MVSNet论文阅读笔记
MVSNet: Depth Inference for Unstructured Multi-view Stereo
文章提出了一种端到端的深度学习架构,直接从图像得到深度图。
摘要
提出了一种端到端的深度学习架构,用于从多视图图像中推断深度图。
网络
- 提取特征图
- 通过单应性变形在参考相机的视锥上构建三维代价体。
- 用三维卷积对初始深度图进行正则化和回归
- 对输出的深度图结合参考图像进行优化,得到最终输出的深度图。
输入和输出
输入:n-1张源图像(source imgs)+1张参考图像(reference img)
输出:一张深度图(depth imgs)
基本框架
- 特征提取(Feature Extraction)
- 代价体构造(Cost Volume Construction)
- 代价体正则化(Cost Volume Regularization)
- 深度图优化(Depth Map Refinement)
- 深度图滤波和融合(Depth Map Filter and Depth Map Fusion)
引言
基于CNN的方法:可以引入全局语义信息,例如镜面和反射的先验条件
立体匹配:输入的图象是提前校正过的,无需考虑相机参数,只需要估计视差值即可。
MVS:输入的图像必须有完整相机几何模型(内参、外参)
研究内容
SurfaceNet预先构造了彩色立方块(CVC),将所有图片的颜色信息和相机信息组合到单个Volume中作为输入。采用分而治之策略,大规模重建时间长。
LSM利用深度投影/反投影实现了端到端的训练和预测,但仅适用低分辨率。
缺陷:
受规则网络的三维体积限制,内存消耗巨大。
网络结构

1.特征提取
提取N个输入图像 { I i } ( i = 1 ) N \{I_i\}_{(i=1)}^N {Ii}(i=1)N的特征 { F i } i = 1 N \{F_i\}^N_{i=1} {Fi}i=1N。
通过一个八层的2DCNN卷积网络,将第三层、第六层的步长设置为2,将特征塔分为3层,将特征进行下采样,由输入的H × \times ×W,变为32通道的 H 4 × W 4 {\frac{H}{4}}\times{\frac{W}{4}} 4H×4W,所有的领域信息都被编码到32通道的像素描述符中,有效的保证上下文信息。
2.代价体构造
由特征图(Feature map)构建3D代价体(3D Cost Volume)。
首先,在参考图像相机的视锥空间内划分相应的深度间隔,每个深度间隔对应一个深度层。
由于输入为一张参考图像 I 1 I_1 I1和N-1张源图像 { I i } ( i = 2 ) N \{I_i\}_{(i=2)}^N {Ii}(i=2)N,将每张源图像在特征提取后的得到的特征图 { F i } ( i = 2 ) N \{F_i\}_{(i=2)}^N {Fi}(i=2)N通过单应性变换(Differentiable Homography)warp到参考图相机平面空间的划分的深度层上,N-1张warp操作后的特征图+一张参考图像所得的特征图,在参考相机视锥空间得到了一个特征体(feature volume) { V i } ( i = 1 ) N {\{V_i\}_{(i=1)}^N} {Vi}(i=1)N,其中在深度为d的,warp后得到的特征图 V i ( d ) {V}_i(d) Vi(d)与其源相机特征图 F i {F}_i Fi之间的映射关系,由公式 x ′ H i ( d ) ⋅ x x' ~H i ( d )·x x′ Hi(d)⋅x决定
H i ( d ) = K i ⋅ R i ⋅ ( I − ( t 1 − t 2 ) ⋅ n 1 T d ⋅ R 1 T ⋅ K 1 T ) Hi(d)=Ki⋅Ri⋅(I−{\dfrac{(t1−t2)⋅n_1^T}{d}}⋅R_1^T⋅K_1^T) Hi(d)=Ki⋅Ri⋅(I−d(t1−t2)⋅n1T⋅R1T⋅K1T)
- K代表相机内参
- R代表旋转矩阵
- t代表平移矩阵
- d代表深度
下一步进行代价聚合操作,将特征体(Feature Volume)聚合为一个代价体C,为了适应任意数量的输入视图,采用了基于方差的相似性度测量。在计算cost时,和传统方法类似,MVSNet采用的平均权重,即参考图像和源图像所贡献的比例应该是一样的。

在传统算法里,所有领域帧和当前帧进行对比,然后进行匹配代价。深度学习里则是进行方差计算,这体现了作者让每张图像平等参与计算的思想,与传统算法里以参考图像为主的方法 不同。在进行方差处理后,得到的代价体C与图像数量N就无关了,所以作者说我们支持任意数量的输入。
3.代价体正则化
由于从图像提取的特征,对于非朗伯体或存在遮挡的区域,所以初始得到的代价体存在噪声,需要通过平滑约束(平滑约束(在空间上)是指在您向任何方向移动时像素值将缓慢变化的假设,并且它们可能与其邻居的值接近。 在阴影形状的上下文中,这可能意味着平滑度超过恢复的3d位置。相邻像素应投射到3d空间中的近处。)来构建推测深度图的概率体P。
MVSNet采用的正则化方案为3DCNN,网络结构类似于3D-UNet,使用编码器-解码器结构,以相对较低的内存和计算成本,从一个大的感受野聚集相邻的信息。最终沿着深度方向应用softmax操作进行概率体归一化操作(就是将代价体C变为概率体P,每层的深度值是真值的概率)。
4.深度图
初始深度估计
将得到的概率体P沿深度d方向计算期望,得到的的值即为该点的深度值,这样就得到了初始的深度图。 D = ∑ d = d m i n d m a x d ∗ P ( d ) D=\sum_{d=d_{min}}^{d_{max}}d \ast P(d) D=∑d=dmindmaxd∗P(d)其中P(d)是深度 d 处所有像素的概率估计。与argmax相比,计算期望能进行反向传播,同时在深度方向能产生连续的深度估计。
概率图(Probability Map)
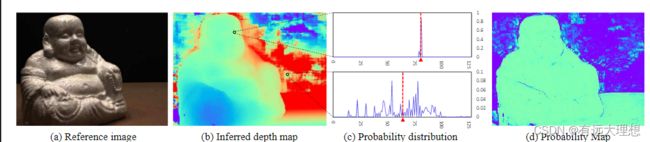
深度估计质量d
真值在深度估计值附近的概率。
计算方法:在概率体P中,沿着深度方向,取该点领域的四个深度假设值,计算他们的概率和。
概率图:每个点是真值的概率。概率越高,则与深度假设值与该值越接近。
深度图优化
从概率体P中提取深度图,由于正则化时感受野较大,可能受到类似图像分割和图像抠图中,边界过度平滑的问题。但自然场景下,参考图像包含边界信息。
受到深度图像抠图(Deep image matting)的启发
优化
- 初始深度图和参考图像(3个通道,RGB)组成一个4通道的输入。
- 过三个 32 通道 2D 卷积层和一个 1 通道卷积层来学习深度残差
- 将得到的残差图与初始深度图进行融合得到细化后的深度图。
5. 损失函数
用地面真实深度图和估计深度图之间的平均绝对差作为我们的训练损失。
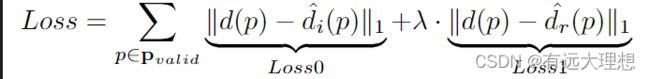

L1损失函数,分别对初始深度图和优化深度图对真值进行损失计算,再以权重系数λ相加,λ一般设置为1.0。
6.后处理
深度图滤波
利用光度一致性和几何一致性,过滤掉背景和遮挡区域中的异常值
利用光度一致性,在概率图估计深度图中,对概率小于0.8的值,视为异常值。
利用几何一致性,测量多个视图之间的深度一致性。类似于立体匹配中的视差约束。
点云融合
将不同视点的深度图融合到统一的点云表示中,使用基于可见性的融合算法,把遮挡,光照等影响降到了最低,使得不同视点之间的深度遮挡和冲突最小化。
为了进一步抑制重建噪声,在滤波步骤中确定每个像素的可见视图,并将所有重投影深度的平均值作为像素的最终深度估计。
融合后的深度图直接投影到空间,生成三维点云
7.结果
定量分析
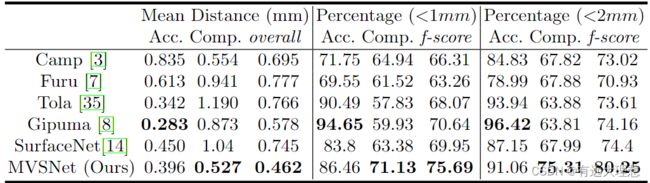
定性分析
