【论文笔记】SA-LOAM:Semantic-aided LiDAR SLAM with Loop Closure
【论文笔记】SA-LOAM:Semantic-aided LiDAR SLAM with Loop Closure
~~~ ~~~~ 基于 LiDAR 的 SLAM 系统无疑比其他系统更准确和稳定,但其回环检测仍然是一个悬而未决的问题。随着点云3D语义分割的发展,可以方便、稳定地获取语义信息,对于高级智能至关重要,也有利于SLAM。本文提出了一种基于 LOAM 的具有回环闭合的新型语义辅助 LiDAR SLAM,名为 SA-LOAM,它利用了里程计中的语义以及回环检测。具体来说,我们提出了一种语义辅助 ICP,包括语义匹配、下采样和平面约束,并在回环检测模块中集成了基于语义图的位置识别方法。受益于语义,本文提高了定位精度,有效检测闭环,即使在大规模场景中也可以构建全局一致的语义图。在 KITTI 和 Ford Campus 数据集上进行的大量实验表明,与最先进的方法相比,我们的系统显着提高了基线性能,具有对未知数据的泛化能力,并取得了有竞争力的结果。
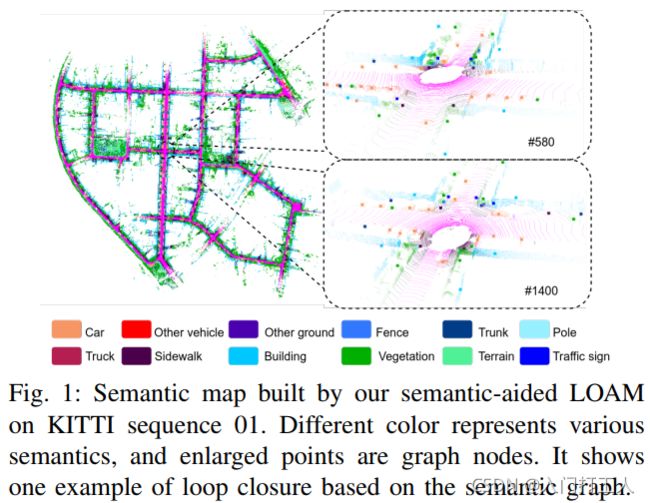
本文提出了 SA-LOAM,一种新颖的基于语义辅助 LOAM 的具有回环闭合的 SLAM 系统。具体来说,在名为 FLOAM [18] 的开源基于 LOAM 的 SLAM 系统上构建了一个语义辅助的 ICP 和基于语义图的回环检测模块。在语义辅助 ICP 中,实现了基于语义的聚类、下采样和平面约束,以减少错误匹配,平衡效率和准确性,并去除错误的平面特征以提高配准质量。本文的闭环检测模块基于之前的工作 [16],它将 3D 场景转换为语义图,并通过图匹配网络获得场景相似度。将其与循环候选生成、几何验证相结合,并维护一个轻量级语义图,以实现高效和稳健的循环闭合检测。图 1 是结果的演示,本文的贡献总结如下:
• 我们提出了一个完整的基于 LiDAR 的语义 SLAM 系统,即使在大规模场景中也可以构建全局一致的语义地图。
• 我们提出了一种基于LOAM 的语义辅助ICP 方法,它充分利用了语义并提高了里程计的准确性。
• 我们在我们的系统中集成了一种基于语义的闭环检测方法,并维护了一个图形映射,以有效地检测闭环并消除累积错误。
• 在 KITTI 和 Ford Campus 数据集上的实验表明,与最先进的方法相比,我们的系统实现了具有竞争力的性能,并且通常可以大幅度提高基线的准确性。
方法
系统总览
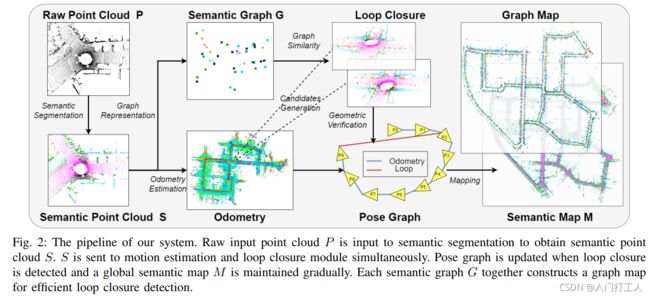
~~~ ~~~~ 在这一部分中,我们对提出的语义辅助激光雷达 SLAM 系统进行了全面介绍。与现有的方法[3],[14]不同,这些方法侧重于在注册中融合语义,我们探索了更多语义在我们的系统中的使用,主要包括语义辅助ICP III-B和基于语义图的闭环检测III- C。图 2 是我们方法的流程。原始点云P首先被发送到现成的语义分割方法[7]-[13]中,以获得具有逐点类标签 l ∈ L l \in L l∈L的语义点云S,L是语义类别的数量。然后将 S 发送到里程计估计模块以提取平坦的平面特征和锐利的边缘特征,这些特征稍后用于通过注册到本地地图来估计里程计。同时将语义点云S转化为语义图表示G,进一步输入到闭环检测模块。当检测到闭环时,我们将更新姿势图并优化姿势。因此,我们可以逐步获得高质量的全局语义图 M。
语义辅助ICP
~~~ ~~~~ LOAM 使用边缘和平面特征来配准点云,实现准确快速的定位和映射。我们用语义信息扩展了该方法,具体改进如下:
• 首先,受 SE-NDT [22] 的启发,我们将特征分别通过语义标签和注册进行划分,降低了错误匹配的概率。
• 其次,我们根据语义标签分别对点云进行下采样。大多数现有方法通过体素网格过滤对点云进行下采样以提高效率。但是,一些包含有用信息的小对象不可避免地会被过滤掉。我们基于语义的下采样对不同类型的对象使用不同的采样率,可以有效地维护小对象的信息,如图 3 所示。
• 第三,我们利用语义来约束平面拟合。基于地平面应平行于水平面并垂直于建筑表面的假设,我们可以去除拟合不佳的平面。
特征提取:我们采用了 LOAM [1] 的特征提取策略。具体来说,我们从点云中提取边缘和平面特征,并通过以下方式计算每个点的粗糙度
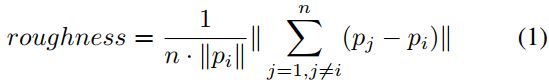
其中 pi 代表目标点,边缘特征和 Np 个最平坦点作为每个部分的平面特征。最后,我们得到整个目标帧的边缘特征点 Ce 和平面特征点 Cp。
运动估计:为了估计激光雷达的自我运动,我们最小化目标边缘特征点到其对应线的距离以及目标平面特征点到其对应平面的距离。由于不同的语义类具有不同的含义,这些含义应该有助于区分定位,因此我们将与语义相关的权重 wl 附加到每个错误项。我们的总优化目标是:pj 在同一个环中。然后,使用阈值 α 将这些点划分为边缘点(粗糙度大于 α)和平面点(粗糙度小于 α)。为了均匀采样,每个环被分成 Nr 个部分。我们选择 Ne 最尖锐的点作为

其中 d e i l d^l_{ei} deil 是第 i 个边缘特征点 c e i l ∈ C e c^l_{ei} \in C_e ceil∈Ce 到其对应直线的距离, d p j l d^l_{pj} dpjl 是第 j 个平面特征点 c p j l ∈ C p c^l_{pj} \in C_p cpjl∈Cp 到其对应平面的距离, l ∈ L l \in L l∈L是目标特征点的语义标签, w l w^l wl是语义相关的权重。
我们首先使用最近Nm帧的边缘特征点Ce和平面特征点Cp建立边缘特征子图Me和平面特征子图Mp。为了加快配准,我们对子图Me进行下采样;和目标点云Ce; CP;根据它们的语义标签。图 3 描绘了我们的下采样策略的可视化。然后通过将下采样的特征点云与子图配准来估计里程计。具体来说,给定一个边缘特征点 c e i l ∈ C e c^l_{ei} \in C_e ceil∈Ce 及其语义标签 l ∈ L l \in L l∈L,我们选择一个语义边缘子图 { M e l ∣ M e l ⊂ M e , l ∈ L } \{M_e^l | M_e^l ⊂ M_e,l \in L\} {Mel∣Mel⊂Me,l∈L}; 具有相同的语义标签 l。我们使用 kd-tree 找到距离目标点最近的 Nne 个点作为对应点。这些Nne个点用来拟合一条直线,以目标点到对应直线的距离作为优化目标。假设 m e 1 l , m e 2 l ∈ M e l m_{e1}^l, m_{e2}^l \in M_e^l me1l,me2l∈Mel 是直线上两个不同的点,目标点到直线的距离可以计算如下:
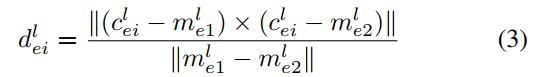
类似地,给定一个平面特征点 c p i l ∈ C p c^l_{pi} \in C_p cpil∈Cp,我们在其对应的语义子图 M p l M_p^l Mpl 中找到Nnp 个最近点。然后我们使用这些 Nnp 点来拟合一个平面。如果它们的法线是垂直的,我们将保留地平面,如果它们的法线是水平的,我们将保留建筑平面。通过此约束,可以移除拟合不佳的平面。假设 m p 1 l , m p 2 l , m p 3 l ∈ M p l m_{p1}^l,m_{p2}^l,m_{p3}^l\in M_p^l mp1l,mp2l,mp3l∈Mpl 是平面上三个不同的点, c p i l c^l_{pi} cpil 到平面的距离为:
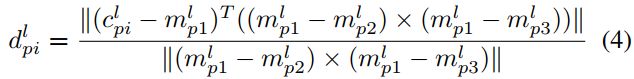
基于语义的循环闭合检测
~~~ ~~~~ 我们的回环检测模块主要由回环候选生成、相似度评分、几何验证和姿态图优化组成。候选生成部分根据里程计提出潜在的循环候选。相似性评分基于我们之前的工作 [16],它通过图相似性网络快速估计对语义图的相似性,对遮挡和视点变化具有鲁棒性。然后,几何验证使用 ICP 来排除可能的错误建议,避免灾难性的假阳性闭环。最后,通过位姿图优化更新更准确的位姿。
循环候选生成:给定当前帧点云,将其与所有其他点云帧进行比较非常耗时。因此,根据里程计,更接近当前位置的帧是首选。具体来说,保持与当前帧的距离小于 δd m 的帧距离,其定义为:
![]()
其中σ是一个常数,代表里程计的漂移率,d代表候选帧和当前帧之间的行进距离。 δmax 和 δmin 是 d 的上限和下限,因为 d 在运动中不断增加。我们最多选择 Ncandi 候选人。如果通过等式过滤的候选数量。 5 大于 Ncandi,我们将从他们中随机选择 Ncandi 候选者。由于累积误差的存在,随机选择比选择最接近当前帧的帧更合理。当然,还可以尝试更多的采样策略。
相似度评分:我们采用我们之前的基于语义图的位置识别方法 [16] 来计算场景对之间的相似性分数,该方法运行速度快,重量轻且鲁棒。我们首先将语义点云 S 聚类为语义图表示 G,将其与其对应的位姿一起保存在全局语义图图中以供重用。请注意,每个语义图最多仅占用 100x4 个浮点数(每帧最多 100 个节点,中心坐标为 x、y、z 和语义标签)[16],可以高效存储和读取。根据循环候选生成提出的候选,我们方便地索引语义图图中所有对应的语义图,并创建一批语义图对。这些图对由图匹配网络 [16] 并行处理以获得相似度分数。我们保留分数大于 ζ 的对,并从保留的对中选择分数最高的 Nloop 作为最终候选。
几何验证。通常,根据相似度选出的候选循环不一定正确。因此,我们需要检查当前点云和候选点云的一致性。与里程计模块 IIIB 类似,我们在候选点云附近使用连续扫描来构建子图,并使用语义辅助 ICP 将当前点云与子图配准。如果方程中的 ICP 损失 r 2 大于 δr,我们认为这个候选是假阳性并丢弃它。
姿势图优化。当我们找到一个循环闭包时,我们构建一个姿势图并使用 g2o [43] 对其进行优化。假设每一帧点云对应的pose为 { T 0 ; T 1 ; ⋅ ⋅ ⋅ ; T n ∣ T i ∈ S E 3 } \{T0; T1; · · · ; Tn|Ti \in SE3\} {T0;T1;⋅⋅⋅;Tn∣Ti∈SE3},帧i和帧j之间的误差函数为
![]()
其中 Zij 表示从几何验证模块获得的第 i 帧和第 j 帧之间测量的相对位姿。 优化后,我们为每一帧获得了更准确的姿态,它们有助于构建全局一致的语义图 M。
实验
~~~ ~~~~ 在本节中,设计实验来证明(1)语义辅助 ICP 可以有效提高测距精度,(2)基于语义的回环检测模块可以有效地减少累积误差并帮助建立全局一致的地图,( 3)系统具有对看不见的数据的泛化能力。
数据集和实现细节
~~~ ~~~~ 在 KITTI Odometry Benchmark [20] 和 Ford Campus Vision and Lidar Dataset [44] 上评估本文的方法。 KITTI Odometry Benchmark 由 11 个序列 (00-10) 和真实轨迹组成,Ford Campus 数据集包含两个序列 (01-02)。尽管这两个数据集都是使用 Velodyne HDL-64E 收集的,但两个数据集的数据分布却大不相同,因为 KITTI 是在德国收集的,而 Ford 是在美国收集的。
我们选择开源工作 FLOAM [18] 作为我们的系统基线。在语义分割中,我们使用 RangeNet++ [7] 的预训练模型 1 来执行符合 SUMA++ [14] 的语义分割,以进行公平比较。我们采用的 RangeNet++ 和基于语义图的闭环检测方法 [16] 都是在 PyTorch [45] 上实现的。 RangeNet++ 在 SemanticKITTI [46] 上进行训练,输出 19 个语义类,我们根据 [16] 保留了 12 个类,如图 1 所示,去掉了人、行人等无用的语义。我们在配备 16 GB RAM 的 Intel Core i7-9750H @3.00GHz 和配备 8 GB RAM 的 Nvidia GeForce GTX1080 GPU 上测试我们的方法。表中列出了我们设置的参数。 I. 与语义相关的权重 wl 在我们的实验中是平等定义的,我们希望在未来找到一种合理的自动权重设置方式。请注意,我们无意进行详尽的参数选择,我们相信微调会带来一定的改进。
为了评估每个提议的组件如何有助于提高性能,我们分别展示了基于语义辅助里程计 III-B(Ours-ODOM)的姿势和通过闭环 IIIC(Ours-LOOP)进一步优化后的姿势。此外,我们将我们的方法与几种最先进的纯基于 LiDAR 的 SLAM 方法进行比较,例如 LOAM [1]、[19]、FLOAM [18](我们的基线)、SUMA [15]、SUMA++ [14]和 ISC-LOAM [33]。由于 LOAM [19] 的代码不可用,我们直接引用论文中的结果,而 FLOAM2、ISCLOAM3、SUMA4 和 SUMA++5 的结果是使用他们的开源代码获得的。
KITTI 里程计基准
~~~ ~~~~ 相对位姿误差:为了评估里程计的准确性改进,我们在 KITTI Odometry Benchmark 上进行测试,并使用平均相对姿态误差 (mRPE) 作为指标。
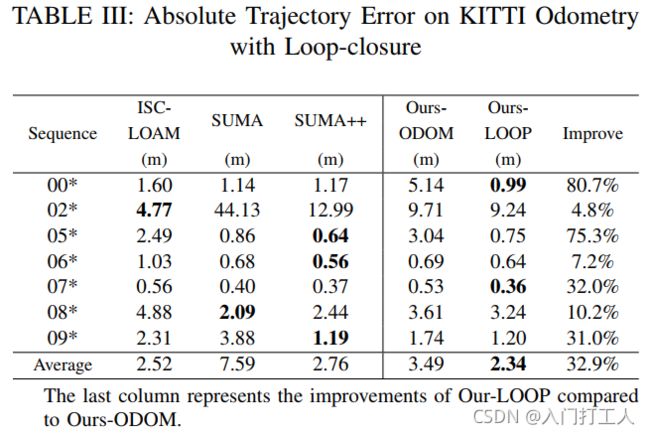
表II 显示了在 KITTI Odometry Benchmark 上的实验结果。与基线方法 FLOAM 相比,我们的方法大大提高了里程计的准确性。在现有的基于 LOAM 的方法中,LOAM 具有最高的精度,我们的方法在大多数序列上都超过了 LOAM。 SUMA 和 SUMA++ 是基于面元的,而 SUMA++ 是最先进的基于语义的方法。与SUMA++相比,我们的方法在00、02、05、08等长距离序列上有更好的性能。注意序列00、02、05、06、07、08、09有循环,Ours-LOOP一般表现更好比 OursODOM 毫不意外。此外,我们发现回环优化可以显着降低大多数序列的相对旋转误差,而对相对平移误差的影响较小,这意味着旋转误差对轨迹的不一致性影响更大。
绝对轨迹误差:为了评估减少累积误差和建立全局一致地图的能力,我们进一步评估绝对轨迹误差 (ATE) 并给出定性结果。
在表III中,我们发现 Ours-LOOP 在每个序列上都比 Ours-ODOM 有很大的改进,尤其是在序列 00 和 05 上,Ours-LOOP 分别将 ATE 降低了 80.7% 和 75.3%。与 ISC-LOAM、SUMA、SUMA++ 等最先进的基于 LiDAR 的闭环检测方法相比,Ours-LOOP 在大多数序列上的 ATE 更小,平均优于其他方法。
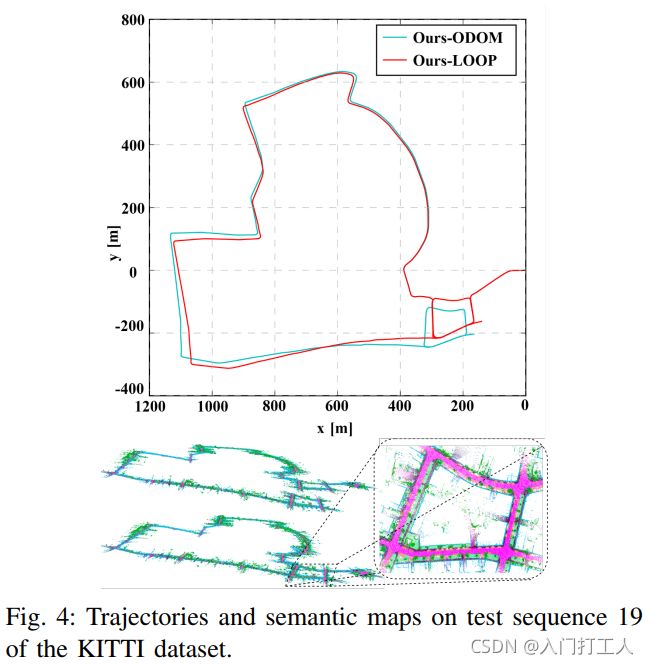
图 4 显示了循环闭合前后 KITTI 数据集测试序列 19 上的轨迹和语义图。该轨迹的起点和终点之间存在全局闭环。由于里程计的累积误差,Ours-ODOM 生成的轨迹在起点和终点附近不一致。相比之下,OursLOOP 可以检测这些循环并消除里程计的累积误差,以生成一个全局一致的地图,如图 4 所示。

福特校园视觉和激光雷达数据集
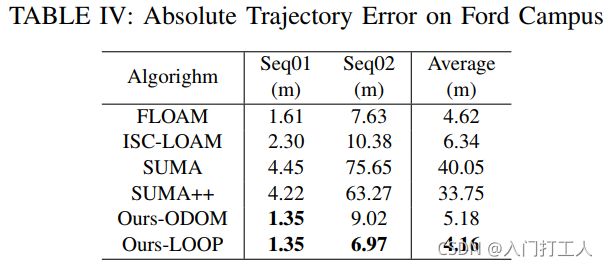
~~~ ~~~~ 为了验证对未知数据的泛化能力,我们在福特校园数据集 [44] 上进行了实验,并评估了 RTE 和 ATE。我们方法中使用的所有模型都在 KITTI 上进行了预训练,并且在训练阶段从未见过福特的数据。
图 5 显示了 Ford 数据集序列 01 上的相对平移误差。由于所有方法的参数都在 KITTI 上进行了调整,因此它们通常在 Ford 上表现更差。然而,基于 SUMA 的方法受到更严重的影响,因为我们发现由于不同的传感器设置,投影图像比 KITTI 上的更稀疏。在所有方法中,OursLOOP 实现了最小的相对误差。
标签。 IV 显示了 ATE,Ours-LOOP 在两个序列上都优于其他序列。更重要的是,在所有方法中,只有Ours-LOOP成功纠正了图6所示的闭环。 注意Ford上的语义分割比KITTI上的差很多,如图7所示,这将不可避免地影响后续的性能. SUMA++ 和我们的方法使用相同的语义,而我们的方法更一致,受益于语义图表示。