大规模并行分布式深度学习
作者:林伟
最新的十年是人工智能爆炸的十年,人工智能已经在社会各个领域如图片,语音,语言理解,推荐算法取得重大突破,使得其判断的结果已经接近或者超越了人类。这个背后的主要原因是是互联网的不断发展使我们能够快速地积累了海量数据,再加上硬件的快速发展以及神经网络训练方式的革新,使我们越来越有能力训练深且宽的神经网络,产出了超越人类“智能”的模型,并得到广泛应用。所以如何实现大规模并行分布式深度学习就成为深度学习的研究热点,从而成为推动算法创新的关键的人工智能工程能力。
并行分布式深度学习的历史发展历程和范式
最开始推动分布式训练的场景是大规模搜索广告推荐模型。随着互联网的发展,我们需要建立一个能够满足互联网用户以及数据规模一种搜索广告推荐模型,需要通过训练能够很好对用户,网页进行有效的向量化,从而能够通过不同人或者网页的特征,找出更加相关的信息,提高人们在海量数据中匹配数据的效率。而这类模型往往需要学习出来一个非常大的特征矩阵,比如现代系统这种特征规模以及从最开始百亿[1]已经发展到千亿乃至于万亿[2],这就需要一种分布式的系统来支撑这种机器学习的模型训练。而且因为这种特征矩阵因为人群和网页这种互联网的特性,具有明显的热点效应,是非常稀疏的,使得其在访问时候常常具有在时间和空间上的不均匀性。这也是 2014年谷歌等团队在 OSDI 发表一个分布式系统《Scaling Distributed Machine Learning with the Parameter Server》[3](相关其他研究还有[4][5]),该系统(Figure 1)建立一个分布式 Key-Value 的存储系统来保存海量的特征向量,然后我们把海量训练数据分发到多个没有状态的训练工作节点(worker),每个工作节点从分布式 KV的参数服务器取得最新的参数,在当前这批数据进行训练算出在这批数据上做出的估计和希望的答案(一般是把用户最后真实点击的网页或者商品作为目标答案)的差距,从而计算出需要对于参数调整的梯度,然后在把这些梯度推送会参数服务器进行相关加权平均,汇总后再调整参数,使得整个模型的预测能够更加贴近目标值。因为稀疏的特性,为了能够充分发挥系统的性能,也因为这类模型往往追求的目标是一个动态的目标,因为人的兴趣和网页本身都是时刻在变化的。所以我们可以利用这个特性进行异步训练,也就是在训练时候可以适当使用过期的参数以及利用异步的方式来更新参数,从而能够更好的,在更大范围来容忍参数服务器参数访问的不均匀性以及分布式场景下容错以及网络通讯的压力,使得分布式训练效率更优。更加具体的可以参照 NIPS 2013 年的《More effective distributed ml via a stale synchronous parallel parameter server》等论文[5]。
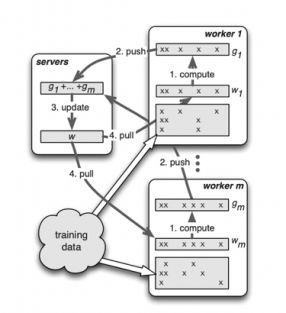 标题图1参数服务器(选自[3])
标题图1参数服务器(选自[3])
于此同时,在图片,语音和语言等感知类领域,随着海量数据的积累以及算力发展,神经网络算法终于可以取得突破性的结果,随着 AlexNet[6], GoogleNet[7],Resnet[8],模型的规模和深度也是越来越大,从而机器学习领域从神级网络算法诞生出一支独立学派:深度学习,并得到了快速爆炸性的发展,以至于如今人们谈论人工智能往往和深度学习画上了等号。但是因为GPU等硬件也是快速发展,显存大小也是同步在变大,使得这类模型还是能够在单块显卡能够放的下,加上我们可以通过 ZeRO optimizer[25],CPU-offload 等技术进一步提高 GPU 显存的使用效率,以至有文章[26]说实用的模型总是能够在单卡能够放下并且得到训练。但是即便如此,模型的参数还是有上亿的规模,需要海量的数据来训练,为了加速训练,我们还是需要使用数据并行来分布式训练,因为感知类模型往往是稠密的参数,训练每批数据后,几乎是所有的参数都需要更新,这样使得在通讯行为上有着非常显著不同于稀疏模型的特点,于是我们有了另外一种并行分布式方式:AllReduce[27]的同步的数据并行。这种分布式训练模式其实从高性能集群 HPC 领域来,也就是每个训练参与方都维护一个模型的副本,然后在训练时候,每个工作节点分到 N 分之一的数据,通过前向和反向计算,得到这个数据下模型估计值和目标指的差距,从而得到这批数据上参数需要变换的梯度,然后利用高性能 HPC 集群的通讯库原语 AllReduce 使得每个节点同时加权平均所有节点局部梯度变化,使得每个工作节点都得到全局梯度变化的副本,最后同时将该梯度变化运用于模型参数上,使得其每个工作节点上的模型副本同步得到相同的更新。AllReduce 的有可以细分为 Ring-AllReduce[26]和 Reduce-Scatter 的方式来做,其中 Ring-Allreduce 因为去中心化以及非常确定性的消息传递,使得 Nvidia 可以根据这个特性构建多个 GPU 卡的物理拓扑NVLink[9],从而能够高效进行 Ring 的 Allreduce,并且将这个通讯原语集成到自己软件 NCCL 库[10],从而大大推动同步的数据并行模型训练的开展和人工智能应用的发展。当然也有其他研究比如字节跳动的 BytePS[11] 利用参数服务器的分布式架构来进行稠密模型的 AllReduce 这个计算,以便在没有良好 NVLink 拓扑上一样能够进行高效的同步的数据并行训练。
随着深度学习演进,在搜索推荐广告领域也从原来逻辑回归等传统机器学习算法向深度学习演进,最有影响力以及开创深度学习模型在这个领域的模型训练的是谷歌 2016 年发表于 DLRS 的《Wide & Deep Learning for Recommender System》[12]。为了能够有效支持感知类以及推荐类模型两者的需要,谷歌团队推出 TensorFlow 深度学习框架[13],从而能够把多种并行分布式训练范式都能够统一在 Tensor 流图的深度学习计算引擎上。
虽然 TensorFlow 从一开始就对于整个分布式深度学习训练做了非常基础和本质的抽象,该抽象可以支持任意的大规模的分布式训练方式,并且在这个框架基础上很快在 2018 年就出现了流水并行[14]和算子拆分[15]的模型并行的方式。流水并行是将模型层和层之间横向分成多个阶段,从而可以将模型的不同部分分配到不同的节点(GPU)中,从而我们可以训练单个 GPU 存储放不下的大模型。这种模式下不同 GPU 之间传递是层和层之间的计算结果,但是我们知道整个神经网络的训练过程是前向和反向的计算过程,所以这些 GPU 因为计算依赖是依次进行计算的(图 2 中的 b 所示),并不能在计算进行很好并行,无法充分利用 GPU 的算力。所以 Gpipe[14]进一步把计算进行 mini-batch 的切割,从而进一步让计算在 GPU 间类似微流水(图 2 中 c 所示)的方式进行并行。进一步提高 GPU 的利用率。另外一种并行方式是算子拆分,就是将神经网络纵向分割(如图 3 所示),把一个算子计算切割到不同节点进行计算,这种方式克服了流水因为计算依赖关系造成的 GPU 闲置的问题,但是不同算子分布式计算需要不同计算和拆分方式才能有效进行并行化,并且并行效率也和算子类型息息相关,所以这种方式往往需要非常大开发成本才能很好对模型进行并行训练。其实大规模推荐稀疏模型也是一种算子拆分的方式,只是这个算子是一个简单的稀疏特征的 lookup 算子而已。虽然研究人员很快在 TensorFlow 这个框架基础上给出多样的并行方式从而能够训练任意大的模型,但是因为 GPU 的硬件发展也很快,GPU 的显存大小也得到快速的发展。所以在很长的时间,除了推荐类大规模稀疏模型训练,感知类模型训练只是需要数据并行方式进行训练,直到 2019 年有一篇重量性工作《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》[16]的发表。
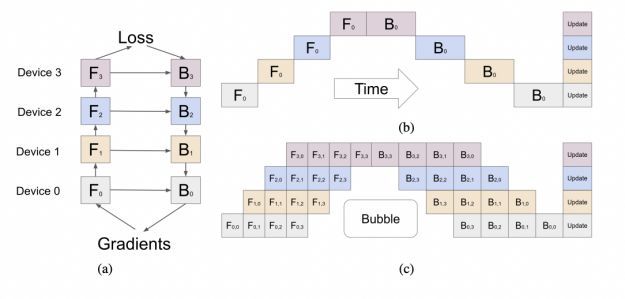 标题图 2 流水并行(选自[14])
标题图 2 流水并行(选自[14])
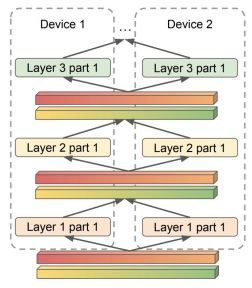 标题图 3 算子拆分
标题图 3 算子拆分
Bert推动超大规模预训练模型快速发展,这种 transformer 为基础的模型结构推动着感知类模型的参数规模从亿级别迅速进入到千亿以及万亿规模,例如 GTP-2[17],GTP-3[18],T5[19],M6[20]等等。终于复杂的模型并行从学术研究领域进入到企业界实际落地过程中。当前的超大规模模型往往需要根据模型的特点,进行多种并行训练方式的混合并行。这也是大家有时候叫做 3D,4D,5D 分布式训练,其实本质上就是把所有这些技巧综合在一起。
所以总结起来分布式并行训练的范式分为
- 大规模稀疏模型训练:参数服务器方式,异步训练为主
- 大规模稠密模型训练
- 数据并行:AllReduce 或者参数服务器进行梯度汇总,利用极致的显存优化(CPU-offload,Zero 梯度优化器优化,checkpoint 等)进一步扩大单节点的模型大小
- 流水并行
- 算子切分
- 混合并行
大规模并行分布式训练的发展方向
自动分布式训练:模型混合并行日益重要,但是混合并行往往需要根据模型的特点和集群资源现状,选择不同并行方式在模型不同部分,如果这个都需要模型的构建者来进行选择,整个问题是一个 NP 问题,会给模型构建者带来巨大的研发成本,使得很难进行快速算法研发迭代,为了更加系统的解决这个混合并行的寻优问题,产研界进行积极相应的研究,比如 GShard[21],OneFlow[22],Whale[23]等。其核心思路就是利用静态图逻辑性地描述一个网络训练步骤,执行的时候再进行系统化的分图和分布式训练,利用反映了现实约束的成本分析模型(Cost Model)对于不同并行策略进行评估,最后自动选择最优的并行方案。
这些工作中,GShard 更多关注于谷歌的 TPU 集群,OneFlow 从重新构建一个面向分布式的深度学习生态,而 Whale 其实采取的理念是让算法同学利用现有深度学习生态,如同构建一个单卡的模型训练的方式去构建,并且能够在异构资源(不同能力的加速卡能力)环境找到更优的混合并行方案。图 4 展示了 Whale 的整体架构图。Whale 会把模型训练脚本转换成一个的 DAG 静态图,然后进一步转化成自有中间代码(Intermediate Representation,IR)描述的逻辑执行计划,然后系统进行自动规划,再根据规划出来的并行策略对执行计划进行切图,并且把系统资源进行相应的划分,再把切图的结果和资源绑定,最后让 Cost Model 在多个可能并行策略上进行选择,从而自动寻找到接近最优的分布式策略。
 标题图 4 Whale 整体构架图
标题图 4 Whale 整体构架图
更大规模异构多模态多任务的模型训练: 随着模型算法,数据以及算力的发展,研究者终于可以开始构建神经网络算法最初的设想,就是建立类似大脑多任务综合在一起学习的方式,从而使得机器学习能够进一步仿真人脑的认知过程,把语言,视觉,听觉等多个认知任务关联在一起来进行整体训练,这个就要求更加异构的训练过程。Pathways[24] 就是在这个方向最新的探索。
总之,随着互联网的蓬勃发展,人们开始积累非常多的有价值的数据,同时随着半导体行业的方式使得我们具备足够算力使得模型研究者能够更敢去构建更加大型的模型,从而大大提升了模型的效果,产生能够媲美人类认知的人工智能模型,而大规模分布式训练的工程成为能够粘合数据,算力和算法的关键。
参考文献
[1] KunPeng: Parameter Server based Distributed Learning Systems and Its Applications in Alibaba and Ant Financial. KDD 2017.
[2] Persia: An Open, Hybrid System Scaling Deep Learning-based Recommenders up to 100 Trillion Parameters.CoRR 2021.
[3] Scaling Distributed Machine Learning with the Parameter Server. OSDI 2014.
[4] Parameter server for distributed machine learning. NIPS 2013.
[5] More effective distributed ml via a stale synchronous parallel parameter server. NIPS 2013.
[6] ImageNet Classification with Deep Convolutional Neural Networks. NIPS 2012.
[7] Going deeper with convolution. CVPR 2015.
[8] Deep Residual Learning for Image Recognition. CVPR 2016.
[9] https://www.nvidia.com/en-us/data-center/nvlink/
[10] https://developer.nvidia.com/nccl
[11] A Unified Architecture for Accelerating Distributed DNN Training in Heterogeneous GPU/CPU Clusters. OSDI 2020.
[12]Wide & Deep Learning for Recommender System. DLRS 2016.
[13] https://www.tensorflow.org/
[14] GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism. NIPS 2019.
[15] Mesh-TensorFlow: Deep Learning for Supercomputers. NIPS 2018.
[16] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL-HLT 2019
[17] https://huggingface.co/docs/transformers/model_doc/gpt2
[18] https://openai.com/blog/gpt-3-apps/
[19] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Mach. Learn. Res. 2021.
[20] M6: Multi-Modality-to-Multi-Modality Multitask Mega-transformer for Unified Pretraining. KDD 2021
[21] GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding. CoRR 2020.
[22] OneFlow: Redesign the Distributed Deep Learning Framework from Scratch. CoRR 2021
[23] Whale: Scaling Deep Learning Model Training to the Trillions. https://arxiv.org/pdf/2011.09208.pdf
[24] https://blog.google/technology/ai/introducing-pathways-next-generation-ai-architecture/
[25] ZeRO: memory optimizations toward training trillion parameter models. SC 2020
[25] DeepSpeed: https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/
[26] https://andrew.gibiansky.com/blog/machine-learning/baidu-allreduce/
[27] Horovod: fast and easy distributed deep learning in TensorFlow. arXiv preprint arXiv:1802.05799 (2018)