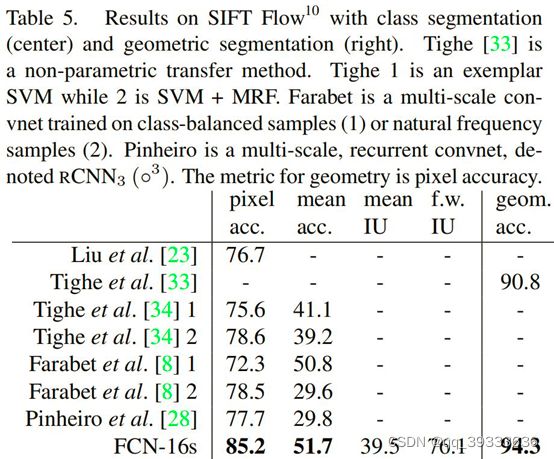
6、SIFT Flow数据集上实验结果对比(没太看懂这个对比)
五、全文总结
作者认为全卷积网络可以看作是分类网络的一种特例,基于这一点,将分类网络扩展到分割,并改进具有多分辨率层组合的体系结构,极大的改进了最新技术,同时简化并加速了学习和推理。
图片上传会被压缩,里面有一张比较重要的FCN网络的图片 压缩之后看不清楚了,如有需要请访问这里,查看照片和PPT。