TensorFlow 2019
numpy pandas sklearn
算法
神经网络的Math
动手实现网络结构
应用
TensorFlow框架
图像案例
Machine Learning VS Deep Learning
1 特征提取方面 自动
2 数量集 量大/参数大
* 机器学习 : 朴素贝叶斯 决策树
深度学习 : 统称神经网络
3 应用
图识别/自然语言处理/语言识别
4 架构
Caffe TensorFlow Pytorch(Facebook)
架构/框架对比
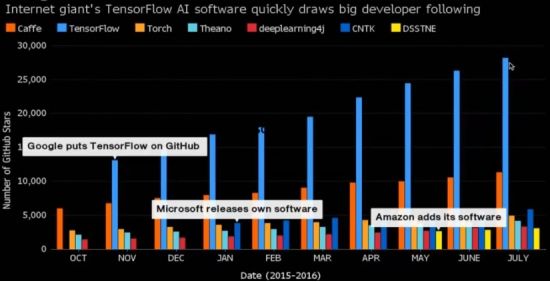
Followers
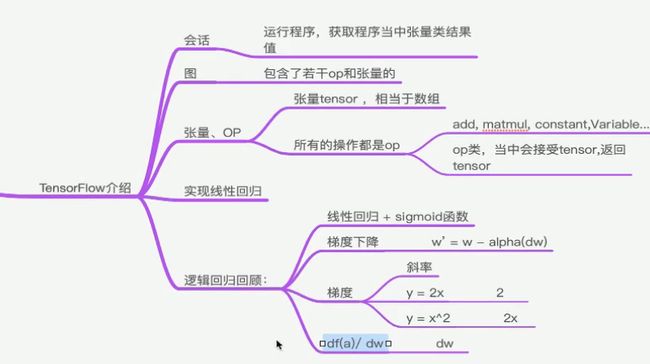
TensorFlow:
语言多 : C++封装 Python封装 可Go/Swift
分布式训练 : GPU TPU(Google)
TensorBoard可视化 : Web
跨平台应用 : HTTP的TF服务 / TF Lite / tf .js
2 Tensorflow架构(一)
加法
a_t = tf.constant(10)
b_t = tf.constant(20)
c_t = tf.add(a_t ,b_t)
减法
* print 不支持,需要开启会话
with tf.session() as sess :
sum_t = sess.run(c_t)
print(“sum:/t”, sum_t)
3 Tensorflow架构(二)
Tensorflow : 构架图阶段 , 执行图阶段
图 : 指令之间依赖关系
会话 : 本地/远程多设备
张量 : tensor 节点(operate) : 图的操作
数据流图:
**
2 图和TensorBroad
图包含tf.Operation计算单元 tf.Tensor 数据流动
#获取默认图片
g = tf.get_default_graph()
print(g)
print(a.graph)
print(b.graph)
#会话默认图
print(sess.graph)
通过tf.Graph()创建图
new_g = tf.graph()
with new_g.as_default() :
new_a = tf.constant(30)
new_b = tf.constant(40)
new_c = tf.add(new_a ,new_b)
*很少,但是可以一个程序多个图(Model)
TensorBroad
图略
1 数据序列化 - events文件
tf.summary.FileWriter(./temp/tests , graph = sess.graph)
events.out.tfevents.{timestamp}{hostname}
2 启动 TensorBroad
tensorboard --logdir = “./temp/tests”
代码
graph = sess.graph
OP

神经网络组件
softmax sigmod relu convolution max_pool
存储 恢复
save restore
队列及同步运算
Enqueue Dequeue MutexAcquire MutexRelease
*打印类型
Tensor(“Const_1:0” , shape=() ,dtype =float32)
Tensor(“Add:0” , shape=() ,dtype =float32)
2.3 会话
tf.session()
tf.InteractiveSession() : 交互上下文,用于shell
初始化
__int__(target=”” , graph = None ,config = None)
#通用开启
with tf.session() as sess :
...
return None
target 网址,训练器
config 控制会话
# 代码
tf.session(config = tf.ConfigProtol , allow_soft_placement = True , log_device_placement = True)
会话运行
run(fetches , feed_dict = None , option = None , run_metadata = None)
*定义占位符(不知何值)
a = tf.placeholder(tf.float32)
b = tf.placeholder(tf.float32)
sum_ab = tf.add(a ,b)
sess.run(sum_ab ,feed_dict = {a:30 ,b:40})
会话在Shell中 InteractiveSession :
$ iPython
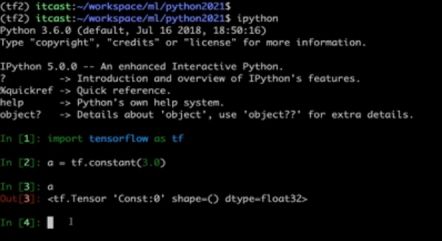
tf.InteractiveSession() 交互式
a.eval() #在shell中直接run
张量Tensor
type shape(几阶)
类型图
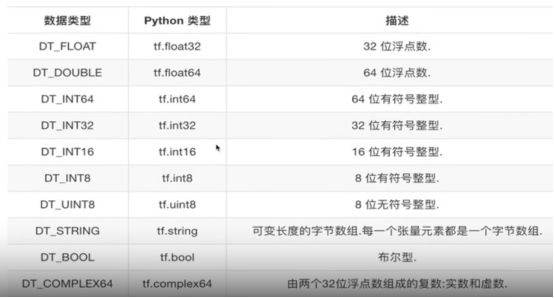
阶

创建张量指令
tf.zeros()
tf.one()
tf.contant()
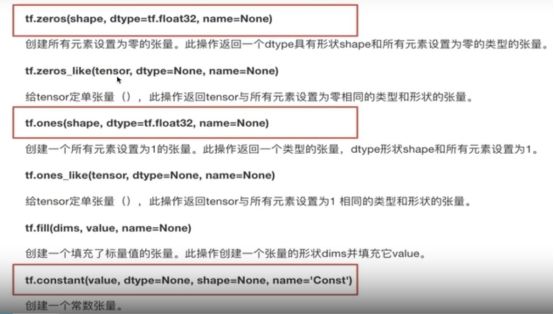
random_n = tf.random_normal( [3,4] ,mean = 0.0 , stddev = 1.0)
平均值 标准差 (正态分布)
张量的转换
类型转换
tf.string_to_number()
tf.cast()

形状改变
cast_one = tf.cast(one , tf.int32)
动态/静态
动态:
tf.reshape
元素数匹配即可
静态:
tf.set_shape
2D -> 2D
1D -> 1D
*形状可选/定义
a_p = tf.placeholder(dtype = tf.float32 , shape = [None ,None])
//联想四元数,角动量(slam)
变量OP
variable 可存磁盘 (权重、偏置)
tf.variable()
init = tf.global_variable_inltialier()
sess.run(init)
6 线性回归案例
y = wx + b Wi
案例 y = 0.8x + 0.7
运算
矩阵运算 tf.matmul(x ,w)
平方 tf.square(error)
均值 tf.redoce_mean(error)
梯度下降优化
tf.train.GradientDescentOptimizer(learning_rate)
梯度下降优化
learning_rate 学习率,一般为0~1之间的较小值
method :
minimize(loss)
return : 梯度下降op
#特征值x,目标值y_true
X = tf.random_normal(shape=(100,1) ,mean=2 ,stddev=2)
y_true = tf.matmul(X ,[[0.8]]) + 0.7
#建立线性模型
weights = tf.Variable(initial_value = tf.rnadom_normal(shape=(1,1)))
bias = tf.Variable(initial_value=tf.random_normal(shape=(1,1)))
#确认损失函数(预测值与真实值之间的误差) - 均方差
error = tf.reduce_mean(tf.squera(y_predict - y_true))
#梯度下降优化损失 : 需要学习率(超参数)
#W2 = W1 - 学习率*方向
#b2 = b1 - 学习率*方向
optimizer = tf.train.GradientDescentOptimizer(learning_rate = 0.01).minimize(error)
#初始化变量
init = tf.global_variables_initializer()
with tf.Session() as sess :
sess.run(init)
print(“随机初始化权重%f,偏置为%f” % (weights.eval() , bias.eval()))
#训练
for i in range(100):
sess.run(optimizer)
print(“第%d步的误差为%f ,权重为%f ,偏置为%f” % (i ,error.eval() ,weights.eval()))
return None
/
def linearregression() :
#1准备数据集
#x [100 ,1] 0.8 + 0.7 = [100,1]
X = tf.random_normal([100,1] ,mean=0.0 ,stddev=1.0)
#0.8是个二维
y_true = tf.matmul(X ,[[0.8]] ) +[[0.7]]
#2建立线性回归模型
#W [1,1] , b 1
weights = tf.Variable(inital_value = = tf.random_normal( [1,1] ) ) //w初始化
bias = tf.Variable(inital_value = = tf.random_normal( [1,1] ) ) //b必须使用变量OP被训练
y_predict = tf.matmul(X ,weights) + bias
#3确立损失函数,均方误差((y-y_predict)^2) / m
loss = tf.reduce_mean(tf.square(y_predict - y_true))
#4梯度下降优化:需要学习率(超参数)
optimizer = tf.train.GradientDescentOptimzer(learning_rate = 0.01).minimize(loss)
init_op = tf.gobal_variables_initalizer()
with tf.Session() as sess:
sess.run(init_op)
print(sess.run(optimizer)) // (1)优化不明显
for i in range(100):
print(sess.run(optimizer)) //(2)优化步长,梯度下降
print(“loss:” ,sess.run(loss))
print(“loss:” ,sess.run(“loss: weight: bias:” % [loss ,weigth ,bias] ))
return None
if __name__ == ‘__main__’ :
linearregression()

变量Variable设置trainable观察
属性 trainable
![]()
指定参数被训练
*迁移学习,部分参数(权重、偏置)不被训练
TensorBoard
添加命名空间
// Session命名空间
with tf.variable_scope(“original_data”) :
with tf.variable_scope(“linear_model”) :
//
Variable ( ,name = “rognal_date_since”)
Variable ( ,name = “w”)
// 添加本地文件
file_writer = tf.summary.FileWritter(“./temp/summary” ,)
$ tensorboard --logdir = “./temp/summary”
添加变量
零维度 tf.summary.scalar(“error” ,error)
高维度 tf.summary.histogram(“bias” ,bias) weight
merge = tf.summary.merge_all()
for i in range(100) : //训练100此,每次损失值都要记录
summary = sess.run(merge)
file_writer = tf.summary(summary ,i)
模型的保存与加载(简单方式)
tf.train.Saver(var_list = None ,max_to_keep = 5) //每隔5次
* 保存原则 : 什么值重要? 权重、偏置。
saver.save(sess ,”/tmp/ckpt/test/myregression.ckpt”)
saver.restore(sess ,”/tmp/ckpt/test/myregression.ckpt”)
ckpt格式 检查点文件格式
*eval()函数
1 字符串string转化成有效表达式
2 定义图、计算图时,类似run
3 有输出的Operation
命令行参数的使用
tf.app.flag 有个FLAG标志,它在程序中使用。
tf.app.flags.DEFINE_interger(“max_step” ,10 ,“训练步长”)
FLAG = tf.app.flags
for i in range(FLAG.max_step) :
print(“train loss:%f ,weight:%f ,bias:%f”% (loss.eval() ,weight.eval() ,bias.eval()))
逻辑回归复习(神经网络基础)
Logistic回归
主要的二分分类的算法。
Sigmoid函数
![]()
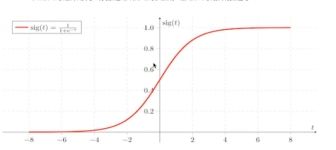

逻辑回归 sigmoid 线性回归 均方误差
概率小于1,log是负值 : -log(P) -log(0.4)
代价函数Cost Function : 所有损失值的平均数
![]()
导数向量化编程介绍
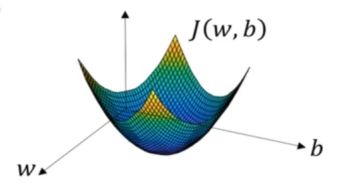
梯度gradient
参数 w b 的更新
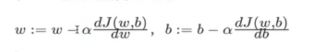
α是学习速率,即每次更新的w的步伐长度
导数

J雅可比公式 b b - a c < 0
逻辑回归训练实现前向和后向
向量化编程 : m个样本,每个样本都可以处理梯度

向量化 : 提高计算速度,比如Numpy
improt numpy as np
import time
a = np.random.rand(100000)
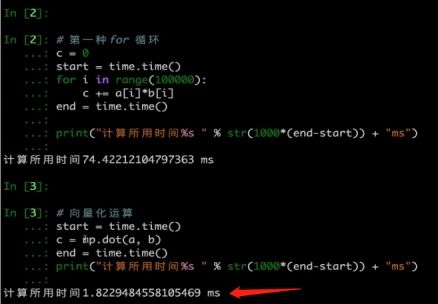
np常用:
np.ones np.zeros 全1 全0 矩阵
np.exp 指数运算
np.log 对数计算
np.abs 绝对值计算
实现逻辑回归 - 案例
1 使用数据:制作二分类数据集
from sklearn.datasets import load_iris ,make_classification
from sklearn.model_selection import train_test_split
import numpy as np
X,Y = make_classification(n_samples = 500 ,n_features = 5 , n_classes = 2)
x_train ,x_test ,y_train ,y_test = train_test_split(X ,Y ,test_size=0.3)
2 步骤设计
def basic_sigmoid(x) :
s = 1 / (1 + np.exp(-x))
return s
def propagate(w ,b ,X ,Y): //前向传播
m = X.shape[1] //维数
A = basic_sigmoid(np.dot(w.T ,X) + b)
#计算损失
cost = -1 / m * np.sum(Y * np.log(A) + (1 - Y) * np.log(1 - A)) // sigmoid函数的导数公式
dz = A - Y
dw = 1 / m * np.dot(X ,dz.T)
db = 1 / m * np.sum(dz)
cost = np.squeeze(cost)
grad = {“dw”:dw ,””db”:db}
return grads ,cost
def optimize(w ,b ,X ,Y ,num_iterations ,learning_rate):
costs = []
for i in range(num_iterations) :
# 梯度更新计算函数
grads ,cost = propagate(w ,b ,X ,Y)
#取出两个部分参数的梯度
dw = grads[‘dw’]
db = grads[‘db’]
#按照梯度下降公式去计算
w = w - learning_rate *dw
b = b - learning_rate * db
if i % 100 == 0 :
costs.append(cost)
if i % 100 = 0
print(“损失结果 %i : %f”% (i ,cost))
print(b)
params = {“w”:w ,”b”:b}
grads = {“dw”:dw ,”db”:db}
return params ,grads ,costs
def predict(w ,b ,X):
m = X.shape[1]
y_prediction = np.zeros( (1,m) )
w = w.reshape(X.shape[0] ,1)
#计算结果
A = basic_sigmoid(np.dot(w.T ,X) + b)
for i in range(A.shape[1]) :
if A[0 ,i] <=0.5 :
y_prediction[0 ,i] = 0
else :
y_prediction[0 ,i] = 1
return y_prediction
def model(x_train ,x_test ,y_train ,y_test ,num_iterations = 2000 ,learning_rate=0.0001)
x_train = x_train.reshape(-1 ,x_train.shape[0])
x_test = x_test.reshape(-1 ,x_test.shape[0])
y_train = y_train.reshape(-1 ,y_train.shape[0])
y_test= y_test.reshape(-1 ,y_test.shape[0])
print(x_train.shape)
print(x_test.shape)
print(y_train.shape)
print(y_test.shape)
#初始化参数
w , b = initialize_with_zeros(x_train.shape[0])
#梯度下降
#params:更新后的网络参数
#grads:最后一次梯度
#costs:每次更新损失列表
optimize(w ,b ,x_train ,y_train ,num_iterations ,learning_rate)
return None
神经网络与tf.keras
图片:宽 高 通道
如果一个像素点,有RGB三个颜色来描述它,就是三通道。
Keras开源的Python的神经网络库。
*减少认知困难,提供一系列API
*因为Keras和底层深度学习语言(特别是Tensorflow)集成一起
*Keras被学界和工业界广泛使用
*GPU相关的训练
tf.Keras的API
applications module : Keras应用程序具有预训练权重的固定架构
callbacks module : 回调,再模型训练期间在某些点调用的实用程序
datasets module : 数据集
initializers module : 序列化/反序列化
layers module : API
losses module : 内置损失功能
metrics module : 内置模标
models module : 代码克隆、线程模型 API
optimizers module : 内置优化器
preprocessing module : 数据预处理工具(图片预处理)
regularizers module : 内置正则化器
utils module : 实用程序
图片预处理
tensorflow.python.keras.preprocessing.image
预下载图片读取库
pip install Pillow
image = load_image(path = “”,target_size)
imageArr = image_to_array(image)
print(imageArr.shape)

NHWC 和 NCHW
通道数在前面,通道数在后面
NHWC [batch ,height ,width ,channels]
NCHW [batch ,channels ,height ,width]
Tensorflow 默认[height ,width ,channel]

RGB的格式

tf.transpose( depth_major ,[1 ,2 ,0]).eval() //横竖转换
*转换维度
tf.reshape( [1,2,3,4,5,6,7,8,9,10,11,12] ,[3 , 2 ,2]).eval() //成功
tf.reshape( [1,2,3,4,5,6,7,8,9,10,11,12] ,[2 ,2 3]).eval() //失败
reshape()不能对一维中按照RGB做channel_last变换,只能做channel_first变换。
NHWC和NCHW变换
1 首先reshape()
2 transpose(),维度位置变换
tf.keras数据集
CIFAR小图片分类数据集
50000张32x32的小图片
10000张32x32的测试图片
from keras.datasets import cifar100
(x_train ,y_train) ,(x_test ,y_test) = cifar100.load_data()
时装分类Minist数据集
(x_train ,y_train) ,(x_test ,y_test) = keras.datasets.fashion_mnist.load_data()
图像神经网络
神经网络Neural Network NN :
输入层 隐藏层 输出层
*没有隐藏层,直接链接的层数,叫做全连接层。
感知机 Perceptorn Learning Algorithm PLA
具有链接的权重和偏置 W b

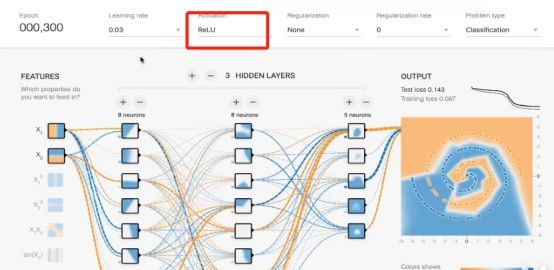
Playground 2016年谷歌发布的模拟神经网络
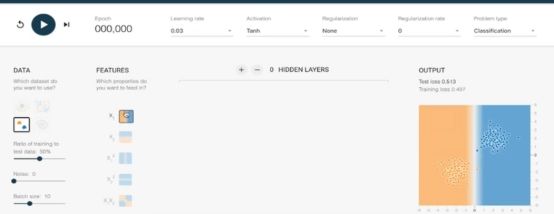
x12 x1*x2 sin(x2)各自出现非线性分类的过程
神经网络原理
多分类 : 避免n个双分类器,设置n个输出结点的全连接输出
Softmax回归

1 数值 -> 预测概率值
2 概率和为1(归一化)
交叉熵损失 :
衡量预测的概率分布,和真实的概率分布之间的关系
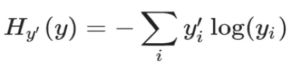
损失大 /损失小 -> 预测不准 / 预测更准
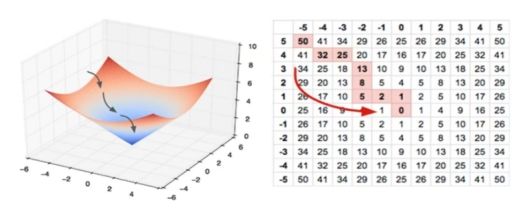
训练中增大或减少每个参数,看如何减少相比于训练数据集的误差,以望能找到最有的权重、偏置参数组合。
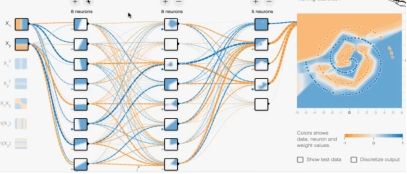
上示负责数据,三层隐藏层的解决方案(增加深度)
tf.keras API介绍(一)
构建模型 :
tf.keras.Sequential() //堆叠层数
tf.keras.layers() :
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.layers import DepthwiseConv2D
from tensorflow.python.keras.layers import Dot
from tensorflow.python.keras.layers import Dropout
from tensorflow.python.keras.layers import ELU
from tensorflow.python.keras.layers import Embedding
from tensorflow.python.keras.layers import Flatten
from tensorflow.python.keras.layers import GRU
from tensorflow.python.keras.layers import LSTMCell
......
Flatten :
将输入进行形状改变展开
28x28 -> 784
Dense :
Dense(units ,activation=None ,**kwargs):
*untis : 神经元个数
*activations : 激活函数,参考:
tf.nn.relu
tf.nn,softmax
tf.nn.sigmoid
tf.nn.tanh
*kwargs : 输入上层输入的形状,input_shape = ()
//两个隐藏层的10分类器
model = keras.Sequential(
keras.layers.Flattern(input_shape = (28 ,28)),
keras.layers.Dense(128 ,activation = tf.nn.relu),
keras.layers.Dense(10 ,activation = tf.nn.softmax)
)
训练与评估
通过调用model的compile方法去配置该模型所需要的训练参数和评估方法
optimizer :
梯度下降的优化器(keras.optimizers)
from tensorflow.keras.optimizers import Adadelta
from tensorflow.keras.optimizers import Adagrad
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.optimizers import Nadam
from tensorflow.keras.optimizers import Optimizer
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.optimizers import desrialize
from tensorflow.keras.optimizers import get
from tensorflow.keras.optimizers import serialize
from tensorflow.keras.optimizers import AdamOptimizer()
losses :
真实值和预测值之间的差值
损失类型
from tensorflow.keras.losses import KLD
from tensorflow.keras.losses import KLD as kls
from tensorflow.keras.losses import KLD as kullback_leibler_divergence
from tensorflow.keras.losses import MAE
from tensorflow.keras.losses import MAE as mae
from tensorflow.keras.losses import MAE as mean_absolute_error
from tensorflow.keras.losses import MAPE
from tensorflow.keras.losses import MAPE as mape
from tensorflow.keras.losses import MAPE as mean_ablsolute_precentage_error
from tensorflow.keras.losses import MSE
from tensorflow.keras.losses import MSLE
from tensorflow.keras.losses import binary_crossntroy
from tensorflow.keras.losses import categorical_crossentropy //均方误差
from tensorflow.keras.losses import cosine
from tensorflow.keras.losses import desrialize
from tensorflow.keras.losses import get
from tensorflow.keras.losses import hinge
from tensorflow.keras.losses import logcosh
from tensorflow.keras.losses import pisson
metrics = None,[‘accuracy‘] //指标
进行训练
model.fit(x = None ,y = None ,batch_size = None ,epochs = 1 ,callbacks = None)
x : 特征值
1 numpy array
2 tensor
3 tf.data / tuple
4 a generate
y : 目标值
batch_size = None :
批次大小
epochs = 1
训练迭代次数
tf.keras API介绍(二)
Model module :
Model(inputs = a ,output = b)
*input : 定义模型的输入,input类型
*output : 定义模型的输出
def call(self , inputs) : 接受来自上层的输入
from keras.models import Model
from keras.layers import Input ,Dense
data = Input(shape=(784 ,))
out = Dense(32)data
model_Sec = Model(input = data ,output = out)
print(model_Sec)
model.compile(optimizer=tf.keras.optimizers.Adam(),loss = ‘sparse_categorical_crossentropy’,metrics=[‘accuracy’])
return None
Models 属性
Models.Layers
Models.Input
Models.Output
Model.Compile() :
优化器 算法 损失计算
损失计算 :
sparse_categorical_crossentropy 对于目标值是整型的进行交叉熵损失计算
categorical_crossentropy 对于两个output tensor and a target tensor (one-hot code)进行交叉熵损失
Model.fit(x=None ,y=None ,batch_size=None ,epoch=1 ,call backs=None)
x:特征值
y:目标值
epochs=1 : 训练迭代次数
callback=None : 添加回调列表(用于tensorboard显示等)
model.evalute(test_image ,test_labels):
评估
或者预测model.predict(test)
其他方法:
model.save_weight()
model.load_weight()
使用多层神经网络进行时装分类

class SingleNN(object) :
model = keras.Sequential(
keras.layers.Flattern(input_shape=(28,28)),
keras.layers.Dense(128 ,activation=tf.nn.relu),
keras.layers.Dense(10 ,activation=tf.nn.softmax)
)
// 双层:128个单元,全连接10个类别输出
//编译定义优化过程,这里选择我们SGD优化器
keras.optimizers.SGD(lr=0.01)
//lose:tf.keras.losses.spare_categorical_crossentropy
//metrics:accuracy
def compile(self):
SingleNN.model.compile(optimizer=keras.optimizer.SGD(lr=0.01) ,loss=tf.keras.losses.spare_categorical_crossentropy ,metrics=[‘accuracy’])
return None
//训练
//设置batch_size=32或者128查看效果(值如何设置,优化部分会进行详解)
def fit(self):
SingleNN.model.fit(self.train ,self.train_label ,epochs=5 ,batch_size=32)
return None
//评估
def evaluate(self):
test_loss ,test_acc = SingleNN.model.evaluate(self.test ,self.test_label)
print(test_loss ,test_acc)
return None
def__init__(self):
(self.train_,self.train_label),(self.test ,self.test_label) = keras.datasets.fashion_mnist.load_data()
效果修改和对比
效果不好 :换优化器等
效果不好的根本原因: 对图片特征进行归一化
(0 ~ 255) -> (0~1)
#进行数据归一化
self.train = self.train / 255.0
self.test= self.test/ 255.0
模型的保存和加载
保存到h5文件,避免多个文件夹
SingleNN.model.load_weights(“./ckpt/SingleNN.h5”)
model check point
fit 的 Callbacks = “”详解
keras.callbacks.ModelCheckpoint(filepath ,mointor=’val_loss’,save_best_only=False ,save_weights_only=False ,mode=’auto’,period=1)
每隔多少次保存一次模型
提前中止 : 准确率或者阈值,然后中止
modelcheck = keras.callbacks.ModelCheckpoint(
filepath = ‘./ckpt/singlenn_{epoch:02d}-{val_acc:.2f}.h5’,
montor=’val_acc’,
save_best_only = True.
save_weights_only = True,
period = 1,
mode = ‘auto’
)
SingleNN.model.fit(self.x_train ,self.y_train ,epochs=1, batch_size=128 ,callbacks=[modelcheck])
Tensorboard效果
keras.callbacks.TensorBoard( log_dir=’./logs’,histogram_freq=0 ,batch_size=32 ,write_graph = True,write_grads=False,write_images=False ,embeddings_freq=0 ,embeddings_layer_names=None ,embeddings_metadata=None ,embeddings_data=None ,update_freq=’epoch’)
write_graph = True : 是否显示图结构
write_images = False :是否显示图片
write_grads = True :是否显示梯度hitogram_freq 必须大于零
tensorboard=keras.callbacks.TensorBoard(log_dir=’./graph’,histogram_freq=1 ,write_graph=True ,write_images=True)
SingleNN.model.fit(self.train ,self.train_label ,epochs=5 ,callbacks=[tensorboard])
深层神经网络
随着模型的层数(深度)增加,处理复杂问题的能力,可能越好
什么是深层网络?
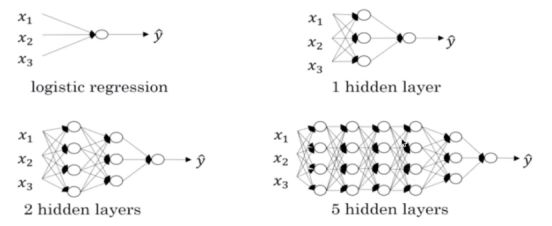
前向传播和反向传播
例如四层

单个样本的反向传播
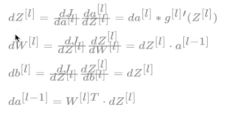
多个样本的反向传播
参数和超参数
网络有限相关的两个概念
参数(权重、偏置) :模型运行过程中学习到的
超参数(人为设置) : 需要控制的一些参数信息(学习率、迭代次数、隐藏层层数、每层神经元个数、激活函数选择 等等)
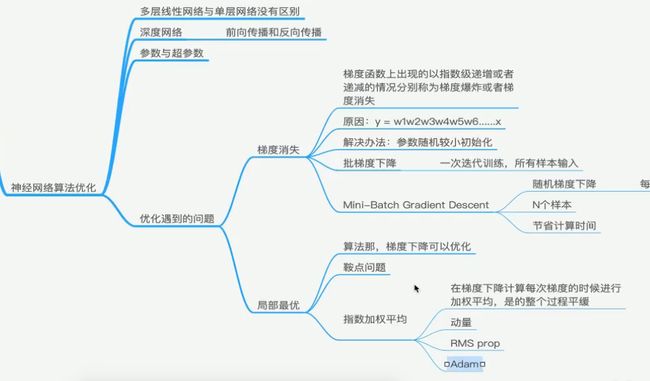
优化过程遇到的问题
梯度消失和局部最优
如何解决上述问题?
1 初始化参数策略 (relu函数无问题)
2 Mini梯度下降算法
batch一起epoch

3 梯度下降算法的优化

SGD 随机梯度下降
BGD 批梯度下降
Mini-Batch 小批量梯度下降
*选择方法是个数量的经验值
马鞍面
加权平均值优化
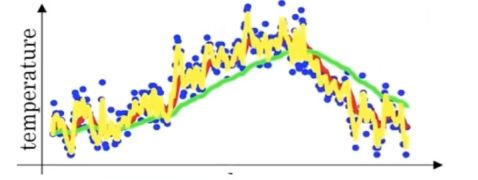
绿线显示的数据更光滑
RMSProp算法 : 求导增加一个动量,减少摆动。更平滑。
Adam算法 :(Adaptive Moment Estimation 自适应矩估计)
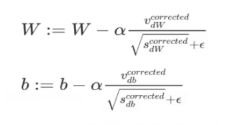
亚当
目前在机器学习中,处理梯度最好的算法
tf.train.AdamOptimizer(learning_rate = 0.001 ,beta1 = 0.9 , beta2 = 0.999 ,epsilon = 1e-08 ,name = ‘adam’)
学习率α : 尝试一系列的值,寻找比较合适的
β1 : 作者常用却省值0.9
β2 : 建议0.999
ε : 建议1e-8
4 学习率衰减
如果设置一个固定的学习率,在最小点附件不容易收敛
所以随着时间逐渐减小学习率α的大小,有助于算法收敛
指数衰减 α = 0.95^(epoch_num) * α0
*其他非算法的优化的方式
标准化输入 平均值0 标准差1 的 平均正态分布
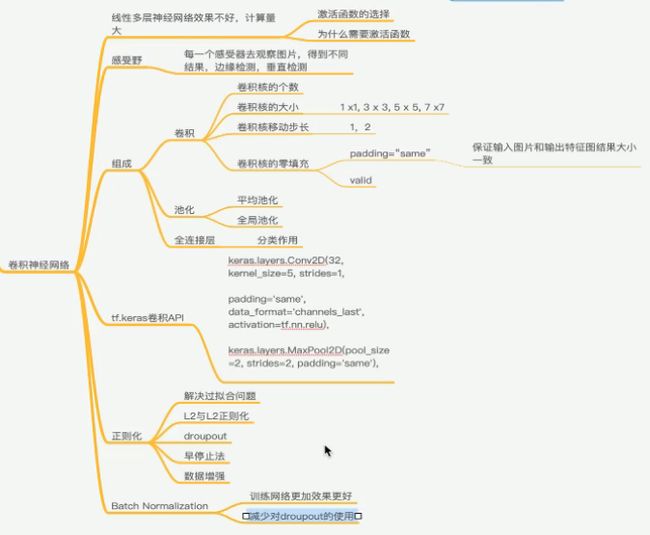
卷积神经网络的简介
Convolution Neural Network
线性模型解决问题的能力是有限的。
使用非线性的激活函数
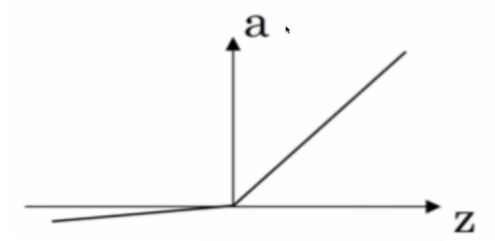
Leaky Relu 带泄露的Relu
为什么需要非线性的激活函数?
如果直接logistic回归,那么无论多少神经网络层,输出都是输入的线性组合。与没有隐藏层相当,相当于最原始的感知器。
感受野概念
如果不使用卷积处理图片? 特征数量太大(几个神经元,几千万个权重参数)。
基于是觉得卷积神经网络:

边缘检测 :
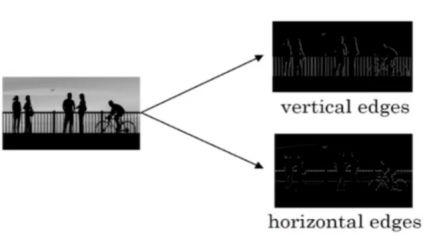
过滤器Filter
卷积网络CNN的三个组成
由一个或多个卷积层(Convolutions) , 池化层(Subsmpling) ,以及全连接层(Full connection)组成。
卷积曾主要目的是:提取图片特征
size : 卷积核/Filter的大小 3*3 5*5
padding : 填充
stride : 步长,通常1
为什么填充增加0值? 不对运算造成影响。
填充多少? Vailed/Same输出大小和输入大小的比较。
池化层 Pooling
池化层作用 :
1 收集/减少图片的特征数量,避免全连接层参数过多。
2 提高FeatureMap的鲁棒性,防止过拟合(训练好但是测试差)
Max Pooling / Avg Pooling
全连接层
先对FeatureMap 扁平化
再接一个或多个全连接层,以进行模型学习
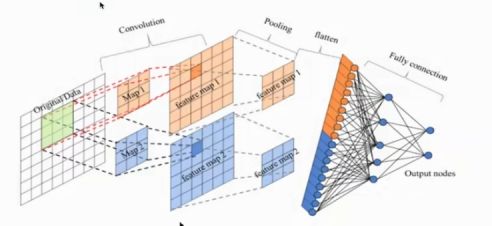
CIFAR100类识别
构建CNN常用API
Conv2D
MaxPool2D
keras.layers.Conv2D(32,kernel_size=5 ,strides=1 ,padding=’same’ ,data_format=’channels_last’,activation=tf.nn.relu),keras.layers.MaxPool2D(pool_size=2 ,strides=2 ,padding=’same’))
步骤实现,缩减版的LeNet v5
class CNNMnist(object) :
def __init__(self) :
(self.train ,self.train_label) ,(self.test ,self.test_label) = \ keras.datasets.cifar100.load_data()
self.train = self.train.reshape(-1 ,32 ,32 ,3) / 255.0
self.test = self.test.reshape(-1 ,32 ,32 ,3) / 255.0
设计模型LeNet:
两层卷积层 + 两个神经网络层
第一层
卷积: 32个filter 大小5*5 strides=1 padding=“SAME”
激活: Relu函数
池化: 大小2X2 strides=2
第二层
卷积: 64个filter 大小5*5 strides=1 padding=“SAME”
激活: Relu
池化:大小2X2 strides=2
model = keras.Sequential([
keras.layers.Conv2D(32 ,kerenl_size=5,strides=1,padding=”same”,data_format=’channel_last’,activation=tf.nn.relu),
keras.layers.MaxPool2D(pool_size=2 ,strides=2 ,padding=’same’),
keras.layers.Conv2D(64 ,kernel_size=5 ,strides=1 ,padding=’same’,data_format=’channels_last’ ,activation=tf.nn.relu),
keras.layers.MaxPool2D(pool_size=2 ,strides=2 ,padding=’same’),
keras.layers.Flatten(),
keras.layers.Dense(1024 ,activation =tf.nn.relu),
keras.layers.Dense(100 ,activation=tf.nn.softmax),
])
编译/执行。评估。
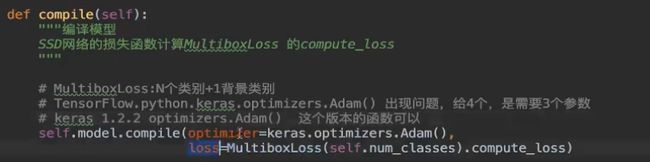
def compile(self):
CNNMnist.model.compile(
optimizer=keras.optimizers.Adam() ,
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[‘accuracy’]
)
return None
def fit(self):
CNNMnist.model.fit(self.train ,self.train_label ,epochs=1 ,batch_size=32)
return None
def ecaluate(self):
test_loss,test_acc=CNNMnist.model.evaluate(self.test ,self.test_label)
print(test_loss ,test_acc)
return None
卷积神经网络案例实现
#归一化
self.train = self.train /255.0
self.test = self.test /255.0
其余的代码同上节
正则化(Regularization)介绍 - 偏差方差
梯度下降的优化:限制权重;期望为0的正态分布;
梯度下降的优化,主要是数学方面。正则化的数学意义不大,主要是工程方面的意义。
数据集的划分
三个数据集:训练集(train set)、验证集(development set)、测试集(test set)
6:3:1 的比例(或者其他比例),进行交叉验证,选出最好的模型。
偏差-方差分解(bias-variance decomposition) 是解释学习算法泛化能力的一种重要工具
泛化误差: 数据集的偏差、方差、噪声。泛化性能是学习算法的能力、数据的充分性、以及学习任务的难度决定
偏差:度量学习算法的期望预测与真实值的偏离程度,刻画学习算法的拟合能力
方差:度量同样大小的训练集的变动所导致的性能变化,刻画数据扰动所造成的影响
噪声:表达当前任务上任何学习算法所能达到的期望泛化误差的下界,刻画学习问题本身的难度
那么偏差、方差和数据集划分到底有什么关系?
1 训练集的错误率较小,验证集/测试集的错误率较大,说明模型存在较大方差,可能出现过拟合
2 训练集和测试集误差都很大,且两者接近,说明模型存在较大方差,可能出现欠拟合
3 反之,训练集和测试集错误率很小,且两者接近,说明模型效果比较好
*算法优化和正则化的区别?
算法优化是针对问题选模型、层数、激活函数;
正则化是处理过拟合中训练集/测试集(实际问题)的能力不一致;
正则化的方法:
1 L1和L2
2 DropOut
3 早停止
欧姆剃刀:简单模型比复杂模型的泛化能力好
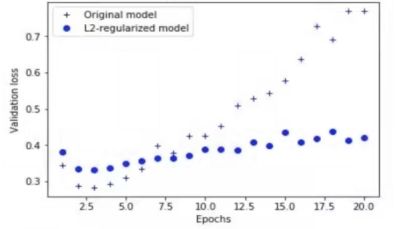
正则化,即在成本函数中加入一个正则化项(惩罚项),惩罚模型的复杂度。防止网络过拟合。
逻辑回归L1和L2
L2又叫做权重衰减(减小的慢)
keras.regularizers.l1(0.01)
keras.regularizers.l2(0.01)
keras.regularizers.l1_l2(l1=0.01 ,l2=0.01)
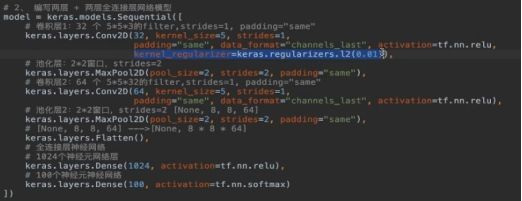
DroupOut正则化
Drouput-regularition Model (随机丢弃)
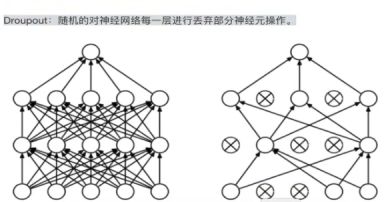
keep_prob = 0.8
其他正则经验
早停止法(Early stop)
*
数据增强
通过多种组合变换达成增加数据集大小
剪切 旋转/翻转 缩放 对比度变换 噪声扰动 颜色变换
翻转 tf.image.random_flip_left_right
旋转 tf.image.rotate
剪裁 tf.image.random_crop
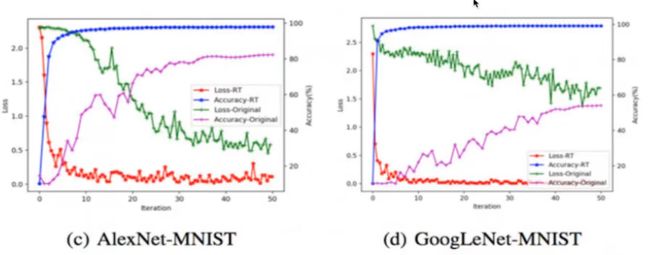
数据增强在理论上,不会增加噪声。
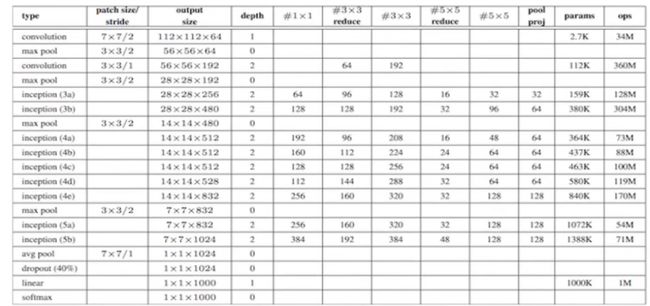
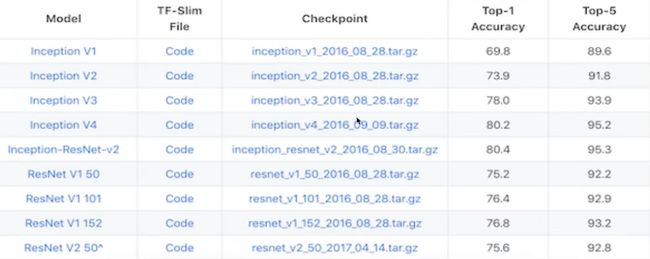
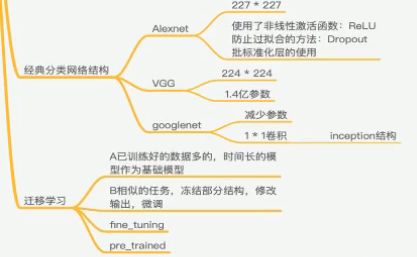
经典分类网络结构
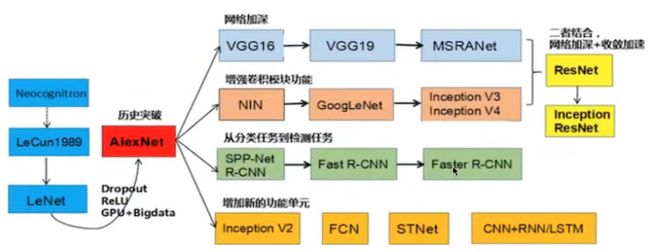
AlexNet
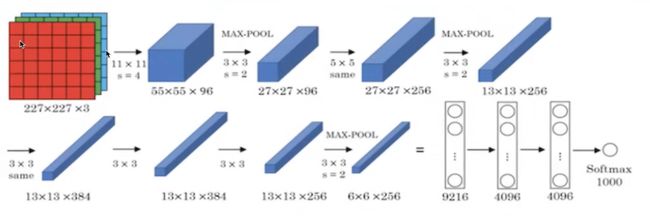
总参数数量: 60M = 6000万 , 5层卷积+3层全连接
使用非线性激活函数: Relu
防止过拟合的方法:Dropout
进化历史: AlexNet -- NIN -- (VGG / GoogLeNet) -- ResNet
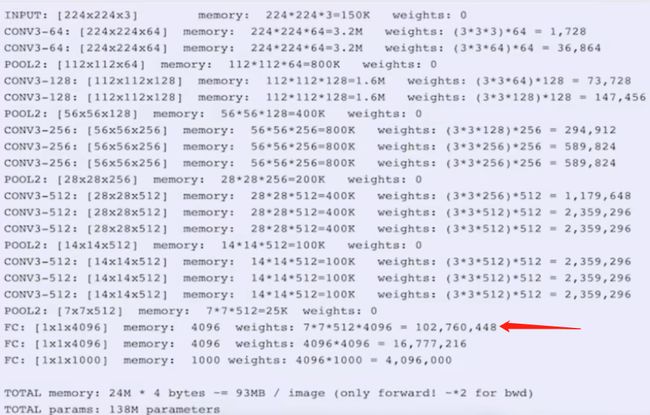
VGG
2014年分类第二(第一是GoogleNet),定位任务第一
参数量大,140M = 1.4亿
模型分两种 16层,19层
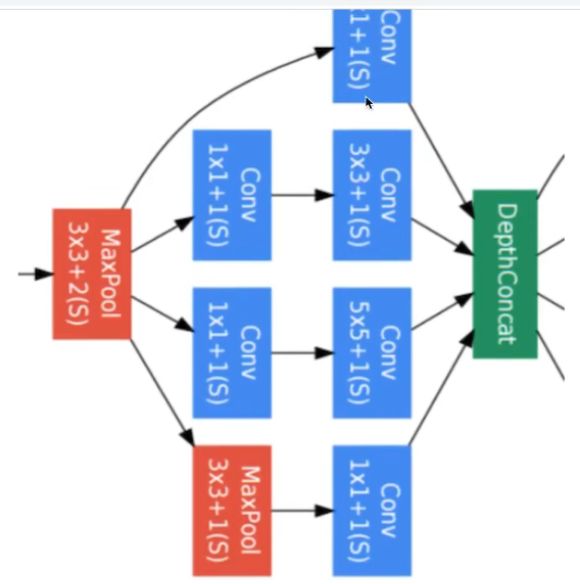
为保持精确度,改进内存,引入Inception模块
MLP: 卷积1X1 NIN : 网络中的网络
参数/权重 数量的减少:
1 看作对三个通道进行线性组合
2 通常卷积后加入非线性函数,这里加入激活函数,理解成一个简单MLP
实际中的Inception Modul:
卷积神经网络的学习可视化过程





使用Pre_trained模型进行VGG预测
tensorflow.keras.applications有很多现有模型。
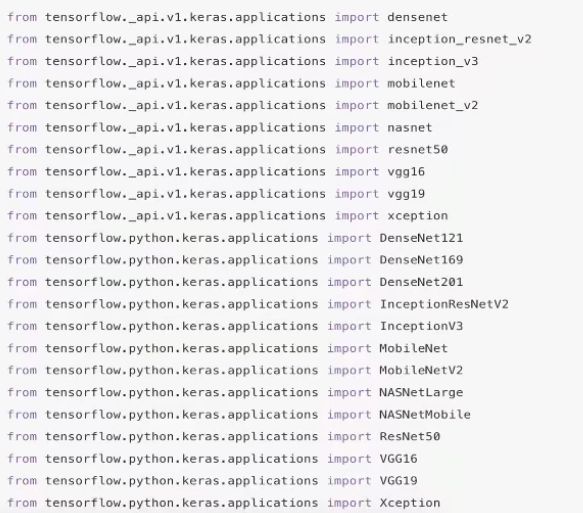
from tensorflow.python.keras.applications.vgg16 import VGG16
from tensorflow.python.keras.applications.vgg16 import preprocess_input,decode_prediction
from tensorflow.python.keras.preprocessing.image import load_img, img_to_array
def predict():
model = VGG16()
print(model.summary())
image = load_img('' ,target_size = (224 ,224))
image = image_to_array(image)
print(image.shape)
#输入卷积中,需要四维结构
image = image.reshape((1 ,image.shape[0] ,image.shape[1] ,image.shape[2] ))
#VGG16进行归一化处理
image = preprocess_input(image)
y_predictions = model.predict(image)
print(y_predictions)
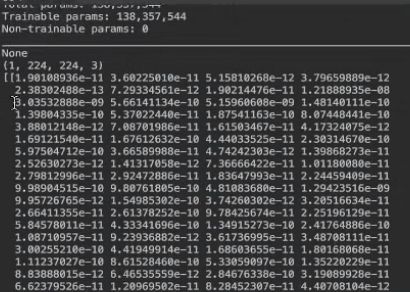
# 1000个类别里,“老虎”图片的维度是最大的
#VGG16解码工具
label = decode_predictions(y_predictions)
print("预测类别:%s ,概率是%s" % (label[0][0][1] ,label[0][0][2])) //获取其中元组
if __name__ == '__main__':
predict()
以上内容,是使用VGG进行迁移学习。
神经网络调优与BN层
知道常用的一些超参数
知道BN层的意义以及数学原理
算法层面:
学习率α (一般自学习)
β1 β2 :Adam优化算法的超参数,通常设置0.9 0.999 10-8
λ:正则化网络参数
网络层面:
hidden units : 各隐藏层神经元个数
layers: 神经网络层数
调参技巧:

合理参数设置:
学习率α: 0.001 0.01 0.1 跨度尽量大
算法参数β: 0.999 0.995 0.998 尽量接近1

试参数很步骤很麻烦,如何让整个过程简单?
批标准化 BN (Batch Normaliztion):
2015年2月的arxiv论文
内部协变量偏移 (internal covariate shift)的现象,通过标准层化来解决。
使用批标准化的图像分类,效果优于人类。
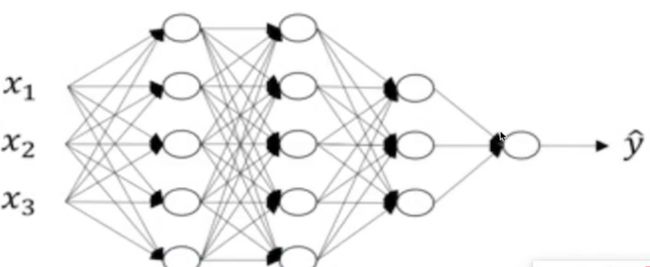
深藏网络中,不止是初始的特征输入,而隐藏层也有输出,所以对深层网络层的每一层层级进行批标准化。
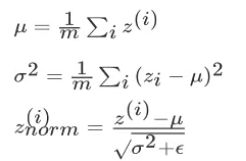
防止分母为0
原作者不希望方差1均值0,所以增加参数γ β
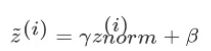
增加参数γ β(同W b一样),可以用各种梯度下降算法更新γ β的值,如同更新神经网络权重一样。为什么?
如果方差1均值0,那么得到较差的模型。
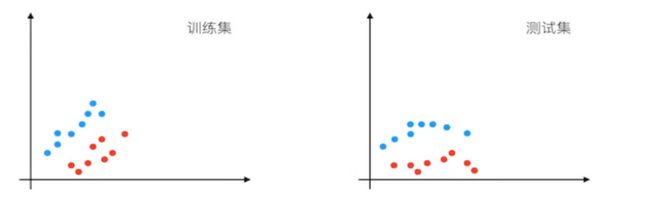
如果测试集中的数据,分布不一样,这个网路可能就不能准确区分。这种情况下需要重新训练。
1 Batch Normalization的作用是减少 Internal Covation Shift带来的影响,让模型的鲁棒性更强。
2 Batch Normalization的作用,使得均值和方差保持固定(每层由γ β决定),不同层学习到不同的分布状态
3 因此厚层的学习更容易些,Batch Normalization 减少各层W和b之间的耦合性,让各层更加独立,实现自我训练学习的效果。
CNN(卷积神经网络) 的内容复习
激活函数的选择?
非线性的Relu比tanh好,避免梯度消失。
感受野/边缘检测 的概念
网络层的组成?
一个或多个卷积层、池化层以及全连接层等组成
卷积层(Convolutions)
池化层(Subsampling)
卷积层的目的是什么?
提取特征 filter
卷积核 padding stride
Valid填充/Same原图大小
多通道卷积
池化层的作用?
作用:减少图片的特征数量
最大池化/平均池化
stride (类似卷积核)
部分代码
Conv2D
MaxPooling
正则化的作用?
作用:避免过拟合
训练好(迭代过多,层过深),效果差(测试机、线上效果差)
L2 Lp
消除噪声
Droupout为什么有效?
当确定已发生过拟合现象时,
来保证损失函数是单调下降的。
其他的正则化方法/训练方法?
早停止
数据增强(旋转/裁剪等等)
经典的网络结构?
LeNet
参数6万
AlexNet
2012年,参数6M=6000万,5层卷积+3层全连接
VGG
1.4亿参数,输入224*224*3 ,1000个分类
GoogleNet
引入Inception结构,500万参数
什么是Inception结构?
卷积层代替全连接 / Conv2D 代替 Dense
参数量减少
案例: 迁移学习Pre_trained的VGG16模型,识别图片“老虎”
批标准化的作用?
手动超参数的网络调优。
解决 内部协变量 的现象。
减少各个层W和b之间的耦合性,让各层更加独立,实现自我训练学习的效果。
迁移学习(Transfer Learning)
利用旧领域(数据、任务或模型)的相似性,将旧领域学习或训练好的模型,应用到新的领域中。
相反,机器学习系统很容易从海量数据中学习到一个鲁棒性很强的系统。
方法:
最常见的 fine tuning (微调)。
已训练好的模型,叫Pre-trained model
任务A海量数据已训练好的模型(1000类图片识别),新增任务B(250类图片识别)
1 可以在最后输出层(全连接层),在1000基础上,新增250个神经元
2 如果B数据量小,我们对A所有层进行freeze(通过Tensorflow的trainable=False参数实现),剩下层部分进行参数调整
3 如果B数据量大,我们对A中一半或者大部分的层进行freeze,剩下的部分layer进行新任务数据基础的微调。
迁移学习案例介绍
基于Keras中的VGG对五种图片类别的识别。
思路和步骤:
读取本地图片数据及类别
keras.preprocessing.image import ImageDataGenerator提供读取转换功能
模型的结构修改(添加自定义的分类层)
freeze掉原始VGG模型
编译以及训练和保存模型方式
输入数据进行预测
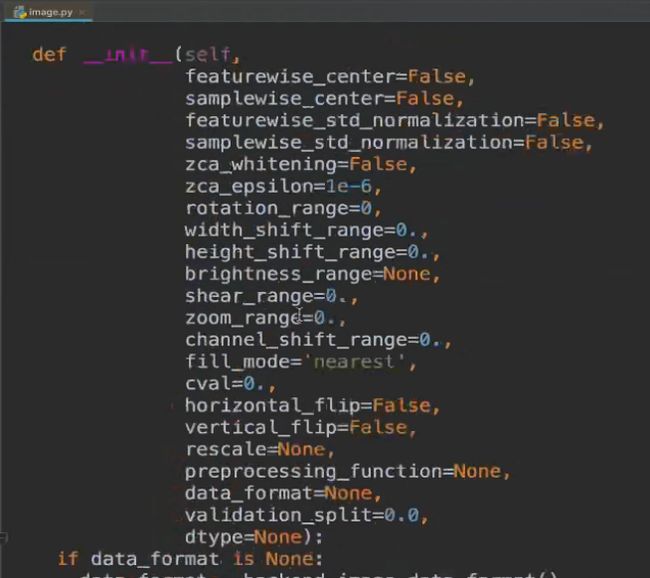
迁移学习--数据读取
train_generator = ImageDataGenerator()
生产图片的批次张量并且提供数据增强功能
rescale = 1.0/255 标准化
zca_whitening = False #zca白化的作用是针对图片进行PCA降维操作,减少图片冗余信息。
等等
import tensorflow as tf
from tensorflow.python import keras
from tensorflow.python.keras.preprocessing.image import ImageDataGenerator
class TransferModel(object):
def __init__(self):
self.train_generator = ImageDataGennerator(rescale = 1.0 / 255.0)
self.test_generator = ImageDataGennerator(rescale = 1.0 / 255.0)
self.train_dir = "./data/train"
self.test_dir = "./data/test"
self.image_size = (244 ,244)
self.batch_size = 32
def get_local_data(self):
train_gen = self.train_generator.flow_from_directory(
self.train_dir,
traget_size = (244 ,244),
class_model = self.image_size,
batch_size = self.batch_size,
shuffle = True
)
test_gen = self.train_generator.flow_from_directory(
self.test_dir,
traget_size = (244 ,244),
class_model = self.image_size,
batch_size = self.batch_size,
shuffle = True
)
return train_gen,test_gen
if __name__ == '__main__':
tm = TransferModel()
train_gen ,test_gen = tm.get_local_data()
print(train_gen)
print(test_gen)
for data in train_gen:
print(data)
模型定义
谷歌提供的NoTop模型:
VGG16不包含最后的三个全链接层。用来做fine tuning,专门开源模型。
keras_application/vgg16.py

self.base_ model = VGG16(weights = 'imagenet' ,include_top = Fasle)
weights='imagenet',意思是VGG在imagenet比赛中预训练的权重,使用resnet训练
模型修改
VGG模型的修改添加全连接层 GlobalAveragePooling2D
全局池化:
图像分类任务中,模型经过最后CNN层的尺寸为[batch_size ,img_width ,img_height ,channels],通常做法是街一个flaten layer,将尺寸改为[batch_size ,w h channels]再至少链接一个FC layer。这样做的问题:模型参数越多,容易过拟合
利用pooling layer来代替最后的FC layer

参数Dense 8 * 8 * 2048 * 1000
参数Conv2D 1 * 1 * 2048 * 1000
*如果正常训练,那么参数数量不可缺少、很重要
def refine_vgg_model(self):
'''
微调VGG结构:
5blocks后面+全局平均池化(减少迁移学习的参数数量) + 两个全连接层
'''
#获取NoTop模型输出
x = self.base_model.outputs[0]
#在输出层后面增加我们结构
x = keras.layers.GlobalAveragePooling2D()(x)
x = keras.layers.Dense(1024 ,activation = rf.nn.relu)(x)
y_predict = keras.layers.Dense(5 ,activation=tf.nn.softmax)
transfer_model = keras.Model(input=self.base_model.inputs ,outputs = y_predict)
return transfer_model
freeze VGG模型
如果参数数量小,可以全部层freeze(trainable = False)
def freeze_vgg_model(self):
for layer in self.base_model.layers:
layer.trainable = False
#主代码
tm.freeze_vgg_model()
tm.compile(model)
tm.fit_generator(model ,train_gen ,test_gen)
#class tranfer类
trainfer_model = keras.models.Model(
input=self.base_model.inputs ,
outputs = y_predict
)
transfer_model.compile(
optimizer = keras.optimizers.Adam(),
loss = keras.losses.sparse_categotical_crossentropy,
metrics=['accuracy']
)
#class tranfer类的自定义fit方法
def fit_generator(self ,model ,train_gen ,test_gen)
keras.callbacks.ModelCheckpoint('./ckpt/transfer_{epoch:02d}-{val_acc:.2d}.h5',
mointor='val_acc',
save_weight_only = True,
save_best_only = True,
model = 'auto',
period = 1
)
transfer_model.fit_generator(
train_gen ,
epochs = 3,
validation_data = test_gen,
callbacks=[model]
)
freeze模型训练 And 模型预测
from tensorflow.python.keras.preprocessing.image import ImageDataGenerator ,load_img ,img_to_array
#class transfer类
def predict(self ,model):
#加载模型 transfer_model
model.load_weights("./ckpt/transfer_02-0/93.h5")
#读取图片、处理
load_img(./data/test/dinosaurs/400.jpg ,target_size = (224 ,224))
image = img_to_array(image)
print(image.shape)
#四维(224 ,224 ,3)-> (1 ,224 ,224 ,3)
// image = tf.reshape(image ,[1 ,image.shape[0], image.shape[1], image.shape[2],] )
image = image.reshape(image ,[1 ,image.shape[0], image.shape[1], image.shape[2],] )
#处理图像内容,归一化处理等,进行预测
img = preprocess_input(img)
print(img.shape)
y_predict = model.predict(img)
index = np.argmax(y_predict ,axis = 1)
print(self.label_dict[str(index[0])])
#预测结果进行处理
image = preprocess_input(image)
predictions = model.predict(image)
print(predictions)
案例--商品物体检测
项目已部署上线,Web检测,百度机器人识别段。
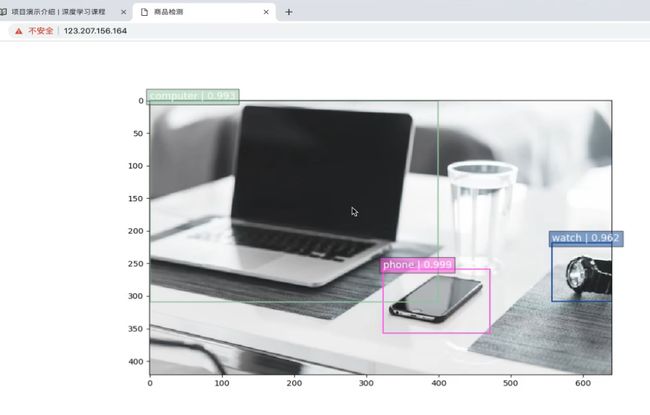
Tensorflow server部署,SSD和YOLO

目标检测算法:
两步走:先区分推荐,再进行目标分类。
R-CNN FastR-CNN FasterR-CNN
端到端:采用一个网络一步到位
YOLO SSD
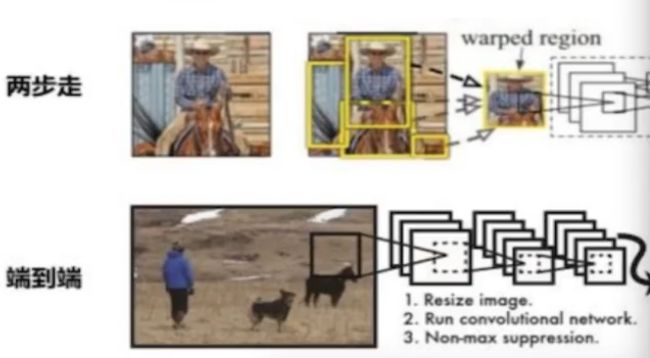
回顾图片分类的原理:
图片经过卷积、激活、池化相关层,最后加入全连接层。
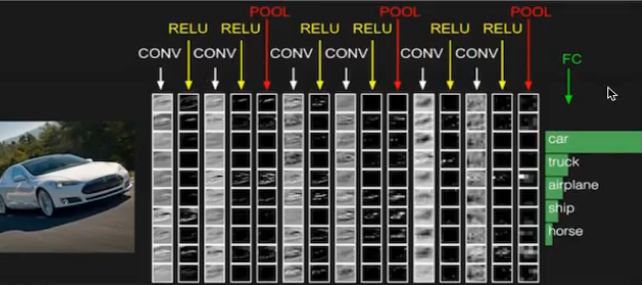
常见CNN模型: AlexNet VGG GoogleNet ResNet
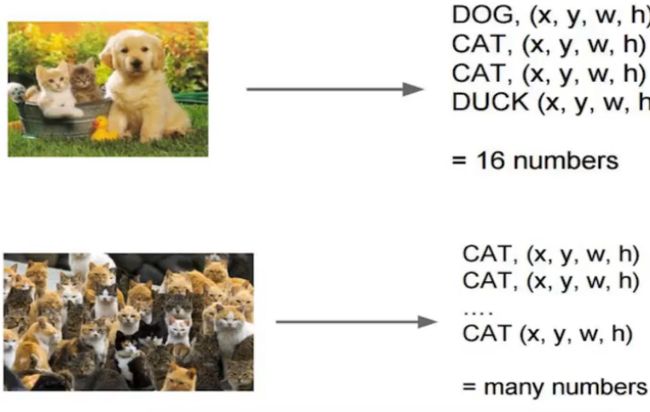
目标检测不仅仅是分类这么简单,还需要输出位置信息。
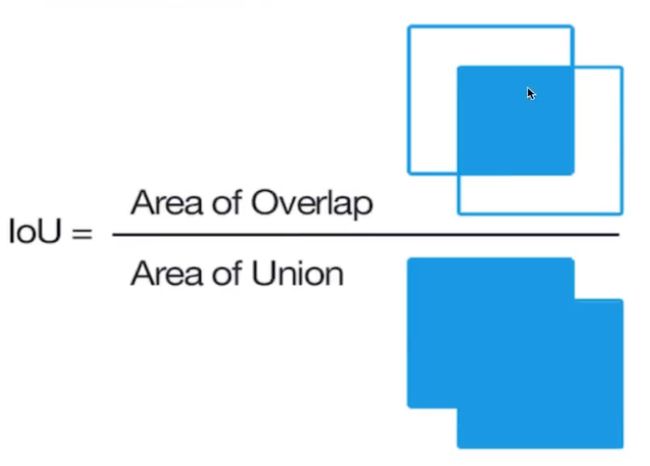
语义切割主要评估指标: IOU (Intersection over Union)
B-Box (bounding box): (x ,y ,w ,h)


Ground-truth bounding box : 图片真实标记的框 (人手画的)
Predicted bounding box:预测时标记的框
对于分类的概率,还是使用交叉熵损失。
位置信息具体的数值,可使用MSE俊芳误差损失(L2损失)
R-CNN (region proposal method 候选区域方法)
为什么要循环检测?
因为检测数量不确定。解决办法overfeat模型。
Overfeat方法: K X M
缺点是暴力破解,计算量大
CVPR2014年提出的R-CNN。
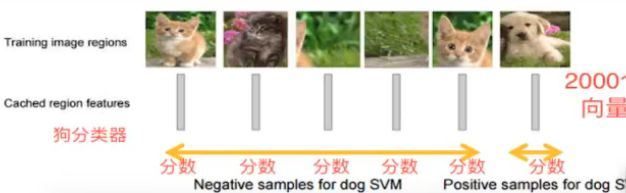
R-CNN的原理
论文中的步骤:
1 默认找图片中2k个候选区域region proposal
2 基于ALexNet的227X227,通过CNN提取特征,2000X4096维矩阵
3 2000X4096维矩阵经过SVM分类器(假如20种分类,SVM是二分类,则有20个SVM SVM分类已经过时), 2000X20种类别矩阵,[2000 20]得分。
4 对2000X20矩阵做非极大抑制(NMS non-maximum suppression) ,去除重复、不好的候选区域
5 修正B-box,对bbox做出回归微调
*候选区域(Region of Interset)
选择性搜索(SelectiveSearch),首先将每个像素分组,然后相近的像素进行合并。

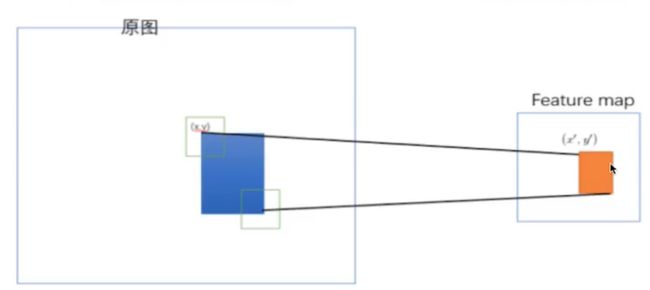
候选框的长宽不固定,不能直接输入ALexNet CNN网络
修正候选区域
bbox regression,回归用于修正筛选后的候选区域,使之归于ground-truth。默认是线性关系,因为最后筛选出来的候选区域和ground-truth。

目标检测—评估指标
IoU交并比
平均精确率(mean average precision map)
精确率/召回率 *

R-CNN总结
在VOC2007数据集上平均map准确率达到66%
缺点:
1 训练阶段多: 微调网络+SVM训练+训练边框回归器
2 训练耗时:5000张图片,几百G的特征文件
3 处理速度慢: GPU VGG16需要47秒
4 图形形状变化: 需要crop/warp进行处理
R-CNN改进 SPPNet
改进哪里了?改进的详细细节?
R-CNN最慢的步骤在哪里? 进行卷积运算。
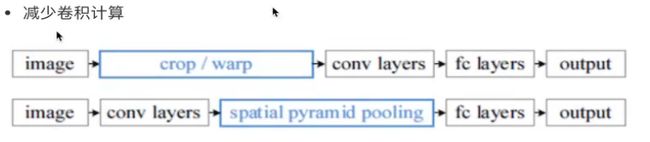


通过spatial pyramid pooling 将特征图转换成特定大小的特征向量。
CNN的改进 — Fast R-CNN
提出Rol pooling,然后整合模型,把CNN Rolpooling 分类器SVM B-box一起训练。
Softmax替换SVM
多任务损失 Multi-task loss
1 对分类损失,是一个N+1的softmax输出
2 对回归损失,是一个4XN的输出的regression
所以使用平均绝对误差MAE 损失,即L1损失
fine-tuning 训练
微调时,调整CNN + Rol pooling + softmax
调整bbox regression回归中的参数

缺点
使用Selective Search 提取 Region Proposals ,没有真正的端到端,比较耗时
CNN改进 Faster R-CNN
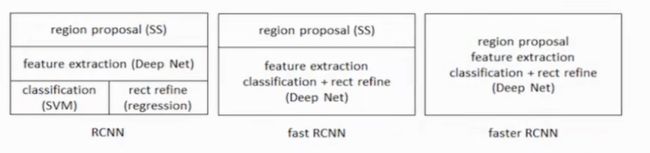
Faster R-CNN 看成区域特征生成网路,加上Fast R-CNN。
区域特征生成网络 Region Proposal Networks RPN :
用于生成region proposals,称之为anchors。
通过softmax判断anchors属于前景foreground还是背景background
bounding box regression 修正anchors获得精确的proposals
获取经验的2000个候选区
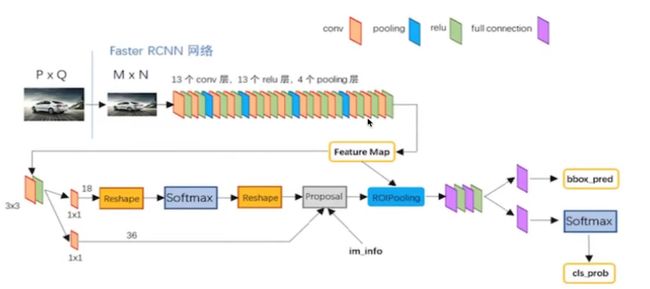
候选区域的训练:
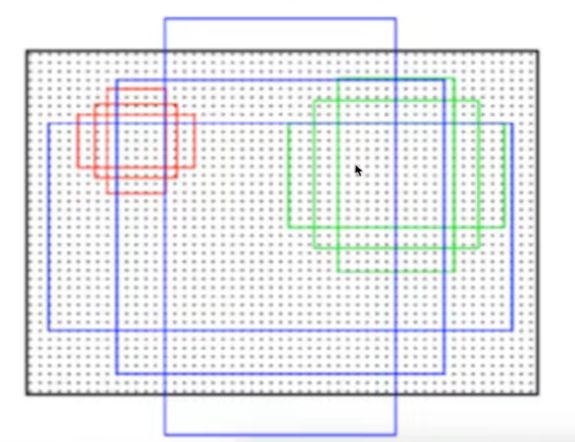
正负anchors样本比例 1:3
RPN的原理
目的是得到候选区域
使用nxn的大小窗口去扫描特征图,得到K个候选窗口
Faster R-CNN 的训练:
1 RPN的训练,得到score分高的候选区域
2 Fast R-CNN的训练
Fast R-CNN classificaion : 得到正确的分类
Fast R-CNN regression (B-Box loss) : 得到更好的位置
开源Keras Faster RCNN 模型介绍
地址 GitHub - jinfagang/keras_frcnn: Keras Implementation of faster-rcnn
代码笔记
assert 断言 ,不成立条件中断执行
__feature__ 使用python3的新特性
__iter__ 迭代器,返回的是对象本身
**kw 关键词参数,用于词典
pip install opencv-python #视频的OpenCv用途更大
代码架构:

工程里所有trainable = True
YOLO(You only look once)
YOLOv4 结构 :
GoogleNet + 4个卷积 + 2个全连接层
惊不惊喜,意不意外?
例如:

1 每一个单元格,计算两个候选框
2 对9 X2 = 18 个候选框,进行概率计算、筛选
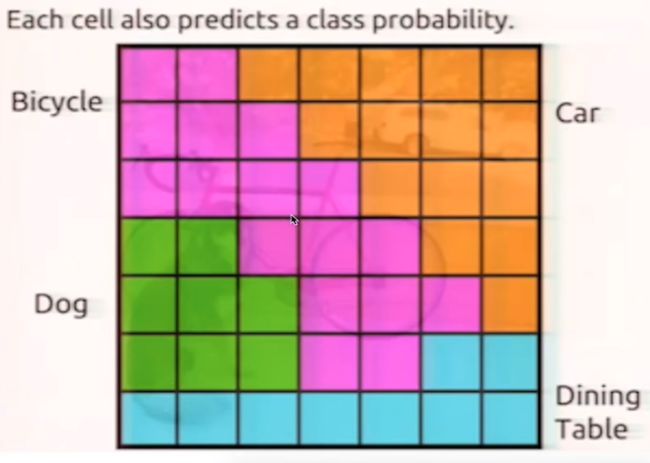
单元格 Grid Cell
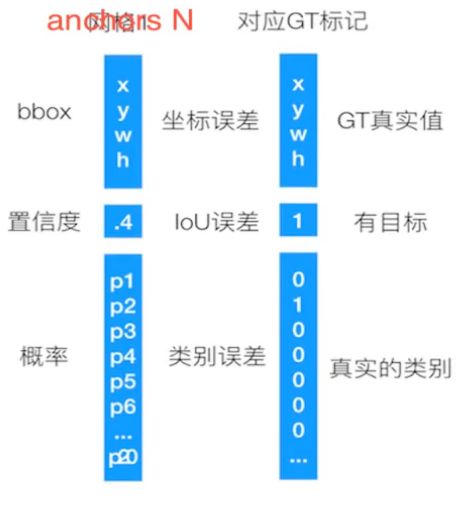
YOLOv4 网络层输出大小: 7X7X30

每个Grid Cell 需要预测一个物体类别
每个Grid Cell 预测两个(默认)B-box位置,两个B-box置信度。
一个B-box: xmin ymin xmax ymax confidence
两个B-box 4 +1 + 4 + 1 有10个值
所以一个Grid Cell 需要输出 10 + 20(预测) = 30 个值
Grid Cell 的Score值
如没有object,score是0
如果有object,score是object和confidence的乘积
一个object的ground truth,两个B-box的IoU值比较,确定自己的物体。
不同于faster rcnn 的anchors,yolo的框坐标直接由网络输出,在 7X7X30 的30里面。但是RPN网络对其优化得到一个更准的坐标和是否北京类别。
非最大抑制(NMS)
每个B-box的Class-Specific Confidence Score以后,设置阈值,滤掉概率低的bbox,对每个类别过滤IoU,得到最终检测结果
损失
三个部分 B-box损失 + confidence损失 + classfication 损失
与Faster R-CNN对比
Faster R-CNN利用RPN网络与真实值调整候选区域,然后再进行候选区域和卷积特征结果映射的特征向量,通过与真实值优化网络预测结果。
Yolo将这两步合成一步,直接网络输出预测结果进行优化。
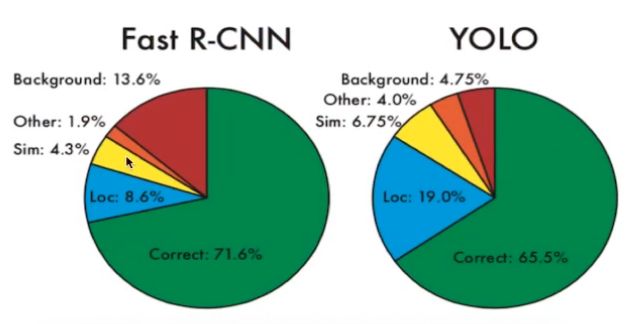
YOLO是回归法的代表,特点是块,缺点是准确率(Grid Cell 中间)
YOLO对运动跟踪的效果更好
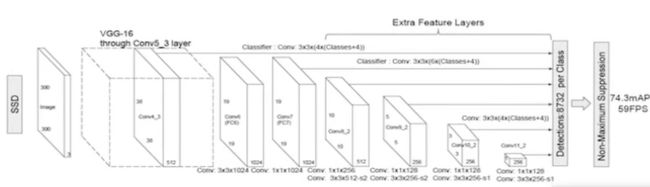
SSD (Single Shot MultiBox Detector)
2016年发表arxiv论文。结合yolo的回归思想和faster rcnn的anchors机制。
核心:不同尺度的特征图上采取卷积核预测一系列Default Bounding Boxes的类别、坐标偏移。
SSD以VGG-16为基础,使用VGG的前五个卷积,后面增加从Conv6开始的五个卷积结构,输入图片要求300*300
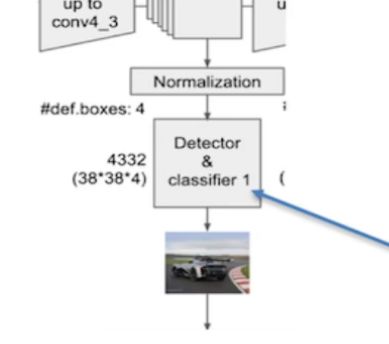
SSD会把中间不同尺度的特征图,再会进行BoundingBox的Detector & Classifier 预测

SSD会把中间不同尺度的feature map特征图都使用PriorBox层。
Detector & Classifier
PriorBox层由 Detector & Classifier 组成。

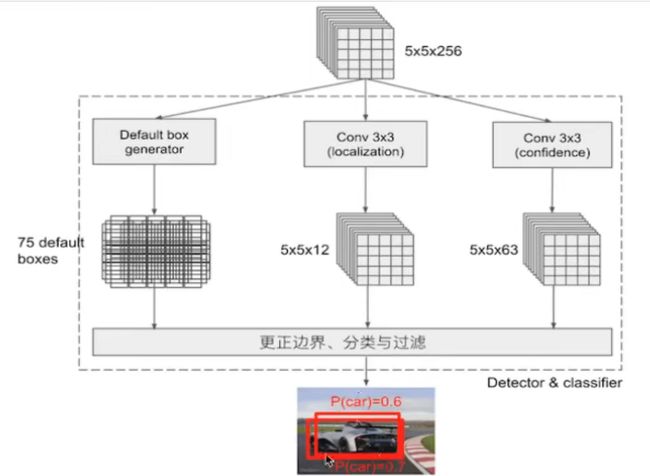
Detector & Classifier 的三个部分:
1 PriorBox层: 生成default boxes ,默认候选框
2 吸取YOLO邮电 Conv3X3 : 网络生成localization ,confidence,4个位置、预测概率、置信度
PriorBox 层 类似B-Box:

生成候选框后,prior_variance 做微调

SSD多个 Detector & Classifier的作用?
核心是在不同尺度的特征图上,进行Detector&Classifier容易使SSD观察到更小的物体。
localization & confidence
两者主要是用来过滤、训练

训练与测试流程
输入-> 输出-> 结果与ground truth标记样本回归损失计算-> 反向传播,更新权值
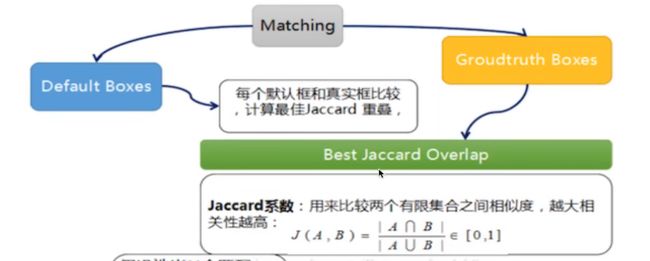
样本标记
将prior box 与ground truth box 做匹配,标记正负样本。先不训练8735张图片,先进行置信度筛选,并且训练指定的正负样本。
default boxes按照正负样本控制positive :negative = 1 : 3
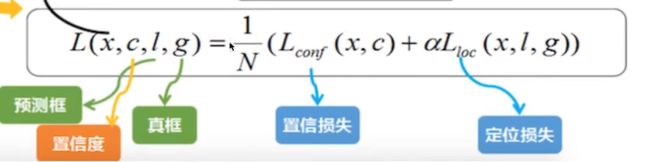
损失 losses
网络输出预测predict box 与ground truth回归变换之间的损失计算,置信度采用Softmax Loss(Faster R-CNN 是logstic loss),位置采用L1 losses。
测试test流程
输入 -> 输出 -> nms -> 输出
SSD兼顾速度和精度。
Keras SSD 代码结构
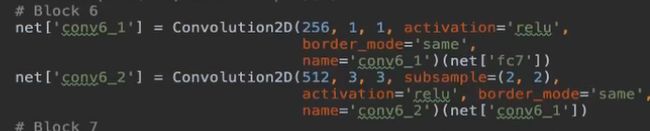
num_priors = 6 #配置好的关联框
案例: 利用SSD做图片的物体检测
输入数据,找几千个PriorBox,在非最大抑制NMS,输出结果
from nets.ssd_net import ssd300
from utils.ssd_utils import BBoxUtility
from tensorflow.python.keras.preprocesing.iamge import load_img ,img_to_array
from scipy.misc import imread
from keras.applications.imagenet_utils import preprocess_input
import os
class SSDTest(object):
def __init__:
self.classes_name = ['car' ,'sofa' 等等]
self.classes_nums = len(self.classes_name) + 1
self.input_shape = (300 ,300 ,3)
def test(self):
#SSD300模型的输入以及加载参数
model=SSD300(self.input_shape ,num_classes=self.classes_nums)
#加载训练好的模型
model.load_weights("./ckpt/weights_SSD300.hdf5" ,by_name=True)
#读取多个本地路径测试图片,preprocess_input以及保存图片像素值
feature = []
images_data = []
for path in os.listdir("./images"):
img_path = os.path.join("./images" ,path)
image=load_img(img_path ,target_size=(self.input_shape[0] ,self.input_shape[0] ))
image = img_to_array(image)
feature.append(image)
images_data.append( imreadimread(img_path)) # 图片数据集
#预处理需要数组,不能是列表
#inputs = preprocess_input(feature)
#print(inputs)
inputs = preprocess_input(np.array(feature))
print(inputs)
#模型预测结果,处理7308个PriorBox
pred= model.predict(inputs ,batch_size =1 ,verbvose=1)
print(pred.shape)
#形状是(2 ,7308 ,33)
# 2 张图片数量 ,7308个PriorBox ,33: 4+ 21+ 88(position confidence )
#进行非最大抑制算法处理NMS
bb = BBoxUtility(self.classes_nums)
res = bb.detection_out(pred)
print(res)
print(res[0].shape ,res[1].shape)
# (200 ,6) (200,6)
#NMS后还有200个PriorBox ,6是label location xmin ymin xmax ymax
return res ,images_data
def teg_picture(self ,images_data ,outputs):
for i , img in enumerate(images_data):
pre_label = outputs[i][: , 0]
pre_conf = outputs[i][: , 1]
pre_xmin = outputs[i][: , 2]
pre_ymin = outputs[i][: , 3]
pre_xmax = outputs[i][: , 4]
pre_ymax = outputs[i][: , 5]
print("pre_label:{} ,pre_conf:() ,pre_xmin:{} ,pre_ymin:{} ,pre_xmax:{} ,pre_ymax:{}" .format(pre_label ,pre_conf ,pre_xmin ,pre_ymin ,pre_xmax ,pre_ymax))
#概率预测结果太多,置信度大于90%的图片我们看一下
top_indeicts = [i for i ,conf in enumerate(pre_conf) if conf > 0.9]
top_label_indices = pre_label[top_indeicts].tolist()
top_xmin = pre_xmin[top_indices]
top_ymin = pre_ymin[top_indices]
top_xmax = pre_xmax[top_indices]
top_ymax = pre_ymax[top_indices]
print("after filter top_label:{} ,top_conf:() ,top_xmin:{} ,top_ymin:{} ,top_xmax:{} ,top_ymax:{}" .format(top_label ,top_conf ,top_xmin ,top_ymin ,top_xmax ,top_ymax))
#matplot画图显示
#定义21种颜色,显示图片
#currentAxis增加图片中文本显示和标记
colors = plt.m.hsv(np.linspace(0,1,21)).tolist()
plt.imshow(img / 255.)
currentAxis = plt.gca()
for i in range(top_conf.shape[0]):
xmin = int(round(top_xmin[i] * img.shape[1]))
ymin = int(round(top_ymin[i] * img.shape[0]))
xmax = int(round(top_xmax[i] * img.shape[1]))
ymax = int(round(top_ymax[i] * img.shape[0]))
#获取图片的预测概率,名称,定义显示颜色
score = top_conf[i]
label = int(top_label_indices[i])
label_name = self.classes_name[label-1]
display_txt = '{:0.2f} ,{}'.format(score ,label_name)
coords = (xmin ,ymin),xmax - xmin + 1 ,ymax - ymin + 1
color = colors[label]
#显示方框
currentAxis.add_patch(plt.Rectangle(*coords ,fill= False ,edgecolor = color , 'alpha':0.5))
lt.show()
return None
if __name___ == '__main__':
ssd = SSDTest()
res = ssd.test()
ssd.tag_picture(images_data ,outputs)
常用目标检测检测数据集介绍
pascal Visual Object Classes

Classification Detection Segementation PersonLayout 由VOC2007 VOC2012提供

Open Images Dataset V4
谷歌提供
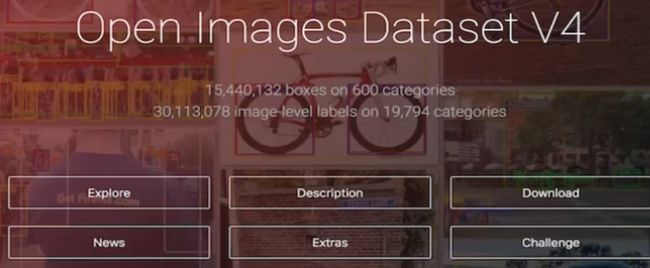
2018年发布190万张图片,针对600类别的1540万个边框盒
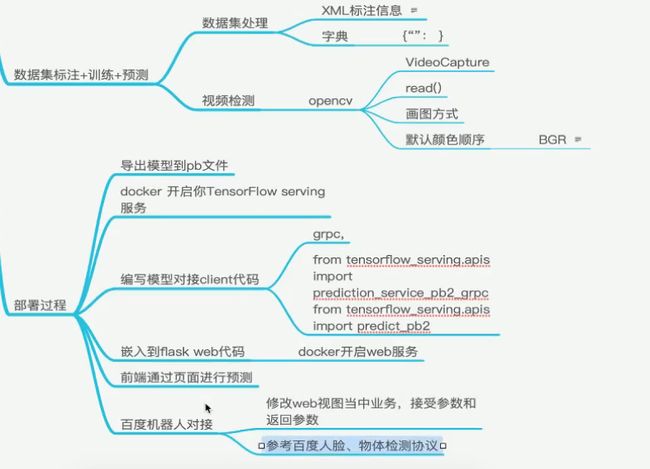
XML对应标记信息

数据集的目标标记
提供给训练的数据样本,图片和目标真实结果
特定的场景会缺少标记图片
LabelImg的图形图像注释工具。基于QT。注释以PASCAL格式保存。

Linux MacOS的教程
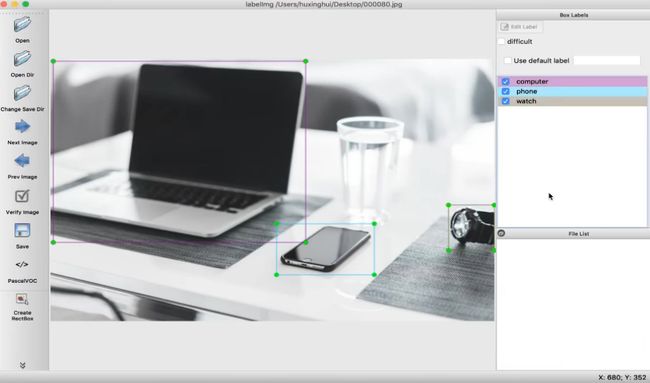
商品检测数据集的处理
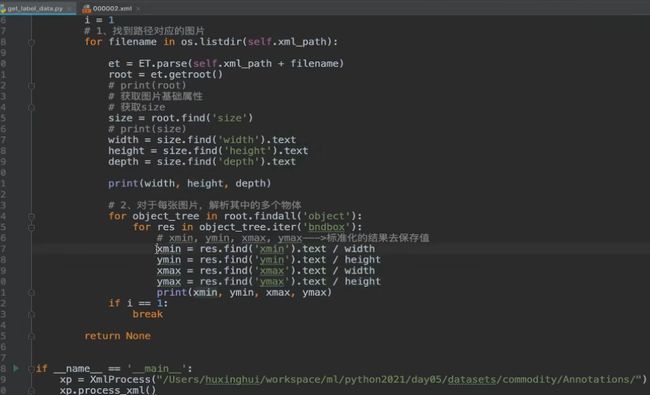
XML的结构解析
from xml.etree import ElementTree as ET
tree = et.parse(filename) #获得树形结构
tree.getroot() #获得树根
root.find() 与 findall()进行查询XML每个标签的内容
商品检测数据集的存储

复习(一)
YOLO的结构:
GoogleNet + 4个卷积 + 2个全连接
网络输出大小 7X7X30
单元格Grid Cell
一个B-box: xmin ymin xmax ymax confidence
损失
bbox损失 + confidence损失 + classification损失
优点
速度快,适合视频和跟踪
缺点
对单元格分割处不敏感,对小物体不敏感
SSD的结构:
基本结构同YOLO
Detector & Classifier 块:
组成PriorBox层,默认的候选框群
Conv3X3 组成localization,4个位置偏移
Conv3X3 组成confidence,21个类别置信度(需要区分前景背景)
数据集的制作和保存
复习(二)
训练时的fine tuning
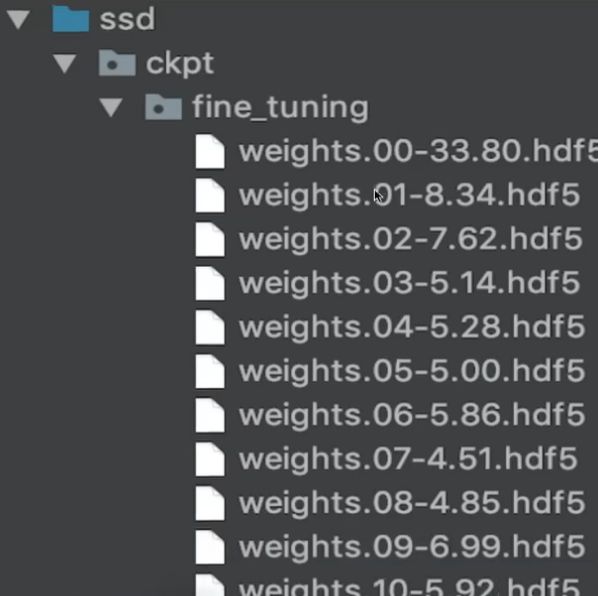
案例 商品物体检测
上章节的分类图片迭代器
keras.preprocessing.image import ImageDataGeneratorm
本地图片,标注分割数据类
from utils.detection_generate import Generator
1 初始化模型参数以及冻结部分结构
2 compile与fit_generator
from utils.ssd_losses import MultiboxLoss
指定模型冻结
freeze = [
'input_1' , 'conv1_1' ,'conv1_2','pool1',
'conv2_1',‘conv2_2’,‘pool2’,
'conv3_1', 'conv3_2' , 'conv3_3' ,'pool3'
]
for L in self.model.layers :
if L.name in freeze:
L.trainable = False
SSD训练商品数据
略。
同以上,无新意。
问题解决与多GPU训练
GPU训练
英伟达
tf.keras DistrubutionSttrategy
OpenCv介绍


视频捕捉
cv.VideoCapture()
CV颜色空间转换
HSV(色相 饱和度 明度)是一种将RGB彩色模型的点,在圆柱种表示的方法。
cv2.COLOR_BGR2GRAY
cv2.COLOR_BGR2HSV
cv2.COLOR_BGR2RBGB

CV画框画图
案例--视频检测介绍获取帧数据
太简单了。
CV采集视频,上文的SSD,NMS置信区间判断物体。
案例--视频检测介绍获取帧数据(2)
文本框显示

显示FPS
总结:
1 图片的大小会变化
2 图片的信息shape ,随着处理,Tensor一直在变。
模型部署逻辑
- 1 将训练好的模型,进行导出,tf.export工具
- 2 使用TensorFlow serving 开启模型服务
- 3 编写模型客户端程序,在web后台使用

模型格式pb
可以支持热更新
Serving服务安装开启和Serving
使用Docker部署

Client端代码

Serving Client 代码编写
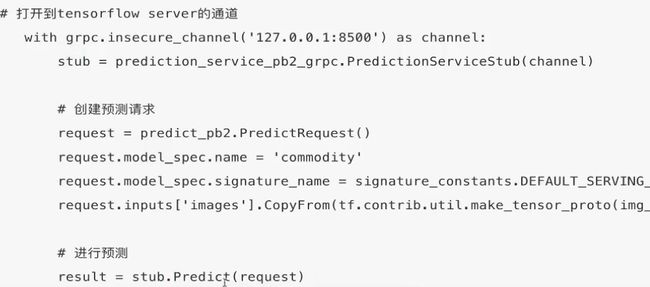
这样做的目的,是服务端/客户端的分离,方便成员分工。
再次见到 Session
Web服务开启和Client对接
讲道理,这里不是核心知识,而且有点过时。
百度机器人接口对接
不完全开源
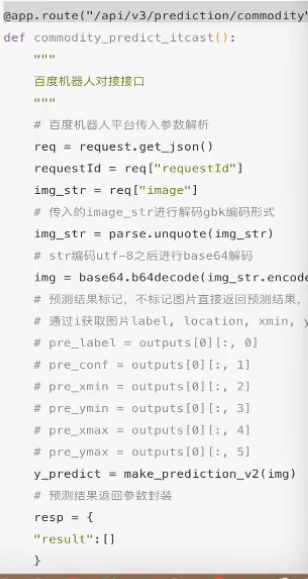
百度飞浆平台
收费
很多好的模型
人脸识别
模型基础都是BERT
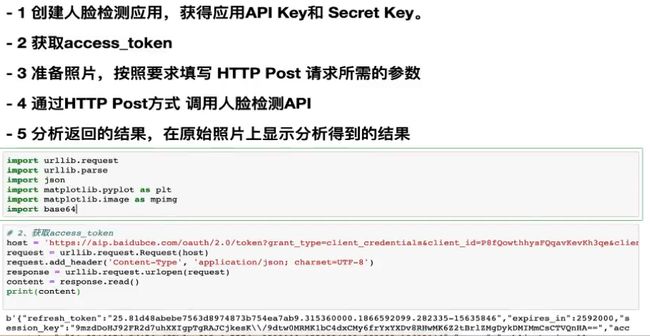
人脸SDK
文字识别
识别笔画、语系
进行CNN识别
高精度的文字识别(生僻字)
调超参数
车牌识别
通用发票识别
语音识别
讯飞、搜狗、阿里
普通话、四川话、粤语
特征
傅里叶转换,正弦周期性
语音合成
物体检测课程总结



*
上述视频录制时间是2019年。技术2至5年一代,理论20至50年一代。