Pytorch基于官方模型实现Faster-RCNN自定义数据集多GPU并行训练
本文用于记录利用Pytorch官方目标检测模型(torchvision.models.detection.xx)训练自定义数据集的多GPU并行训练爬坑过程,不具备普适性排雷功能,代码规范度较差,主要用于个人记录回溯。本文基于:Pytorch官方fastrcnn的Tutorial以及中文博客完成。
目录
环境
数据集
数据处理代码
主程序头(单GPU)
训练和测试代码(单GPU)
多GPU训练
-
环境
win10-homebasic(Linux);Pytorch 1.4.0;torchvision 0.5.0; Python 3.6.5/3.8.5;OpenCV 4.2.0 ;CUDA 10.0
尝试过Pytorch 1.7.0+torchvision 0.7.0 + CUDA 10.2,会报nms()函数没定义的错误。
-
数据集
自定义数据集由labelImg生成的Pascal格式标注集,格式如下图所示。Pytorch中torchvision.model可能是仅接受COCO格式,因此本文手写了格式转换的代码。官方Tutorial中有一点需要注意,maskrcnn输入的target必须包含

-
数据处理代码
数据处理代码基于torchvision.datasets.VOCDetection(path)改写。有一些需要注意的地方。首先,__ini__()函数中我加了一段判断:
if os.path.splitext(i)[1] != ".jpg":
idx = file_names.index(i)
file_names.__delitem__(idx)这是由于我在Jupyter中查看‘JPEGImages’文件夹中有300个.jpg文件,而读取时多了一个xx_checkpoint文件。因此多加了一步检查。
重点在__getitem__()函数中的target_form_trans()。它的功能是将parse_voc_xml得到的xml信息转换成coco格式(?我不确定这么写对不对,更严格的说是符合fasterrcnn输入的格式)。parse_voc_xml得到了一个以annotation为唯一key的dict。而annotation这个key的键值是我们需要的标注信息。因此target_form_trans第一行先把annotation的键值作为新的字典进行处理。接下来最关键的标注信息存放在dic的key=‘object’的键值中。这里面最大的一个坑是如果一幅图像有多个标注框,就会在dic这个字典中产生多个key=‘object’的内容。而字典是不允许key重名的,因此要考虑如何找到所有的object。如果object有多个,就需要通过以下语句:
if isinstance(dic['object'],list):
num_objs = len(dic['object'])
elif isinstance(dic['object'],dict):
num_objs = 1
else:
num_objs = 0来判断object的个数。因为多个object时,dic['object']的格式为list,而单个object时格式为dic。因此仅仅用len(dic['object'])会在object数量为1时返回其字典的key数量,造成计数错误。其余不表,至于和
import os
import torch
import sys
import tarfile
import collections
import numpy as np
from torchvision.datasets.vision import VisionDataset
from torchvision.datasets.voc import VOCDetection
if sys.version_info[0] == 2:
import xml.etree.cElementTree as ET
else:
import xml.etree.ElementTree as ET
from PIL import Image
from torchvision.datasets.utils import download_url, check_integrity, verify_str_arg
# 用于在图像中显示的class label
COCO_INSTANCE_CATEGORY_NAMES = [
'__background__', 'cover', 'uncover', 'other' ,'empty'
]
class VOCDataset(VisionDataset):
def __init__(self,
root,
transforms=None,
transform=None,
target_transform=None):
super(VOCDataset, self).__init__(root, transforms, transform, target_transform)
voc_root = self.root
self.image_dir = os.path.join(voc_root, 'JPEGImages') #数据集中图片放在'JPEGImages'文件夹
self.annotation_dir = os.path.join(voc_root, 'Annotations') #数据集中标注xml放在'Annotations'文件夹
if not os.path.isdir(voc_root):
raise RuntimeError('Dataset not found or corrupted.')
#用于存放train和test标签的ImageSets文件夹,存放的是txt文件,暂时不用
#splits_dir = os.path.join(voc_root, 'ImageSets/Main')
#split_f = os.path.join(splits_dir, image_set.rstrip('\n') + '.txt')
#with open(os.path.join(split_f), "r") as f:
# file_names = [x.strip() for x in f.readlines()]
#加载图片和标注
file_names = os.listdir(self.image_dir,)
for i in file_names: # 循环读取路径下的文件并筛选输出
if os.path.splitext(i)[1] != ".jpg":
idx = file_names.index(i)
file_names.__delitem__(idx)
file_names = [x.split(".",1)[0] for x in file_names] #分离出.jpg
self.images = [os.path.join(self.image_dir, x + ".jpg") for x in file_names]
self.annotations = [os.path.join(self.annotation_dir, x + ".xml") for x in file_names]
assert (len(self.images) == len(self.annotations))
def __getitem__(self, index):
"""
Args:
index (int): Index
Returns:
tuple: (image, target) where target is a dictionary of the XML tree.
"""
img = Image.open(self.images[index]).convert('RGB')
dic = self.parse_voc_xml(
ET.parse(self.annotations[index]).getroot())
target = self.target_form_trans(dic,index)
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, target
def target_form_trans(self,dic,index):
dic = dic['annotation']
# 处理image_id字段
image_id = torch.tensor([index])
target = {}
target["boxes"] = []
target["labels"] = []
target["image_id"] = image_id
target["area"] = []
target["iscrowd"] = []
# 处理object中包含的字段
boxes = []
labels = []
if 'object' not in dic: #没有标记信息直接返回
return target
if isinstance(dic['object'],list):
num_objs = len(dic['object'])
elif isinstance(dic['object'],dict):
num_objs = 1
else:
num_objs = 0
if num_objs == 1: #仅有一个标签
xmin = np.int32(dic['object']['bndbox']['xmin'])
xmax = np.int32(dic['object']['bndbox']['xmax'])
ymin = np.int32(dic['object']['bndbox']['ymin'])
ymax = np.int32(dic['object']['bndbox']['ymax'])
label = 0
obj_name = dic['object']['name']
if obj_name in COCO_INSTANCE_CATEGORY_NAMES:
label= np.int64(COCO_INSTANCE_CATEGORY_NAMES.index(obj_name))
boxes.append([xmin, ymin, xmax, ymax])
labels.append(label)
else:
for i in range(num_objs):
xmin = np.int32(dic['object'][i]['bndbox']['xmin'])
xmax = np.int32(dic['object'][i]['bndbox']['xmax'])
ymin = np.int32(dic['object'][i]['bndbox']['ymin'])
ymax = np.int32(dic['object'][i]['bndbox']['ymax'])
label = 0
obj_name = dic['object'][i]['name']
if obj_name in COCO_INSTANCE_CATEGORY_NAMES:
label= np.int64(COCO_INSTANCE_CATEGORY_NAMES.index(obj_name))
boxes.append([xmin, ymin, xmax, ymax])
labels.append(label)
boxes = torch.as_tensor(boxes, dtype=torch.float32)
labels = torch.as_tensor(labels, dtype=torch.int64)
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
# suppose all instances are not crowd
iscrowd = torch.zeros((num_objs,), dtype=torch.int64)
target["boxes"] = boxes
target["labels"] = labels
target["image_id"] = image_id
target["area"] = area
target["iscrowd"] = iscrowd
return target
def __len__(self):
return len(self.images)
def parse_voc_xml(self, node):
voc_dict = {}
children = list(node)
if children:
def_dic = collections.defaultdict(list)
for dc in map(self.parse_voc_xml, children):
for ind, v in dc.items():
def_dic[ind].append(v)
voc_dict = {
node.tag:
{ind: v[0] if len(v) == 1 else v
for ind, v in def_dic.items()}
}
if node.text:
text = node.text.strip()
if not children:
voc_dict[node.tag] = text
return voc_dict-
主程序头(单GPU)
本文先以单GPU的探索过程来描述,因为实现起来比较容易。这个过程其实没什么好说的,把全局参数放在了一起,方便调试(后来看起来用parser传参进main()的方式应该更规范,在下文多GPU训练时再改)。需要注意的是import里的几个文件是从官方的接口库中下载(这个过程可以认为是我没有跑官方的demo,而是用了demo里的一些库),如图所示。如util,并不是torchvision的util,具体下载地址可以参见中文博客中给出的github链接。
import os
import torch
import numpy as np
import torch.utils.data
from PIL import Image
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from torchvision.models.detection.mask_rcnn import MaskRCNNPredictor
import utils
import transforms as T
import torchvision.transforms as T_ori
from engine import train_one_epoch, evaluate
import cv2
import os
import matplotlib.pyplot as plt
from MyDataSet import VOCDataset
from MyDataSet import COCO_INSTANCE_CATEGORY_NAMES
#************Global 变量******************#
num_classes=5 #对应MyDataset中的COCO_INSTANCE_CATEGORY_NAMES
num_epochs = 20
batch_size_train =8 #训练集batch_size
batch_size_test =4
NUM_WORKERS = 4 #使用的线程数量
#************Global 变量******************# -
训练和测试代码(单GPU)
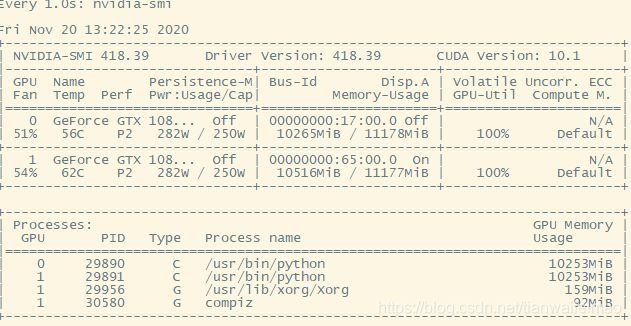
其余没什么,就是训练和测试。值得注意的一点是,在本文的例子中,出现了优化器选择不同造成识别不成功的情况(甚至是所有训练图片无法检测到目标)。示例中给的优化器为SGD,实验中使用Adam优化器时会发生在1 在fasterrcnn_resnet50_fpn的说明中提到: “ During training, the model expects both the input tensors, as well as a targets (list of dictionary), containing: - boxes (``FloatTensor[N, 4]``): the ground-truth boxes in ``[x1, y1, x2, y2]`` format, with values between ``0`` and ``H`` and ``0`` and ``W`` - labels (``Int64Tensor[N]``): the class label for each ground-truth box The model returns a ``Dict[Tensor]`` during training, containing the classification and regression losses for both the RPN and the R-CNN. ”可以参照代码中collate_fn=utils.collate_fn函数以及engine.py中的train_one_epoch函数查看一下demo是如何处理训练集格式尤其是标注信息targets的。target最后被打包为一个list[dic[tensor[]]]格式。 如果使用torch.nn.DataParallel(model)或torch.nn.parallel.DistributedDataParallel(model)进行多GPU并行处理,会报tensor尺寸不一致的错,具体错误如下: 这个问题困扰了很久。直到找到了GitHub上一段关于这个的讨论,简单的说torchvision.detection是不支持DataParallel的。而且在这篇文章中,比较详细的给出了这两种并行处理的说明,因此可以粗鲁的认为,在任何条件下也不要用torch.nn.DataParallel,全部改用torch.nn.parallel.DistributedDataParallel这种方式。 之前提到过,对于本文的例子,使用torch.nn.parallel.DistributedDataParallel(model)仍然会报错,在这里给出最终解决方案,在这里,以及这条评论里给出的demo链接。通过这条评论可以看到,如果想要达到最终目的,要严格按照demo给出的解决方案。尤其是运行命令(我单独列一行出来)。值得注意的是nproc_per_node=2这个参数,我个人认为是设置线程数量而非GPU数量,而另外一个参数world-size指定GPU数量(单机多GPU)。但是实际上如果设置nproc_per_node=1,本例只会在单GPU运行,而我试了一下简单的classification代码,word-size=2,nproc_per_node=1代表在2块GPU上,每个GPU上运行1个线程。如果nproc_per_node=2结果是2块GPU,每个GPU上跑两个线程,一共4个训练线程。 现在我先把整体代码贴上,再说其他的注意事项。与单GPU相比,只有main函数和train这个阶段不一样。但是!注意model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.gpu]),如果不指定device_ids一样会报错!另外,data_loader的shuffle要置位FALSE,可以尝试一下如果不这么做会怎样。pin_memory=True的含义可以搜索一下,简单的说是为了加速。train_sampler的作用也值得注意查看一下,如果不用这个而直接将原始data_loader传入的话虽然在两块GPU运行,但是速度与单GPU没差别,我暂时认为没有train_sampler是将数据集分配给不同GPU,如果没有这一步不同GPU会重复处理相同的数据。 main函数代码。可以仔细看看,很多的arg是没有用的。。。解决tensor的size不匹配其实只有一个地方:指定device_ids。我尝试不适用这么多参数,仍然用utils.init_distributed_mode(args)初始化,注意用torch.distributed.init_process_group(backend="nccl")初始化(main中被注释掉的第一行)方法仍然会在单GPU中运行,然后直接在DDP中使用model=DistributedDataParallel(model,device_ids=[torch.cuda.current_device()])的方式(train中有注释掉的代码),同样可以达到目标,原因我不知道。 简单说一下结果,我是两块12G的GPU,测试batch_size=8。单GPU训练基本把一块GPU占满。不改参数的情况下用以上方式会把两块GPU均占满(而不是batch_size可以double),而且两个GPU的占用非常均衡,如下图。但是训练时间降低50%。#训练样本的增强
def get_transform(train):
transforms = []
# converts the image, a PIL image, into a PyTorch Tensor
transforms.append(T.ToTensor())
#if train:
# during training, randomly flip the training images
# and ground-truth for data augmentation
#transforms.append(T.RandomHorizontalFlip(0.5))
return T.Compose(transforms)
#模型重新定义
def get_instance_segmentation_model(num_classes):
# load an instance segmentation model pre-trained on COCO
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
# get the number of input features for the classifier
in_features = model.roi_heads.box_predictor.cls_score.in_features
# replace the pre-trained head with a new one
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
return model
#*************************训练************************#
# use the PennFudan dataset and defined transformations
def train():
dataset = VOCDataset('PublicDatasets/CR', get_transform(train=True))
dataset_test = VOCDataset('PublicDatasets/CR', get_transform(train=False))
# split the dataset in train and test set
torch.manual_seed(1)
indices = torch.randperm(len(dataset)-1).tolist()
split_size = round(len(dataset)*0.8)
dataset = torch.utils.data.Subset(dataset, indices[:split_size])
dataset_test = torch.utils.data.Subset(dataset_test, indices[split_size:])
# define training and validation data loaders
data_loader = torch.utils.data.DataLoader(
dataset, batch_size=batch_size_train, shuffle=True, num_workers=NUM_WORKERS,
collate_fn=utils.collate_fn)
data_loader_test = torch.utils.data.DataLoader(
dataset_test, batch_size=batch_size_test, shuffle=False, num_workers=NUM_WORKERS,
collate_fn=utils.collate_fn)
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
# get the model using the helper function
model = get_instance_segmentation_model(num_classes)
model.to(device)
# construct an optimizer
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005,
momentum=0.9, weight_decay=0.0005)
# the learning rate scheduler decreases the learning rate by 10x every 3 epochs
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer,
step_size=3,
gamma=0.1)
for epoch in range(num_epochs):
print("===>current epoch<===%d",epoch)
# train for one epoch, printing every 10 iterations
train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq=10)
# update the learning rate
lr_scheduler.step()
# evaluate on the test dataset
evaluate(model, data_loader_test, device=device)
torch.save(model.state_dict(), 'fasterrcnn_model.pkl')
#*************测试*****************#
def get_prediction(img_path, threshold):
model = get_instance_segmentation_model(num_classes)
model.load_state_dict(torch.load('fasterrcnn_model.pkl'))
model.eval()
img = Image.open(img_path) # Load the image
transform = T_ori.Compose([T_ori.ToTensor()]) # Defing PyTorch Transform
img = transform(img) # Apply the transform to the image
pred = model([img]) # Pass the image to the model
#print('pred')
#print(pred)
#pred_class = [COCO_INSTANCE_CATEGORY_NAMES[i] for i in list(pred[0]['labels'].numpy())] # Get the Prediction Score
#print("original pred_class")
#print(pred_class)
pred_boxes = [[(i[0], i[1]), (i[2], i[3])] for i in list(pred[0]['boxes'].detach().numpy())] # Bounding boxes
pred_class=pred[0]['labels'].numpy()
#print("original pred_boxes")
#print(pred_boxes)
pred_score = list(pred[0]['scores'].detach().numpy())
# print("orignal score")
#print(pred_score)
#pred_t = [pred_score.index(x) for x in pred_score if x > threshold][-1] # Get list of index with score greater than threshold.
pred_t = []
for x in pred_score:
if x > threshold:
idx = pred_score.index(x)
pred_t.append(idx)
#没有满足阈值的结果
if len(pred_t) == 0:
pred_boxes = []
pred_class = []
else:
pred_boxes = pred_boxes[:pred_t[-1]+1]
#pred_class = pred_class[:pred_t+1]
#print(pred_t)
#print(pred_boxes)
#print(pred_class)
return pred_boxes, pred_class
def object_detection_api(img_path, threshold=0.5, rect_th=2, text_size=1, text_th=1):
boxes, pred_cls = get_prediction(img_path, threshold) # Get predictions
if len(pred_cls) == 0:
print("No Object is found\n")
return
img = cv2.imread(img_path) # Read image with cv2
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # Convert to RGB
for i in range(len(boxes)):
cv2.rectangle(img, boxes[i][0], boxes[i][1],color=(0, 255, 0), thickness=rect_th) # Draw Rectangle with the coordinates
text = COCO_INSTANCE_CATEGORY_NAMES[pred_cls[i]]
cv2.putText(img,text, boxes[i][0], cv2.FONT_HERSHEY_SIMPLEX, text_size, (0,255,0),thickness=text_th) # Write the prediction class
plt.figure(figsize=(20,30)) # display the output image
plt.imshow(img)
plt.xticks([])
plt.yticks([])
plt.show()
cv2.imwrite('1-res.jpg',img)
def main():
#print(torch.__version__)
#print(torchvision.__version__)
#print(cv2.__version__)
#return
print("*****start training*****") #训练
train()
print("*****start testing*****") #测试
object_detection_api('/home/tjmt/tjmt_new/notebook/test-cx/000888.jpg', threshold=0.4)
print("******done*******")
if __name__ == "__main__":
main()
多GPU训练
发生异常: RuntimeError
Caught RuntimeError in replica 0 on device 0.
Original Traceback (most recent call last):
File "/home/tjmt/.local/lib/python3.6/site-packages/torch/nn/parallel/parallel_apply.py", line 60, in _worker
output = module(*input, **kwargs)
File "/home/tjmt/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 532, in __call__
result = self.forward(*input, **kwargs)
File "/home/tjmt/.local/lib/python3.6/site-packages/torchvision/models/detection/generalized_rcnn.py", line 66, in forward
images, targets = self.transform(images, targets)
File "/home/tjmt/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 532, in __call__
result = self.forward(*input, **kwargs)
File "/home/tjmt/.local/lib/python3.6/site-packages/torchvision/models/detection/transform.py", line 46, in forward
image = self.normalize(image)
File "/home/tjmt/.local/lib/python3.6/site-packages/torchvision/models/detection/transform.py", line 66, in normalize
return (image - mean[:, None, None]) / std[:, None, None]
RuntimeError: The size of tensor a (2) must match the size of tensor b (3) at non-singleton dimension 0
File "/home/tjmt/tjmt_new/notebook/test-cx/MaskRcnn-torch/engine.py", line 90, in train_one_epoch
loss_dict = model(images, targets)
File "/home/tjmt/tjmt_new/notebook/test-cx/MaskRcnn-torch/torch-object-detection-fudan.py", line 144, in train
train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq=20)
File "/home/tjmt/tjmt_new/notebook/test-cx/MaskRcnn-torch/torch-object-detection-fudan.py", line 259, in main
train()
File "/home/tjmt/tjmt_new/notebook/test-cx/MaskRcnn-torch/torch-object-detection-fudan.py", line 268, in python -m torch.distributed.launch --nproc_per_node=2 --use_env 你自己的train文件.py#*************************训练************************#
# use the PennFudan dataset and defined transformations
def train():
dataset = VOCDataset(dataset_path, get_transform(train=True))
dataset_test = VOCDataset(dataset_path, get_transform(train=False))
# split the dataset in train and test set
torch.manual_seed(1)
indices = torch.randperm(len(dataset)).tolist()
#indices = [k for k in range(len(dataset))]
split_size = round(len(dataset)*0.9)
dataset = torch.utils.data.Subset(dataset, indices[:split_size])
dataset_test = torch.utils.data.Subset(dataset_test, indices[split_size:])
# define training and validation data loaders
# data_loader = torch.utils.data.DataLoader(
# dataset, batch_size=batch_size_train, shuffle=True, num_workers=NUM_WORKERS,collate_fn=utils.collate_fn)
train_sampler = torch.utils.data.distributed.DistributedSampler(dataset)
data_loader = torch.utils.data.DataLoader(dataset, batch_size=batch_size_train, shuffle=False,collate_fn=utils.collate_fn,
num_workers=NUM_WORKERS, pin_memory=True, drop_last=True,sampler=train_sampler)
data_loader_test = torch.utils.data.DataLoader(
dataset_test, batch_size=batch_size_test, shuffle=True, num_workers=NUM_WORKERS ,collate_fn=utils.collate_fn)
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
# get the model using the helper function
model = get_instance_segmentation_model(num_classes)
# move model to the right device
model.to(device)
if args.distributed:
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.gpu])
print('we use parallel mode by {} gpus'.format([args.gpu]))
#model=torch.nn.parallel.DistributedDataParallel(model,device_ids=[torch.cuda.current_device()])
#print("Current Gpus: =>",torch.cuda.current_device())
# construct an optimizer
params = [p for p in model.parameters() if p.requires_grad]
#lr=learning rate;
optimizer = torch.optim.SGD(params, lr=0.005, momentum=0.9, weight_decay=0.0005)
#optimizer = torch.optim.Adam(params,lr=0.005,)
# the learning rate scheduler decreases the learning rate by 10x every 3 epochs
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.9)
#print("******>total epoches<%d*****",num_epochs)
for epoch in range(num_epochs):
print("===>current epoch: ",epoch)
# train for one epoch, printing every 10 iterations
train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq=20)
if lr_scheduler is not None:
lr_scheduler.step()
# evaluate on the test dataset
#evaluate(model, data_loader_test, device=device)
if epoch % 10 == 0:
torch.save(model.state_dict(), model_save_name)
torch.save(model.state_dict(), model_save_name)ef main(args):
utils.init_distributed_mode(args)
print(args)
#torch.distributed.init_process_group(backend="nccl")
print("*****start training*****") #训练
start_time = time.time()
train()
total_time = time.time() - start_time
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
print('Training time {}'.format(total_time_str))
return
print("*****start testing*****") #测试\
object_detection_api(test_img_path, threshold=detection_thre)
print("******done*******")
if __name__ == "__main__":
import os
import re
import argparse
parser = argparse.ArgumentParser(
description=__doc__)
parser.add_argument('--data-path', default='/datasets01/COCO/022719/', help='dataset')
parser.add_argument('--dataset', default='coco', help='dataset')
parser.add_argument('--model', default='maskrcnn_resnet50_fpn', help='model')
parser.add_argument('--device', default='cuda', help='device')
parser.add_argument('-b', '--batch-size', default=2, type=int,
help='images per gpu, the total batch size is $NGPU x batch_size')
parser.add_argument('--epochs', default=26, type=int, metavar='N',
help='number of total epochs to run')
parser.add_argument('-j', '--workers', default=4, type=int, metavar='N',
help='number of data loading workers (default: 4)')
parser.add_argument('--lr', default=0.02, type=float,
help='initial learning rate, 0.02 is the default value for training '
'on 8 gpus and 2 images_per_gpu')
parser.add_argument('--momentum', default=0.9, type=float, metavar='M',
help='momentum')
parser.add_argument('--wd', '--weight-decay', default=1e-4, type=float,
metavar='W', help='weight decay (default: 1e-4)',
dest='weight_decay')
parser.add_argument('--lr-step-size', default=8, type=int, help='decrease lr every step-size epochs')
parser.add_argument('--lr-steps', default=[16, 22], nargs='+', type=int, help='decrease lr every step-size epochs')
parser.add_argument('--lr-gamma', default=0.1, type=float, help='decrease lr by a factor of lr-gamma')
parser.add_argument('--print-freq', default=20, type=int, help='print frequency')
parser.add_argument('--output-dir', default='.', help='path where to save')
parser.add_argument('--resume', default='', help='resume from checkpoint')
parser.add_argument('--start_epoch', default=0, type=int, help='start epoch')
parser.add_argument('--aspect-ratio-group-factor', default=3, type=int)
parser.add_argument(
"--test-only",
dest="test_only",
help="Only test the model",
action="store_true",
)
parser.add_argument(
"--pretrained",
dest="pretrained",
help="Use pre-trained models from the modelzoo",
action="store_true",
)
# distributed training parameters
parser.add_argument('--world-size', default=1, type=int,
help='number of distributed processes')
parser.add_argument('--dist-url', default='env://', help='url used to set up distributed training')
args = parser.parse_args()
if args.output_dir:
utils.mkdir(args.output_dir)
args = parser.parse_args()
main(args)