3.一脚踹进ViT——ViT总结完善
3.ViT
前两节搭建了ViT结构框架,对Encoder中最重要的MSA部分进行构建,同时还介绍了Transformer用在视觉上与NLP不同的地方,对patch embedding也进行了介绍,首先对前两节进行一个简单回顾,再对class token和position embedding进行完善。
1.WQ WK WV 矩阵

我们定义了一个qkv,实质上是一个Linear层,输入是所有的image tokens/ patch embedding,维度是num_patches,channel数是embed_dim,all_head_dim*3中all_head_dim的头加起来,比如有8个head,all_head_dim就是8乘以embed_dim,即单个QKV的列的个数,即图中不同颜色的各部分,最后乘以3就是QKV三部分。
self.qkv = nn.Linear(embed_dim,self.all_head_dim*3)
2.Encoder结构
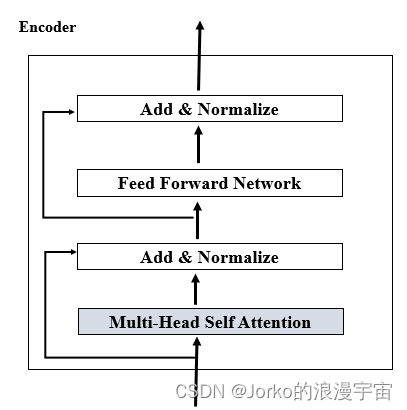
编码器的输入已经经过了Patch Embedding,输入维度就是(B,num_patches, embed_dim),MSA并不会改变输出,仍然和输入一样(B,N,D),Add&Normalize仍然不改变维度,Feed Forward Network仍然是MLP层,在其中设置了mlp_ratio,将输入维度变大,最后再恢复,其中也不改变其大小。同样之后的Add&Normalize也不会改变尺寸,所以Encoder 是不会改变输入尺寸,虽然里面会有操作将它变大再恢复回去,总之最后输出与输入维度一样,需要注意,其中的Normalize是Layer Normaliztion,那和常用的BN有什么不一样呢?
3.Layer Normaliztion

BN和LN都是对每一个Batch去做,若Batch=4,即每次仍入4张图去做,假设形状都是[N,C,H,W]
BN公式如下
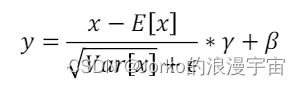
若表示离散情况,减去均值,除以方差,有两个可学习的参数γ和β,最主要就是求均值和方差,到底它减去谁,除以谁呢?这就是BN和LN最大的差别。
看最开始的图,如果是BN,我们按照阴影部分去求,每一个channel去求一个mean,一个var;
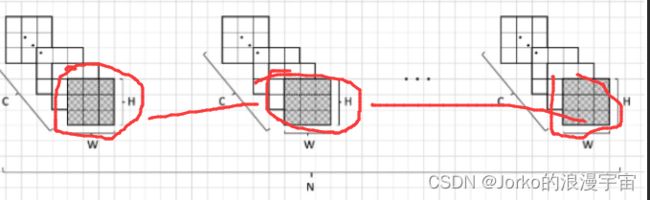
形象理解:可以把每个batch比作N本书,每一本有C页,每页又有H行和W列的文字,BN做的是把每本书的第一页抽出来,对所有的文字取出来求一个均值去做归一化,再去把每本书第二页抽出来去做……;
而LN则是对N本书,我们取第一本书的每一页所有文字加起来求个平均,求个归一化,然后再对下一本书去做。
那为什么Transformer中要用LN而不用BN呢?
我们在做BN的时候对每一个channel,负责学习的是固定的feature,每一个维度关注某一个特定的特征表示,比如在图像中,某一个channel被学习的时候可能关注的图像的纹理/颜色,通常训练图像的话N很大,若N很大的话可以更好的刻画整个数据的分布,若N很小或者为1的话,做BN则意义不大。
而在Transformer/Seq2Seq中,我们Batch_size可能不会很大,数据也不一定固定长度,在翻译句子中,可能同一个句子中很多词会有较强的联系,而不同的句子中关系不是很紧密,所以我们会用LN,而实际过程中在Transformer中LN比BN效果好
4.LN层所用的位置

左图中模型先做MSA,再做LN,在做MLP,最后再做一次LN。而右侧叫PreNorm是更新的方法,它会先做LN,再去做MSA,再做LN,最后走MLP。
实验结果表明,实验PreNorm训练模型,十次会有七八次正常收敛,而PostNorm很多情况模型效果不好;而PostNorm里成功的训练效果比PreNorm要好,同样也有论文提出了新的Normalization方式,论文如下:
-
Liu L, Liu X, Gao J, et al. Understanding the difficulty of training transformers[J]. arXiv preprint arXiv:2004.08249, 2020.
-
Xiong, Ruibin, et al. "On layer normalization in the transformer architecture."International Conference on Machine Learning. PMLR, 2020.
而一般常用的还是PreNorm的方式。
5.Class Token

之前我们的数据经过Encoder层,我们用AvgPooling1D,将数据的embed_dim直接求了平均,最后进行了分类
那我们有没有别的方法呢?
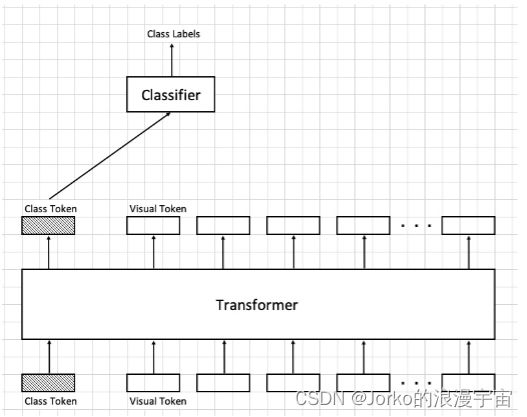
我们有一种更接近NLP的方法来做这个,可以加入一个Class Token来做,我们单个Vision Token都去注意同一个序列中其他的token的信息,将有用的信息提取出来表示自己,我们人为添加一个class token,维度和其他 vision token一样,它的任务是去学习分类,它需要去看整个序列中的信息,提取出和目标图像分类相关的信息作为自己的feature,即class Token可以看到其他所有Vision Token中的信息,来帮助Classfier进行分类。
但是实际过程中,它与AvgPooling1D 效果差不多,还增加了计算量
6.Position Encoding
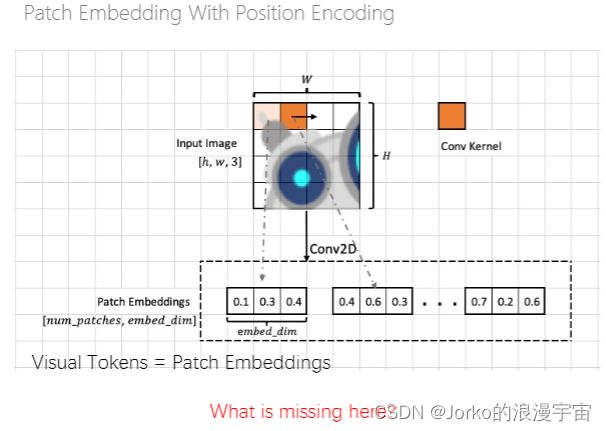
我们最终得到了Patch Embedding,但丢失了什么呢?
我们在扫描过程中是不是缺失了表达不同向量之间位置信息的参数,可能并不知道第一个和最后一个的具体的位置/相对的位置在哪,在ViT中加入了位置编码

那怎么去给他加入位置信息呢?
最简单的就是对Token直接编码(给它0,1,2,3……N),但这样效果是不好的
但推荐的是需要学习的一个嵌入,我们也不知道它要填写多少,而让他自己去学应该是多少
那怎么将Visual Token和Pos_Embed进行结合呢?
一般做法就是直接将它们相加就好了,因为他们的维度是一样的,也可以concat连接起来,但是ViT测试过后的结论是:用比不用效果好,这两种差别不大,所以肯定用计算量小的加法呀!
所以ViT的流程就串起来了。
7.ViT论文复现
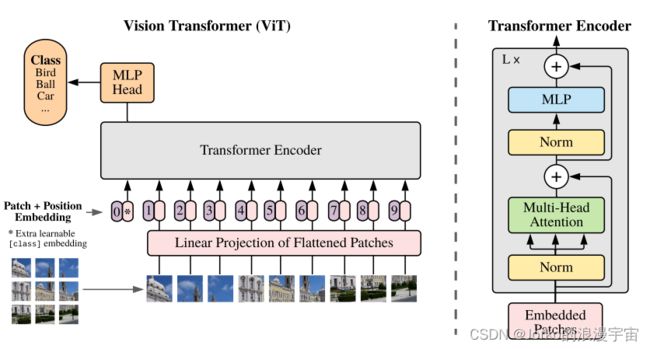
7.1 框架搭建
和先前一样,我们先对ViT的框架先进行搭建,再去填充内容,它由三部分组成,Patch_embedding,Encoder,classifier。
图像输入网络中被打成patch块后,进行线性投射,再加入类别嵌入和类编码,再经过多层的Encoder,最后经过MLP头,最终得到分类结果
import torch
import torch.nn as nn
class VisionTransformer(nn.Module):
def __init__(self,
image_size=224,
patch_size=16,
in_channels=3,
num_classes=1000,
embed_dim=768,
depth=3,
num_heads=8,
mlp_ratip=4,
qkv_bias=True,
dropout=0.,
attention_drop=0.,
droppath=0.):
super().__init__()
self.patch_embedding = PatchEmbedding(image_size,)
self.encoder = Encoder(embed_dim,depth)
self.classifier = nn.Linear(embed_dim,num_classes)
def forward(self,x):
# x:[N, C, H, W]
N, C, H, W = x.shape
x = self.patch_embedding(x) # [N, embed_dim, h', w']
# x = x.reshape([N,C,-1]) / x = x.reshape(x.shape(:2)+[-1])
x = x.flatten(2) #比reshape更简单 [N, embed_dim, h'*w'=num_patchrs]
x = x.permute(0, 2, 1) # [N, num_patches, embed_dim]
x = self.encoder(x) # [N, num_patches,embed_dim]
print(x.shape)
x = self.classifier(x[:, 0])
return x
def main():
vit = VisionTransformer()
print(vit)
t = ([4, 3, 224, 224])
out = vit(t)
print(out)
if __name__ == '__main__':
main()
7.2 整合已完成部分
我们之前对于Encoder、Attention、MLP部分已经写完了,这里因为有多层Encoder,我们将之前Encoder定义为EncoderLayer,通过depth参数来构建多层的Encoder
class Encoder(nn.Module):
def __init__(self,embed_dim,depth):
super().__init__()
layer_list = []
for i in range(depth):
encoder_layer = EncoderLayer()
layer_list.append(encoder_layer)
self.layers = nn.ModuleList(layer_list)
self.norm = nn.LayerNorm(embed_dim)
def forward(self,x):
for layer in self.layers:
x = layer(x)
x = self.norm(x)
return x
其中调用 EncoderLayer来创建其中的内容,使用PreNorm形式进行创建
class EncoderLayer(nn.Module):
def __init__(self,embed_dim=768, num_heads=4, qkv_bias=True, mlp_ratio=4.0, dropout=0., attention_drop=0.):
super().__init__()
self.attn_norm = nn.LayerNorm(embed_dim)
self.attn = Attention(embed_dim,num_heads)
self.mlp_norm = nn.LayerNorm(embed_dim)
self.mlp = Mlp(embed_dim,mlp_ratio)
def forward(self,x):
# PreNorm
h = x #residual
x = self.attn_norm(x)
x = self.attn(x)
x = x+h
h = x
x = self.mlp_norm(x)
x = self.mlp(x)
x = x+h
return x
将Attention、以及MLP模块加入
class Mlp(nn.Module):
def __init__(self,embed_dim, mlp_ratio=4.0, dropout=0.):
super().__init__()
self.fc1 = nn.Linear(embed_dim, int(embed_dim* mlp_ratio))
self.fc2 = nn.Linear(int(embed_dim* mlp_ratio),embed_dim)
self.act = nn.GELU()
self.dropout = nn.Dropout(p=dropout)
def forward(self,x):
x = self.fc1(x)
x = self.act(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.dropout(x)
return x
class Attention(nn.Module):
def __init__(self,embed_dim, num_heads, qkv_bias=False, dropout=0.,attention_dropout=0.):
super().__init__()
self.embed_dim =embed_dim
self.num_heads =num_heads
self.head_dim = int(embed_dim/num_heads)
self.all_head_dim = self.head_dim*num_heads
# 把所有q 写在一起, 所有k、V写在一起,然后拼接起来,前1/3代表了所有head的Q,每一个head的尺寸已经定义好,要用的时候切就行了
self.qkv = nn.Linear(embed_dim,
self.all_head_dim*3,
bias=False if qkv_bias is False else None)
self.scale = self.head_dim ** -0.5
self.softmax = nn.Softmax(-1)
self.proj = nn.Linear(self.all_head_dim,embed_dim)
def transpose_multi_head(self,x):
# x: [B, N, all_head_dim]
new_shape = x.shape[:-1] + (self.num_heads, self.head_dim)
x = x.reshape(new_shape)
# x: [B, N, num_heads, head_dim]
x = x.permute(0,2,1,3)
# x: [B, num_heads, num_patches, head_dim]
return x
def forward(self,x):
B,N ,_ = x.shape
qkv = self.qkv(x).chunk(3,-1)
# [B, N, all_head_dim]* 3 , map将输入的list中的三部分分别传入function,然后将输出存到q k v中
q, k, v = map(self.transpose_multi_head,qkv)
# q,k,v: [B, num_heads, num_patches, head_dim]
attn = torch.matmul(q,k.transpose(-1,-2)) #q * k'
attn = self.scale * attn
attn = self.softmax(attn)
# dropout
# attn: [B, num_heads, num_patches, num_patches]
out = torch.matmul(attn, v) # 这里softmax(scale*(q*k')) * v
out = out.permute(0,2,1,3)
# out: [B, num_patches,num_heads, head_dim]
out = out.reshape([B, N, -1])
out = self.proj(out)
#dropout
return out
接下来就是在PatchEmbedding中加入 class token和 position embedding,它俩都是可学习的参数。
-
Class Token:即以一个虚拟的patch去关注所有图像中的所有的patch,来获得图像中的综合的信息,通过与classifier的连接来优化分类目标。
-
Pos_Embed:之前没有关注我们的每个patch的空间信息,现在将其加入,为了更好的训练。
我们创建一个参数,并对它初始化,class token定义就将最后一个维度定为embed_dim,前两个维度定为1,在前向过程中根据情况进行expand,代码中的expand部分也可以把后两维度设置为-1,class_tokens = self.class_token.expand([x.shape[0],-1,-1)第一维度就是batch_size,第二个维度是1,因为他算一个patch,第三个维度是embed_dim,最后在y方向与x进行concat连接;而position_embedding是与输入的image_token维度一样,在前向过程需要将它与输入的x相加,我们定义为(1,patch的数量+1,embed_dim)
class PatchEmbedding(nn.Module):
def __init__(self,image_size=224, patch_size=16, in_channels=3, embed_dim=768 ,dropout=0.):
super().__init__()
n_patches = (image_size//patch_size) * (image_size//patch_size)
self.patch_embedding = nn.Conv2d(in_channels = in_channels,
out_channels= embed_dim,
kernel_size=patch_size,
stride=patch_size)
self.dropout = nn.Dropout(dropout)
self.embed_dim =embed_dim
# TODO: add cls token
self.class_token = nn.Parameter(nn.init.constant_(torch.zeros(1,1,embed_dim,dtype=torch.float32),1.0))
# TODO: add position embedding
self.position_embedding = nn.Parameter(nn.init.trunc_normal_(torch.randn(1,n_patches+1,embed_dim,dtype=torch.float32),std=.02))
def forward(self,x):
class_tokens =self.class_token.expand([x.shape[0], 1, self.embed_dim]) #for batch
# x: [N, C, H, W]
x = self.patch_embedding(x) # x: [n, embed_dim, h', w']
x = x.flatten(2) #[n, embed_dim, h'*w']
x = x.permute(0, 2, 1) #[n, h'*w', embed_dim]
x = torch.concat([class_tokens, x], axis=1)
# print('embeding中:',x.shape)
x = x + self.position_embedding
x = self.dropout(x)
return x
完成后调试过程中出现RuntimeError: Given normalized_shape=[768], expected input with shape [*, 768], but got input of size[4, 768, 197]
定位到EncoderLayer部分中进行layer_norm的时候报错,我们对它之前的维度进行打印
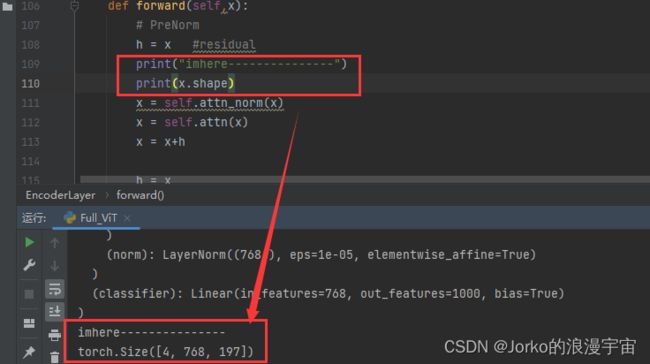
发现进入encoder的维度是torch.Size([4, 768, 197]),那他的输入是从哪里来的?
是从Patch Embedding中来的,查看ViT在forward中经过Patch Embedding 后的维度
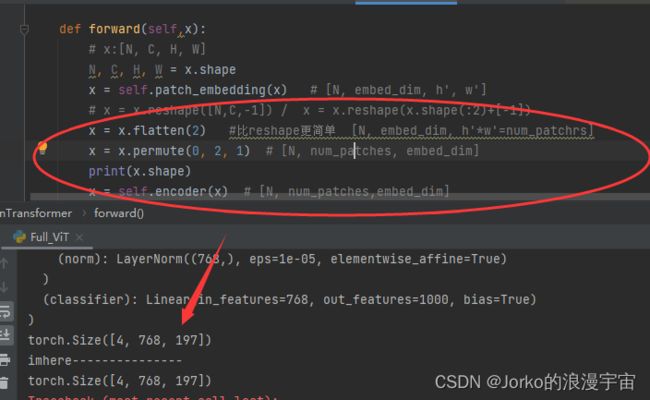
我们使用permute进行换位置了,但为什么没有呢?我们再看转置前一步
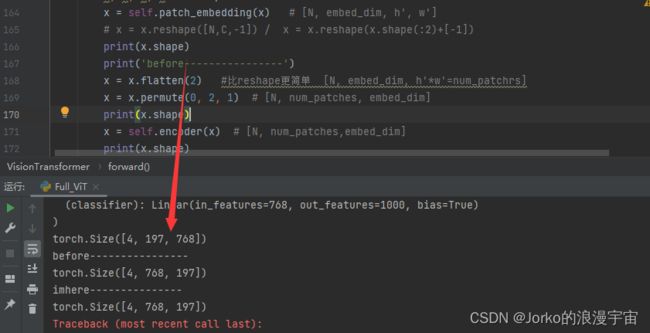
可以发现,我们patch embedding之后以及将embed_dim维度放在最后了,我们不需要进行转置了。
查看patch_embedding中
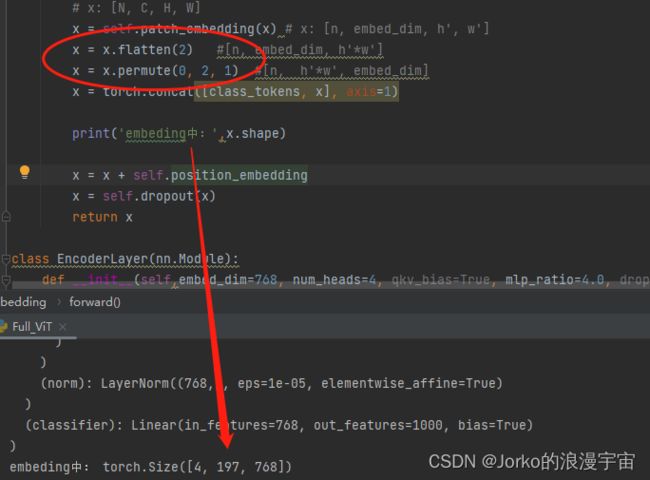
在走完后patch_embedding已经进行转置了,197就是14×14个patch块,再加1个cls token。
这样就可以输出模型的结果以及正确输出模型结构了
torch.Size([4, 1000])
VisionTransformer(
(patch_embedding): PatchEmbedding(
(patch_embedding): Conv2d(3, 768, kernel_size=(16, 16), stride=(16, 16))
(dropout): Dropout(p=0.0, inplace=False)
)
(encoder): Encoder(
(layers): ModuleList(
(0): EncoderLayer(
(attn_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=False)
(softmax): Softmax(dim=-1)
(proj): Linear(in_features=768, out_features=768, bias=True)
)
(mlp_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(act): GELU(approximate=none)
(dropout): Dropout(p=0.0, inplace=False)
)
)
(1): EncoderLayer(
(attn_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=False)
(softmax): Softmax(dim=-1)
(proj): Linear(in_features=768, out_features=768, bias=True)
)
(mlp_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(act): GELU(approximate=none)
(dropout): Dropout(p=0.0, inplace=False)
)
)
(2): EncoderLayer(
(attn_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=False)
(softmax): Softmax(dim=-1)
(proj): Linear(in_features=768, out_features=768, bias=True)
)
(mlp_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(act): GELU(approximate=none)
(dropout): Dropout(p=0.0, inplace=False)
)
)
)
(norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(classifier): Linear(in_features=768, out_features=1000, bias=True)
)
在pytorch中想要查看模型当中的参数和各层的输出维度
可以使用torchinfo / torchsummary 库
因为我们设计的网络架构中用的四个维度,发现torchsummary传入没有Batch_size维度,但torchinfo可以传入batch_size维度
from torchinfo import summary
summary(vit,input_size=(4, 3, 224, 224))
输出结果如下:
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
VisionTransformer [4, 1000] --
├─PatchEmbedding: 1-1 [4, 197, 768] 152,064
│ └─Conv2d: 2-1 [4, 768, 14, 14] 590,592
│ └─Dropout: 2-2 [4, 197, 768] --
├─Encoder: 1-2 [4, 197, 768] --
│ └─ModuleList: 2-3 -- --
│ │ └─EncoderLayer: 3-1 [4, 197, 768] 7,085,568
│ │ └─EncoderLayer: 3-2 [4, 197, 768] 7,085,568
│ │ └─EncoderLayer: 3-3 [4, 197, 768] 7,085,568
│ └─LayerNorm: 2-4 [4, 197, 768] 1,536
├─Linear: 1-3 [4, 1000] 769,000
==========================================================================================
Total params: 22,769,896
Trainable params: 22,769,896
Non-trainable params: 0
Total mult-adds (M): 551.13
==========================================================================================
Input size (MB): 2.41
Forward/backward pass size (MB): 169.46
Params size (MB): 90.47
Estimated Total Size (MB): 262.34
==========================================================================================