【深度学习MVS系列论文】R-MVSNet: Recurrent MVSNet for High-resolution Multi-view Stereo Depth Inference
Recurrent MVSNet for High-resolution Multi-view Stereo Depth Inference
CVPR 2019
核心思路
之前的缺陷:scalability, hard for high-resolution scenes
contribution: scalable MVS framework 内存消耗减少,也可以应用大场景
instead of regularizing the entire 3D cost volume in one go, R-MVSNet sequentially regularizes the 2D cost maps along the depth direction via the gated recurrent unit(GRU)
key insight: regularize the cost volume in a sequential manner using GRU → 3D CNNs
O(N^3) → O(N^2)
主要是深度范围可以无穷假设 unlimited depth-wise resolution
相关工作
之前的最大缺陷是当分辨率上去,由于volume太大,几乎无法使用
- exploit the sparsity in 3D data
- octree structure to 3D CNNs
- divide-and-conquer: loss of global context information and slow processing speed
- regularize the cost volume implicitly(隐式的):sequentially
GRU
最开始在顺序语音和文本任务中被提出,现在也用在视频序列分析
R-MVSNet: gather spatial and temporal context information in the depth direction(空间和时间上下文信息)
网络架构
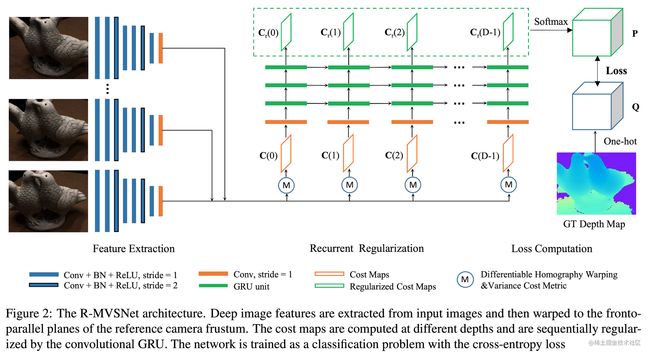
Sequential Processing
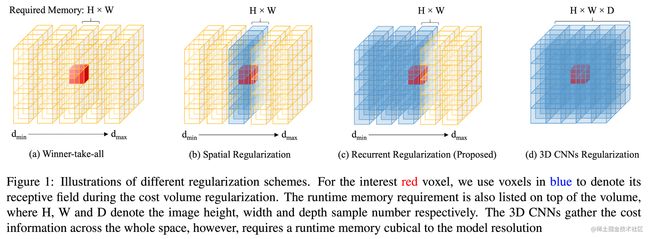
- winner-takes-all: replace the pixel-wise depth value with the best one(noise)
- spatial: filter the matching cost at different depths, gather spatial context information
- recurrent: 除了空间还利用单向的上下文信息,在效果上与整个3D空间差不多,内存消耗大大减少
Convolution GRU
cost volume C could be viewed as cost map concatenated in the depth direction
apply convolutional variant of GRU to aggregate such temporal context information
这种策略的另一个优点在于,连续的物体往往在一定的深度范围之内有着互相影响,而在代价体深度平面相隔很远的两个位置的相关性可能并不大,通过GRU的方式避免了错误信息和不相关信息的无限传递。
核心思路还是RNN的那套:update gate,reset gate
C r ( t ) = ( 1 − u p d a t e _ g a t e ) ∗ C r ( t − 1 ) + u p d a t e _ g a t e ∗ C u ( t ) C_r(t) = (1-update\_gate) * C_r(t-1) + update\_gate * C_u(t) Cr(t)=(1−update_gate)∗Cr(t−1)+update_gate∗Cu(t)
现在的cost volume综合考虑之前的cost volume和当前状态
当前状态通过标准的神经网络构建(这里的公式都有所简化)
C u ( t ) = σ ( W ∗ [ r e s e t _ g a t e × C r ( t − 1 ) ] + b ) C_u(t) = \sigma(W * [reset\_gate \times C_r(t-1)] + b) Cu(t)=σ(W∗[reset_gate×Cr(t−1)]+b)
Stacked GRU
将多层GRU组合(详细的网络结构说明暂略)
Loss
apply the inverse depth to sample the depth values in order to efficiently handle reconstructions
regression task → multi-class classification problem
用概率体和真值的cross entropy作为loss
- training: compute the whole probability volume
- testing: depth map can be sequentially retrieved using winner-take-all
Other Parts Pipeline
预处理
- target image + source images: score each image pair using a pice-wise Gaussian function w.r.t the baseline angle of the sparse point cloud
- depth range: determined by the sparse point cloud(COLMAP)
- depth sample number(
inver depth): 将时间分辨率调整为空间分辨率(这里不是很懂什么意思)
深度图优化改进
depth map will be retrieved from the regularized cost map
winner-take-all cannot produce sub-pixel accurancy
refine the depth map in a small depth range by enforcing the multi-view photo-consistency
interatively minimize the total image reproduction error between the reference image and all source images
这一步是为了让深度图达到sub-pixel准确度,原本已经很不错了,类似于二次插值(具体数学表示没太看懂)
Filter & Fusion
- photo-metric: take the probability as its confidence measure, filter probability loser than 0.3
- geometric consistency: 与MVSNet相同,pixel should be at least three view visible
实验
training
to prevent depth maps from being biased on the GRU regularization order, each training sample is passed to the network with forward and backward GRU regularization
- batch size = 1
- RMSProp optimizer
- learning rate = 0.001
Tanks and Temples Benchmark
- intermediate: outside-look-in camera trajectories
- advanced: 非常大非常复杂的场景,之前的方法都由于内存消耗太大失效
highly dependent on the point cloud density
R-MVSNet的深度图进行了1/4下采样,所以点云密度不太够
ETH3D Benchmark
- low-res:一些由于手持拍摄导致模糊和过曝
- high-res
提供depth map真值
Scalability
width-range
memory requirement is independent to the depth sample number
内存消耗是NVSNet的一半,内存利用率也更高
high-resolution
R-MVSNet can sample denser in depth direction
Ablation Studies
2D CNN: learned 2D features
WTA: Winner-take-all
ZCNN: classical plane sweeping
- 2D CNNs + 3D CNNs
- 2D CNNs + GRU
- 2D CNNs + Spatial
- 2D CNNs + WTA
- ZCNN + WTA
充分的消融实验
缺陷
- 只能在DTU上训练,没有更好的训练集
- 在ETH3D的高分辨率上仍然没法测试(6000*4000)