【yoloV5实战记录】小白也能训练自己的数据集!
这里是目录,可以自行空降哦~
-
-
- 数据集采样
- 数据标注
-
- 工具安装
- 初始化项目
- 开始标注
- 数据导出
- 模型训练
-
- YOLOV5安装
- 文件配置
- 模型训练
- 模型验证
- 结语
-
数据集采样
由于本次的任务是训练自己的数据集,因此我们直接采用OpenCV来进行直接采集。采集好的数据样本一共56张图片。
这里奉上我的采样脚本:
#Author: Elin.Liu
# Date: 2022-11-13 16:17:31
# Last Modified by: Elin.Liu
# Last Modified time: 2022-11-13 16:17:31
import cv2
import time
# 这里指定cv2.VideoCapture函数从哪一个媒体流获取
# 当指定为0时,表示为从笔记本的内置摄像头获取流
# 否则可以指定为字符串表示一个本地的视频流,或者网络摄像头串流
cap = cv2.VideoCapture(<InputSource>)
i = 1
while True:
# cap.read()函数会返回两个值
# 第一个表示是否初始化摄像头
# 第二个则是读取到的图像的Numpy矩阵
ret, frame = cap.read()
# 使用cv2.imshow()显示当前帧
cv2.imshow('frame', frame)
# 使用cv2.imwrite()写入当前帧
cv2.imwrite(f"../data/capture_{100+i}.jpg", frame)
# 迭代指针累加
i += 1
# 使用cv2.waitkey()获取当前键盘是否按了一下q
if cv2.waitKey(1) & 0xFF == ord('q'):
# 则终止循环
break
# 释放摄像头资源
cap.release()
数据标注
这里我很不推荐新手(其实就是我~~~)使用labelimg这个工具,为什么?因为labelimg你需要手动的去调整数据集的结构。
但?就没有懒人使用的工具吗?
工具安装
答案是有的!label-studio,一款基于Django的WEB数据标注平台,原生支持Yolo,coco等数据集导出,自动打包!
对,你没听错,你再也不用为数据结构错误而导致yolo模型无法训练的烦恼了!
调用pip来进行安装即可开箱即用
pip install -m label-studio -i https://pypi.tuna.tsinghua.edu.cn/simple
下载好后,可以直接调用bash命令:label-studio来进入。
通过阅读英文,并按照操作注册一个本地的label-studio账号即可开始我们的数据标注之旅啦~
初始化项目
注册好后我们会进入到如下的界面:

通过界面可以看到我们这里已经有了两个标注项目,已经顺利标注完了所有的图像。
不过,对于需要创建一个新项目的同学而言,则是需要点击右上角蓝色的create按钮,点击create按钮后,出现了如下的界面:
之后我们点击Data Import按钮,label-studio支持直接对文件进行拖拽,它可以自动识别目标压缩包下的文件或者你准备上传的文件数量及类型。
导入玩数据后,我们需要指定这个项目是一个什么类型的项目,因此需要点击Labeling Setup按钮进行设置:
由于我们是为YOLO模型准备的数据集,所以我们需要加载object detection with bouding boxes这个模板:
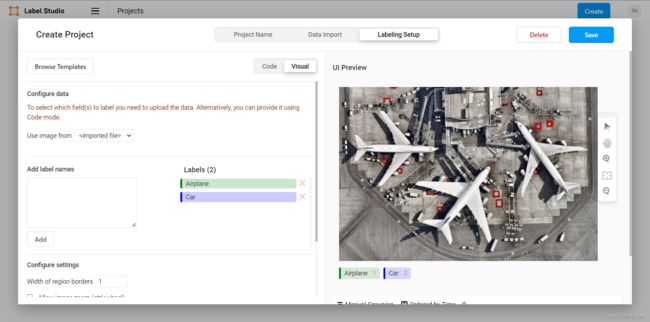
可以看到这里模板为我们初始化了两个label,一个是car汽车,一个是airplane飞机。这里我们可以视情况选择是否保留它们。
开始标注
在我们完成以上的配置后,则可以点击save按钮执行标注了任务啦。
点击完save按钮后,我们跳转到了如下的界面:
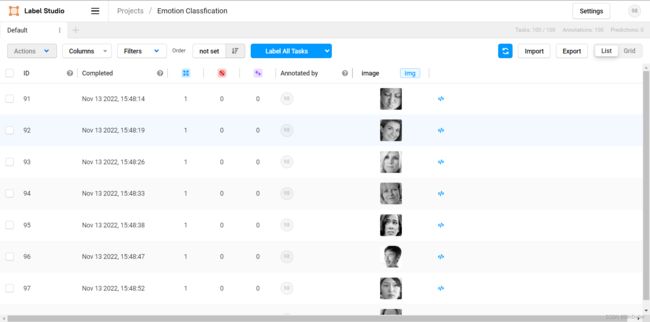
这里我们点击Label All Tasks按钮开始标注,进入到标注界面后,通过点击图片下方的标签按钮进行标注,每标注完一个图片,我们可以点击submmit按钮进行结果的提交,如果我们需要修改图像时,则submmit按钮会变成update按钮进行更新。
当所有的标注任务完成之后,我们就会变成如下的界面,提示我们没有多余的任务了:
数据导出
完成后退回到项目界面,点击Export按钮后,我们可以指定我们的导出模式:
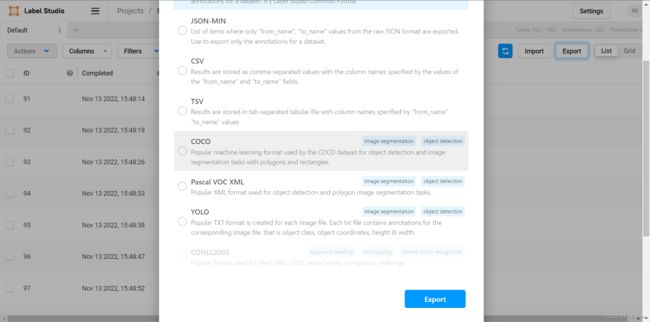
在这里,你可以根据你所使用的算法进行导出,这里我们点击yolo选项进行导出。
这时,你的浏览器会自动下载数据压缩包:
![]()
数据结构如下:
total 40
drwxr-xr-x 4 elin elin 4096 Nov 13 18:29 .
drwxr-xr-x 5 elin elin 4096 Nov 13 18:21 ..
-rw-r--r-- 1 elin elin 36 Nov 13 18:21 classes.txt
drwxr-xr-x 2 elin elin 4096 Nov 13 18:21 images
drwxr-xr-x 2 elin elin 4096 Nov 13 18:21 labels
-rw-r--r-- 1 elin elin 13403 Nov 13 18:29 labels.cache
-rw-r--r-- 1 elin elin 283 Nov 13 18:21 notes.json
模型训练
在准备完我们的数据集后,我们就可以开始进行模型的训练了。
既然你能点开我的文章,就证明你已经掌握了如何安装cudnn、cuda了,这里不做赘述了。
YOLOV5安装
那么我们怎么来获得yoloV5呢?这里我将yolov5官方仓库的链接放在这里了。
使用
git clone https://github.com/ultralytics/yolov5
命令将yolov5的仓库克隆下来之后,我们则可以使用
pip install -r requirements.txt
来安装yolov5的依赖项。
文件配置
还记得我们之前准备的数据集吗?现在就有了大用了。
为了不破坏yolov5的原始框架,我们可以自己在项目结构下创建如下的配置文件:./data/myconf.yaml并写入如下的文件
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
# path: ../data/ # dataset root dir
train: ../../../data_yolo/images/ # train images (relative to 'path') 128 images
val: ../../../data_yolo/images/ # val images (relative to 'path') 128 images
test: # test images (optional)
nc: 3
names: ["Fiddling Hands", "Idling", "Playing Phone"]
- 这里train指定的是我们之前使用label-studio导出的文件,包含
images,labesl,labels.cache,classes.txt和notes.json这些文件的路径。 - val指定的是验证集,这里我们仍然保留train的路径
- nc是
num_classes的所有,表示的是类别数量,这里我们需要识别的是3个类别,因此需要的是3 - names:传入一个数组,与nc长度相等,每一个元素是我们需要识别的类的名称,这里建议与label-studio导出的顺序保持一致。
模型训练
在修改完配置文件后,我们则可以开始我们的模型训练,切换目录到yolov5的主目录下,调用如下的bash指令:
python train.py --epochs 100 --batch 8 --data myconf.yaml --weight yolov5l.pt --device 0
- 这里ephocs指的是迭代次数,如果你对深度神经网络以及深度学习有所了解的话,应该不需要再关心它的定义是什么了
- batch表示我们每一个迷你批次中的数据量大小为多少,这里笔者的GPU是RTX2060,CUDA官方指出的
computbility为7.5,因此我们设置过大的迷你批次大小,会导致模型无法顺利训练完成,这里读者可以视自己的实验环境自行斟酌。 - data代表着我们的配置文件路径,由于刚才我们创建的文件名叫
myconf.yaml,所以这里直接输入myconf.yaml即可 - weight指定初始化的权重文件,这里我放出一张来自YOLOV5官方的介绍图,读者可以自行考虑自己实验环境的计算能力来进行判断。
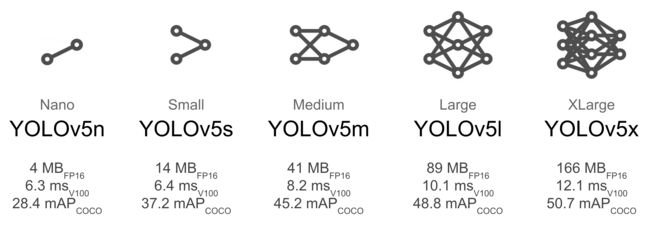
这里考虑到了模型的准确率,我们选择YOLOV5L这个模型进行训练
- device指定为GPU的设备序列号,因为这里笔者只有一张GPU,因此设备ID为0,如果读者有多卡训练的情况下,可以自行寻找多卡GPU的训练方式,本文不做过多的探讨。如果读者没有GPU可以,则可以传入参数CPU来指定使用CPU来训练YOLOV5。
好了,在知道这些参数的涵义之后,我们只需要按下回车键进行训练就好了。
模型验证
这里我们执行模型的验证,可以使用yolov5架构内自带的detect.py进行验证。这里调用如下的bash命令来执行识别:
python detect.py --weight ./runs/train/exp2/weights/best.pt --source <InputSource> --device 0
- weight同如上的训练命令的定义一样,但是请注意,如果模型多次训练过,请读者一定确定
./runs目录下的最终输出路径,这里我们的最终输出时exp2这个路径,我们调用该路径下的weights下的best.pt这个权重文件 - source指定输入源,同OpenCV一样,我们需要在这里为detect.py配置好我们的媒体流。
- device与如上train的含义一样,这里不做赘述。
结语
以上就是本次文章的全部内容,希望你能玩的开心,我们下期博客再见咯~