4.一脚踹进ViT——ViT再审视与DeiT的实现
4.一脚踹进ViT——ViT再审视与DeiT的实现
1.ViT的几个问题
1.1 为什么不在MLP中做LayerNorm?
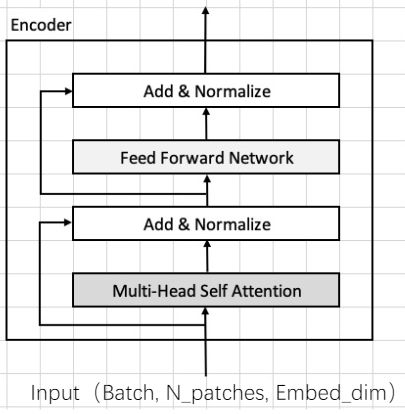
其实我们在MLP之后会做Norm,我们MLP层后会有Residual加法,若我们在MLP中加入Norm,走完MLP进行残差链接后还需要再去做一次,于是就在最后做一次就行了。
1.2 cls token 与 pos_embedding
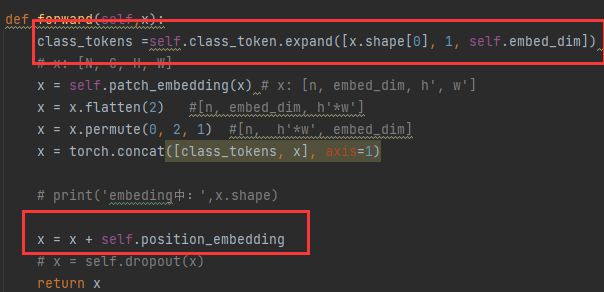
cls token用的expand的方式,需要对每一个样本都去增加cls token去做分类
pos_embedding使用的是boardcast(广播方式),所有图片都是使用统一的方式去切patch,所以每一个patch的顺序是一样的,我们可以使用广播机制,对于batch中的每一个样本去加同一个position embedding,如果我们的position是1,2,3顺序的话,我们每一个样本都是按照这样加进去的,所以可以使用同一个pos_embedding。
ViT训练模型很难,要求算力较高,那如何更有效的训练ViT模型?
2.DeiT(Data-efficient image Transformers)
DeiT被提出,在ViT-B上改进后,最终acc提升了约6个点,解决的最大的问题:
-
ViT模型性能被大幅度提高了
-
ViT模型能够用8卡甚至4卡训练
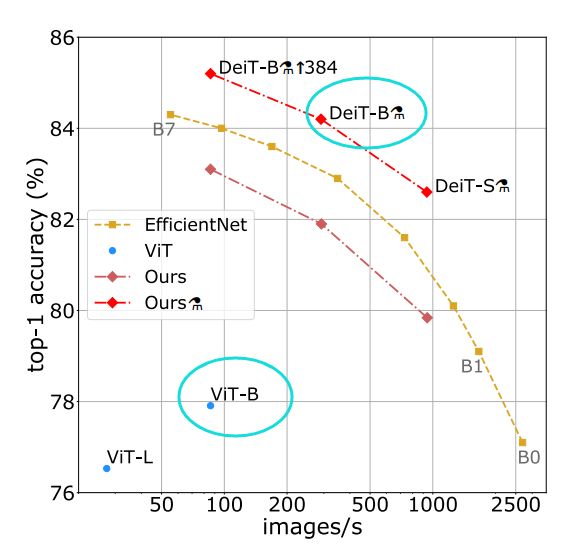
DeiT与ViT结构差不多,它进行了一些改进,能够取得更好的效果的方法:
-
Better Hyperparameter(更好超参数设置)——保证模型更好收敛
-
Data Augmentation(多个数据增广)——可以使用小数据训练
-
Distillation(知识蒸馏)/Teacher-Student——进一步提升性能
2.1 知识蒸馏
即用老师模型去训练学生模型,老师模型(B)是提前预训练好的,学生模型(A)就是我们当前要训练的,B模型是已经在某些数据集上达到较好的效果,是不拿来训练的,只是帮助模型A去提高性能。
我们Teacher Model已经可以提出一个带有分类信息的Feature Vector,已经可以对其做softmax,在softmax之前对其除了一个数(后面会说),在softmax之后,我们得到了对类别的概率表示,我们叫做Soft Labels,先存放起来。
在对Student Model训练时,它也会走一个前向过程,经过Softmax,之后也会得到一个预测结果,它会与Teacher Model分类的结果计算Loss(KLDivLoss),也叫做Teacher Loss;同样,他会与Ground Truth进行比对,计算CrossEntroyLoss,最终两个Loss加权得到最终Loss
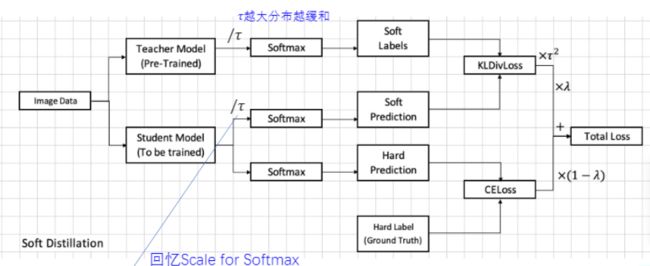
Teacher Loss前向操作在Softmax之前会计算除以τ,我们的数据在Softmax之前若除以一个数字,如果除的越大,最终得到的Feature Var会越小,经过softmax之后就会越平滑。所以,τ来控制Softmax之后概率分布更平滑还是更抖动,这种方式因为有Soft Label和Soft Prediction ,也叫做Soft Distillation(软蒸馏),使用老师的预测分布和学生的预测分布来算Loss。
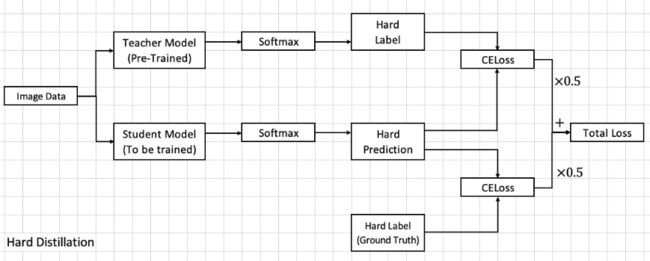
也可以直接取最终的标签,来与训练的模型输出Hard Prediction来算CELoss,这叫做Hard Distillation,貌似说这种方式效果更好。
那在ViT中是如何使用这种方式呢?
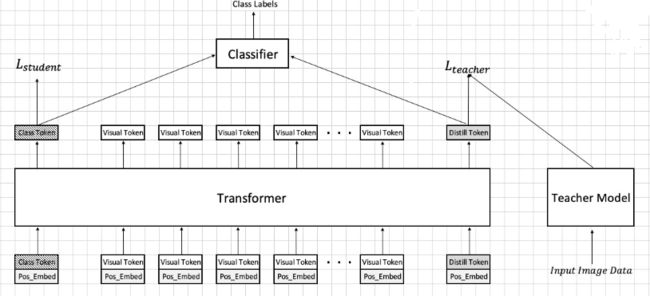
ViT中用Class Token来提取分类信息,我们可以加入一个新的Distill Token,也去学与其他Patch之间的Attention,学完后它产生的Loss连接的是Teacher Model中,Teacher Model的Loss与class Token与分类器的Loss(Student部分)进行加权,去算总Loss,去训练。
如果在预测时,Teacher 和 Student 部分都会产生一个feature,它们加权,就会得到最终的结果表达,经过分类器后,得到最终分类结果。
Teacher Model中用的已经训练好的CNN中的RegNet网络,也可以用其他网络。
2.2 更好的参数设置
通常网络初始化用Kaiming Norm,或者给一些常数,DeiT中用了一个新的方式,即
Truncated Norm Distribution(截断高斯标准分布):

将两侧以外的部分截断
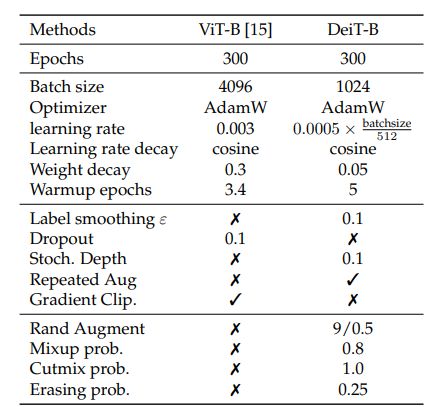
论文所用的一些超参数设置如下:
学习率是随着Batch Size变大逐渐变大的
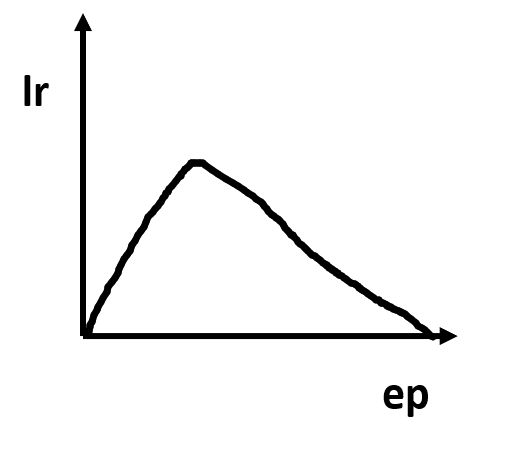
Learning rate decay 是加了一个warm up,先增加后面使用cos的函数将lr减小为0
2.3 数据增广
介绍的数据增广主要是RandomErase,Mixup,Cutmix,RandomAug,Droppath,EMA

RandomErase:随机将图像中的一块抹掉,随机填充一些填充的值
Mixup:将一个batch中的两个图的像素值取平均相加,label也变为了soft label,混合了两类的label
CutMix:将一个batch中的一个图切出来贴到另一个图像中,按比例去融合,比如图中0.3的比例给猫,0.7的比例给狗
RandomAug:是由google做的AutoAug的基础上设计的

我们有很多种方式来改变图像,例如:错切、平移、旋转、亮度调节、对比度调节等等,AutoAug为搜索出了25种变化,每次随机选择一条变化(每一条中有两个变化方式),这样用效果很好。
而RandAug认为AutoAug效果一般,它设计了13个policy,一次性随机选择6个方式依次对图像进行处理。

EMA(Exponential Moving Average)指数滑动平均:每次要把历史的权重取个平均
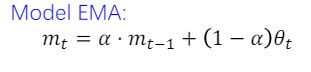
mt就是此时的权重,α是动量,一般设置的很接近1(0.9996),θ就是我们当前的模型,模型基本保持稳定的状态,来提升性能。
Label smoothing:看图

正常one-hot vector,属于第0类,即第0类是1,其他是0,smoothing是设置一个α,将真实Label减去α=0.1,将减去的值平均分给其他的类,0.1/5,其余每个分0.02
Droppath:
假设Batch是128,我们会有一个概率会把128个样本中n个样本置0,类似于Dropout
3.ViT + Distiall实现
看程序先找入口
设计DeiT函数,在模型前向过程中,加入一个x_distill部分与分类器相连
在patch_embedding中加入一个类似cls_token的distill_token,维度和cls_token一致,所以最后位置编码部分,shape 第二维度应该变为n_patches+2
在Encoder部分,最终得到的x的shape为
torch.Size([4, 198, 768])
返回cls tokens 和 distill tokens,即取第一个和第二个
return x[:,0],x[:,1]
其shape都为torch.Size([4, 768])
import torch
import torch.nn as nn
from torchinfo import summary
class Mlp(nn.Module):
def __init__(self,embed_dim, mlp_ratio=4.0, dropout=0.):
super().__init__()
self.fc1 = nn.Linear(embed_dim, int(embed_dim* mlp_ratio))
self.fc2 = nn.Linear(int(embed_dim* mlp_ratio),embed_dim)
self.act = nn.GELU()
self.dropout = nn.Dropout(p=dropout)
def forward(self,x):
x = self.fc1(x)
x = self.act(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.dropout(x)
return x
class Attention(nn.Module):
def __init__(self,embed_dim, num_heads, qkv_bias=False, dropout=0.,attention_dropout=0.):
super().__init__()
self.embed_dim =embed_dim
self.num_heads =num_heads
self.head_dim = int(embed_dim/num_heads)
self.all_head_dim = self.head_dim*num_heads
# 把所有q 写在一起, 所有k、V写在一起,然后拼接起来,前1/3代表了所有head的Q,每一个head的尺寸已经定义好,要用的时候切就行了
self.qkv = nn.Linear(embed_dim,
self.all_head_dim*3,
bias=False if qkv_bias is False else None)
self.scale = self.head_dim ** -0.5
self.softmax = nn.Softmax(-1)
self.proj = nn.Linear(self.all_head_dim,embed_dim)
def transpose_multi_head(self,x):
# x: [B, N, all_head_dim]
new_shape = x.shape[:-1] + (self.num_heads, self.head_dim)
x = x.reshape(new_shape)
# x: [B, N, num_heads, head_dim]
x = x.permute(0,2,1,3)
# x: [B, num_heads, num_patches, head_dim]
return x
def forward(self,x):
B,N ,_ = x.shape
qkv = self.qkv(x).chunk(3,-1)
# [B, N, all_head_dim]* 3 , map将输入的list中的三部分分别传入function,然后将输出存到q k v中
q, k, v = map(self.transpose_multi_head,qkv)
# q,k,v: [B, num_heads, num_patches, head_dim]
attn = torch.matmul(q,k.transpose(-1,-2)) #q * k'
attn = self.scale * attn
attn = self.softmax(attn)
# dropout
# attn: [B, num_heads, num_patches, num_patches]
out = torch.matmul(attn, v) # 这里softmax(scale*(q*k')) * v
out = out.permute(0,2,1,3)
# out: [B, num_patches,num_heads, head_dim]
out = out.reshape([B, N, -1])
out = self.proj(out)
#dropout
return out
class EncoderLayer(nn.Module):
def __init__(self,embed_dim=768, num_heads=4, qkv_bias=True, mlp_ratio=4.0, dropout=0., attention_drop=0.):
super().__init__()
self.attn_norm = nn.LayerNorm(embed_dim)
self.attn = Attention(embed_dim,num_heads)
self.mlp_norm = nn.LayerNorm(embed_dim)
self.mlp = Mlp(embed_dim,mlp_ratio)
def forward(self,x):
# PreNorm
h = x #residual
# print("imhere---------------")
# print(x.shape)
x = self.attn_norm(x)
x = self.attn(x)
x = x+h
h = x
x = self.mlp_norm(x)
x = self.mlp(x)
x = x+h
return x
class Encoder(nn.Module):
def __init__(self,embed_dim,depth):
super().__init__()
layer_list = []
for i in range(depth):
encoder_layer = EncoderLayer()
layer_list.append(encoder_layer)
self.layers = nn.ModuleList(layer_list)
self.norm = nn.LayerNorm(embed_dim)
def forward(self,x):
for layer in self.layers:
x = layer(x)
x = self.norm(x)
# TODO:return cls and distill tokens
return x[:,0],x[:,1]
class PatchEmbedding(nn.Module):
def __init__(self,image_size=224, patch_size=16, in_channels=3, embed_dim=768 ,dropout=0.):
super().__init__()
n_patches = (image_size//patch_size) * (image_size//patch_size)
self.patch_embedding = nn.Conv2d(in_channels = in_channels,
out_channels= embed_dim,
kernel_size=patch_size,
stride=patch_size)
self.dropout = nn.Dropout(dropout)
self.embed_dim =embed_dim
# TODO: add cls token
self.class_token = nn.Parameter(nn.init.constant_(
torch.zeros(1,1,embed_dim,
dtype=torch.float32),1.0))
# TODO: add distill embedding
self.distill_token = nn.Parameter(nn.init.trunc_normal_(
torch.zeros(1,1,embed_dim,
dtype=torch.float32),std=.02))
# TODO: add position embedding
self.position_embedding = nn.Parameter(nn.init.trunc_normal_(torch.randn(1,n_patches+2,embed_dim,dtype=torch.float32),std=.02))
def forward(self,x):
# 定义并不知道batch_size是多少,我们cls_token是对样本进行分类
class_tokens =self.class_token.expand((x.shape[0], -1, -1)) #for batch
distill_tokens =self.distill_token.expand((x.shape[0], -1, -1)) #for batch
# x: [N, C, H, W]
x = self.patch_embedding(x) # x: [n, embed_dim, h', w']
x = x.flatten(2) #[n, embed_dim, h'*w']
x = x.permute(0, 2, 1) #[n, h'*w', embed_dim]
x = torch.concat([class_tokens, distill_tokens, x], axis=1)
# print('embeding中:',x.shape)
x = x + self.position_embedding
# x = self.dropout(x)
return x
class DeiT(nn.Module):
def __init__(self,
image_size=224,
patch_size=16,
in_channels=3,
num_classes=1000,
embed_dim=768,
depth=3,
num_heads=8,
mlp_ratip=4,
qkv_bias=True,
dropout=0.,
attention_drop=0.,
droppath=0.):
super().__init__()
self.patch_embedding = PatchEmbedding(224, 16, 3, 768)
self.encoder = Encoder(embed_dim,depth)
self.head = nn.Linear(embed_dim,num_classes)
self.head_distill = nn.Linear(embed_dim,num_classes)
def forward(self,x):
# x:[N, C, H, W]
x = self.patch_embedding(x) # [N, embed_dim, h', w']
x,x_distill = self.encoder(x) # [N, num_patches,embed_dim]
# print(x.shape)
x = self.head(x)
x_distill = self.head_distill(x_distill)
if self.training:
return x, x_distill
else:
return (x + x_distill)/2
def main():
model = DeiT()
print(model)
summary(model,input_size=(4,3, 224, 224))
if __name__ == '__main__':
main()
模型结构输出如下:
DeiT(
(patch_embedding): PatchEmbedding(
(patch_embedding): Conv2d(3, 768, kernel_size=(16, 16), stride=(16, 16))
(dropout): Dropout(p=0.0, inplace=False)
)
(encoder): Encoder(
(layers): ModuleList(
(0): EncoderLayer(
(attn_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=False)
(softmax): Softmax(dim=-1)
(proj): Linear(in_features=768, out_features=768, bias=True)
)
(mlp_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(act): GELU(approximate=none)
(dropout): Dropout(p=0.0, inplace=False)
)
)
(1): EncoderLayer(
(attn_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=False)
(softmax): Softmax(dim=-1)
(proj): Linear(in_features=768, out_features=768, bias=True)
)
(mlp_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(act): GELU(approximate=none)
(dropout): Dropout(p=0.0, inplace=False)
)
)
(2): EncoderLayer(
(attn_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=False)
(softmax): Softmax(dim=-1)
(proj): Linear(in_features=768, out_features=768, bias=True)
)
(mlp_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(act): GELU(approximate=none)
(dropout): Dropout(p=0.0, inplace=False)
)
)
)
(norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(head): Linear(in_features=768, out_features=1000, bias=True)
(head_distill): Linear(in_features=768, out_features=1000, bias=True)
)
模型其中每层输出以及参数量如下:
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
DeiT [4, 1000] --
├─PatchEmbedding: 1-1 [4, 198, 768] 153,600
│ └─Conv2d: 2-1 [4, 768, 14, 14] 590,592
├─Encoder: 1-2 [4, 768] --
│ └─ModuleList: 2-2 -- --
│ │ └─EncoderLayer: 3-1 [4, 198, 768] 7,085,568
│ │ └─EncoderLayer: 3-2 [4, 198, 768] 7,085,568
│ │ └─EncoderLayer: 3-3 [4, 198, 768] 7,085,568
│ └─LayerNorm: 2-3 [4, 198, 768] 1,536
├─Linear: 1-3 [4, 1000] 769,000
├─Linear: 1-4 [4, 1000] 769,000
==========================================================================================
Total params: 23,540,432
Trainable params: 23,540,432
Non-trainable params: 0
Total mult-adds (M): 554.21
==========================================================================================
Input size (MB): 2.41
Forward/backward pass size (MB): 170.33
Params size (MB): 93.55
Estimated Total Size (MB): 266.28
=========================================================================================