单目三维目标检测之CaDDN论文阅读
文章目录
- CaDDN: Categorical Depth Distribution Network for Monocular 3D Object Detection
-
- 作者和机构信息:
- Abstract
- 1. Introduction
- 2. Related Work
- 3. Proposed Method
-
- 3.1 3D Representation Learning
-
- Frustum特征网络:
- Frustum到Voxel的转换
- Voxel到Collapse的转换
- 3.2 BEV 3D Object Detection
- 3.2 Depth Discretization(深度离散化?)
- 3.4 Depth Distribution Label Generation(深度分布标签生成)
- 3.5 Training Losses
- 4. Experimental Result
-
- 4.1 KITTI Dataset Results
- 4.3 Ablation Studies
- 5.总结
- 6.代码调试
CaDDN: Categorical Depth Distribution Network for Monocular 3D Object Detection
paper: https://arxiv.org/abs/2103.01100
code:https://github.com/TRAILab/CaDDN
作者和机构信息:

Abstract
3D目标检测的主要难点是准确的估计出物体的深度,而这个深度是从物体和场景中估计出的(也就是说从2D图片中估计深度信息)。图片来自于小孔成像原理,在小孔成像时只得到了投影的信息,而忽略了深度、距离信息。很多方法是直接估计出深度信息来辅助目标检测,但由于估计出的深度信息不准确而影响最终的检测精度。
我们提出的CaDDN网络(Categotical Depth Distribution Network),预测每个像素的绝对深度分布,将丰富的背景特征信息(也就是图像特征,2d特征)投影到3D空间中适当的深度区间。然后我们使用计算效率高的鸟瞰图投影和单级检测器产生最终输出检测结果。最终评测效果极好,提升明显。这是第一篇在Waymo数据集上进行单目3D目标检测任务的论文。

a). 输入的图像
b). 由于没有depth distribution supervision,CaDDN的BEV特征受到了涂抹效应。
c). depth distribution supervision使得来自CaDDN的BEV特征编码更加准确,其中的对象可以准确检测。
本文的核心貌似就是depth distribution supervision.
1. Introduction
3D空间感知是自动驾驶和机器人领域一项重要的技术。由于单个摄像头具有低成本、易于部署的潜在能力,单目3D感知也逐渐开始发展。由于图像在投影过程中丢失了深度信息,目前单目3D感知的效果是远不如双目、激光雷达的感知。
为了让单目图像能够获取到深度感知的能力,很多学者开始通过训练神经网络以期获得对应的深度图。在训练阶段,深度估计与3D detection 分离,防止深度图估计针对检测任务进行优化。图像数据中的深度信息也可以隐式学习,直接将提取的特征从二维图像转换到三维空间,最后转换到鸟瞰(BEV)网格。然而,隐式方法容易出现特征涂抹(feature smearing),即相似的图像特征可能存在于投影空间的多个位置。特征涂抹也增加了物体定位的难度。
为了解决这个问题,我们设计了CaDDN网络。通过利用概率深度估计,CaDDN能够生成高质量的BEV图。然后总结了本文的三点贡献:
-
Categorical Depth Distributions(我的理解是绝对的深度分布).
-
端到端的深度估计
-
BEV场景解释
在Kitti排行榜上效果不错,Car、Pedestrian类排名第一。第一篇在Waymo Open Dataset中测试的论文。
2. Related Work
单目深度估计(Monocular Depth Estimation):
单目深度估计将图像中的每个像素都估计出一个深度信息。而单目深度估计的网络架构一般来自已经被研究很好的像素到像素的网络架构,如语义分割所使用的网络架构。如FCNs(全卷积神经网络)来进行单目的估计深度,如[论文][Deeper depth prediction with fully convolutional residual networks. 3DV, 2016.]。ASPP(atrous spatial pyramid pooling,苍穹空间金字塔池化)也被DeepLab提出用于语义分割,并在[DORN][Deep ordinal regression network for monocular depth estimation. CVPR, 2018.]和[BTS][From big to small: Multi-scale local planar guidance for monocular depth estimation. arXiv preprint, 2019.]中用于进行深度估计。此外还有很多方法进行了端到端的深度估计和语义分割:
- Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. ICCV, 2015.
- Sdc-depth: Semantic divide-and-conquer network for monocular depth estimation. CVPR, 2020.
- Pad-net: Multi-tasks guided prediction-and-distillation network for simultaneous depth estimation and scene parsing. CVPR, 2018.
- Joint task-recursive learning for semantic segmentation and depth estimation. ECCV, 2018.
本文的深度估计方法借鉴了DeepLab中的思想。
BEV语义分割:
BEV分割方法[42,49]尝试从图像中预测BEV 3D语义地图。单目图像可以直接被用来估计BEV语义地图[39,35,60],或者估计BEV特征表示[44,47,41],以此作为分割任务的中间步骤。还有Lift,Splat,Shoot[44]非监督方法来预测categorical depth distributions,以此来生成中间的BEV表示。
在本文中,我们通过监测带有ground truth的one-hot编码的 categorical depth distributions估计,以产生更准确的深度分布,以供目标检测。
单目3D检测:
单目3D目标检测通常会生成中间的表示来帮助进行3D检测任务。根据这些中间表示,单目3D目标检测可以被划分为三类方法:
1). 直接法(Direct Methods)
所谓直接法就是直接从图像中估计出3D检测框,也无需预测中间的3D场景表示[9,52,4,32]。更进一步的说就是,直接法可以结合2D图像平面和3D空间的几何关系来辅助检测[53,12,40,3]。例如,可以在图像平面上估计出某对象的关键点,以帮助使用已知几何结构构建3D box[33,29]。[M3D-RPN][M3D-RPN: monocular 3D region proposal network for object detection. ICCV, 2019.][3]引入深度感知卷积,它按行划分输入并学习每个区域的no-shared kernels,以学习3D空间中位于相关区域的特定特征。
可以对场景中的物体进行形状估计,从而理解三维物体的几何形状。形状估计可以从3D CAD模型的标记顶点中被监督[5,24],或从LiDAR扫描[^22],或直接从输入数据以自我监督的方式[2]。
直接法的缺点是检测框直接从2D图像中生成,没有产生明确的深度信息,相对于其它方法,定位性能较差。
2). 基于深度的方法(Depth-Based Methods)
该方法先利用深度估计网络结构来估计出图像的像素级深度图,再将该深度图作为输入用于3D目标检测任务,[论文][Deep ordinal regression network for monocular depth estimation. CVPR, 2018.]。将估计的深度图与原图像结合,再执行3D检测任务的论文有许多[38,64,36,13]。深度图可以转换成3D点云,这种方法被称为伪激光雷达(Pseudo-LiDAR)[59],或者直接使用[61,65],或者结合图像信息[62,37]来生成3D目标检测结果。基于深度的方法在训练阶段将深度估计从三维目标检测任务中分离,导致还需要学习用于三维检测任务的次佳的深度地图。如何理解上边这句话呢?**对于属于感兴趣的目标的像素,应该优先考虑获取精确的深度信息,而对于背景像素则不那么重要,如果深度估计和目标检测是独立训练的,则无法捕捉到这一属性。**所以将深度估计和目标检测任务融合成一个网络,效果会不会更好呢?
3). 基于网格的方法(Grid-Based Methods)
基于网格的方法通过预测BEV网格表示(BEV grid representation)[48,55],来避免估计用做3D 检测框架输入的原始深度值。具体来说,OFT[48]通过将体素投射到图像平面和采样图像特征来填充体素网格,并将其转换为BEV表示。多个体素可以投影到同一图像特征上,导致特征沿着投影射线重复出现,降低了检测精度。
CaDDN通过端到端的方式,在一个网络中实现深度估计和三维目标检测任务,利用深度估计生成有意义的、精确的鸟瞰表示(BEV representations)和局部特征。
3. Proposed Method
CaDDN通过从图像中获取图像特征,然后将该特征投影到三维空间,来生成BEV表示。然后使用一个高效的BEV检测网络,利用丰富的BEV表示信息来实现三维目标检测。CaDDN的网络结构如下:

该网络由三个模块来生成三维特征表示,一个模块进行3D detection。将图像I生成的Frustum特征G,和估计的深度分布D结合。将其转换为体素特征v,将体素特征堆叠到bird s-eye-view特征B中,用于3D object detection。
3.1 3D Representation Learning
本方法的网络结构学习了对3D目标检测有用的BEV representations。以图像为输入,我们使用估计的categorical depth distributions 构造了一个frustum 特征网格。利用相机参数将frustum特征网格转化为voxel网格,然后堆叠到BEV特征网格中。
Frustum特征网络:
frustum特征网络通过将图像特征与估计深度关联,将图像特征投影到3D空间。该网络输入的是一个图像 I ∈ R W 1 × H 1 × 3 I\in \mathbb{R}^{W_1\times H_1\times 3} I∈RW1×H1×3,W、H是图像的宽和高。输出是frustum特征网格 G ∈ R W F × H F × D × C G \in \mathbb{R}^{W_F\times H_F \times D \times C} G∈RWF×HF×D×C,其中 W F , H F W_F,H_F WF,HF是图像特征表示的宽和高,D是discretized depth bins的个数,C是特征通道的个数。我们注意到frustum网格结构类似于stereo 3D detection方法DSGN[11]中使用的plane-sweep volume。
使用ResNet101[^17]骨干网络提取图像特征 F ~ ∈ R W F × H F × C \widetilde{F}\in \mathbb{R}^{W_F\times H_F \times C} F ∈RWF×HF×C。在我们的实现中,我们从ResNet-101主干的Block1中提取图像特征,以保持高空间分辨率(high spatial resolution)。high spatial resolution对frustum到voxel网格的转换是非常必要的。这样可以在没有任何图像特征的情况下对frustum网格进行精细采样(finely sampled)。
图像特征 F ~ \widetilde{F} F 被用来进行像素级的估计出绝对的深度分布 D ∈ R W F × H F × D D \in \mathbb{R}^{W_F \times H_F \times D} D∈RWF×HF×D,where the
categories are the D discretized depth bins.(这块不太理解)。具体来说就是,我们预测出图像特征 F ~ \widetilde{F} F 每个像素的D概率,where each probability indicates the network’s confidence
that depth value belongs to a specified depth bin. 而depth bin的定义将依赖于在第3.3节中讲的深度离散化方法(depth discretization method)。
我们follow了DeepLabV3[^6]语义分割网络的设计,来从图像特征 F ~ \widetilde{F} F 中估计出绝对深度分布。我们修改了这个网络,产生了属于depth bins的像素级的概率分数,而不是带有downsample-upsample结构的semantic classes。图像特征 F ~ \widetilde{F} F 通过ResNet-101骨干网络的剩余模块(Block2,Block3,和Block4)进行降采样。ASPP模块用来获取多尺度信息,其中输出的通道数设置为D。ASPP模块的输出通过双线性插值向上采样得到原始特征块的大小,然后产生绝对深度分布 D ∈ R W F × H F × D D\in \mathbb{R}^{W_F \times H_F \times D} D∈RWF×HF×D。然后使用softmax函数对每个像素进行归一化,得到0-1之间的概率值。
在估计深度分布的同时,我们对Figure 2中的图像特征 F ~ \widetilde{F} F 进行通道剪枝操作,剪枝后生成最终的图像特征F。使用一个1x1的卷积+BathchNorm+ReLU层,将通道数从256降到64。因为原来的ResNet-101图像特征具有高内存占用的特性,而这个特征是将要填充到3D frustum网格中的,所以进行通道剪枝最好。

我们用 ( u , v , c ) (u,v,c) (u,v,c)来表示图像特征F中每个像素的坐标表示,用 ( u , v , d i ) (u,v,d_i) (u,v,di)来表示绝对深度分布D的像素坐标表示。其中 ( u , v ) (u,v) (u,v)代表每个像素的位置,c代表通道索引, d i d_i di表示depth bin索引。为了生成一个frustum特征网格 G G G,每一个像素特征 F ( u , v ) F(u,v) F(u,v)用depth bin概率 D ( u , v ) D(u,v) D(u,v)来进行计算,填充生成depth axis d i d_i di。可视化过程如上图Figure 3。使用外积的计算方式,公式如下:
G ( u , v ) = D ( u , v ) ⨂ F ( u , v ) G ∈ R W F × H F × D × C G(u, v) = D(u, v) \bigotimes F(u, v) \\ G \in \mathbb{R}^{W_F \times H_F \times D \times C} G(u,v)=D(u,v)⨂F(u,v)G∈RWF×HF×D×C
Frustum到Voxel的转换

如上Figure 4所示,利用已知的相机calibration和differentiable sampling来进行frustum特征 G ∈ R W F × H F × D × C G\in \mathbb{R}^{W_F \times H_F \times D \times C} G∈RWF×HF×D×C到voxel 表示 V ∈ R X × Y × Z × C V \in \mathbb{R}^{X \times Y \times Z \times C} V∈RX×Y×Z×C的转换。每一个体素的中间生成一个采样点 s k v = [ x , y , z ] k T s^v_k = [x,y,z]^T_k skv=[x,y,z]kT,并找到视锥(frustum grid)对应的采样点 S ~ k f = [ u , v , d c ] k T \widetilde{S}^f_k = [u,v,d_c]^T_k S kf=[u,v,dc]kT,其中 d c d_c dc是连续的,沿frustum depth axis d i d_i di。变换是使用摄像机校准矩阵 P ∈ R 3 × 4 P \in \mathbb{R}^{3 \times 4} P∈R3×4来完成的。使用3.3节中介绍的深度离散化方法,将每个连续深度值 d c d_c dc转换为离散深度bin index d i d_i di。
这一步的主要目的是进行视锥到3D空间的映射过程,即对于体素空间中的点 ( x , y , z ) (x,y,z) (x,y,z),找到其在视锥空间中的映射点 ( u , v , d ) (u,v,d) (u,v,d),通过trilinear interpolation获取视锥体网格采样点深度值,将其填充至体素空间。具体的操作过程如上图。
为了进行高效的转换,视锥体网格G和体素网格V的空间分辨率应该相似。高分辨率的体素网格V会导致高密度的采样点,这些采样点会对低分辨率的截锥网格进行采样,从而产生大量类似的体素特征。因此,我们从ResNet-101主干的Block1中提取特征 F ~ \widetilde{F} F ,以确保我们的截锥体网格G具有高空间分辨率(high spatial resolution)。
Voxel到Collapse的转换
直接堆叠体素特征 V ∈ R X × Y × Z × C V \in \mathbb{R}^{X \times Y \times Z \times C} V∈RX×Y×Z×C,就可以得到鸟瞰图特征(BEV Feature) B ∈ R X × Y × C B \in \mathbb{R}^{X \times Y \times C} B∈RX×Y×C。BEV网格在极大的提高了计算性能的同时,也有着跟3D voxel grids相似的检测性能[26]。我们将体素网格V的垂直轴z,沿着通道维度c连接,形成一个BEV网格 B ~ ∈ R X × Y × Z ∗ C \widetilde{B} \in \mathbb{R}^{X \times Y \times Z * C} B ∈RX×Y×Z∗C。BEV也需要通道剪枝,剪枝过程Figure 2所示,使用一个 1x1 的卷积层 + BatchNorm +ReLU layer,在学习到相关特征的同时,使得通道数回归到原来的C,得到BEV网格 B ∈ R X × Y × C B \in \mathbb{R}^{X \times Y \times C} B∈RX×Y×C 。
3.2 BEV 3D Object Detection
我们采用PointPillars[26]中的骨干网络和BEV 3D object detector结构,因为此结构已经展示了其良好的3D检测精度和较低的计算量,因此我们采用此结构对BEV特征网格进行3D目标检测任务。(在生成的鸟瞰图上执行3D目标检测,并对PointPillar的网络结构进行了一定的调整,最终完成检测过程。)在BEV的backbone中,我们增加降采样模块中3x3 convolution+BathchNorm+ReLU层中卷积层的数量,依次对Block1、Block2、Block3从原来的(4,6,6)增加到(10,10,10)。增加卷积层的数量可以提高BEV网络学习能力,与最初由激光雷达点云生成的高质量特征相比,从图像生成的低质量特征中学习很重要。我们使用与PointPillars[26]相同的检测头来生成最终的检测。
3.2 Depth Discretization(深度离散化?)
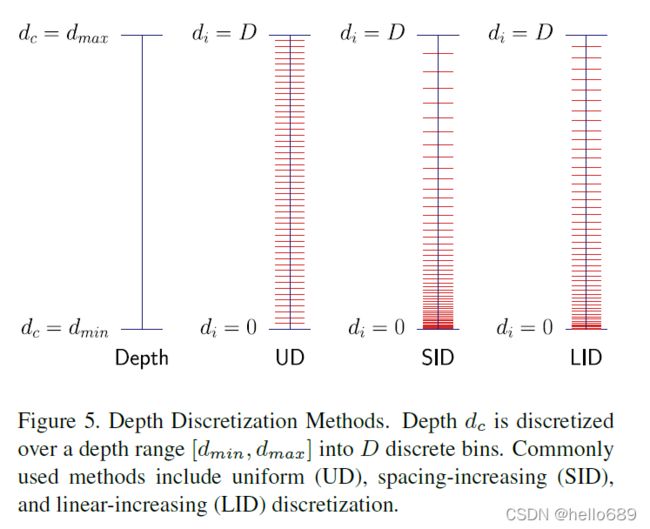
如何定义Depth bin?为了定义深度分布 D D D中使用的D个集合的bins,我们将连续的深度空间值离散化处理。文章的特点就是如何对深度进行网格化的估计,因此作者给出了深度网格的监督,其实核心方法是如何将连续值离散化。这里作者给出了三种离散方式 :
- 均匀离散(uniform discretization,UD):fixed bin size,等间距离散;
- 间距增加的离散( spacing-increasing discretization,SID):increasing bin sizes in log space,即间距按对数值离散;
- 线性增加的离散化(linear-increasing discretization,LID):linearly increasing bin sizes, 即间距线性增加离散。
作者采用了LID的方式,因为这种方式提供了在all depthes上的的均衡深度估计。LID的定义如下:
d c = d m i n + d m a x − d m i n D ( D + 1 ) ⋅ d i ( d i + 1 ) d_c = d_{min} + \frac{d_{max}-d_{min}}{D(D+1)}\cdot d_i(d_i+1) dc=dmin+D(D+1)dmax−dmin⋅di(di+1)
其中 d c d_c dc是连续的深度值, [ d m i n , d m a x ] [d_{min},d_{max}] [dmin,dmax]是将要被离散化的深度范围,D是depth bins的数量, d i d_i di是depth bin的索引。
3.4 Depth Distribution Label Generation(深度分布标签生成)
我们需要一个深度分布标签 D ~ \widetilde{D} D 来监督我们预测的深度分布。将激光雷达点云投影到图像帧中生成深度分布标签,生成稀疏稠密地图。Depth completion[20]用来生成图像中每个像素的深度值。我们需要图像特征中每个像素的深度信息,因此我们将深度图进行降采样,将其尺寸从 W I × H I W_I \times H_I WI×HI降到图像特征的尺寸 W F × H F W_F \times H_F WF×HF。使用3.3节中介绍的LID离散化方法,将深度图转换成bin indices,然后转换为one-hot编码以生成深度分布标签。one-hot编码确保深度分布标签的清晰度,这对于通过监督提高深度分布预测的清晰度至关重要。
3.5 Training Losses
一般来说,分类是通过预测概率分布的形式来得到分类结果的,为了得到更精确的分类结果,还会来增强分布的sharpness。关于深度信息的损失函数设计如下:

D D D是深度分布预测结果, D ~ \widetilde{D} D 是深度信息的label。因为自动驾驶的图像数据中,一般目标对象的像素个数是多于背景像素的个数的。也就是样本不均衡的问题,因此使用focal loss。其中,前景目标像素的 α \alpha α值设为3.25,背景目标像素的 α \alpha α值设置为0.25。前景像素是2D检测框中的像素,背景像素就是剩余的像素。设定focal loss的focusing parameter Υ = 2.0 \Upsilon = 2.0 Υ=2.0。
我们使用PointPillars中的分类损失、回归损失、方向分类损失方法来进行3D目标检测任务。总的损失函数为:

这几个 λ \lambda λ值都是人工设定的fixed权值。分别是3.0、1.0、2.0、0.2
4. Experimental Result
Training and Inference Details
KITTI数据集中的,训练集(training samples 7481)和测试集(testing samples 7581),其中训练集又被划分为训练set和验证set,样本数为3712 samples和3769 samples。
voxel grid的定义:范围是 [ 2 , 46.8 ] × [ − 30.08 , 30.08 ] × [ − 3 , 1 ] [2, 46.8] \times [-30.08, 30.08] \times [-3, 1] [2,46.8]×[−30.08,30.08]×[−3,1], 另外x,y,z轴的voxl size为[0.16, 0.16, 0.16] m.
adam优化器,初始值为0.001;
λ \lambda λ分别是3.0、1.0、2.0、0.2;
推理细节
boxes threshold是0.1, apply non-maximum suppression (NMS) with an IoU threshold of 0.01。
4.1 KITTI Dataset Results
使用average precision(AP|R40)标准进行评估,其中Car 类IoU标准是0.7,Cyclist和Pedestrian是0.5。跟MonoPair和MonoPSR做了对比,精度得到了提升。
4.3 Ablation Studies
通过消融实验来验证效果:


发现了已经有博主对这篇文献进行了翻译工作,这里列一下,后边我就不翻译了。
CaDDN翻译
5.总结
端到端的网络结构,使得训练起来相对简单,没有额外的几何约束,有点搭积木的感觉。这种设计使得不能侧重某一方面,就是把深度估计、2d检测、3d检测放一起,炖大锅菜的感觉。只能通过损失函数的权重来进行一些侧重倾向,但这种侧重能起到核心平衡作用吗?能否把残差的理念引入网络结构中?以减少网络模块间的误差传递。
6.代码调试
博客链接