20天吃pytorch 3-3 高阶API 遇到问题及分析
目录
1. 报错 module 'pytorch_lightning' has no attribute 'metrics'
2. 为什么Model可以传入参数net?
3. model和下边的Trainer有什么关系?是怎么开始训练的?pl.callbacks.ModelCheckpoint(monitor="val_loss")是什么意思?
1. 报错 module 'pytorch_lightning' has no attribute 'metrics'
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(2,4)
self.fc2 = nn.Linear(4, 8)
self.fc3 = nn.Linear(8,1)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
y = nn.Sigmoid()(self.fc3(x))
return y
class Model(torchkeras.LightModel):
#LightModel定义是要传入一个参数net的,对net自动调用forward方法
#->常常出现在python函数定义的函数名后面,为函数添加元数据,描述函数的返回类型,从而方便开发人员使用
#loss,and optional metrics
#共享单步
def shared_step(self,batch) ->dict:
x,y = batch
#Doing val = self(x) is identical to doing val = self.__call__(x)
# prediction = self(x) 与下面的代码等价
prediction = self.forward(x)
loss = nn.BCELoss()(prediction,y)
# metric = torchmetrics.Accuracy()
preds = torch.where(prediction>0.5,torch.ones_like(prediction),torch.zeros_like(prediction))
# acc = metric(preds,y.int())
acc = pl.metrics.functional.accuracy(preds,y) #<- 问题出在这句代码上
# attention: there must be a key of "loss" in the returned dict
dic = {"loss":loss,"acc":acc}
return dic
#optimizer,and optional lr_scheduler
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(),lr=1e-2)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=10,gamma=1e-4)
return {"optimizer":optimizer,
"lr_scheduler":lr_scheduler}
pl.seed_everything(1234)
net = Net()
model = Model(net)
torchkeras.summary(model,input_shape =(2,))
ckpt_cb = pl.callbacks.ModelCheckpoint(monitor="val_loss")
# set gpus=0 will use cpu,
# set gpus=1 will use 1 gpu
# set gpus=2 will use 2gpus
# set gpus = -1 will use all gpus
# you can also set gpus = [0,1] to use the given gpus
# you can even set tpu_cores=2 to use two tpus
trainer = pl.Trainer(max_epochs=100,gpus=0,callbacks=[ckpt_cb])
trainer.fit(model,dl_train,dl_valid)解决方法
acc = pl.metrics.functional.accuracy(preds,y)
变为
import torchmetrics
metric = torchmetrics.Accuracy()
acc = metric(preds,y)2. 为什么Model可以传入参数net?
![]()
Model继承了LightModel,LightModel中初始化有net参数,因此需要传入一个net。
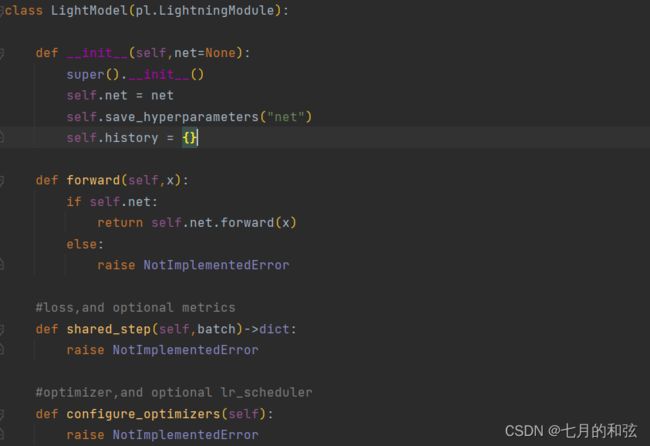
3. model和下边的Trainer有什么关系?是怎么开始训练的?pl.callbacks.ModelCheckpoint(monitor="val_loss")是什么意思?
[1]提到一个Trainer训练之前,要自定一个继承LightningModule的模型,再将这个模型、训练集、测试集放入Trainer中,之后进行trainer.fit就可以训练。这里model继承torchkeras.LightModel,而torchkeras.LightModel又继承了LightningModule,因此是可以的。
model = MyLightningModule()
trainer = Trainer()
trainer.fit(model, train_dataloader, val_dataloader)
trainer.validate(val_dataloaders=val_dataloaders)
trainer.test(test_dataloaders=test_dataloaders)torchkeras的LightModel中配置shared_step和configure_optimizers就好,后面的代码会调用者两部分的代码,里面的training_step调用了shared_step。

ModelCheckpoint是Pytorch Lightning中的一个Callback,它就是用于模型缓存的。它会监视某个指标,每次指标达最好的时候,就缓存当前的模型[2]。最后的结果在tensorboard里存放。