【目标检测】YOLOv3手动实现Pytorch代码全流程详解 RCNN、YOLO系列
目录:
-
- 目标检测概述
- RCNN系列
-
- R-CNN
- Fast R-CNN
- Faster R-CNN
- YOLO系列
-
- YOLOv1
- SSD
- YOLOv2 / YOLO9000
- YOLOv3
- YOLOv3 实现详解
-
- anchor
- 网络
- 标签
- 损失
- 预测
- 闲言
目标检测概述
之前的MTCNN实现了单类多目标的高效检测,而现实中更普遍的任务是多类多目标检测。
目标检测可划分为3个发展阶段:
- 传统的目标检测
区域选择:滑动窗口
特征提取:Harr、SIFT、HOG等特征提取算法
分类器:如常用的SVM模型
基于滑动窗口的区域选择策略没有针对性,时间复杂度高,窗口冗余;
手工设计特征费时费力,且对于多样性的变化没有很好的鲁棒性。 - 基于Region Proposal的深度学习目标检测算法
使用 region proposal+CNN 代替传统目标检测使用的 滑动窗口+手工设计特征
region proposal利用图像中的纹理、边缘、颜色等信息预先找出图中目标可能出现的位置,获取的候选窗口要比滑动窗口的质量更高, 可以在选取较少窗口(几千个甚至几百个)的情况下保持较高的召回率。以RCNN系列为代表。 - 基于回归方法的端到端的深度学习目标检测算法
端到端(End-to-End)的目标检测方法,不需要将检测过程分为两步(two-stage), 用region proposal来选择区域,而是把目标检测问题,当作回归问题,一步(one-stage)直接完成分类和定位。
以YOLO系列为代表,一张图只需看一次,这也是YOLO(You Only Look Once)名字的由来。
RCNN系列
R-CNN
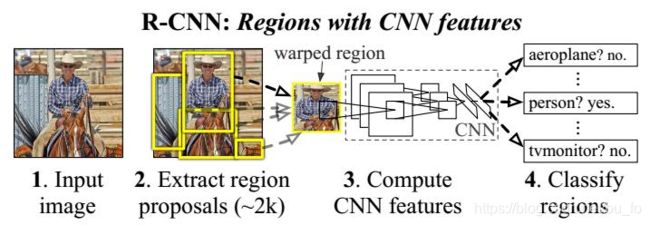
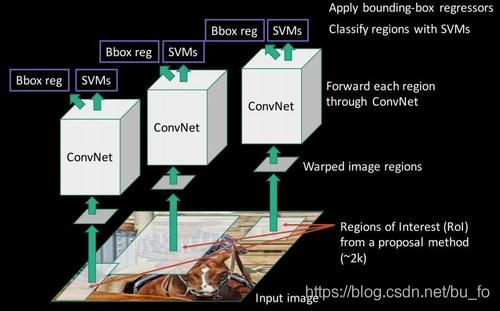
流程:
- 输入图像,使用选择性搜索算法(selective search)评估相邻图像之间的相似度,把相似度高的进行合并,对合并后的区块打分,选出2000个左右的region proposal(建议框),并把所有 region proposal 裁剪/缩放成固定大小。
- 将归一化后的region proposal 输入CNN网络,提取特征。
- 对于提取到的CNN特征,用SVM分类来做识别,用线性回归来微调边框位置与大小,其中每个类别单独训练一个边框回归(bounding-box regression)器。
不足:
- 2000个左右的候选框都需要进行卷积操作,计算量依然很大,其中有不少是重复计算。
- 训练分为多个阶段,步骤繁琐:region proposal、CNN特征提取、SVM分类、边框回归。
- 训练耗时,占用磁盘空间大:卷积出来的特征数据还需要单独保存。
Fast R-CNN



流程:
- 利用selective search 算法在图像中从上到下提取2000个左右的Region Proposal。
- 将整张图片输入CNN,进行特征提取。
- 把建议框映射到CNN的最后一层卷积feature map上。
- 通过RoI pooling层(类似SPP精简版)使每个建议窗口生成固定尺寸的feature map。
- 使用Multi-task Loss(多任务损失函数)对Softmax Loss(分类概率) 和Smooth L1 Loss(边框回归)联合训练。
SPP-net
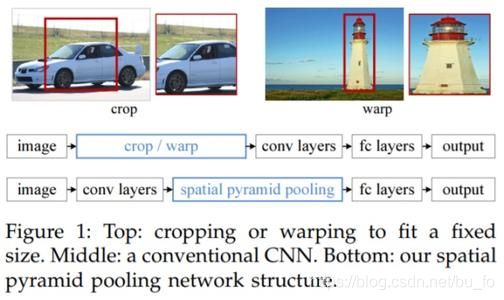
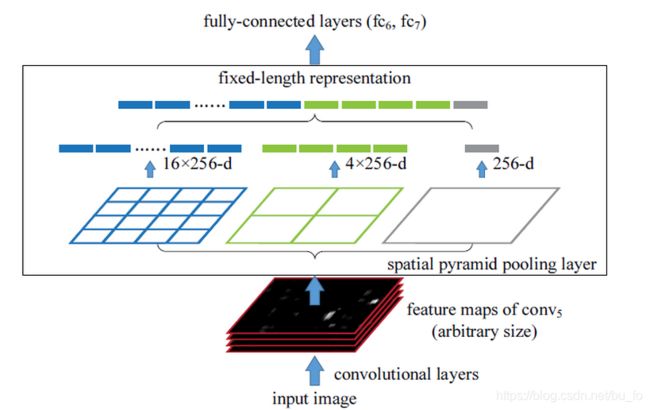
R-CNN 之所以要将建议框crop / warp成固定尺寸,是因为网络最后是全连接层。 空间金字塔池化层(Spatial Pyramid Pooling,SPP)使用多尺度池化,然后将结果拼接。可以在不限制输入大小的情况下,固定输出尺寸,有效避免了R-CNN算法对图像区域剪裁、缩放操作导致的图像物体剪裁不全以及形状扭曲等问题。
输入图片的某个位置的特征反映在特征图上也是在相同位置。基于这一事实,对某个RoI区域的特征提取只需要在特征图上的相应位置提取即可。SPP-net 最重要的改进在于,对原图只做一次特征提取,而不是对所有region proposal都做卷积,解决了重复特征提取的问题,极大地提高了检测速度。
Faster R-CNN

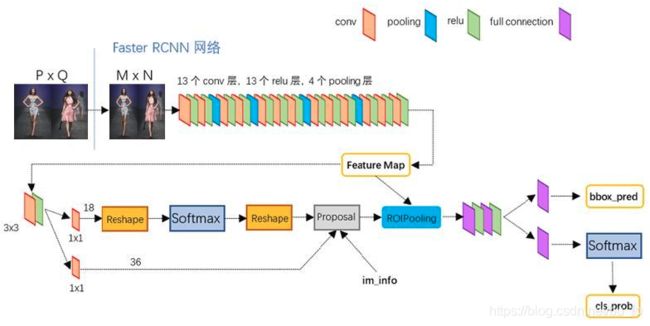
流程:
- 将整张图片输入CNN,进行特征提取。
- RPN层,用于生成候选框,并利用softmax判断候选框是前景还是背景,从中选取前景候选框(因为物体一般在前景中),并利用bounding box regression调整候选框的位置,从而得到特征子图(proposals)。
- RoI pooling层 生成固定尺寸的feature map
- 通过全连接层判断proposal的类别,同时再次对bounding box进行regression从而得到精确位置。
selective search 算法是非常耗时的,Faster R-CNN最大的贡献就是RPN(Region Proposal Networks)网络,创造性地采用卷积网络自行产生建议框,并且和目标检测网络共享卷积网络,使得建议框数目从原有的约2000个减少为300个,且建议框的质量也有本质的提高.。
RPN具体步骤:
- 生成锚框 anchors
经过RPN层的3x3卷积后每个feature map上的一个点,生成9个anchor(3种尺寸×3种比例)。anchor分为前景和背景两类(先不管物体类别,只用区分它是前景还是背景即可)。anchor有[x,y,w,h]四个坐标偏移量,x,y表示中心点坐标,w和h表示宽度和高度。 - 判断选区是前景还是背景
输出分为两部分,一部分在1x1卷积后,reshape成一维向量,经过softmax来判断anchors是前景还是背景,由于感兴趣的物体位于前景中,大量背景anchors将被舍弃。 - 确定建议框位置
另一部分经1x1卷积后用来确定建议框的位置,也就是回归anchors的 [x,y,w,h] 坐标值。 - 输出特征子图 proposal
对anchors做非极大值抑制(NMS)等筛选处理,至此得到最终的proposals,即物体的粗糙定位。 - RoI pooling层 生成固定尺寸的feature map。
- 通过全连接层和softmax得到分类概率,并对建议框做最后回归调整。
Faster R-CNN用resNet101模型作为卷积层,在voc2012数据集上可以达到83.8%的准确率,超过YOLO SSD和YOLOv2。 其最大的问题是速度偏慢,每秒只能处理5帧,达不到实时性要求。

YOLO系列
YOLOv1
针对于two-stage目标检测算法普遍存在的运算速度慢的缺点,YOLO创造性的提出了one-stage端到端算法,将目标检测重新定义为单个回归问题,也就是将物体分类和物体定位在一个步骤中完成,直接在输出层回归bounding box的位置坐标和所属类别概率。通过这种方式,YOLO可实现45帧每秒的检测速度,完全能满足实时性要求。
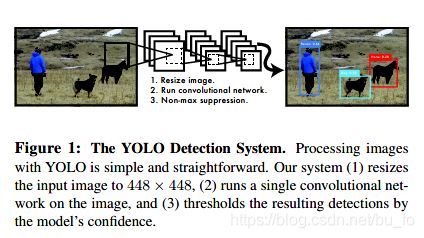
YOLO的使用流程非常简洁:
- resize图片大小至448×448
- 传入单个卷积网络
- 根据模型置信度做非极大值抑制

实现原理:
将输入图像划分成 S ∗ S S * S S∗S个网格,如果一个物体的中心点落入一个grid cell(单元格)内,那么这个grid cell就负责检测这个物体。每一个grid cell预测 B B B个bounding boxes,以及这些bounding boxes的分数。这个分数反映了模型预测这个grid cell是否含有物体,以及是这个物体的可能性是多少。
定义 c o n f i d e n c e = P r ( O b j e c t ) ∗ I O U p r e d t r u t h confidence=Pr(Object)*IOU^{truth}_{pred} confidence=Pr(Object)∗IOUpredtruth ,如果这个 cell 中不存在物体,则得分为0 ;否则的话,分数为 predicted box(预测框)与ground truth(真实框)之间的 IoU(交并比)。
每个 bounding box 由五个预测值组成:x,y,w,h,confidence。坐标(x,y)代表了 bounding box 的中心点相对于 grid cell 边界的值,(w,h) 则是 bounding box 的宽和高相对于整幅图像的值,confidence 就是 IoU 值。
在测试阶段,把每个栅格的条件类别概率乘上每个 bounding box 的 confidence,这样既包含了 bounding box 包含物体的类别信息,也包含了预测框和真实框的符合程度。
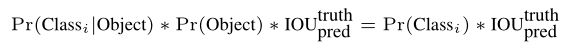
图片划分为 S × S S×S S×S个grid , 每个grid cell预测 B B B个bounding boxes,类别数为 C C C。预测值是一个 S × S × ( B ∗ 5 + C ) S×S×(B*5+C) S×S×(B∗5+C)的张量。在论文中,使用 PASCAL VOC 数据集, S = 7 , B = 2 , C = 20 S=7,B=2,C=20 S=7,B=2,C=20, 最终预测值为 7 × 7 × 30 7×7×30 7×7×30的张量。
网络模型

YOLO检测网络结构借鉴了GoogLeNet ,用1x1+3x3卷积层简单代替 inception 模块,包括24个卷积层和2个全连接层。
特点:
- 使用 224 ∗ 224 224*224 224∗224的图像预训练分类样本,再改为 448 ∗ 448 448*448 448∗448训练检测样本。
- 激活函数由ReLU改为PReLU。
- 输出层为全连接层,因此在检测时要求输入图像尺寸和训练图像相同。
损失函数
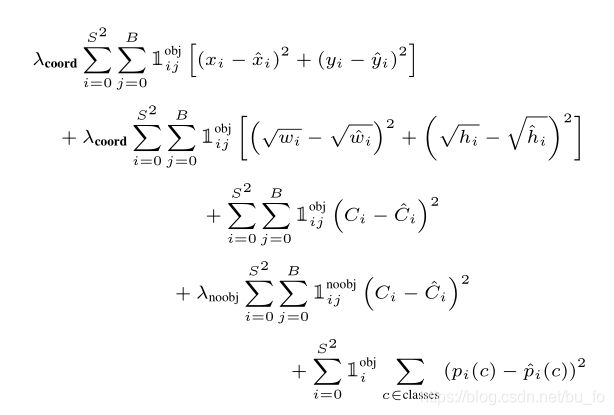
- 第1行:bounding box 中心点坐标 ( x , y ) (x, y) (x,y)损失
- 第2行:bounding box 宽高 ( w , h ) (w, h) (w,h)损失
相同值的宽高误差对不同大小的目标影响是不一样的,比如同样是宽度相差2个像素,对小目标的预测影响很大,对大目标则无足轻重,因此加根号的目的是拉开这种差距,使得同样的误差对大目标的损失更小,对小目标的损失更大。 - 第3、4行:bounding box 的置信度损失
分为包含物体和不包含物体两部分,包含物体的置信度只在每个grid cell的两个bounding boxes中选择IoU大的计算,因此每个grid cell只能预测一个物体,这是YOLOv1的一个缺陷。 - 第5行:分类损失
只有在grid cell包含物体的时候才计算。

YOLO最大的特点就是速度快,处理速度达到45fps,fast版本(网络较小)甚至可以达到155fps。
不足之处有以下几点:
- 一张图片最多只能检测 7 ∗ 7 = 49 7*7=49 7∗7=49个物体。
- 每个grid cell只有两个bounding boxes,只对应一个类别,容易漏检,相比较Faster R-CNN虽然降低了背景误检率,但召回率低。
- 对小目标和聚集目标效果差。


SSD
SSD(Single Shot MultiBox Detector)针对YOLOv1对宽高不常见物体和小目标物体侦测效果差的缺陷做了改进。

SSD去掉了网络最后的全连接层,其认为目标检测中的物体,只与周围信息相关,它的感受野是局部的,故没必要也不应该做全连接。
SSD最大的特点是:多尺度检测。对多个卷积层,提取不同大小感受野的feature map,在这些多尺度的feature map上,进行目标位置和类别的训练和预测。显然,越浅层的feature map感受野越小,越利于检测小物体。
和Faster R-CNN相似,SSD也提出了anchor(锚框)的概念。feature map 的每个点对应为原图的一个区域的中心点,以这个点为中心,构造出6个宽高比例不同,大小不同的anchor, 每个anchor对应4个位置参数 ( x , y , w , h ) (x,y,w,h) (x,y,w,h)和21个类别概率(VOC训练集20个类别,加上anchor是否为背景,共21类)。

通过多尺度多 anchor 的方法,SSD显著提升了YOLOv1的检测精度。
YOLOv2 / YOLO9000
YOLOv1与Fast R-CNN的误差比较分析表明,YOLOv1 产生了大量的定位错误。此外,与生成候选区域方法相比,YOLOv1召回率相对较低。 因此,YOLOv2主要关注改善召回率和定位,同时保持分类准确性。

YOLOv1到YOLOv2的进化之路中尝试了各项改进,我们看一下最重要的几点:
批标准化(batch normalization)
批标准化可以显着改善收敛性,避免过拟合,而且不再需要dropout和其他形式的正则化。
全卷积网络
和SSD一样,YOLOv2移除了全连接层,另外消除一个池化层,使网络卷积层的输出具有更高的分辨率,将网络输入图像分辨率由448×448改为416X416,这样做是为了让特征图尺寸为奇数,只有一个中心点。目标,尤其是大的目标,往往占据图像的中心,所以最好在正中心拥有单独一个位置来预测这些目标,而不是在中心附近的四个位置。如此,通过32倍的下采样,416X416的图像最终得到13×13的特征图。
使用锚框anchor
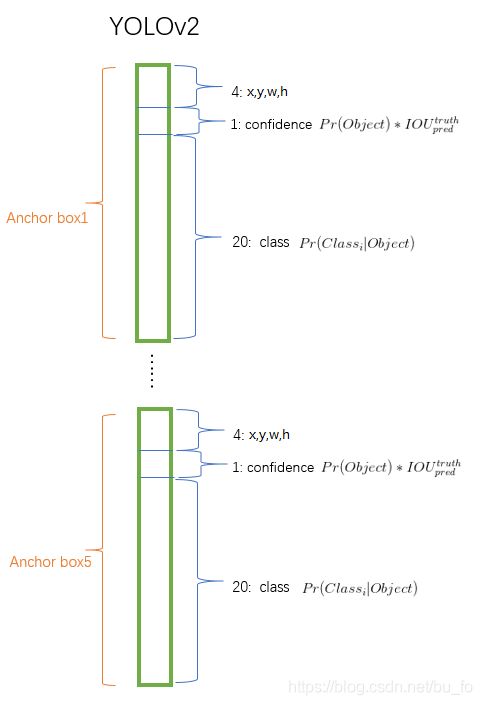
引入anchor后,我们将类别预测与坐标回归分开处理,单独预测每个anchor的类及其目标。对比YOLOv1,现在每个grid cell可以预测多个类别的物体,一个anchor可以预测一个物体。YOLOv1仅为每个图片预测98个框,使用anchor后,模型预测的框数超过一千个,虽然精度会小幅下降,但召回率显著提升。
聚类获得anchor尺寸
anchor的尺寸是手工挑选的,虽然网络可以通过学习适当地调整方框,但是如果从一开始就为网络选择更好的prior(先验),就可以让网络更容易学习。
YOLOv2不手工选择先验,而是对训练集的边框使用k-means聚类算法,自动找到良好的prior。如果在算法中使用欧氏距离进行聚类,大框比小框的误差会更大,我们重视的是同一类框的IoU值,因此定义距离为:
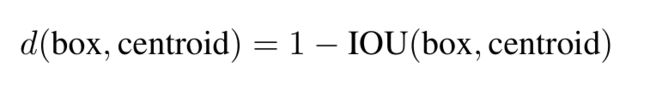

用不同的k值运行k-means,并绘制样本框和聚类中心的平均IoU。权衡模型复杂度和召回率,选择 k = 5 k = 5 k=5。聚类的中心与手工选取的anchor显著不同,它有更少的短宽框,更多的长窄框。5个聚类anchor的性能类似于9个手工选取anchor。
位置预测
按照Faster RCNN的anchor方法,在训练的早期阶段,预测bounding box的中心点没有约束,可能出现在任何位置,位置预测容易不稳定,因此YOLOv2调整了预测公式。
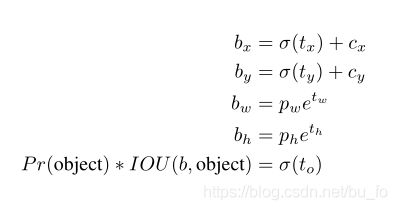
b x , b y , b w , b h b_x,b_y,b_w,b_h bx,by,bw,bh为bounding box的中心点和宽高;
σ \sigma σ为sigmoid函数;
c x , c y c_x,c_y cx,cy为grid cell大小归一化后,当前grid cell相对图像左上角的坐标;
p w , p h p_w,p_h pw,ph为anchor的宽高;
t x , t y , t w , t h , t o t_x,t_y,t_w,t_h,t_o tx,ty,tw,th,to是要学习的参数,分别用于预测bounding box的中心点、宽高、置信度。
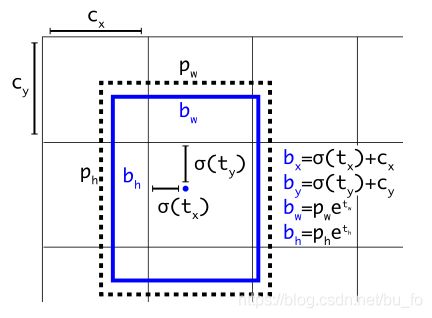
通过sigmoid函数, t x , t y t_x,t_y tx,ty被约束在 ( 0 , 1 ) (0,1) (0,1),即当前grid cell内。如此参数更容易学习,网络更稳定。

相较YOLOv1计算loss时使用 w , h \sqrt w,\sqrt h w,h来平衡大小框的损失,YOLOv2选择用自然对数函数 ln \ln ln压缩宽高对anchor的偏移量,对照两个函数图像, ln \ln ln函数的值域在 ( − ∞ , + ∞ ) (-\infty,+\infty) (−∞,+∞),更符合网络输出,而且宽高偏移量的值在1左右,对应的梯度稳定,利于网络学习。
网络模型

为了进一步提升速度,YOLOv2提出了Darknet-19模型,包含19个卷积层和5个最大池化层,最后使用全局平均池化来进行预测。
识别更多类别
YOLOv2联合训练ImageNet数据集和COCO数据集,其中混合了分类和检测两种数据,当学习分类样本时,只计算分类损失,学习检测样本时,才同时计算位置损失。这是一种开创性的训练方法,拓展了网络检测能力,使其学会检测一些没有检测样本的对象。由此,训练出了可以识别9000个类的YOLO9000。

YOLOv3
虽然YOLO之父Joseph Redmon在YOLOv3论文引言中说,他之前一年啥也没干,主要刷Twitter… 但丝毫不影响YOLOv3成为当时目标检测算法的集大成者。
使用sigmoid分类器
作者发现Softmax对于提升网络性能没什么作用,YOLOv3选择使用单独的Logistic分类器,在训练中用binary cross-entropy loss(二元交叉熵损失)来预测类别。
因为Softmax总和为1的排他性,强加了一个假设:每个框有且只有一个类别。对于有嵌套关系标签的复杂数据集(如“人”和“女人”),这种假设是不妥的,相比之下,多标签的分类方法能更好地模拟数据。
跨尺度预测
为了更好地检测小目标,YOLOv2曾使用passthrough层来获得细粒度特征(感受野更小), 而YOLOv3选择在3个不同尺度进行预测,网络分别为每种尺寸各预测了3个边界框,对于COCO数据集,每种尺寸最终得到的张量为 N × N × [ 3 × ( 4 + 1 + 80 ) ] N ×N ×[3 \times (4+ 1+ 80)] N×N×[3×(4+1+80)]:4个边框偏移量、1个目标置信度、80个类别。
从浅层网络提取特征图,上采样之后,在element-wise(像素级别)将高低两种分辨率的特征图拼接到一起,由此得到早期特征映射中的细粒度特征,并获得更丰富的语义信息。

YOLOv3依然使用K-Means聚类方法来得到anchor的尺寸,在COCO数据集上选择了9个聚类和3个尺寸。特征图下采样次数越少,尺寸越大,感受野越小,用来检测越小的物体。
新的网络
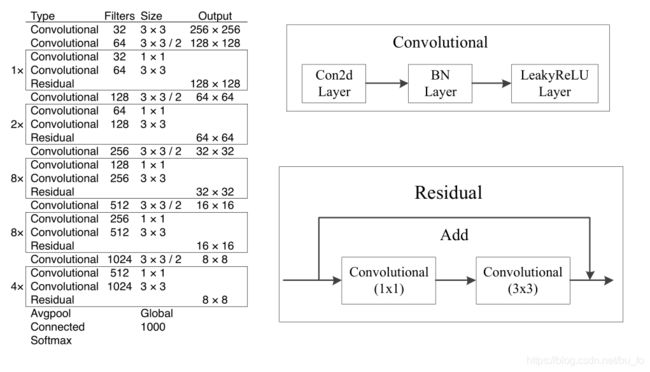
YOLOv3提出新的网络模型:Darknet-53。在Darknet-19基础上借鉴了residual(残差)网络,添加了shortcut connection(捷径连接),共有53个卷积层。这个新网络在性能上远超Darknet-19 ,但是在效率上同样优于ResNet-101和ResNet-152。
YOLOv3 实现详解
anchor
在进入实现流程之前,不得不先开启一个番外篇。你说不就anchor嘛,看好多遍早明白了。不!你没有!!好叭对不起,是我没有……让我们不厌其烦(手动微笑)地再来撸一撸:
bounding box?anchor box??
这两个概念在一些不严谨的说法里容易混淆。Bounding box是完整的边框信息,包括中心坐标、宽高、置信度以及类别;而anchor box是一个物体形状的先验,只包含宽高。
搞个anchor出来有啥用??
按照吴恩达的课程,anchor是为了在一个grid cell中预测多个物体。
我的脑回路
:为啥YOLOv1选择一个类别对应两组坐标?一个类别对应一组坐标,再来一个类别对应一组坐标,不就能预测两个物体了嘛?
:哦……这样的两组预测好像没法对应物体。做标签的时候可以指定哪组标签表示哪个物体,可是预测的时候网络只会输出最有可能的两组值,这两组值基本上只会是预测同一个物体的相似值,起不到预测多个物体的效果。
:emmm 我想起来了,好像在做单类单目标检测的时候遇到过类似的问题,如果单纯地将一幅图片上的目标改成两个,标注两个目标进行训练,预测的时候两个框只会出现在同一个目标上,置信度较低的目标是框不到的。
so,anchor的意义就是告诉这两组预测,你俩分别负责找什么形状的物体。比如1号bounding box找高瘦的目标,2号bounding box找矮胖的目标。在训练的时候用anchor和ground truth的IoU作为置信度来筛选正负样本,将物体交给大小形状相近的anchor所对应的那组值来学习,这样在预测时,两个bounding box就有了倾向,不会只框到同一个物体。
那么,anchor的尺寸怎么给呢?这是一种先验,表示我们一开始就告诉模型物体更有可能是哪些大小形状的。这个尺寸如果给的不好,不同的物体就没法区分,自然会影响训练效果。比如,我给了高瘦和矮胖两个尺寸较小的anchor,而实际物体的ground truth都是接近正方形的或者尺寸很大的,这就不好办了,它和两个anchor的IoU都不大,不知道该交给哪个来学习,起不到对应的效果。我们手动设计的anchor先验尺寸并不准确,因此才需要K-means聚类算法。
anchor思想在代码中的实现并不复杂,但很少有人解释为什么这么做。那不管了,暂时按我说的为主!有不服的……请快来教教我!
好了,番外篇完结,进入正题~
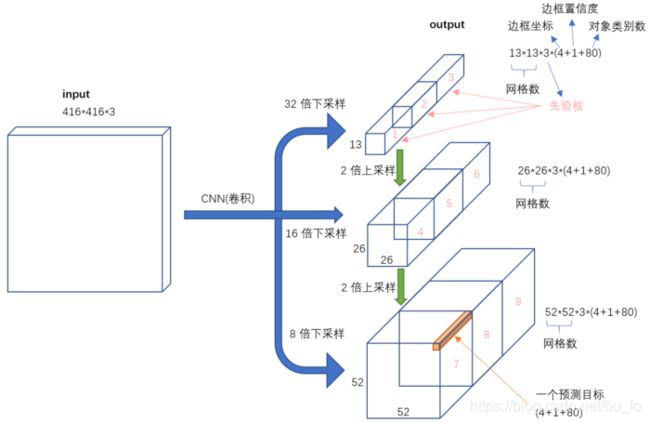
网络
YOLOv3网络模型的主干部分是Darknet-53,输入图像经过Darknet-53得到52×52、26×26、13×13三种尺寸的特征图,网络具体参数如下:
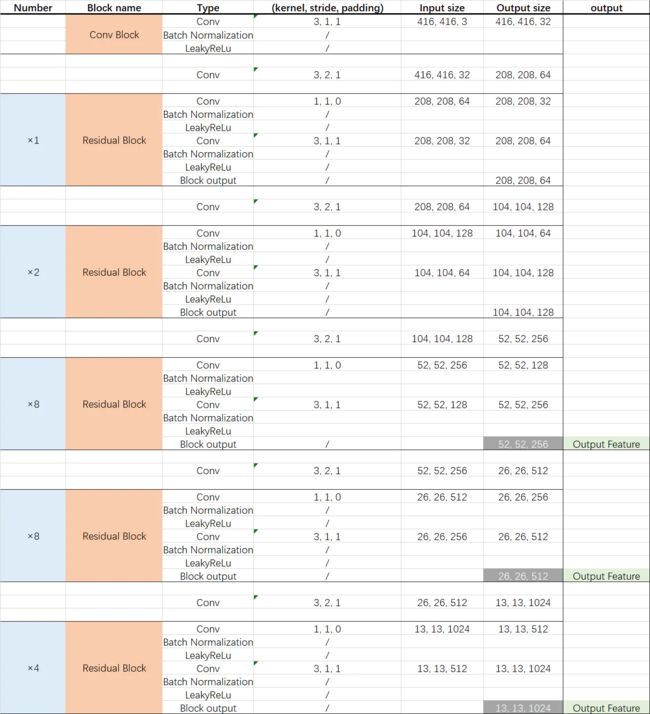
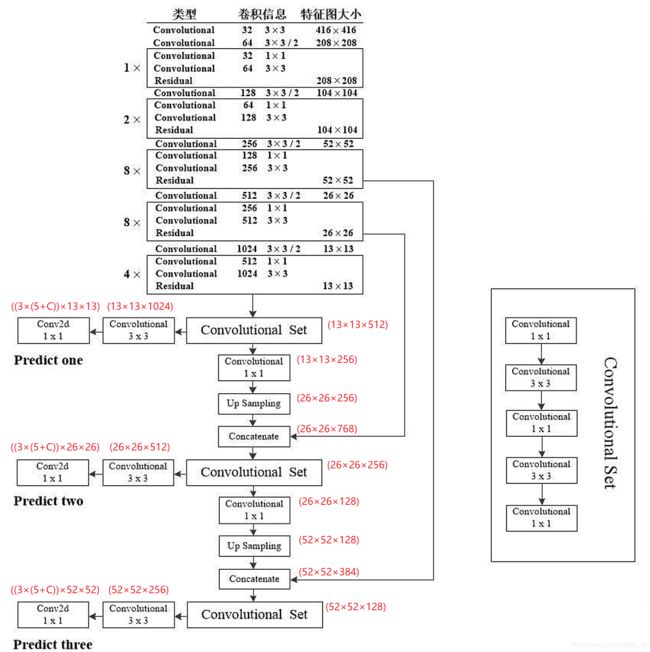
通过route(特征在通道维度拼接)操作,融合了不同层次的特征,从而提高预测精度。以26×26的特征图为例,concatenate(拼接)操作融合了浅层网络的512维特征(偏局部)和由上采样得到的256维特征(偏全局),为了预测小物体,显然以局部特征为主。52×52的特征图同理。
网络输出为:
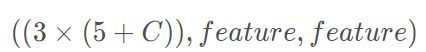
其中 3 3 3表示每个尺寸的特征图预测3个anchor, 5 5 5表示4个坐标偏移量+置信度,C为类别数。
以COCO数据集80分类为例,网络输出如下:
标签
生成的训练标签应该和网络输出相对应,分别有13×13、26×26、52×52三组。
思路是这样的:首先生成 ( 13 , 13 , 3 , 5 + C ) , ( 26 , 26 , 3 , 5 + C ) , ( 52 , 52 , 3 , 5 + C ) (13,13,3,5+C),(26,26,3,5+C),(52,52,3,5+C) (13,13,3,5+C),(26,26,3,5+C),(52,52,3,5+C)三个零矩阵,其中 3 3 3表示每种尺寸特征图的每个grid cell有3个anchor, 5 + C 5+C 5+C的含义同上。然后在有物体的grid cell计算3个anchor与对应ground truth的IoU得到置信度以及坐标偏移量,填入矩阵。没有物体的grid cell只需要训练置信度,默认为0即可。
b x , b y , b w , b h b_x,b_y,b_w,b_h bx,by,bw,bh为bounding box的中心点和宽高;
σ \sigma σ为sigmoid函数;
c x , c y c_x,c_y cx,cy为grid cell大小归一化后,当前grid cell相对图像左上角的坐标;
p w , p h p_w,p_h pw,ph为anchor的宽高;
t x , t y , t w , t h , t o t_x,t_y,t_w,t_h,t_o tx,ty,tw,th,to是要学习的参数,分别用于预测bounding box的中心点、宽高、置信度。
为了避免混淆,沿用上图预测时的参数名称进行说明。设每张样本图片有n个物体,每个物体对应标签 ( c l s , x , y , w , h ) (cls,x,y,w,h) (cls,x,y,w,h),分别表示类别、中心点坐标、宽高。
grid cell在归一化之前,代表原图的尺寸就是该特征图在网络中下采样的倍数,如13×13的特征图, 每个grid cell代表的尺寸自然是 416 ÷ 13 = 32 {416}\div{13}=32 416÷13=32,这也是网络中5次下采样的倍数总和 32 = 2 5 32=2^5 32=25。
我们先要找到有物体的grid cell的坐标 c x , c y c_x,c_y cx,cy,这里有个取巧的做法:将物体中心点坐标 ( x , y ) (x,y) (x,y)除以每个grid cell代表的尺寸,相当于给grid cell做归一化,如此可以同时得到物体所在grid cell的坐标 c x , c y c_x,c_y cx,cy和中心点偏移量 t x , t y t_x,t_y tx,ty。
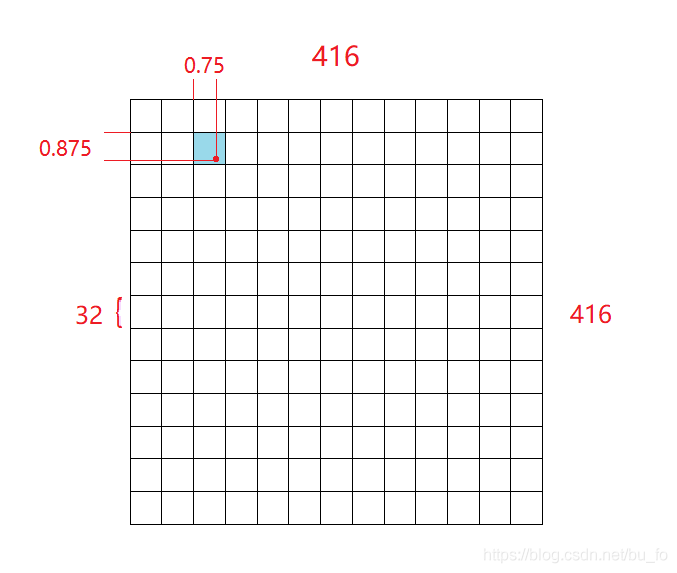
举个栗子:13×13的特征图,一个grid cell尺寸为32,现有一物体中心点坐标 ( x , y ) = ( 88 , 60 ) (x,y)=(88,60) (x,y)=(88,60),除以32后等于 ( 2.75 , 1.875 ) (2.75,1.875) (2.75,1.875),不难发现,其中整数部分 ( 2 , 1 ) (2,1) (2,1)正是物体所在grid cell的坐标 c x , c y c_x,c_y cx,cy,小数部分 ( 0.75 , 0.875 ) (0.75,0.875) (0.75,0.875)正是物体对所在grid cell左上角点的偏移量 t x , t y t_x,t_y tx,ty。
宽高偏移量比较简单, t w , t h = l o g e w p w , l o g e h p h \displaystyle t_w,t_h=log_e \frac w{p_w},log_e \frac h{p_h} tw,th=logepww,logephh。
如果当前先验边界框比之前其他的任何先验边界框更好的与 ground truth 对象重合,那它的分数就是 1。如果当前先验边界框不是最好的,但它和 ground truth 对象重合了一定的阈值以上,神经网络会忽略这个预测。我们使用的阈值是 0.5。
论文中这段话比较模糊,我参考了其他人的解释,觉得意思应该是:计算物体的真实框ground truth与3个anchor的IoU,IoU最大的anchor置信度设为1,作为正样本;IoU在阈值和最大值之间的置信度就等于IoU,但不参与训练;IoU小于阈值的置信度设为0,作为负样本。
在具体实现中,有些GitHub上的代码和原论文思路不同。有的在生成标签时将IoU最大的anchor置信度设为1,其余两个anchor置信度直接给0,有的在训练时将置信度大于阈值的anchor都作为正样本训练,这些改动似乎实现效果也还可以,有什么其他影响我尚不清楚。
我们还是先按原论文来实现,一个物体最终只会交给一个anchor负责,由此得到置信度标签 t o t_o to。最后,在创建的零矩阵中,对应坐标 c x , c y c_x,c_y cx,cy处,填入三个anchor对应的 5 + C 5+C 5+C个值,类别 C C C经过one-hot编码,因此需要 C C C个数表示。
至此,标签处理完成。你可能注意到,标签shape和网络输出还是不一样,在计算loss和预测时,通过矩阵变换就能解决,具体在损失设计中说明。
这里我在一开始有个疑惑:在做训练标签时, t w , t h t_w,t_h tw,th是用真实框ground truth宽高比上anchor宽高,再取log得到,因此在预测时符合上述公式,可是 t x , t y t_x,t_y tx,ty并未做任何处理,为什么在预测时可以直接加上sigmoid函数?
我的理解是: t x , t y t_x,t_y tx,ty的label是在 ( 0 , 1 ) (0,1) (0,1)内,可是网络学习到的值没有任何约束,很可能超出这个范围,显然超出当前grid cell的预测是不合理的。虽然我们对标签未做处理,但在训练时将网络输出 t x , t y t_x,t_y tx,ty经过sigmoid函数后与标签做损失,因sigmoid函数是增函数,在压缩的同时,不会改变值的大小关系,也就是说网络梯度更新的方向是对的,只是对值的要求变低了。比如我们希望 σ ( t x ) \sigma(t_x) σ(tx)值在 ( 0.8 , 0.9 ) (0.8,0.9) (0.8,0.9),根据sigmoid反函数算得,网络学习到的 t x t_x tx满足 ( 1.4 , 2.2 ) (1.4,2.2) (1.4,2.2)范围内即可,降低了网络学习难度。置信度 t o t_o to也是同理。
损失
根据置信度标签筛选正负样本,按照我对论文的理解,置信度为1的作为正样本,置信度为0的作为负样本,其余的不参与训练。正样本损失包含置信度、坐标、分类损失3部分,负样本置信度标签为0,只有置信度损失。
相对于anchor的总数,其中需要负责物体预测的正样本往往是远不足一半,正负样本损失求和时前面需要加上系数以均衡样本: l o s s = α l o s s p o s i t i v e + β l o s s n e g a t i v e loss=\alpha loss_{positive} + \beta loss_{negative} loss=αlosspositive+βlossnegative。最后将3种特征图的损失求和得到总损失。
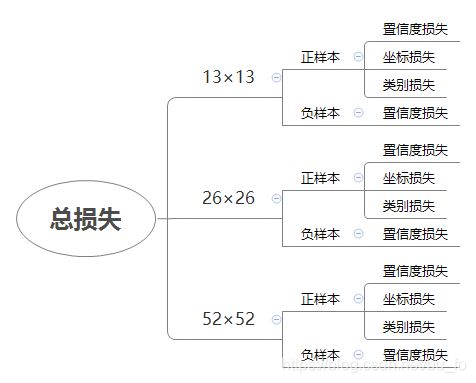
损失函数如下:
- 置信度损失:二元交叉熵损失(BCE)
- 坐标损失:均方差损失(MSE)
- 分类损失:交叉熵损失(标签无嵌套)或二元交叉熵损失(标签有嵌套)
三种损失其实都可以简单地用均方差损失函数,YOLOv2就是这么干的,但是对分类损失,使用交叉熵更合理,而且在求导时不会有MSE的梯度弥散问题。
别忘了在计算前,要将网络输出的3组值通过换轴和reshape变成和标签一致:
( ( 3 × ( 5 + C ) ) , f e a t u r e , f e a t u r e ) ((3×(5+C)),feature,feature) ((3×(5+C)),feature,feature)
− > ( f e a t u r e , f e a t u r e , ( 3 × ( 5 + C ) ) ) ->(feature,feature,(3×(5+C))) −>(feature,feature,(3×(5+C)))
− > ( f e a t u r e , f e a t u r e , 3 , 5 + C ) ->(feature,feature,3,5+C) −>(feature,feature,3,5+C)
我一开始觉得,网络输出的值本身是没有任何含义的,只要和标签对应上就行,所以输出可以直接reshape,没必要加一步换轴操作。后来经过思考和实验发现不是这样,2个feature维度是通过下采样得到的特征尺寸,不能被reshape破坏,否则下采样和特征融合就没意义了。
另外记得要将网络输出的置信度和中心点偏移加sigmoid后再做损失。
预测
流程:
- 将网络输出reshape。
- 置信度经sigmoid函数后,根据给定阈值筛选,大于阈值的作为预测目标留下。
- 根据公式反算bounding box的坐标值。
- 预测出的同一种类别的边框进行NMS(非极大值抑制)。
- 在原图上画出边框,输出预测类别。
坐标反算:
mask = torch.sigmoid(output[..., 0]) > thresh
idxs = mask.nonzero()
vecs = output[mask]
根据置信度筛选得到满足条件的特征图坐标idxs和对应向量vecs。
设共检测到n的物体。
idxs的shape为 ( n , 4 ) (n,4) (n,4),4个值为 ( N , H , W , 3 ) (N,H,W,3) (N,H,W,3),分别表示第几张图片、物体中心点所在grid cell坐标 c y , c x c_y,c_x cy,cx(注意变换)、第几个anchor。
vecs的shape为 ( n , 5 + C ) (n,5+C) (n,5+C), 5 + C 5+C 5+C含义同上。
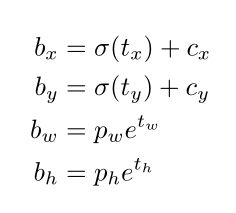
b x , b y , b w , b h b_x,b_y,b_w,b_h bx,by,bw,bh为bounding box的中心点和宽高;
σ \sigma σ为sigmoid函数;
c x , c y c_x,c_y cx,cy为当前grid cell在特征图中的坐标;
p w , p h p_w,p_h pw,ph为anchor的宽高;
t x , t y , t w , t h t_x,t_y,t_w,t_h tx,ty,tw,th为vecs中的第2到第5个值。
接下来找到每个物体对应的anchor尺寸,按照公式反算即可,只需要注意 b x , b y b_x,b_y bx,by反算时要再乘以下采样倍数还原到原图坐标,其余没有太难的地方。
闲言
YOLOv4、v5嘛,其中技巧太多,我现在理解还不透彻,就不献丑了,之后有机会再补上。
YOLOv3作者在论文最后探讨了一下YOLO的意义,对YOLO侵犯隐私和伤害生命的用途表达了抗议和愧疚,许多人选择忽视甚至翻译都跳过了。我却觉得作者的表达极客且活泼,人需要理性的技术,也需要敏感的心。
YOLO之父还是退出了CV界,双刃恒存,不予置评。
技术不会停止,关于技术的思考也不会。
文章难免有错漏之处,敬请指正。