机器学习三:决策树
机器学习三:决策树
- 1. 介绍
- 2. 参数
-
- 2.1. min_samples_split
- 2.2. 不纯度和熵
-
- 2.2.1 信息增益
-
- 2.1.1.1 信息增益计算
- 3. Bias-Variance Dilemma
- 4. 总结
- 5. SK Learn
1. 介绍
决策树是机器学习中最早也是最常使用的算法之一,它已经有几十年历史,稳定性非常好。
它和支持向量机类似,也可以在这里使用核技巧,将线性决策面转换为非线性。决策树可以通过核技巧把简单的线性决策面转换为非线性的决策面。
举个例子,有个叫 Tom 的朋友,他非常喜欢冲浪,而冲浪需要满足两个条件:要有风和太阳。我们列出去年每天的天气作为数据点,他不会在天气不够晴朗时冲浪,也不会在风力较弱的时候冲浪,但是当有风且天晴的时候,他就可以冲浪了。如下左图所示,很显然这个数据是线性不可分的。

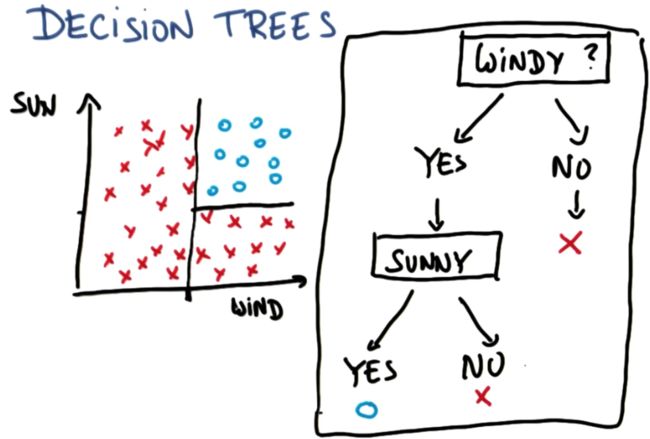
这时可以用决策树一个接一个地处理多元线性问题。其实本质上来说,可以首先问:有风吗?根据是否有风,我们可以在这个轴上设定一个阈值。根据不同答案,选择树的对应分支。实际上,这就等于在图上的位置设定一个线性决策面。
决策树后面的部分如何构建呢?对于有风的情况,我们问另一个问题:即天气是否晴朗。如果回答是天气晴朗,那么就会得到蓝色的圈,也就是可以冲浪;如果答案是天气不晴朗,那就会得到红色的叉,也就是不能冲浪。
该决策如上右图所示,我们把它称为决策树,而机器学习中的决策树学习就是将根据类似这样的数据去寻找这样的图,通过树这种简单的数据结构对新数据进行分类。
2. 参数
2.1. min_samples_split
min_samples_split 的作用是这样的:比方说我们的决策树从一系列训练样本开始然后将它们分隔成更小的子集,在某个阶段必须明确是否还能继续分隔下去。
例如,我们开始时用 100 100 100 个样本,那么分隔后可能会分别得到 60 60 60 和 40 40 40 个样本,然后这边可能会分别得到 40 40 40 和 20 20 20 个,再然后,这里的 20 20 20 个样本可能会分隔成 15 15 15 和 5 5 5 个,以此类推。
问题是,对于决策树最下层的每一个节点是否还要继续进行分隔,也就是说 min_samples_split 决定了能够继续进行分隔的最少分割样本。换句话说,是否有足够的样本数来继续进行分割。这个参数的默认值为 2 2 2。因此,除其中一个以外,这些叶子节点都可以被继续分隔。
 现在来看看这个参数的作用。这里有两个决策树,一个非常复杂,有很多零碎的决策边界,另一个相对比较简单,大概只有两三处转折。两个决策树的 min_samples_split 分别被设为了 2 2 2 和 50 50 50。很容易可以看出左边的为 2 2 2 而右边的为 50 50 50,右边的在准确率上很可能会高一点点,虽然差别不大,但这一提升仅仅是通过这一项参数的调整就轻松获得的。
现在来看看这个参数的作用。这里有两个决策树,一个非常复杂,有很多零碎的决策边界,另一个相对比较简单,大概只有两三处转折。两个决策树的 min_samples_split 分别被设为了 2 2 2 和 50 50 50。很容易可以看出左边的为 2 2 2 而右边的为 50 50 50,右边的在准确率上很可能会高一点点,虽然差别不大,但这一提升仅仅是通过这一项参数的调整就轻松获得的。

2.2. 不纯度和熵
熵(Entropy) 是一个对于决策树非常重要的问题。熵主要控制决策树,决定在何处分隔数据,它是一系列样本中的不纯度(impurity) 的测量值。
熵是有数学公式的:
Entropy = − ∑ i ( p i ) log 2 ( p i ) \text { Entropy }=-\sum_{i}\left(p_{i}\right) \log _{2}\left(p_{i}\right) Entropy =−i∑(pi)log2(pi)其中 p i p_i pi 是第 i i i 类中的样本占总样本数的比例。然后,对所有类的结果求和。
从定义中可以看出,熵与数据单一性呈负相关的关系,在一种极端情况下,所有样本属于同一类,在这种情况下熵为 0 0 0。在另一种极端情况下,样本均匀分布在所有类中,在这种情况下熵将达到其数学上的最大值 1.0 1.0 1.0。

2.2.1 信息增益
现在来看看实际上熵是如何影响决策树确定其边界的,这涉及到一个新的术语-------信息增益(Information Gain)。信息增益定义为父节点的熵减去子节点的熵的加权平均,这些子节点是划分父节点后生成的。
Information gain = entropy(parent) − [weighted average]entropy(children) \text {Information gain}=\text {entropy(parent)} -\text{[weighted average]}\text {entropy(children)} Information gain=entropy(parent)−[weighted average]entropy(children)决策树算法会最大化信息增益,它通过这种方法来选择进行划分的特征。如果特征可以取多个不同值,该方法将帮助它找出在何处进行划分。总之,它会把信息增益最大化。
2.1.1.1 信息增益计算
现在我们举个例子,假设数据是下图这样的。有四个数据点,每个数据点有三个特征,分别是:坡度、颠簸程度、是否超过限速,以及车的行驶速度。

首先从决策树的顶端开始计算父节点的熵。这里有两个需要减速行驶和两个可以快速行驶的样本:slow-slow-fast-fast,共四个样本。因此这里为减速行驶的样本比例与快速行驶的样本比例均为 p i = 2 / 4 = 0.5 p_i = 2/4 = 0.5 pi=2/4=0.5。因此最终熵的结果为:
Entropy = − ∑ i ( p i ) log 2 ( p i ) = − 0.5 log 2 ( 0.5 ) − 0.5 log 2 ( 0.5 ) = 1.0 \text { Entropy }=-\sum_{i}\left(p_{i}\right) \log _{2}\left(p_{i}\right) = -0.5\log _{2}\left(0.5\right)-0.5\log _{2}\left(0.5\right) = 1.0 Entropy =−i∑(pi)log2(pi)=−0.5log2(0.5)−0.5log2(0.5)=1.0
然后用信息增益来确定对哪个变量进行划分。
先利用信息增益对 grade 这一变量进行计算,平坡和陡坡分支上分别有 1 1 1 个和 3 3 3 个样本。因为平坡上只有一个样本类别 fast,所以在平坡节点上的熵为 0 0 0。而陡坡上有两个 slow 和一个 fast,该节点上的熵为:
Entropy = − ∑ i ( p i ) log 2 ( p i ) = − 1 3 log 2 ( 1 3 ) − 2 3 log 2 ( 2 3 ) = 0.9184 \text { Entropy }=-\sum_{i}\left(p_{i}\right) \log _{2}\left(p_{i}\right) = -\frac{1}{3}\log _{2}\left(\frac{1}{3}\right)-\frac{2}{3}\log _{2}\left(\frac{2}{3}\right) = 0.9184 Entropy =−i∑(pi)log2(pi)=−31log2(31)−32log2(32)=0.9184这个子节点的熵为:
Entropy(children) = 3 4 ( 0.9184 ) + 1 4 ( 0 ) \text { Entropy(children) }=\frac{3}{4}(0.9184)+\frac{1}{4}(0) Entropy(children) =43(0.9184)+41(0)信息增益为:
Information gain = 1 − 3 4 ( 0.9184 ) = 0.3112 \text { Information gain }= 1-\frac{3}{4}(0.9184)=0.3112 Information gain =1−43(0.9184)=0.3112使用相同的方式,可以得到 bumpiness 和 speed limit 的信息增益分别为: 0 0 0 和 1.0 1.0 1.0,这里 1.0 1.0 1.0 是我们所能得到的最大信息增益,所以 speed limit 就是应该进行划分的变量。
3. Bias-Variance Dilemma
高偏差机器学习算法实际上会忽略训练数据,它几乎没有能力学习任何数据,这被称为偏差。所以,对一个有偏差的汽车进行训练,无论训练通过何种方式进行它的操作都不会有任何区别。
但也可能进入另一个极端情况:也就是汽车对数据高度敏感,它只能复现曾经见过的东西,那样就会是一个方差极高的算法。它的问题在于,对于之前未见过的情况它的反应非常差,因为没有适当的偏差让它泛化新的东西。
所以,真正想要的算法是两者的折中,也就是所谓的偏差—方差权衡,这需要调参来完成。
4. 总结
决策树非常易于使用,完整的决策树结构会很漂亮。从某种程度上来说,它们能以图形化方式很好地剖析数据,这比支持向量机的结果要容易理解得多。
但是它们也存在一些不足:决策树存在的一个缺点就是容易过拟合。尤其对于具有包含大量特征的数据时,复杂的决策树可能会过拟合数据。所以需要谨慎对待决策树的参数,仔细调整参数以避免过拟合。
对于节点上只有单个数据点的决策树,这几乎肯定是发生了过拟合。所以,测量决策树的准确率是非常重要的,需要在适当的时候停止决策树的生长。
决策树还有一个很棒的地方,就是可以通过所谓的集成方法从决策树出发构建更大规模的分类器,也就是从一个分类器出发构建另一个分类器。
5. SK Learn
决策树(DTs) 是一种用于分类和回归的无参数监督学习方法。其目标是创建一个模型,通过学习从数据特征推断出的简单决策规则来预测目标变量的值。一个树可以被看作是一个近似常数的分段。
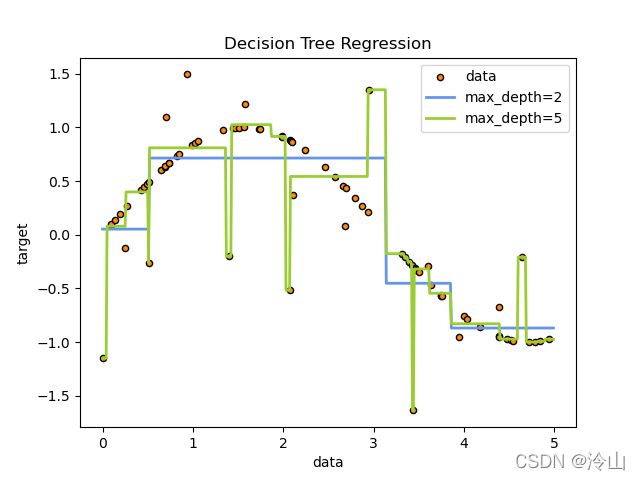
例如,在下面的例子中,决策树从数据中学习,使用一组if-then-else决策规则来逼近正弦曲线。树越深,决策规则越复杂,模型越适合。
 优点:
优点:
- 简单易懂,易于解释。树可以被可视化;
- 只需要很少的数据准备。其他技术通常需要数据归一化、需要创建虚拟变量和删除空白值。但是请注意,此模块不支持缺失值;
- 使用树(即,预测数据)的成本为用于训练树的数据点数量的对数;
- 能够处理多输出问题;
- 使用白盒模型。如果给定的情况在一个模型中是可观察到的,那么对这个条件的解释很容易用布尔逻辑来解释。相比之下,在黑盒模型中(例如,在人工神经网络中),结果可能更难解释;
- 可以使用统计测试来验证模型。这使得解释模型的可靠性成为可能;
- 即使生成数据的真实模型在某种程度上违反了它的假设,它也能很好地执行。
缺点:
- 决策树学习者可能会创建过于复杂的树,不能很好地概括数据。这叫做过拟合。为了避免这个问题,需要使用修剪、设置叶子节点所需的最小样本数量或设置树的最大深度等机制。
- 决策树可能是不稳定的,因为数据中的小变化可能导致生成完全不同的树。通过在集合中使用决策树,可以缓解这个问题。
- 决策树的预测既不是平滑的,也不是连续的,而是如上图所示的分段常数近似。因此,他们不擅长外推。
- 学习最优决策树的问题是已知的 NP-complete 在几个方面的最优性,甚至简单的概念。因此,实际的决策树学习算法是基于启发式算法,如贪婪算法,在每个节点上做出局部最优决策。这种算法不能保证返回全局最优决策树。这可以通过在集成学习器中训练多棵树来缓解,其中特征和样本是随机采样的替换。
- 有些概念很难学习,因为决策树不容易表达它们,比如异或、奇偶校验或多路复用问题。
- 如果某些类占主导地位,决策树学习者会创建有偏差的树。因此,建议在拟合决策树之前平衡数据集。
文章跳转:
机器学习一:朴素贝叶斯(Naive Bayes)
机器学习二:支持向量机
传统物体检测