神经网络算法的具体流程,深度神经网络简单介绍
深度神经网络具体的工作流程是什么样的?
第一,深度神经网络不是黑盒,个人电脑开机直到神经网络运行在内存中的每一比特的变化都是可以很细微的观察的。没有任何神秘力量,没有超出科学解释的现象发生。
第二,深度神经网络的工作方式是基于传统的电脑架构之上的,就是数据+算法。但人们确实从中窥探到了一种全新的电子大脑方式。所以目前有研究提炼一些常用神经网络算法加速硬件。微软等巨头则在开发量子计算。
第三,深度神经网络是一个很初级的特征自动提取器。说初级因为简单粗暴。以前为了节约算力特征关键模型都是人工亲自设定。而现在这部分工作随着算力的提高可以自动化。
所以从某种意义上来说深度神经网络也是一种自动编程机,但和人们相比,一点点小小的自动化都需要很多很多的计算力支持,这一点也不重要,重要的是,它能工作(手动英文)。那么深度神经网络究竟是什么呢?
它是一个能迭代更新自己的特征提取算法。现在这个算法可是像全自动高级工厂,数据往里一丢,不得了!整个工厂里面所有机器都动了起来。没见过的小伙伴当场就被吓呆瓜了,用流行的话说叫懵住。
几千只机械手把数据搬来搬去,拿出魔方一样的盒子装来装去又倒出来。整个场面就叫一个震撼。算法运行规模也更大了。
学习深度学习如何下手
其实对于初学者来说,不建议刚开始就学算法,因为脱离业务和数据的算法讨论是毫无意义的,刚开始应该先打好编程和数学基础AI爱发猫 www.aifamao.com。
深度学习看似难度大,按照正确的学习路径学习,可以大大降低学习门槛,同时激发学习的乐趣。
简单的说,学习路线大概如下:先学编程、数学和深度学习知识,然后动手实践撸代码,有机会的话多参加数据科学比赛,多做项目练习实操能力。众所周知,深度学习是一个将理论算法与计算机工程技术紧密结合的领域。
对于零基础小白,想往深度学习发展,要掌握哪些数学知识呢?首先是线性代数。在神经网络中大量的计算都是矩阵乘法,这就需要用到线性代数的知识了。
计算向量的余弦相似度也要用到内积运算,矩阵的各种分解办法也出现在主成分分析和奇异值分解中。其次是概率论与统计学。
广义的说,机器学习的核心是统计推断,机器学习的巨头不少都是统计学大师,如迈克尔乔丹,杨乐坤,辛顿等,另外机器学习中大量用到贝叶斯公式,隐马尔科夫模型等等。再次就是微积分。
这是机器学习中的核心知识之一,无论是梯度下降法中的求梯度还是反向传播中的误差传递的推导都需要用到微积分。
我们知道,深度学习是一个将理论算法与计算机工程技术紧密结合的领域,需要扎实的理论基础来帮助你分析数据,同时需要工程能力去开发模型和部署服务。
所以只有编程技能、机器学习知识、数学三个方面共同发展,才能取得更好的成果。
按我们的学习经验,从一个数据源开始——即使是用最传统、已经应用多年的机器学习算法,先完整地走完机器学习的整个工作流程,不断尝试各种算法深挖这些数据的价值,在运用过程中把数据、特征和算法搞透,真正积累出项目经验,才能更快、更靠谱的掌握深度学习技术。
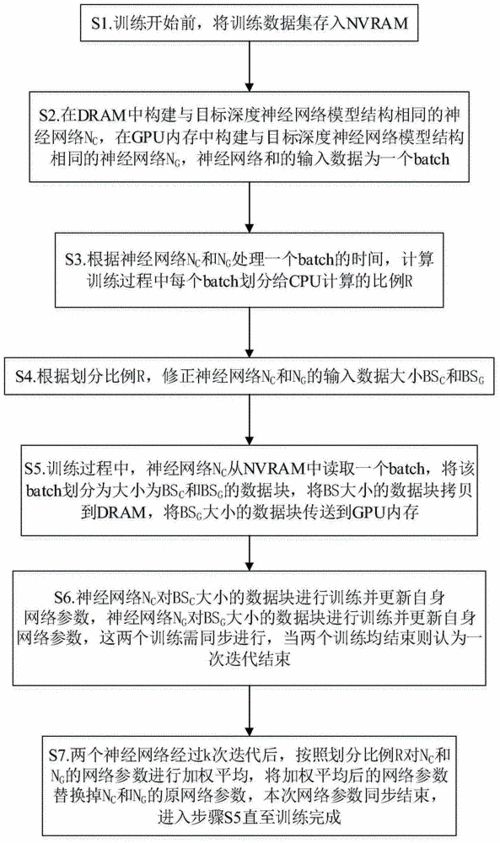
深度神经网络是如何训练的?
Coursera的Ng机器学习,UFLDL都看过。没记错的话Ng的机器学习里是直接给出公式了,虽然你可能知道如何求解,但是即使不知道完成作业也不是问题,只要照着公式写就行。
反正我当时看的时候心里并没能比较清楚的明白。我觉得想了解深度学习UFLDL教程-Ufldl是不错的。有习题,做完的话确实会对深度学习有更加深刻的理解,但是总还不是很清晰。
后来看了LiFeiFei的StanfordUniversityCS231n:ConvolutionalNeuralNetworksforVisualRecognition,我的感觉是对CNN的理解有了很大的提升。
沉下心来推推公式,多思考,明白了反向传播本质上是链式法则(虽然之前也知道,但是当时还是理解的迷迷糊糊的)。所有的梯度其实都是对最终的loss进行求导得到的,也就是标量对矩阵or向量的求导。
当然同时也学到了许多其他的关于cnn的。并且建议你不仅要完成练习,最好能自己也写一个cnn,这个过程可能会让你学习到许多更加细节和可能忽略的东西。
这样的网络可以使用中间层构建出多层的抽象,正如我们在布尔线路中做的那样。
例如,如果我们在进行视觉模式识别,那么在第一层的神经元可能学会识别边,在第二层的神经元可以在边的基础上学会识别出更加复杂的形状,例如三角形或者矩形。第三层将能够识别更加复杂的形状。依此类推。
这些多层的抽象看起来能够赋予深度网络一种学习解决复杂模式识别问题的能力。然后,正如线路的示例中看到的那样,存在着理论上的研究结果告诉我们深度网络在本质上比浅层网络更加强大。
对如下BP神经网络,写出它的计算公式(含学习公式),并对其初始权值以及样本x1=1,x
神经网络算法的三大类分别是?
神经网络算法的三大类分别是:1、前馈神经网络:这是实际应用中最常见的神经网络类型。第一层是输入,最后一层是输出。如果有多个隐藏层,我们称之为“深度”神经网络。他们计算出一系列改变样本相似性的变换。
各层神经元的活动是前一层活动的非线性函数。2、循环网络:循环网络在他们的连接图中定向了循环,这意味着你可以按照箭头回到你开始的地方。他们可以有复杂的动态,使其很难训练。他们更具有生物真实性。
循环网络的目的是用来处理序列数据。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。
循环神经网路,即一个序列当前的输出与前面的输出也有关。
具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。
3、对称连接网络:对称连接网络有点像循环网络,但是单元之间的连接是对称的(它们在两个方向上权重相同)。比起循环网络,对称连接网络更容易分析。这个网络中有更多的限制,因为它们遵守能量函数定律。
没有隐藏单元的对称连接网络被称为“Hopfield网络”。有隐藏单元的对称连接的网络被称为玻尔兹曼机。
扩展资料:应用及发展:心理学家和认知科学家研究神经网络的目的在于探索人脑加工、储存和搜索信息的机制,弄清人脑功能的机理,建立人类认知过程的微结构理论。
生物学、医学、脑科学专家试图通过神经网络的研究推动脑科学向定量、精确和理论化体系发展,同时也寄希望于临床医学的新突破;信息处理和计算机科学家研究这一问题的目的在于寻求新的途径以解决不能解决或解决起来有极大困难的大量问题,构造更加逼近人脑功能的新一代计算机。
神经网络中的前向和后向算法
神经网络中的前向和后向算法看了一段时间的深度网络模型,也在tf和theano上都跑了一些模型,但是感觉没有潜下去,对很多东西的理解都只停留在“这个是干什么的”层次上面。
昨天在和小老师一起看一篇文章的时候,就被问到RNN里面的后向传播算法具体是怎么推。当时心里觉得BP算法其实很熟悉啊,然后在推导的过程中就一脸懵逼了。
于是又去网上翻了翻相关内容,自己走了一遍,准备做个笔记,算是个交代。准备一个神经网络模型,比如:其中,[i1,i2]代表输入层的两个结点,[h1,h2]代表隐藏层的两个结点,[o1,o2]为输出。
[b1,b2]为偏置项。连接每个结点之间的边已经在图中标出。
来了解一下前向算法:前向算法的作用是计算输入层结点对隐藏层结点的影响,也就是说,把网络正向的走一遍:输入层—->隐藏层—->输出层计算每个结点对其下一层结点的影响。
??例如,我们要算结点h1的值,那么就是:是一个简单的加权求和。这里稍微说一下,偏置项和权重项的作用是类似的,不同之处在于权重项一般以乘法的形式体现,而偏置项以加法的形式体现。
??而在计算结点o1时,结点h1的输出不能简单的使用neth1的结果,必须要计算激活函数,激活函数,不是说要去激活什么,而是要指“激活的神经元的特征”通过函数保留并映射出来。
以sigmoid函数为例,h1的输出:于是最后o1的输出结果,也就是整个网络的一个输出值是:按照上面的步骤计算出out02,则[outo1,outo2]就是整个网络第一次前向运算之后得到的结果。
后向算法:??在实际情况中,因为是随机给定的权值,很大的可能(几乎是100%)得到的输出与实际结果之间的偏差非常的大,这个时候我们就需要比较我们的输出和实际结果之间的差异,将这个残差返回给整个网络,调整网络中的权重关系。
这也是为什么我们在神经网络中需要后向传播的原因。
其主要计算步骤如下:1.计算总误差2.隐藏层的权值更新在要更新每个边的权重之前,必须要知道这条边对最后输出结果的影响,可以用整体误差对w5求偏导求出:具体计算的时候,可以采用链式法则展开:在计算的时候一定要注意每个式子里面哪些自变量是什么,求导千万不要求错了。
??需要讲出来的一个地方是,在计算w1的权重时,Etotal中的两部分都需要对它进行求导,因为这条边在前向传播中对两个残差都有影响3.更新权重这一步里面就没什么东西了,直接根据学习率来更新权重:至此,一次正向+反向传播过程就到此为止,接下来只需要进行迭代,不断调整边的权重,修正网络的输出和实际结果之间的偏差(也就是training整个网络)。
深度学习入门课程学习笔记02 得分函数
深度学习入门课程学习笔记02得分函数前向传播之-得分函数剧透:深度学习必备的两个大知识点分别是前向传播和反向传播啦,这里节课我们会先着手把前方传播的所涉及的所有知识点搞定!
我相信这部分对于咱们即便没有什么基础的同学来说也是很容易理解的。得分函数:这个就是咱们这节课最核心的一个问题啦。什么叫得分函数呢?下面这个图就给了我们一个最直接的答案!
得分函数的目的:我们要做的就是对于一个给定的输入,比如一张小猫的图片,通过一系列复杂的变换(中间的过程咱们暂且当做一个黑盒子)能得到这个输入对应于每个类别的得分数值。
可能有些同学对于一个输入的图片如何计算出它的得分还有点困惑,这里我简单的来说一下从输入到输出的一个矩阵计算过程。
矩阵求解过程理解:首先对于一个32*32*3的输入,我们把它拉伸成一个列向量,也就是一个3072*1的向量,咱们下面用最简单的线性分类来解释整个过程,在线性分类中,我们需要权重参数W和B,那么W是整个线性分类的核心参数,我们要把一个输入分成10个类别并且对于每个类别给定一个得分数值,这样咱们的W参数矩阵就是一个10*3072的矩阵,我们可以通俗的理解成对于每一个类别我们都有3072个小参数去和咱们的输入(3072维的列向量)去计算最终的的分值,那么10就是我们最终要输入多少个类别。
参数B就很好理解啦,这里咱们就不说啦。
得分函数计算实例:上图就是一个得分函数计算的最简单的一个流程,我们假设图像是有4个像素点组成的,然后咱们把它拉成了一个列向量(Xi),权重参数W是一个3*4的矩阵,因为咱们要把输入分成三个类别,最终再加上参数b得到了最终这只小猫属于每个类别的得分数值。
理解参数W和b:下面咱们再通过这张图来形象的理解下参数W和b,在真实的情况下对于每一个类别的参数W是一个3072维的,但是咱们为了形象化理解把它画在了2维的空间中,我们可以从图中看到三种颜色的线代表了三个线性分类器,参数W的每一个小权重的改变(共有3072个小权重)意味着这条线在改变的小参数的那个维度发生了偏转,我们可以想象2维空间中对于W的改变意味着什么然后再去想象这个3072维的空间。
那么这个b参数是不是就没用呢?(有用你干嘛一直不说?)其实参数b是比不可少的,因为如果没有b那么所有的分类线都会交集与零点,这显然是不可取的嘛。
小总结:咱们这节课很轻松吧,但是如何从一个输入计算出它最终属于每一个类别的得分在一个实际的深度学习网络中可没这么简单就搞定,我这样做只是让大家能更好的理解这个得分函数。
深度神经网络中最上面一个隐层到输出层之间的权重和偏移量如何计算?
说的确定应该就是训练方法吧,神经网络的权值不是人工给定的。
而是用训练集(包括输入和输出)训练,用训练集训练一遍称为一个epoch,一般要许多epoch才行,目的是使得目标与训练结果的误差(一般采用均方误差)小到一个给定的阈值。
以上所说是有监督的学习方法,还有无监督的学习方法。