用K-Means算法处理wine数据集和wine_quality数据集
一、实验目的
根据wine数据集处理的结果,采用2种不同的聚类算法分别建聚类模型;然后,通过定量指标评价所构建的模型的优劣。
二、实验内容
wine数据集和wine_quality数据集是两份和葡萄酒有关的数据集。
wine数据集包含3种同起源的葡萄酒的记录,共178条。其中,每个特征对应葡萄酒的每种化学成分,并且都属于连续型数据。通过化学分析可以推断葡萄酒的起源。
wine_quality数据集共有1599个观察值,11个输入特征和一个标签。其中,不同类的观察值数量不等,所有特征为连续型数据。通过酒的各类化学成分,预测该葡萄酒的评分。
(1) 使用pandas库分别读取wine数据集和wine_quality数据集;将wine数据集和wine_quality数据集的数据和标签拆分开;将wine数据集和wine_quality数据集划分为训练集和测试集;标准化wine数据集和wine_quality数据集;对wine数据集和wine_quality数据集进行PCA降维。
(2) 根据(1)的wine数据集处理的结果,采用2种不同的聚类算法分别构建聚类模型;然后,通过定量指标评价所构建的模型的优劣。
(3) 根据(1)的wine数据集处理的结果,采用2种不同的分类算法分别构建分类模型;然后,通过定量指标评价所构建的模型的优劣。
(4) 根据(1)的wine_quality数据集处理的结果,采用2种不同的回归算法分别构建回归模型;然后,通过定量指标评价所构建的模型的优劣。
三、实验步骤 (包含算法简介)
K-means
- K-Means算法的简介:
KMeans算法既是一种无监督的学习方式,又是一种聚类方法。
它的主要实现步骤如下:
首先对数据集当中的点,随机设置K个特征空间内的点作为初始的聚类中心点。然后对于其它的每个点,分别计算到它们到K个中心的距离(即:每个点都要经过k次计算),每个点经过k次计算之后,在这k个计算结果当中选择最近的一个聚类中心点作为标记类别。接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值),并且与旧的中心点作比较,如果计算得出的新中心点与原中心点一样,那么结束,否则重新进行第二步过程。
注:在算点与点之间的距离的时候,这个距离可以是欧氏距离,可以是曼哈顿距离,也可以是余弦距离。
算法流程图如下:

KMeans算法的主要优缺点有:
优点:
算法易于理解
缺点:
需要用户提前输入k值;
聚类结果对初始类簇中心的选取较为敏感;
容易陷入局部最优;
只能发现球型类簇;
- 实验主要过程:
(1)数据集处理:
1.使用pandas库分别读取wine数据集和wine_quality数据集:
![]()
2.将wine数据集和wine_quality数据集的数据和标签拆分:
通过打印读取出来的数据集,发现wine数据集的标签为Class,而wine_quality数据集的标签为quality,所以可以进行拆分得到数据和标签。
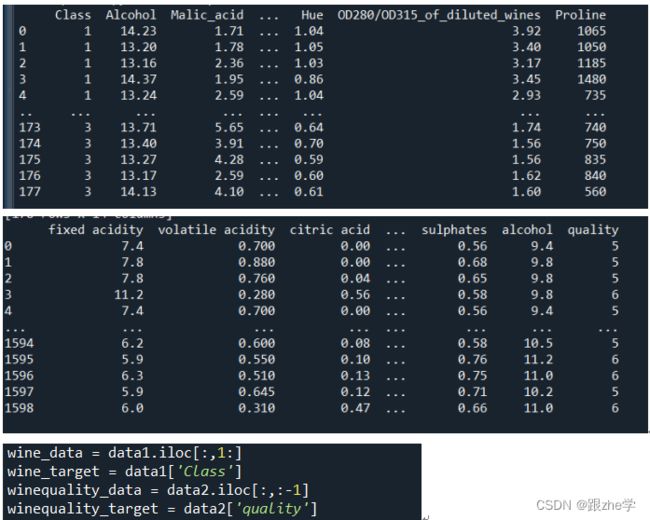
3.将wine数据集和wine_quality数据集划分为训练集和测试集,这里用到了sklearn.model_selection模板里面的train_test_split函数,它的返回结果根据它传入的数据的组数,如果传入两组数据,那么就返回四组数据,传入一组数据,那么就返回两组数据。
4.标准化wine数据集和wine_quality数据集:
先生成标准化模型,然后对wine数据集的训练集进行标准化,再用训练集训练的模型对测试集标准化,wine_quality数据集的操作也是如此。
5.对wine数据集和wine_quality数据集进行PCA降维,直接降到二维:
先生成降维模型,该模型的n_components等于2,然后对步骤四中生成的标准化的wine训练集进行PCA降维,再用训练集降维的模型对测试集进行降维,对wine_quality数据集的操作也是如此。
- 聚类过程:1.根据上面数据处理的结果,先构建聚类数目为3的K-Means模型,这时候选取的数据集为经过PCA降维之后的二维wine训练集:wine_trainPca,
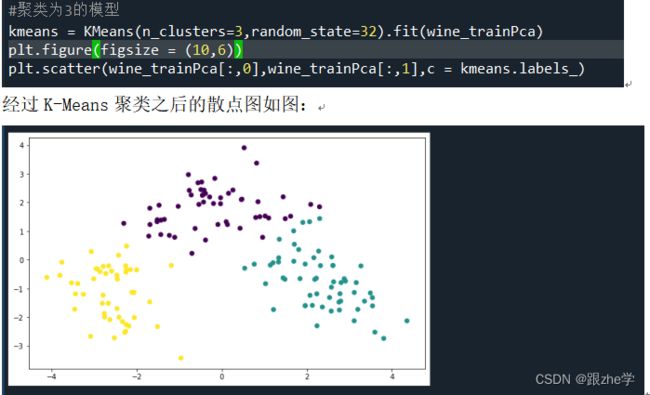
从图中可以看出当聚类数目为3类时,散点图基本上可以分为三种颜色的点。
2.对比真实标签和聚类标签求取FMI,并且在聚类数目为2到10类时,根据所求得FMI确定最优聚类数目。
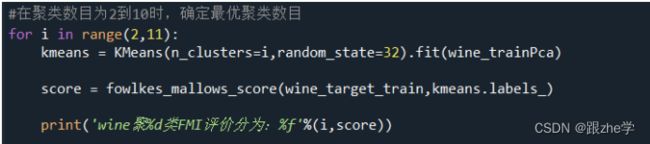
每一个聚类数目下的FMI如图:
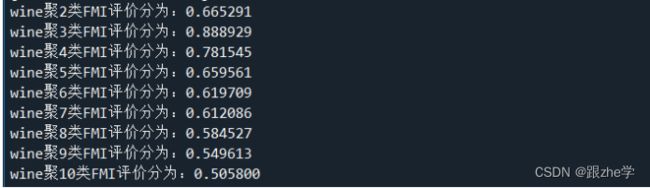
经过FMI计算发现,当聚类数目为3类时,它的FMI最大,此时为最优聚类数目。
3.根据模型的轮廓系数,绘制轮廓系数折线图,确定最优聚类数目:
根据样本输入进来的wine_trainPca数据集和这个数据集在每一个聚类数目下的标签,求取出样本在每一个聚类数目下的平均轮廓系数。

当聚类数目在2至10之间的时候,样本的平均轮廓系数的折线图为:
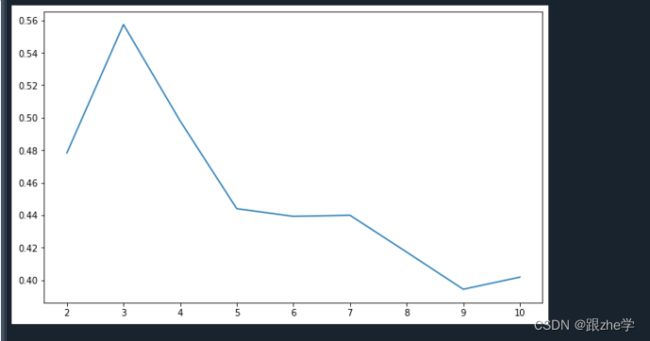
从图中可以看出,降维之后的数据集在聚类数目为3的时候,畸变程度最大,聚类效果最好。
4.求取 Calinski-Harabasz指数,确定最优聚类数:
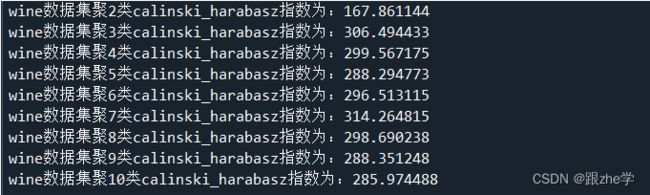
根据求取的Calinski-Harabasz指数,在这里聚3类和聚7类的效果都比较好,但是考虑到它是不需要真实值的,所有用它来评估最优聚类数目有点不可靠。
5.构建的模型的整体评估,确定最终的最优聚类数目:
通过分析FMI评价分值,可以看出wine数据集分为3类的时候其FMI值最高,故聚类为3类的时候wine数据集K-Means聚类效果最好
通过分析轮廓系数折线图,可以看出在wine数据集在分为3类的时候,其平均畸变程度最大,故亦可知聚类为3类的时候效果最佳
通过分析Calinski-Harabasz指数,我们发现其数值大体随着聚类的种类的增加而变多,最大值出现在聚类为7类的时候,考虑到Calinski-Harabasz指数是不需要真实值的评估方法,其可信度不如FMI评价法,故这里有理由相信这里的Calinski-Harabasz指数评价结果是存在异常的。
综上分析,wine数据集的K-Means聚类为3类的时候效果最好。
代码如下:
-
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.decomposition import PCA from sklearn.cluster import KMeans from sklearn.metrics import fowlkes_mallows_score from sklearn.metrics import silhouette_score from sklearn.metrics import calinski_harabasz_score import matplotlib.pyplot as plt data1 = pd.read_csv('./wine.csv') data2 = pd.read_csv('./wine_quality.csv',sep = ';') print(data1) print(data2) wine_data = data1.iloc[:,1:] wine_target = data1['Class'] winequality_data = data2.iloc[:,:-1] winequality_target = data2['quality'] wine_data_train, wine_data_test, wine_target_train, wine_target_test = train_test_split(wine_data, wine_target,test_size=0.1, random_state=6) winequality_data_train, winequality_data_test, winequality_target_train, winequality_target_test = train_test_split(winequality_data, winequality_target, test_size=0.1, random_state=6) stdScale1 = StandardScaler().fit(wine_data_train) #生成规则(建模) wine_trainScaler = stdScale1.transform(wine_data_train)#对训练集进行标准化 wine_testScaler = stdScale1.transform(wine_data_test)#用训练集训练的模型对测试集标准化 stdScale2 = StandardScaler().fit(winequality_data_train) winequality_trainScaler = stdScale2.transform(winequality_data_train) winequality_testScaler = stdScale2.transform(winequality_data_test) pca1 = PCA(n_components=2).fit(wine_trainScaler) wine_trainPca = pca1.transform(wine_trainScaler) wine_testPca = pca1.transform(wine_testScaler) pca2 = PCA(n_components=2).fit(winequality_trainScaler) winequality_trainPca = pca2.transform(winequality_trainScaler) winequality_testPca = pca2.transform(winequality_testScaler) #在聚类数目为2到10时,确定最优聚类数目 for i in range(2,11): kmeans = KMeans(n_clusters=i,random_state=32).fit(wine_trainPca) score = fowlkes_mallows_score(wine_target_train,kmeans.labels_) print('wine聚%d类FMI评价分为:%f'%(i,score)) #聚类为3的模型 kmeans = KMeans(n_clusters=3,random_state=32).fit(wine_trainPca) plt.figure(figsize = (10,6)) plt.scatter(wine_trainPca[:,0],wine_trainPca[:,1],c = kmeans.labels_) #使用轮廓系数评估模型的优缺点,当聚类数目为3时,畸变程度最大,聚类效果最好 silhouettteScore = [] for i in range(2,11): kmeans = KMeans(n_clusters = i,random_state=1).fit(wine_trainPca) score = silhouette_score(wine_trainPca,kmeans.labels_) silhouettteScore.append(score) plt.figure(figsize=(10,6)) plt.plot(range(2,11),silhouettteScore,linewidth=1.5, linestyle="-") #求取 Calinski-Harabasz指数,确定最优聚类数 for i in range(2,11): kmeans = KMeans(n_clusters = i,random_state=1).fit(wine_trainPca) score = calinski_harabasz_score(wine_trainPca,kmeans.labels_) print('wine数据集聚%d类calinski_harabasz指数为:%f'%(i,score)) plt.show()