YOLO发展史
系列文章目录
YOLO发展史
文章目录
- 前言
- 一、YOLO简介
- 二、YOLO发展史
- 三. YOLOV5实用性
- 四. YOLOV5结构解析
- 总结
前言
目前物体检测算法有以下三种:
第一种是传统物体检测算法,使用人工设计特征以及机器学习的分类方式,但这种算法提取到的特征局限性较大且学习速度有限;
第二种是结合候选框+深度学习分类法,这类Two-Stage方法解决了前者的问题,在精度上有很大突破,但在速度上很难达到实时检测的效果;
第三种是基于深度学习的回归方法,在速度上达到了实时级别的突破,本文使用YOLO就是属于One-stage,YOLO虽然在v1,v2版本准确率上有所欠缺,但到v5版本时准确率提高了很多。
一、YOLO简介
①作者:Joseph Redmon,华盛顿大学博士,YOLO目标检测算法主要作者,YOLO是Joseph Redmon和Ali Farhadi等人于2015年提出的第一个基于单个神经网络的目标检测系统。
②YOLO的全称是you only look once,指只需要浏览一次就可以识别出图中的物体的类别和位置。
③YOLO是目标检测模型。目标检测是计算机视觉中比较简单的任务,用来在一张图篇中找到某些 特定的物体,目标检测不仅要求我们识别这些物体的种类,同时要求我们标出这些物体的位置。
④YOLO能实现图像或视频中物体的快速识别,在相同的识别类别范围和识别准确率条件下, YOLO识别速度最快。YOLO有多种模型,其中最新的为V5,V5的特点是速度更快,识别准确率 更高,权重文件更小,可以搭载在配置更低的移动设备上。
二、YOLO发展史
1.YOLOV1
YOLO网络借鉴了GoogLeNet分类网络结构,不同的是YOLO使用1x1卷积层和3x3卷积层替代inception module。如下图所示,整个检测网络包括24个卷积层和2个全连接层。其中,卷积层用来提取图像特征,全连接层用来预测图像位置和类别概率值。

1.1.YOLOV1优点
①快。因为回归问题没有复杂的流程(pipeline)。
②可以基于整幅图像预测(看全貌而不是只看部分)。与基于滑动窗口和区域提议的技术不同,YOLO在训练和测试期间会看到整个图像,因此它隐式地编码有关类及其外观的上下文信息。因为能看到图像全貌,与 Fast R-CNN 相比,YOLO 预测背景出错的次数少了一半。
③学习到物体的通用表示(generalizable representations),泛化能力好。因此,当训练集和测试集类型不同时,YOLO 的表现比 DPM 和 R-CNN 好得多,应用于新领域也很少出现崩溃的情况。
1.2.YOLOV1缺点
①空间限制:一个单元格只能预测两个框和一个类别,这种空间约束必然会限制预测的数量;
②难扩展:模型根据数据预测边界框,很难将其推广到具有新的或不同寻常的宽高比或配置的对象。由于输出层为全连接层,因此在检测时,YOLO 训练模型只支持与训练图像相同的输入分辨率。
③网络损失不具体:无论边界框的大小都用损失函数近似为检测性能,物体 IOU 误差和小物体 IOU 误差对网络训练中 loss 贡献值接近,但对于大边界框来说,小损失影响不大,对于小边界框,小错误对 IOU 影响较大,从而降低了物体检测的定位准确性。
2.YOLOV2
YOLOv2采用Darknet-19,其网络结构如下图所示,包括19个卷积层和5个max pooling层,主要采用3x3卷积和1x1卷积,这里1x1卷积可以压缩特征图通道数以降低模型计算量和参数,每个卷积层后使用BN层以加快模型收敛同时防止过拟合。最终采用global avg pool 做预测。采用YOLOv2,模型的mAP值没有显著提升,但计算量减少了。


YOLOv1虽然检测速度快,但在定位方面不够准确,并且召回率较低。为了提升定位准确度,改善召回率,YOLOv2在YOLOv1的基础上提出了几种改进策略,如下图所示,可以看到,一些改进方法能有效提高模型的mAP。
①大尺度预训练分类
②New Network:Darknet-19
③加入anchor

2.1.YOLOV2优点
- 结果:相对v1 (更快、mAP更高)
- 正负样本:引入Anchor和使用K-means聚类,提高了Recall
- Backbone:DarkNet-19,降低了计算量(更快)
- Neck:引入特征融合模块(passthrouch),融合细粒度特征
- 检测头:去掉v1中的FC,可以适应32x的输入; 多尺度训练提高模型能力;二者实现了速度和精度的权衡
- 小技巧:引入BN,加速网络收敛;约束输出范围,训练更稳定;
2.2.YOLOV2缺点
- Backbone 可持续优化
- Neck 可持续优化
- 只是单个检测头,小目标识别还不太好
- 损失函数可持续优化
3.YOLOV3
YOLOv3总结了自己在YOLOv2的基础上做的一些尝试性改进,有的尝试取得了成功,而有的尝试并没有提升模型性能。其中有两个值得一提的亮点,一个是使用残差模型,进一步加深了网络结构;另一个是使用FPN架构实现多尺度检测。

3.1.YOLOV3的创新点
①新网络结构:DarkNet-53
②融合FPN
③用逻辑回归替代softmax作为 分类
3.2.YOLOV3网络结构的改进
YOLOv3在之前Darknet-19的基础上引入了残差块,并进一步加深了网络,改进后的网络有53个卷积层,取名为Darknet-53,网络结构如下图所示(以256*256的输入为例)。

3.3.YOLOV3中多尺度检测实现方法
YOLOv3借鉴了FPN的思想,从不同尺度提取特征。相比YOLOv2,YOLOv3提取最后3层特征图,不仅在每个特征图上分别独立做预测,同时通过将小特征图上采样到与大的特征图相同大小,然后与大的特征图拼接做进一步预测。用维度聚类的思想聚类出9种尺度的anchor box,将9种尺度的anchor box均匀的分配给3种尺度的特征图.如下图是在网络结构图的基础上加上多尺度特征提取部分的示意图(以在COCO数据集(80类)上256x256的输入为例):

4.YOLOV4
YOLOv4在原来的YOLO目标检测架构的基础上,采用了很多优化策略,在数据处理,主干网络,网络训练,激活函数,损失函数等方面都有不同程度的优化。
①backbone

YOLOv4的网络结构如上所示,可以看出,他是在YOLOv3的主干网络Darknet-53的基础上增加了backbone结构,其中包含了5个CSP模块,可以有效增强网络的学习能力,降低成本。同时增加了Droblock,缓解过拟合现象。
此外很重要的一点是,使用了Mish激活函数,根据实验,这种激活函数可以增加精度。

②YOLOv4中的Neck结构主要采用了SPP模块,FPN+PAN的方式,SPP模块指的是用不同尺度的最大池化方式连接不同尺寸的特征图,可以显著分离上下文的特征,此外FPN和PAN起到了特征聚合的作用。
③输入部分采用了Mosaic数据增强,随机采用四张图片随即缩放后随机凭借,丰富了数据集,增强了模型的鲁棒性。预测部份采用了CIOU_Loss替换了IOU_Loss,DIOU_nms替换了nms,充分考虑了边框不重合,中心点距离,以及边框宽高比的问题。
5.YOLOV5
①YOLOV5简介:
YOLOV4出现之后不久,YOLOv5横空出世。YOLOv5在YOLOv4算法的基础上做了进一步的改进,检测性能得到进一步的提升。虽然YOLOv5算法并没有与YOLOv4算法进行性能比较与分析,但是YOLOv5在COCO数据集上面的测试效果还是挺不错的。大家对YOLOv5算法的创新性半信半疑,有的人对其持肯定态度,有的人对其持否定态度。在我看来,YOLOv5检测算法中还是存在很多可以学习的地方,虽然这些改进思路看来比较简单或者创新点不足,但是它们确定可以提升检测算法的性能。其实工业界往往更喜欢使用这些方法,而不是利用一个超级复杂的算法来获得较高的检测精度。本文将对YOLOv5检测算法中提出的改进思路进行详细的解说,大家可以尝试者将这些改进思路应用到其它的目标检测算法中。
②网络结构
在YOLOv5中新加入了一个focus框架,其最大的特点是原始608×608×3的图像输入Focus结构,采用切片操作,先变成304×304×12的特征图,再经过一次32个卷积核的卷积操作,最终变成304×304×32的特征图,加速了训练速度。 另外在YOLOv4中使用的CSP模块现在在backone和neck中都有应用。
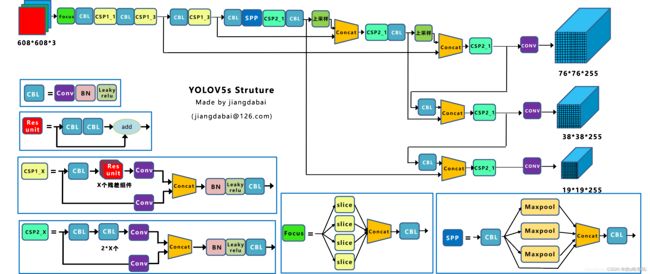
③输入和预测
输入部分依然采用了YOLOv4中采用的Mosaic数据增强技术,另外对于anchor box的设置采用了每次训练时自适应生成的方式,以及为了保持正常的长宽比,在填充增强环节自适应增添最少的黑边。预测部份同样采用了CIOU_Loss替换了IOU_Loss,DIOU_nms替换了nms.
三.YOLOV5实用性
1.应用场景
城市道路抓拍外地车辆未办理进京证,大货车禁行,占用非机动车及公交车道,单行线逆行,违法停车等。

四.YOLOV5结构解析
1.输入端
(1)Mosaic数据增强
主要有几个优点:
丰富数据集:随机使用4张图片,随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好。
减少GPU:可能会有人说,随机缩放,普通的数据增强也可以做,但作者考虑到很多人可能只有一个GPU,因此Mosaic增强训练时,可以直接计算4张图片的数据,使得Mini-batch大小并不需要很大,一个GPU就可以达到比较好的效果。
(2)自适应锚框计算
(3)自适应图片缩放
2.Backbone
(1)Focus结构
源码如下:

Focus结构如下,在yolov3、yolov4中并没有这个结构,其中比较关键是切片操作。

(2)CSP结构
yolov4网络结构中,借鉴了CSPNet的设计思路,在主干网络中设计了CSP结构。

yolov5与yolov4不同点在于,yolov4中只有主干网络使用了CSP结构。
而yolov5中设计了两种CSP结构,以yolov5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。

因此yolov4在主干网络Backbone采用CSPDarknet53网络结构,主要有三个方面的有点:
优点一:增强CNN的学习能力,使得在轻量化的同时保持准确性。
优点二:降低计算瓶颈
优点三:降低内存成本
4.Neck
yolov5现在的Neck和yolov4的一样,都采用FPN+PAN的结构,但在yolov5刚出来时,只使用了FPN结构,后面才增加了PAN结构,此外网络中其他部分也进行了调整。

可以看到经过几次下采样,三个紫色箭头指向的地方,输出分别是76*76、38*38、19*19。
以及最后的Prediction中用于预测的三个特征图,①19*19*255,②38*38*255,③76*76*255。
【注:255表示80类别(1+4+80)*3=255】
我们将Neck部分用立体图画出来,更直观的看下两部分之间是如何通过FPN结构融合的。

如图所示,FPN是自顶向下的,将高层的特征信息通过上采样的方式进行传递融合的,得到进行预测的特征图。
而yolov4中Neck这部分除了使用FPN外,还在此基础上使用了PAN结构:

前面CSPDarknet53中讲到,每个CSP模块前面的卷积核都是3*3大小,步长为2,相当于下采样操作。
因此可以看到三个紫色箭头处的特征图是76*76、38*38、19*19。
以及最后的Prediction中用于预测的三个特征图,①76*76*255,②38*38*255,③19*19*255。
下面是Neck部分的立体图像,展示了两部分是如何通过FPN+PAN结构进行融合的。

和yolov3的FPN层不同,yolov4在FPN层的后面还添加了一个自底向上的特征金字塔。
其中,包含两个PAN结构。
这样结合操作,FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行参数聚合,这样的操作确实很皮。
FPN+PAN借鉴的是18年CVPR的PANet,当时主要应用于图像分割领域,但Alexey将其拆分应用到yolov4中,进一步提高特征提取的能力。
总结
以上就是今天要讲的内容,本文仅仅简单介绍了YOLO的介绍。