决策树——从理论到入手
决策树——从理论到入手
- 决策树
-
- 基本知识点
-
- 基本概念
- 分析与思考
- 决策树前提知识点
-
- 信息增益、增益率、基尼指数
-
- 信息增益(ID3)
- 增益率(C4.5)
- 基尼指数(CART)
- 剪枝处理
-
- 预剪枝
- 后剪枝
- 代码
-
- 伪代码(基本算法)
- 利用sklearn实现决策树——以鸢尾花数据集为例
- 代码底层实现
- 总结
-
- 优缺点
决策树
基本知识点
基本概念
定义:决策树是一类常见的机器学习方法,是一种描述对实例进行分类的树形结构。(给定的实例具有一系列特征,根据这些特征进行判断结果)
描述:决策树由结点和有向边组成。结点可分成:根结点、内部结点、叶结点
根节点:样本全集
内部结点:一个特征或一个属性测试
叶节点:决策结果
判定测试序列:从根节点到每个叶结点的路径对应了一个判定测试序列
目的:产生一颗泛化能力强,即处理未见示例能力强的决策树。
分析与思考
现以西瓜书中如何判断好瓜还是坏瓜的决策树进行理解:
西瓜数据集:
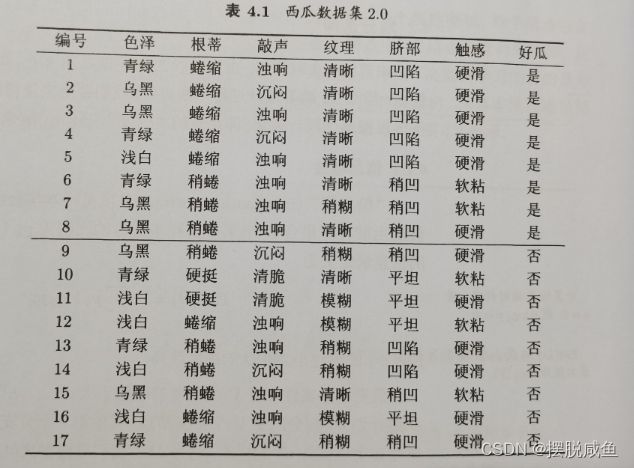
西瓜决策树图:

看到上面的数据集以及生成的决策树,我们便会发现以下的一些问题:
- 这不就是if-else吗,为什么要那么麻烦呢?
- 西瓜决策树第一次为什么是根据纹理来判断?
- 西瓜决策树为什么在第二层判断触感,在第四层树中又有判断触感这一特征呢?
- 在数据集中,有敲声和脐部这两个特征,为什么在决策树中没有体现呢?
- 西瓜数据集的大小对决策树会有怎样的影响呢?
首先先说一下第一个问题:这不就是简单的if-else就可以完成的吗?
首先,决策树的起源就是这么质朴,就是来源于数据机构中的分支结构if-else,之所以要采用树形结构是因为它带来了效率的提高,并且可以有效的让我们进行优化得到一个不错的结果。
然后,请您带着以上的问题接着往下看,我将为您竭尽全力的帮助您了解决策树。
决策树前提知识点
信息增益、增益率、基尼指数
针对上述第二问:西瓜决策树第一次为什么是根据纹理来判断?那肯定是因为纹理可以帮我们更好的辨别哪一个是好瓜还是坏瓜。
决策的目的是为了更好的分类,如果所有的特征带给我们的结果都是50%是好瓜、50%是坏瓜,那决策没有任何意义,买任何一个西瓜,都只存在这两种情况(非好即坏),所以我们的决策树从根结点到叶结点的决策类肯定是越来越低的,毕竟我们追求的就是:通过最短的判定测试序列准确的判断我们选的西瓜是好瓜还是坏瓜。
由此,我们可以知道,决策树学习的关键在于——如何选择最有划分属性。
接下来就介绍三种经典的属性划分方法:
信息增益(ID3)
想要了解信息增益,你需要先知道什么是信息熵。
信息熵
定义:度量样本集合纯度最常用的一种指标。假定当前样本集合D中第K类样本所占比为pk(K = 1,2,3,4…|y|),则D的信息熵
E n t ( D ) = − ∑ k = 1 ∣ y ∣ p k log 2 p k Ent(D) = -\sum_{k=1}^{|y|} p_{k}\log_{2}{p_{k}} Ent(D)=−k=1∑∣y∣pklog2pk
- pk是分类的结果数,如果是二分类就是|y| = 2,在西瓜样例中就是好瓜和坏瓜
- 单位:bit
- Ent(D)值越小,D的纯度越高
- p = 0,则plogp = 0(约定)
- Ent(D)最小值为0,最大值为log|y|
当了解完信息熵,我们便可以了解一下信息增益了。
信息增益:
离散属性a有V个可能的取值{
,
, …,
},用a来进行划分,则会产生V个分支结点,其中第v个分支结点包含了D中所有在属性a上取值为
。
直白的讲:哪一个特征色泽出来(以西瓜判别为例),有青绿(6/17)、乌黑(6/17)、浅白(5/17)三种,分别计算这三者的信息熵,然后进行按比例累加求和。
则可计算出用属性a对样本集D进行划分所获得的信息增益:
G a i n ( D , a ) = E n t ( D ) − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ E n t ( D v ) Gain(D, a) = Ent(D) - \sum_{v=1}^{V}\frac{|D^{v}|}{|D|} Ent(D^{v} ) Gain(D,a)=Ent(D)−v=1∑V∣D∣∣Dv∣Ent(Dv)
一般而言:信息增益越大,实用属性a进行划分所获得的“纯度提升”越大。(直接点说就是:你的信息增益越大,那么使用它先分类的可能性越大。)
但是存在一个问题:
数据集中一般有一个“编号”(可以往上翻一下,看一些截图),如果把他也作为一个候选划分属性,那么它的信息增益会比其他属性大。
每一个编号(1、2、3…|y|)都是“编号”组中的实例,|y|个分支,故每个编号的信息熵如下:
E n t ( D v ) = ( − ( 1 log 2 1 + 0 log 2 0 ) ) Ent(D^{v}) = (-(1\log_{2}{1} + 0\log_{2}{0})) Ent(Dv)=(−(1log21+0log20))E n t ( D v ) = 0 Ent(D^{v}) = 0 Ent(Dv)=0
大家可以试着计算以下(这里不做过多赘述),由信息增益公式可知“ Ent(D) - 0 ”时,是信息增益最大的时候了。
注意:这里0不在对数函数的定义域,但是这是一个约定俗成的,所以不必太纠结其数学含义。
由此可见——信息增益对取值数目较多的属性有所偏好!
在遇到这种情况,提出了一个新的概念,叫做——增益率。
增益率(C4.5)
公式:
G a i n r a t i o ( D , a ) = G a i n ( D , a ) I V ( a ) Gain_ratio(D, a) = \frac{Gain(D, a)}{IV(a)} Gainratio(D,a)=IV(a)Gain(D,a)
I V ( a ) = − ∑ V v = 1 ∣ D v ∣ ∣ D ∣ log 2 ∣ D v ∣ ∣ D ∣ IV(a) = -\sum_{V}^{v=1}\frac{|D^{v}|}{|D|} \log_{2}{\frac{|D^{v}|}{|D|}} IV(a)=−V∑v=1∣D∣∣Dv∣log2∣D∣∣Dv∣
IV(a):称为属性a的固有值,属性a的可能取值越多,那么IV(a)通常越大。
从增益率的公式来看,增益率准则对可取值数目较少的属性有所偏好。
划分属性方式:先从候选划分属性中找出信息增益高于平均水平的属性,在从中选择增益率最高的。
基尼指数(CART)
基尼值定义:假设D有K个类,样本点属于第k类的概率为pk,则概率分布的基尼值定义为:
G i n i ( D ) = ∑ k = 1 K p k ( 1 − p k ) = 1 − ∑ k = 1 K p k 2 Gini(D) = {\textstyle \sum_{k=1}^{K}}p_{k}(1-p_{k}) = 1- {\textstyle \sum_{k=1}^{K}}p_{k}^2 Gini(D)=∑k=1Kpk(1−pk)=1−∑k=1Kpk2
作用:反映了随机抽取两个样本,其类别标记不一致的概率注:Gini(D)越小,数据集D的纯度越高
给定数据集D,属性a的基尼指数定义为:
G i n i i n d e x ( D , a ) = ∑ v = 1 V ∣ D v ∣ ∣ D ∣ G i n i ( D v ) Gini_{index}(D,a) = {\textstyle \sum_{v=1}^{V}}\frac{|D^v|}{|D|}Gini(D^v) Giniindex(D,a)=∑v=1V∣D∣∣Dv∣Gini(Dv)
划分策略:在候选属性集合A中,选择那个使得划分后基尼指数最小的属性作为最优划分属性
相信看到这里,很多人也对问题三:“ 西瓜决策树为什么在第二层判断触感,在第四层树中又有判断触感这一特征呢? ”有了答案
因为每次通过上面三种划分方式得到的最优效果是变化的,在第二层纹理稍糊的情况下可以通过触感直接判断瓜的好坏。而在另一个决策序列可能就是需要先判断其他的才能更准确的确定瓜的好坏。
剪枝处理
为什么要减枝?
对付决策树学习算法中的“ 过拟合 ”现象。
剪枝策略有那些?
- 预剪枝:在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能的提升,则停止划分并将当前结点标记为叶结点。
- 后剪枝:先从训练集中生成一棵完整的决策树,然后自底向上的对非叶结点进行考察,若将该结点对应的子树替换成叶结点能带来决策树泛化性能的提升,则将该子树替换为叶结点。
怎么判断减枝后的性能?
- 留出法:预留一部分数据用作“ 验证集 ”,以进行性能评估。
接下来看一下西瓜书上是如何进行的:
首先是数据准备,双横线上的是训练集,双横线下的是留出法的验证集。

根据上图生成的决策树如下:

预剪枝
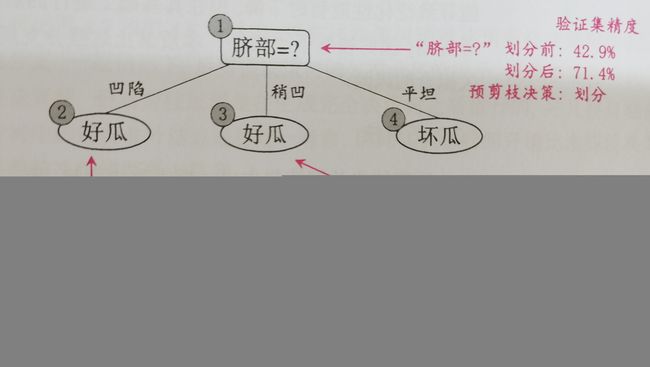
相信你看到这幅图的时候已经有灵感了:这不就是我把我验证集拿进去试吗,然后看划分前后划分后的验证集的精度吗。那他步骤是啥呢?
- 从根 - - - > 叶
- 首先,根据决策,把自己的子节点变成一个确切的分类结果(例如:脐部凹陷中有10个数据,7个好的,3个坏的,就把这个子节点看作好瓜来分析)
- 然后将验证集数据放进去验证,如果划分前的精度 < 划分后的精度,那么就需要划分。
- 根节点划分前精度由验证集来决定,直接判断标签进行简单的二分类。
- 子节点的划分前精度是其父节点的验证精度。
作用:
- 使很多的分支没有“ 展开 ”,降低了过拟合的风险,还减少了决策树的训练时间开销和测试时间开销。
- 在预剪枝的基础上有利于后续划分使性能提高。
缺点:有可能带来欠拟合的风险。
后剪枝
流程如下:
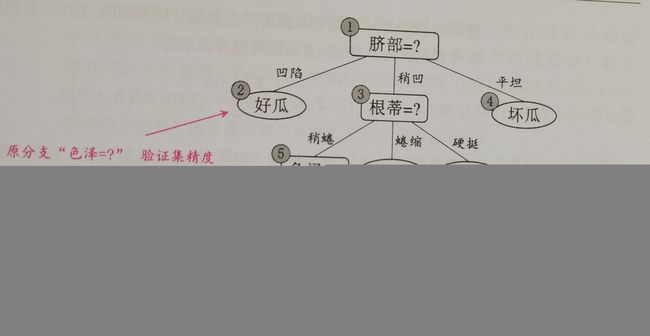
步骤:
- 从叶 - - - > 根
- 首先,将一个内部结点变成叶结点,然后根据训练数据集中,该判断序列的分类结果,将分类结果大的作为叶节点。
- 然后判断剪枝前后的精度,如果剪枝后的精度 > 剪枝前的精度,那么就剪枝。
- 最先进行的叶子结点的验证精度由验证集控制。
- 父节点的剪枝后的精度由训练集决定。
作用:
- 较预剪枝保留了更多的分支。
- 欠拟合风险较小,泛化能力较预剪枝好。
- 训练开销比未剪枝和预剪枝的开销大得多。
代码
伪代码(基本算法)
输入:训练集D={(x1, y1),(x2, y2),.. . , (xm,ym)};
属性集A= {a1, a2,.. . , ad}
过程:过程:函数TreeGenerate(D, A)
1:生成结点node;
2: if D中样本全属于同一类别C then
3: 将node标记为C类叶结点;return
4: end if
5: if A = 空集 OR D中样本在A上取值相同 then
6: 将node标记为叶结点,其类别标记为D中样本数最多的类; return
7: end if
8: 从A中选择最优划分属性a*;
9: for a*的每一个值a*' do
10: 为node 生成一个分支;令Dv表示D中在a*上取值为a*'的样本子集;
11: if Dv为空 then
12: 将分支结点标记为叶结点,其类别标记为D中样本最多的类; return
13: else
14: 以 TreeGenerate( Dv, A\{a*})为分支结点
15: end if
16: end for
输出:以node为根结点的一棵决策树
由上图可知:决策树是一个递归过程,有以下三种情况会导致递归返回:
- 1、当前结点包含的样本全属于同一类别,无需划分。
- 2、当前属性集为空,或所有样本在所有属性上取值相同,无法划分。
- 3、当前结点包含的样本集合为空,不能划分。
利用sklearn实现决策树——以鸢尾花数据集为例
# 决策树分类器
sklearn.tree.DecisionTreeClassifier(criterion = , max_depth= , random_state =)
# criterion:默认是gini指数,也可以选择其他的,例如信息熵:"entropy"
# max_depth:树的深度
# random——state:随机数种子
# 决策树可视化,导数DOT格式
sklearn.tree.export_graphviz(estimator, out_file='*.dot', feature_names=[","])
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from six import StringIO
import pydotplus
def decisiion_iris():
iris = load_iris()
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
estimator = DecisionTreeClassifier(criterion="entropy")
estimator.fit(x_train, y_train)
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比较真实值和预测值:\n", y_test == y_predict)
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
# 可视化
dot_data = StringIO()
export_graphviz(estimator, out_file=dot_data)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
# 将结果存入到png文件中
graph.write_png('diabetes.png')
graph.write_pdf('diabetes.pdf')
# 显示
Image(graph.create_png())
return None
生成.dot文件,并且将.dot文件转换成png格式和生成pdf文件
其生成的png文件为:
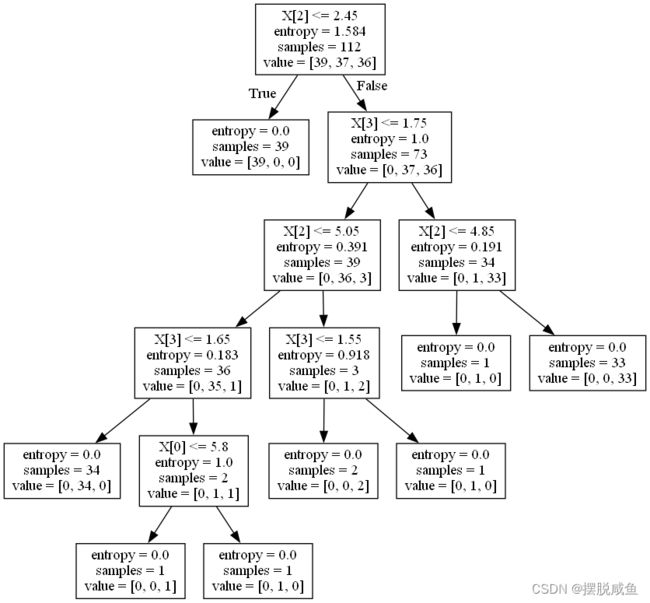
注:想要生成pdf文件和png图片的话,必须下载
windows_10_cmake_Release_graphviz-install-7.0.1-win64,别试着用pip和conda进行下载,因为这需要配置环境,没有啥用,下载链接:点这里 | Graphviz最好在下载期间直接点击帮忙添加路径,安装过程不做过多的介绍。
下载好了之后便可以进行打印输入,如果有报错也可以先去看一下自己环境变量是否安装,并且可以通过cmd进入.dot/pdf文件中进行命令行操作。将dot文件转换成png图片
dot -Tpng *.dot -o *.png。
代码底层实现
通过对《机器学习实战》一书以及参阅别人的代码进行了一次决策树的代码。
数据集内置在代码中,原因是因为我的文件都进去一直报错
Keyerror:list indices must be integers or slices, not str原因是什么我也还不知道,待解决。数据集有三个特征:
数据集解释:
通过建立’气温’, ‘赖床人数’, '饿不饿’三个特征,其中 (气温:3热,2适中,1冷); 饥饿程度:(1饿, 0不饿)进行判断自己要不要赖床!!!
import numpy as np
import operator
import math
# 按照给定特征划分数据集
#dataSet:待划分数据集 axis:划分数据集的特征 value:需要返回的特征的值
def splitDataSet(dataSet,axis,value):
retDataSet=[]
for featVec in dataSet: #遍历元素
if featVec[axis] == value: #符合条件的,抽取出来
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
# 计算给定数据集的信息熵
import math
def calcShannonEnt(dataSet):
numEntries = len(dataSet) #获得数据集的行数
labelCounts = {} #用于保存每个标签出现次数的字典
for featVec in dataSet:
currentLabel = featVec[-1] #提取标签信息
if currentLabel not in labelCounts.keys(): #如果标签未放入统计次数的字典,则添加进去
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1 #标签计数
shannonEnt = 0.0 #熵初始化
for key in labelCounts:
prob = float(labelCounts[key])/numEntries #选择该标签的概率
shannonEnt -= prob*math.log(prob, 2) #根据信息熵公式计算
return shannonEnt #返回经验熵
# 选择最好的数据集划分方式
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 #特征数量
baseEntropy = calcShannonEnt(dataSet) #计数数据集的香农熵
bestInfoGain = 0.0 #信息增益
bestFeature = -1 #最优特征的索引值
for i in range(numFeatures): #遍历数据集的所有特征
featList = [example[i] for example in dataSet] #获取dataSet的第i个所有特征
uniqueVals = set(featList) #创建set集合{},元素不可重复
newEntropy = 0.0 #信息熵
for value in uniqueVals: #循环特征的值
subDataSet = splitDataSet(dataSet, i, value) #subDataSet划分后的子集
prob = len(subDataSet) / float(len(dataSet)) #计算子集的概率
newEntropy += prob * calcShannonEnt((subDataSet))
infoGain = baseEntropy - newEntropy #计算信息增益
print("第%d个特征的信息增益为%.3f" % (i, infoGain)) #打印每个特征的信息增益
if (infoGain > bestInfoGain): #计算信息增益
bestInfoGain = infoGain #更新信息增益,找到最大的信息增益
bestFeature = i #记录信息增益最大的特征的索引值
return bestFeature #返回信息增益最大特征的索引值
# 统计出现次数最多的元素(类标签)
def majorityCnt(classList):
classCount={} #统计classList中每个类标签出现的次数
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True) #根据字典的值降序排列
return sortedClassCount[0][0] #返回出现次数最多的类标签
# 创建决策树
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet] #取分类标签
if classList.count(classList[0]) == len(classList): #如果类别完全相同,则停止继续划分
return classList[0]
if len(dataSet[0]) == 1: #遍历完所有特征时返回出现次数最多的类标签
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet) #选择最优特征
bestFeatLabel = labels[bestFeat] #最优特征的标签
myTree = {bestFeatLabel:{}} #根据最优特征的标签生成树
del(labels[bestFeat]) #删除已经使用的特征标签
featValues = [example[bestFeat] for example in dataSet] #得到训练集中所有最优特征的属性值
uniqueVals = set(featValues) #去掉重复的属性值
for value in uniqueVals: #遍历特征,创建决策树
subLabels = labels[:] #复制所有标签,这样树就不会弄乱现有标签
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
return myTree
import matplotlib
import matplotlib.pyplot as plt
# 定义文本框和箭头格式
decisionNode = dict(boxstyle="square", fc="0.8") #boxstyle文本框样式、fc=”0.8” 是颜色深度
leafNode = dict(boxstyle="round4", fc="0.8") #叶子节点
arrow_args = dict(arrowstyle="<-") #定义箭头
# 绘制带箭头的注解
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
#createPlot.ax1是表示: ax1是函数createPlot的一个属性
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',xytext=centerPt,
textcoords='axes fraction',va="center", ha="center", bbox=nodeType, arrowprops=arrow_args)
# 获取叶节点的数目和树的层数
def getNumLeafs(myTree):
numLeafs = 0 # 初始化
firstStr = list(myTree.keys())[0] # 获得第一个key值(根节点)
secondDict = myTree[firstStr] # 获得value值
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict': # 测试节点的数据类型是否为字典
numLeafs += getNumLeafs(secondDict[key]) # 递归调用
else:
numLeafs += 1
return numLeafs
# 获取树的深度
def getTreeDepth(myTree):
maxDepth = 0 # 初始化
firstStr = list(myTree.keys())[0] # 获得第一个key值(根节点)
secondDict = myTree[firstStr] # 获得value值
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict': # 测试节点的数据类型是否为字典
thisDepth = 1 + getTreeDepth(secondDict[key]) # 递归调用
else:
thisDepth = 1
if thisDepth > maxDepth:
maxDepth = thisDepth
return maxDepth
# 在父子节点间填充文本信息
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0] - cntrPt[0]) / 2.0 + cntrPt[0]
yMid = (parentPt[1] - cntrPt[1]) / 2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
# 画树
def plotTree(myTree, parentPt, nodeTxt):
numLeafs = getNumLeafs(myTree) # 获取树高
depth = getTreeDepth(myTree) # 获取树深度
firstStr = list(myTree.keys())[0] # 这个节点的文本标签
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs)) / 2.0 / plotTree.totalW, plotTree.yOff) #plotTree.totalW, plotTree.yOff全局变量,追踪已经绘制的节点,以及放置下一个节点的恰当位置
plotMidText(cntrPt, parentPt, nodeTxt) #标记子节点属性
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0 / plotTree.totalD #减少y偏移
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
plotTree(secondDict[key], cntrPt, str(key))
else:
plotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalD
# 绘制决策树
def createPlot(inTree):
fig = plt.figure(1, facecolor='white') # 创建一个新图形
fig.clf() # 清空绘图区
font = {'family': 'MicroSoft YaHei'}
matplotlib.rc("font", **font)
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops)
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5 / plotTree.totalW;
plotTree.yOff = 1.0;
plotTree(inTree, (0.5, 1.0), '')
plt.show()
# 定义文本框和箭头格式
decisionNode = dict(boxstyle="square", fc="0.8") #boxstyle文本框样式、fc=”0.8” 是颜色深度
leafNode = dict(boxstyle="round4", fc="0.8") #叶子节点
arrow_args = dict(arrowstyle="<-") #定义箭头
# 绘制带箭头的注解
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',xytext=centerPt,
textcoords='axes fraction',va="center", ha="center", bbox=nodeType, arrowprops=arrow_args)
def createDataSet():
dataSet = [[3, 2, 1,'yes'], #数据集
[3, 1, 1, 'yes'],
[3, 0, 1, 'no'],
[3, 2, 0, 'yes'],
[3, 1, 0, 'yes'],
[2, 2, 1, 'yes'],
[2, 2, 0, 'yes'],
[2, 1, 0, 'no'],
[2, 1, 1, 'yes'],
[2, 0, 1, 'no'],
[2, 0, 0, 'no'],
[1, 0, 0, 'no'],
[1, 1, 0, 'no'],
[1, 0, 1, 'no'],
[2, 3, 1, 'no'],
[3, 3, 0, 'yes'],
[1, 2, 0, 'yes'],
[1, 2, 1, 'yes'],]
# 气温:3热,2适中, 1冷; 1饿, 0不饿
labels = ['气温', '赖床人数', '饿不饿'] #特征标签
return dataSet, labels #返回数据集和分类属性
if __name__ == '__main__':
dataSet, labels = createDataSet()
myTree = createTree(dataSet, labels)
print(myTree)
createPlot(myTree)
生成的决策树:

报错解决:
Error:'dict' object has no attribute 'iteritems'
问题:应该数据集有问题,有重复的了,特征一样,但是标签不同,需要回去修改数据集。
Error:UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xc8 in position 0: invalid continuation byte
将csv读取时设置:encoding="unicode_escape"
总结
优缺点
| 优点 | 缺点 | |
|---|---|---|
| 效果可视化,可以直观的看到决策过程 | 决策树不宜建的过于复杂,否则容易过拟合 | |
| 计算复杂度不高,输出结果易于理解,对中间值缺失不敏感,可以处理不相干特征数据 | – |
决策树是一个从生活来到生活中去的一个机器学习算法,每个人都有一颗属于自己的决策树,通过自己的划分给不同条件进行计算权重,权重大的便是我们选择的偏向。