python绘制训练结果曲线图和散点图、解决坐标刻度标签重复问题 、利用训练标准输出流绘制
python绘制训练结果曲线图和散点图、解决坐标刻度标签重复问题 、利用训练标准输出流绘制
- python绘制训练结果图
-
- 训练结果标准输出流
- 删除标准输出流中多余内容
- 正则表达式提取数据
- 绘制曲线图和散点图
- 戏剧性bug,y轴标签重叠问题
- 分享一个修改刻度密度的方法
python绘制训练结果图
最近, 用python在服务器做训练,得出了一些数据结果。由于在服务器端将训练结果直接绘图蜜汁得不到结果(未解之谜),于是我将标准输出流保存了下来,苦于搜索几天没有现成的对于标准输出流直接绘制成训练结果曲线图的,于是着手自己编写绘制训练过程的准确度和损失的曲线图。先给大家看看整体效果。由于在绘制图像过程中遇到了个很简单的bug,却调试几天才发现,愤而记下此文以警戒自己。
训练结果标准输出流
在服务器端进行训练的时候,需要利用pbs提交作业,并在.pbs脚本文件中指定标准输出流和错误输出流。部分脚本如下:
#!/bin/bash
#PBS -N base_all_rnd
#PBS -o base_all_rnd_SetOut
#PBS -e base_all_rnd_SetErr
#PBS -l nodes=2:gpus=2
#PBS -r y
#PBS -m e
#PBS -q batch
-o指定标准输出流
-e指定错误输出流
训练完成之后下载,用记事本打开标准输出流文件,部分内容如下:
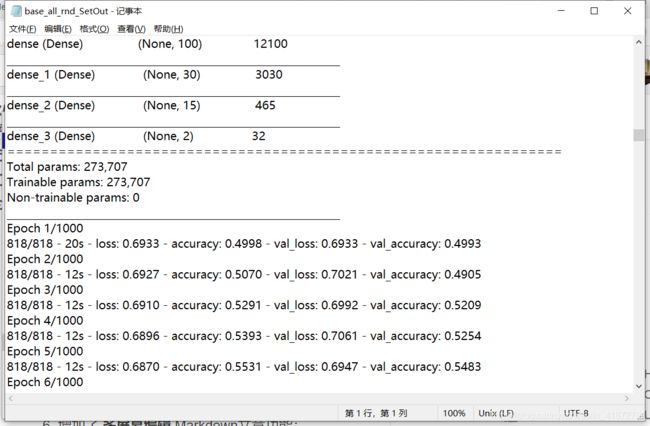
今天我们将利用标准输出流中的每一次训练迭代的精确度和损失值绘制曲线图便于后期分析模型质量。
删除标准输出流中多余内容
绘制模型曲线图,从epoch 1/1000以上的内容全都无关不需要,于是删除,以防出现其他错误。
正则表达式提取数据
输出流中不仅包含很多我们需要的数据,还保留着很多干扰的字符,于是需要用正则表达式匹配accuracy 和loss等数据。
1、用readlines()函数读取文件的每一行
2、用正则表达式:patt3 = r"[0-9].[0-9]+" 匹配需要的数据。
3、用re.findall(patt3,line) 找到每一行的匹配成功的数据字符串。
4、用float()将提取出的字符串转化为float类型。(这点很重要!!我就是在这里栽了两天,才愤而写此文警戒自己)
5、np.save()将数据数组保存下来,方便下次使用。(这一步可有可无,看你自己需求)
废话不多说,直接上代码:
import re
import numpy as np
def read_setout(file_name):
file = open(file_name)
loss = []
acc = []
val_loss = []
val_acc = []
while 1:
lines = file.readlines(100000)
if not lines:
break
for line in lines: # do something
#patt1 = r"^Epoch\s[0-9]+\/[0-9]+"
#patt2 = r"loss:\s[0-9]\.[0-9]+"
patt3 = r"[0-9]\.[0-9]+"
#result = re.search(patt3, line)
result = re.findall(patt3,line)
if len(result) !=4 :
continue
loss.append(float(result[0])) #float将字符串转换为浮点型
acc.append(float(result[1]))
val_loss.append(float(result[2]))
val_acc.append(float(result[3]))
np.save(open('acc.npy', 'wb+'), acc)
np.save(open('val_acc.npy', 'wb+'), val_acc)
np.save(open('loss.npy', 'wb+'), loss)
np.save(open('val_loss.npy', 'wb+'), val_loss)
file.close()
绘制曲线图和散点图
利用matplotlib来绘制训练过程曲线图和散点图。各函数功能或重点事项在代码注释中。
1、前面将数据保存在.npy文件中,于是在这里用np.load()读取.npy文件,读取完仍然是一个数组。
2、因为我们的数据是一个个点(对于坐标的y值),没有x值,而绘制散点图的时候需要坐标(x,y),所以需要用linspace()去生成等差数列x坐标值。
3、plt.figure()绘制一张图纸。其中figsize=()设置图纸宽高。
4、fig.add_subplot(111)为图纸添加一张子图。
5、plot()函数绘制曲线图,可指定曲线的颜色、线宽、标签,标志等。
6、scatter()函数绘制散点图,可指定曲线的颜色、线宽、标签,标志等。
7、set_xlim()设置坐标轴范围。
8、set_xticks()设置x轴坐标刻度,参数minor=True表示设置副刻度
9、tick_params()设置刻度属性,axis='both’选择要进行设置的坐标轴为x和y轴, which='major’选择要进行设置的刻度是主刻度, direction=‘inout’,设置刻度的方向是由里到外,即穿插坐标轴。 length和width设置线长和宽, pad设置坐标轴标签与坐标轴的距离,labelsize设置标签字体大小。
10、set_xlabel()、set_ylabel()设置x、y轴名称。
11、set_title()设置子图标题。
12、plt.legend(),添加图例,参数fontsize指定图例标签大小。
13、grid(),添加网格,linestyle,linewidth指定网格线型和线宽。
14、suptitle(),添加figure总标题fontsize指定字体大小。
15、plt.show()显示图像。
16、fig.savefig()保存图纸。
17、plt.close(fig)在内存中关闭图纸,绘制批量图像时使用。
代码如下:
from matplotlib import pyplot as plt
def plot_data()
train_acc = np.load('acc.npy')
val_acc = np.load('val_acc.npy')
train_loss = np.load('loss.npy')
val_loss = np.load('val_loss.npy')
x = np.linspace(1,10000,10000) #起始值为1,终止值为10000,数据个数10000的等差数列
print(x)
fig = plt.figure(figsize=(35,30))
sub = fig.add_subplot(111)
sub.plot(x, train_acc, color='red', linewidth=5, label='Training Accuracy')
plt.scatter(x, val_acc, color='blue', marker='o', linewidths=2, label='Validation Accuracy') #验证集上的结果比较不稳定,故绘制成散点图
sub.plot(x, train_loss, color='orange', linewidth=5, label='Training Loss')
plt.scatter(x, val_loss, color='green', marker='*', linewidths=2, label='Validation Loss')
#sub.set_xlim([0, 10000]) #设置坐标轴范围,0~10000
#sub.set_ylim([0.0, 1.0]) #设置坐标轴范围,0.0~1.0
sub.set_xticks(np.arange(0, 10001, 1000)) #arange()类似linspace,初始值为0,终止值为<10001,步长为1000的等差数列。如果等差数列最后一个数为10001,则10001不包含进来。
sub.set_xticks(np.arange(0, 10001, 500), minor=True) #set_xticks()设置x轴坐标刻度,minor=True表示设置副刻度
sub.set_yticks(np.arange(0, 1.21, 0.1))
sub.set_yticks(np.arange(0, 1.21, 0.02), minor=True)
sub.tick_params(axis='both', which='major', direction='inout', length=25, width=7, pad=50, labelsize=45) #设置刻度属性
sub.tick_params(axis='both', which='minor', direction='in', length=20, width=3, pad=50, labelsize=45) #axis='both'选择要进行设置的坐标轴为x和y轴, which='major'选择要进行设置的刻度是主刻度, direction='inout',设置刻度的方向是由里到外,即穿插坐标轴。 length和width设置线长和宽, pad设置坐标轴标签与坐标轴的距离,labelsize设置标签字体大小。
sub.set_xlabel('epochs', fontsize=50)
sub.set_ylabel('accuracy or loss', fontsize=50)
sub.set_title('Training and Validation Accuracy and Loss', fontsize=70)
plt.legend(fontsize=45) #添加图例
sub.grid(linestyle='--', linewidth=3) #添加网格
#fig.suptitle('figure', fontsize=100) #添加figure总标题
plt.show()
fig.savefig('base_all_SetOut.png', dpi=500)
plt.close(fig)
绘制出的图像结果如下:
戏剧性bug,y轴标签重叠问题
在绘制图像的过程中,我遇到了一个很戏剧性的bug——标签重叠很严重,如下图。在网上搜索了众多方案,但都离不开设置刻度密度、设置刻度、设置主刻度、分刻度、设置标签、设置刻度范围共享坐标刻度等等众多方案。但是调了两天,无果,完全无果。y轴刻度要么是疯狂重叠要么是直接几乎没有甚至是绘制不出曲线。让我几度怀疑我打印图像部分代码哪里细节出错,每次都重写迭代好几版,还是没能解决。上网搜索专门针对plot()的课程,甚至到最后怀疑环境问题,还用不同的平台编译器尝试,统统无果。

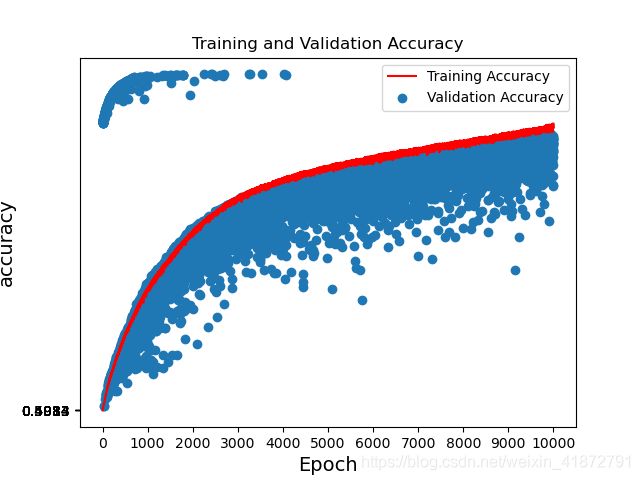
直到我想放弃,想将数据导出到excel,用excel来绘图。突然发现excel中出现很多警示提示是否要将文本转换为数值。茅塞顿开,我才发现我居然忘了将匹配出来的字符串转换为数值类型的。根本就不是打印图像部分代码出错。是那些数据就是一堆字符,怎么对它们进行数学操作都是无效的呀。刚转换完我明明有想过要转换类型的,怎么没做呢,哭唧唧,浪费两天时间,真是被自己蠢哭了。
by the way,感觉其实用excel绘图还是挺香的,一键制作,可视化更改参数,都不用自己改代码调代码,bug也是显而易见,至少我这个bug是能一眼在excel中看出来的。咱也不用总纠结于代码,及时行乐及时行乐,有可视化工具直接嫖也挺香。
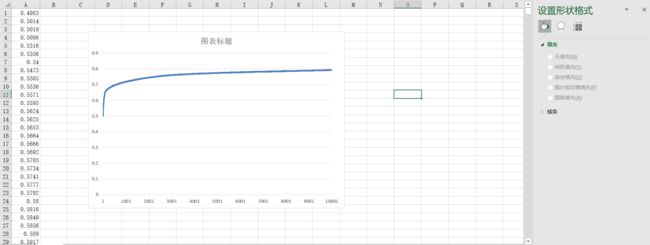
这里附赠一份将np数组保存到.xlsx的代码,主要将ndarray格式转换为DataFrame格式。
import pandas as pd
import numpy as np
# 准备数据
data = np.load('acc.npy')
data_df = pd.DataFrame(data) #将ndarray格式转换为DataFrame
# 将文件写入excel表格中
writer = pd.ExcelWriter('data.xlsx') #创建名称为data的excel表格
data_df.to_excel(writer,'page_1',float_format='%.5f') #float_format 控制精度,将data_df写到data表格的第一页中。若多个文件,可以在page_2中写入
writer.save()
分享一个修改刻度密度的方法
利用MultipleLocator类设置刻度间隔。
from matplotlib.pyplot import MultipleLocator #从pyplot导入MultipleLocator类,这个类用于设置刻度间隔
x_major_locator = MultipleLocator(1000) # 把x轴的刻度间隔设置为1000,并存在变量里
y_major_locator = MultipleLocator(0.1) # 把y轴的刻度间隔设置为0.1,并存在变量里
ax = plt.gca() # ax为两条坐标轴的实例
ax.xaxis.set_major_locator(x_major_locator) # 把x轴的主刻度设置为1000的倍数
ax.yaxis.set_major_locator(y_major_locator) # 把y轴的主刻度设置为0.1的倍数