python数据分析(三)——numpy读取本地数据和索引
系列文章:
python数据分析(一)——numpy数组的创建
python数据分析(二)——numpy数组的计算
python数据分析(四)——numpy中的nan和数据的填充
python数据分析(五)——numpy+matplotlib实例
numpy读取本地数据和索引
- 一、轴(axis)
- 二、numpy读取数据
-
- 01 数组转置
- 三、numpy中的索引和切片
-
- 01 numpy索引和切片
- 02 numpy中数值的修改
-
- 02_01 np.where()
- 02_02 .clip 裁剪
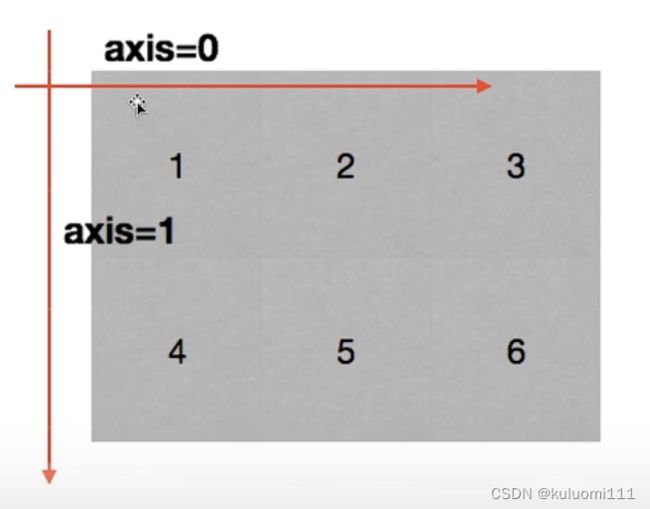
一、轴(axis)
在numpy中可以理解为方向,使用0, 1, 2…数字表示,对于一个一维数组,只有一个0轴,对于2维数组(shape(2, 2)),有0轴和1轴,对于三维数组(shape(2, 2, 3)),有0, 1, 2轴
计算一个2维数组的平均值必须制定是计算哪个方向上面的数字平均值
np.arange(0, 10).reshape((2, 5))中,reshape中2表示0轴长度(包含数据的条数)为2,1轴长度为5,一共2*5=10个数据
二维数组:
- 0表示行,1表示列
- axis=0,从上到下,竖直方向对行操作;axis=1,从左到右,水平方向对列操作
In [1]: t
Out[1]:
array([[0, 1, 2, 3],
[4, 5, 6, 7],
[8, 9, 10, 11]])
# 跨行求和
In [2]: np.sum(t, axis = 0)
Out[2]:
array([12, 15, 18, 21])
# 跨列求和
In [3]: np.sum(t, axis = 1)
Out[3]:
array([6, 22, 38])
三维数组:
- 0表示块,1表示行,2表示列
- axis=0,从外到内;axis=1,从上到下;axis=2,从左到右

二、numpy读取数据
CSV:Comma-Separated Value,逗号分隔值文件
显示:表格状态
源文件:换行和逗号分隔行列的格式化文本,每一行的数据表示一条记录
由于csv便于展示、读取和写入,所以很多地方也是用csv格式存储和传输中小型的数据
np.loadtxt(frame, type = np.float, delimiter = None, skiprows = 0, usecols = None, unpack = False)
frame指的是文件路径,dtype指定数据类型,delimiter指定分割字符串,skiprows跳过哪一行,usecols选用哪一列,unpack表示转置,行列互换

np.loadtxt(US_video_data_numbers_path, delimiter = “,”, type = int, unpack = 1)
注意其中添加delimiter和dtype以及unpack的效果
delimiter:指定边界符号是什么,不指定会导致每行数据为一个整体的字符串而报错
dtype:默认情况下对于较大的数据会将其变为科学技术的方式
unpack:默认是False(0),默认情况下,有多少条数据,就会有多少行;True(1)的情况下,每一列的数据会组成一行,原始数据有多少列,加载出来的数据就会有多少行,相当于转置的效果
01 数组转置
那么如何进行转置?
三种转置方法
In [45]: t
Out[45]:
array([[0, 1, 2, 3, 4, 5],
[6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17]])
In [46]: t. transpose()
Out[46]:
array([[0, 6, 12],
[1, 7, 13),
[2, 8, 14],
[4, 10, 16],
[5, 11, 17]])
In [47]: t. swapaxes(1,0)
Out[47]:
array([[0, 6, 12],
[1, 7, 13),
[2, 8, 14],
[4, 10, 16],
[5, 11, 17]])
In [48]: t.T
Out[48]:
array([[0, 6, 12],
[1, 7, 13),
[2, 8, 14],
[4, 10, 16],
[5, 11, 17]])
以上三种方法都可以实现二维数组的转置效果,转置和交换轴的效果一样
代码如下(示例):
# 三种转置方式
t1 = np.arange(24).reshape(4, 6)
print(t1)
print(t1.transpose())
print(t1.T)
print(t1.swapaxes(1, 0))
三、numpy中的索引和切片
现在这里有一个英国和美国各自youtube1000多个视频的点击、喜欢、不喜欢、评论数量([“views”, “likes”, “dislikes”, “comment_total”])的cdv,运用所学的matplotlib把英国和美国的数据呈现出来?
- 想要反映出什么样的结果,解决什么问题?
- 选择什么样的呈现方式?
- 数据还需要做什么样的处理?
- 写代码
01 numpy索引和切片
对于刚刚加载出来的数据,如果只想选择其中某一列(行)的数据,应该怎么做?
numpy索引和切片
In [83]: a
Out[83]:
array([[0, 1, 2, 3],
[4, 5, 6, 7],
[8, 9, 10, 11]])
In [84]: a[1] #取一行
Out[84]:
array([4, 5, 6, 7])
In [85]: a[:, 2] #取一列
Out[85]:
array([2, 6, 10])
In [84]: a[1:3] #取多行
Out[84]:
array([[4, 5, 6, 7],
[8, 9, 10, 11]])
In [85]: a[:, 2:4] #取多列
Out[85]:
array([[2, 3],
[6, 7],
[10, 11]])
代码如下(示例):
import numpy as np
us_file_path = "./Documents/python数据分析学习/youtube_video_data/US_video_data_numbers.csv"
uk_file_path = "./Documents/python数据分析学习/youtube_video_data/GB_video_data_numbers.csv"
us = np.loadtxt(us_file_path, delimiter = ",", dtype = "int")
print(us)
# 取行
# print(us[2])
# 取连续的多行
# print(us[2:])
# 取不连续的多行
# print(us[[2, 8, 10]])
# 取列
# print(us[1, :])
# print(us[2:, :])
# print(us[[2, 10, 3], :])
# print(us[:, 0])
# 取连续的多列
# print(us[:, 2:])
# 取不连续的多列
# print(us[:, [0, 2]])
# 取行和列,取第3行,第4列的值
# print(us[2, 3])
# 取多行和多列,取第3行到第5行,第2列到第4列的结果
# 取的是行和列交叉点的位置
# 末端的值取不到,前开后闭区间
# print(us[2:5, 1:4])
# 取多个不相邻的点
# 选出来的结果是(0, 0) (2, 1) (2, 3)
# print(us[[0, 2, 2], [0, 1, 3]])
02 numpy中数值的修改
numpy数值修改
In [4]: t
Out[4]:
array([[0, 1, 2, 3, 4, 5],
[6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
In [6]: t[:, 2:4]
Out[6]:
array([[2, 3],
[8, 9],
[14, 15],
[20, 21]])
In [7]: t[:, 2:4] = 0
In [8]: t
Out[8]:
array([[0, 1, 0, 0, 4, 5],
[6, 7, 0, 0, 10, 11],
[12, 13, 0, 0, 16, 17],
[18, 19, 0, 0, 22, 23]])
如果条件更复杂,想要把t中小于10的数字替换为3,怎么实现?
In [9]: t2
Out[9]:
array([[0, 1, 0, 0, 4, 5],
[6, 7, 0, 0, 10, 11],
[12, 13, 0, 0, 16, 17],
[18, 19, 0, 0, 22, 23]])
In [10]: t2<10
Out[10]:
array([[True, True, True, True, True, True],
[True, True, True, True, False, False],
[False, False, False, False, False, False],
[False, False, False, False, False, False]], dtype = bool)
In [11]: t2[t2<10] = 3
In [12]: t2
Out[12]:
array([[3, 3, 3, 3, 3, 3],
[3, 3, 3, 3, 10, 11],
[12, 13, 0, 0, 16, 17],
[18, 19, 0, 0, 22, 23]])
02_01 np.where()
numpy中的三元运算符
In [1]: t = np.arange(24).reshape(4, 6)
In [2]: t
Out[20]:
array([[0, 1, 2, 3, 4, 5],
[6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
# numpy的三元运算符
In [22]: np.where(t<10, 0, 10)
Out[22]:
array([[0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 10, 10],
[10, 10, 10, 10, 10, 10],
[10, 10, 10, 10, 10, 10]])
02_02 .clip 裁剪
如果想把t中小于10的数字替换为0,把大于18的替换为18,应该怎么做?
numpy中的clip(裁剪)
In [1]: t
Out[1]:
array([[0, 1, 2, 3, 4, 5],
[6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, nan, nan, nan]])
In [2]: t.clip(10, 18)
Out[2]:
array([[10, 10, 10, 10, 10, 10],
[10, 10, 10, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 18, 18, nan, nan, nan]])
小于10的替换为10,大于18的替换为18,但是nan没有被替换,那么nan是什么?