【Speaker Recognition】A CHAPTER-WISE UNDERSTANDING SYSTEM FOR TEXT-TO-SPEECH IN CHINESE NOVELS
A CHAPTER-WISE UNDERSTANDING SYSTEM FOR TEXT-TO-SPEECH IN CHINESE NOVELS
Abstract
在基于文本转语音TTS的有声读物制作中,多角色配音和情感表达可以显著提高有声读物的自然性。然而,它需要在句子水平上手动标注带有明确的说话者和情感标签的原创小说,这是非常耗时和昂贵的。在本文中,我们提出了一种中国小说的章节理解系统,基于章节级语境自动预测说话者和情感标签。与每个组件的基线相比,我们的模型获得了更高的性能。由我们提出的系统制作的有声读物和多扬声器情感TTS系统,被证明具有与个人制作人制作的有声读物相当的质量分数。演示模块在https://jeffpan.net/icassp/2021/main.html中进行了演示。
1. INTRODUCTION
由于文本到语音(TTS)相对较低的成本和较高的制作效率,人们试图将小说转换为有声读物。最简单的方法是使用单扬声器TTS系统在句子级合成小说,并将合成的音频组合在一起。该解决方案已广泛应用于新闻和导航广播场景。
然而,小说是相对长尾文本,随意的写作形式,频繁的人物互动和多元对话。由于这些特性,传统的TTS解决方案可能会让观众听力疲劳,对内容理解感到困惑。通过对人类制作的有声读物的分析,我们发现了影响高质量有声读物的两个关键因素——基于故事情节的情感表达和不同对话的各种配音。在此基础上,我们构建了一个创新的小说合成生产管道,它包括两个阶段。首先,首先将非结构化的小说文本手动转换为脚本,每个对话都贴有说话者和情感标签。其次,将标记脚本输入具有多说话者模型的情绪TTS系统,将属于不同说话者的对话以不同的声音合成。根据我们的经验,手工标签工作相当耗时和昂贵,这使得大规模制作有声读物不切实际。
为了解决这一问题,我们提出了一种针对中国小说的章节理解系统来自动预测说话者和情感标签。据我们所知,这是对语音合成的新理解的第一个工作。我们的实验表明,系统中的每个组件都比独立的基线获得了更好的性能。该系统采用多说话人情感TTS系统实现,可以显著提高小说合成的制作效率,并制作出质量与人类个人制作人相当的有声读物。
2. BACKGROUND
该系统实现了汉语小说中的两个文本理解任务——说话人的确定和情感的分类。
- 在确定说话者时,由于角色列表并不总是可用的,因此需要首先确定所有个人角色的范围。需要挖出对话和这些上诉之间的因果关系,即使这些联系没有明确说明。在每一段对话被分配到最可能的名称后,应采用共同引用决议将指同一人的名称合并在一起,确保同一个人的对话可以用同一声音合成。
- 在情绪分类中,基于目标对话预测情绪通常是不可靠和令人困惑的,因为情绪并不总是隐含在对话本身中,而是由长期语境暗示。
在本节中,我们简要回顾了我们提出的系统中的一些主要组成部分,包括人姓名识别(PerNER)、对话中的说话人识别(SID)、共同参考分辨率(CoRef)和基于随机上下文的情绪分类。
2.1 PerNER
从常识上说,命名实体识别(NER)是提取命名实体的过程,如人员名称、组织、位置、医疗代码、时间表达式、数量、货币值和百分比。在中国的NER中已经进行了顺序标记工作。然而,小说中的命名实体因常见情况的不同而差异很大,特别是在人物名称、地点和组织中,而且中国小说中没有开源的NER语料库。考虑到我们的目标是提取人的名字,我们定义了NER-PerNER的一个子任务,它只寻求定位人的姓名和头衔。PerNER大大简化了标签的工作,但它带来了另一个问题,即标签变得更加稀疏,这可能会降低PerNER的性能。为了解决这个问题,我们提出了一个数据增强策略。
2.2 SID
说话者对话识别(SID)的目的是识别从文本中引用的说话者。在新闻或戏剧中,这似乎很简单,因为在这些场景中,说话者总是通过说话模式来明确地陈述,比如说、回答或声明。然而,小说中的内隐说话者和说话者交替模式使SID任务极其困难。基于规则的模型和基于神经网络的模型已由[9]实现。多标签分类不适合用于这个任务,因为类别(说话者)的数量不是固定的。在我们的工作中,SID被认为是所有可能的演讲者中的一个排名任务。
2.3 CoRef
在我们提出的系统中,CoRef共同参考分辨率(Coref)被定义为将人的名称分组到共同引用链中,其中每个链引用一个唯一的说话者。与SID类似,多标签分类也不适合CoRef。为了简化这个任务,我们将人员分为两类——主要名称和候选名称,并将CoRef转换为两阶段排名任务。当在基于TTS的有声读物制作管道中实现时,在同一共参考链中的说话者以相同的声音合成,从而确保了听力的一致性。
2.4 Emotion Classification
为情绪TTS系统提供了情感标签,使合成音频更具表现性。传统的情感分类是指从一段非正式的文本[10,11]中区分积极类和消极类。对于有声读物来说,二元情感分类似乎过于简单,因为情感在对话中更为复杂。根据《普鲁奇克的《情绪之轮[12]》,人们的情绪可以分为八类,每种情绪可以进一步分为不同程度的三种情绪,结合单一情绪可以识别出更多的复合情绪。一些研究已经在社交媒体中从如此细粒度的文本中检测情绪,在英语和中文[15]中检测常识故事。章节理解系统的结构。在我们的研究中,我们选择了7种情绪作为标签(中性、快乐、愤怒、厌恶、悲伤、惊讶、恐惧),并考虑了长期的语境特征。
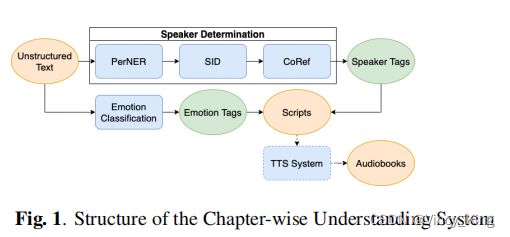
3. MODEL ARCHITECTURE
在本节中,我们提出了一个章节式的理解系统,将非结构化的小说文本转换为带有说话者和情感标签的脚本。整个结构如图1所示。由于训练数据量少和标记工作的难度大,我们选择了统计机器学习模型和相对简单的神经网络(NN)模型,而不是像BERT[16]这样复杂的预训练模型。
3.1 Speaker Determination
说话者决定告诉TTS系统将选择哪个声音来合成当前的句子。所有的叙述都被标记为相同的声音,每个对话都被分配给相应的说话者。指同一个人的说话者被合并成一个单一的说话者标签,因此相应的对话以相同的声音合成。说话者的决定由三个组成部分组成——PerNER、SID和CoRef,如图1所示。
3.1.1. PerNER
PerNER模型是基于变压器的,包括一个256个单元的前置器,一个有8个单元和256个单元的多头自注意层,和一个CRF输出层。PerNER的输入是一个句子的字符嵌入[17],输出是一个BMEIO1标签的序列。采用了如第4.1.1节所述的数据增强策略。
3.1.2. SID
在SID任务中实现了一个基于GBDT的排序模型。SID的输入是来自5个句子窗口的潜在名称,其中中间的一个是目标对话句子,并为每个名称计算11维特征(如表1所示。在dist_rank特征中,候选人根据到目标对话框从最小到最大的距离进行排序

3.1.3. CoRef
如第2.3节所述,我们定义了两种名称——主要名称和候选名称。以中文姓氏开头,在一章中至少出现三次或最常见的两种称呼被定义为主姓名。其他名称被定义为候选名称。首先,所有的候选名称都被分配给最可能的主名称。然后将主名称分配给另一个最可能的主名称或其本身。在此之后,在每个共引用链中生成一个主名作为根节点的共引用链。
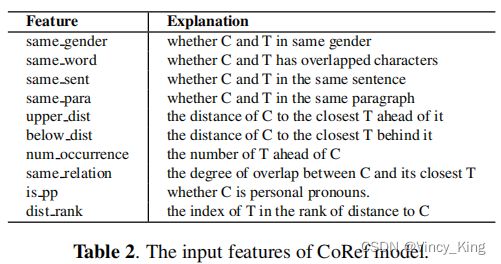
CoRef中使用了基于GBDT的模型,输入特征见表2。C表示当前候选名称,T表示与的最近的目标主名称 C. 距离被定义为C和 D. 性别特征由ngender预测,这是一个开源的中文名称性别预测工具。同样的关系特征也可以用公式1计算出来。
s a m e _ r e l a t i o n = l e n g t h [ s e t ( C a 20 & s e t ( T a 20 ) ) ] same\_relation=length[set(C_{a20}\&set(T_{a20}))] same_relation=length[set(Ca20&set(Ta20))]
其中 C s 20 C_{s20} Cs20和 T s 20 T_{s20} Ts20是与C和D最接近的20个名称的列表。
3.2 Emotion Classification
情绪分类模型由一个包含256个单元的1层BLSTM组成,然后是一个7维的密集层。原输入句子及其前后句子被分割成单词。在每个句子中,最多选择25个情感单词(由第3.2.1节中描述的情感字典定义)并转换为300维的单词嵌入。对于每个单词,其句子索引和位置嵌入连接到嵌入向量。然后最后的输入是所有单词嵌入的连接。
3.2.1. Emotional Word Dictionary
训练语料库首先分为7个部分,每个部分 N e N_e Ne包含所有标记为相同情感的句子。对于每个单词,其在 N e N_e Ne中的TF-IDF得分由公式2计算。
f ( w , S , N e ) = c o u n t ( w ) c o u n t ( a l l w o r d s ) ⋅ log S ∣ s ∈ N e : w ∈ s ∣ f(w,S,N_e)=\frac{count(w)}{count(all_words)}·\log\frac{S}{|s∈N_e:w∈s|} f(w,S,Ne)=count(allwords)count(w)⋅log∣s∈Ne:w∈s∣S
其中 w w w表示当前单词, S S S表示 N e N_e Ne中的句子数, ∣ s ∈ N e : w ∈ s ∣ |s∈N_e: w∈s| ∣s∈Ne:w∈s∣表示单词 w w w出现的句子数。 f ( w , S , N e ) f(w,S,N_e) f(w,S,Ne)越高,情感 e e e中的词 w w w就越重要。对每个情绪重复这个过程,可以获得一个TF-IDF F w F_w Fw的列表。然后根据 F w F_w Fw的方差对所有单词进行排序,其中方差越高,意味着情感区分的重要性越高。在我们的工作中,我们选择了前8000个情感词来构建字典。
4. EXPERIMENTS AND RESULTS
4.1. Dataset
由于没有开源数据,我们从章节层面的中国小说中抽取文本,并进行标记,构建训练语料库。数据集的详细信息列于表3。
4.1.1. Data Augmentation in PerNER dataset
对于PerNER数据集,采用了四种基于替换的数据增强策略:
- 标记的说话者名字被从名称字典中随机选择的名字替换;
- 标签说话者的姓氏被其他中文姓氏取代;
- 标签说话者的标题被从标题字典中选择的其他标题取代;
- 未标记的部分被分割成单词,同义词和反义词字典中的同义词被同义词或反义词取代。数据的增强帮助我们的PerNER模型更多地关注句子结构,而不是被标记的词本身。

4.2. Results and Analysis
4.2.1. Evaluation of PerNER
在这部分中,我们将基于转换器的模型与HanLP[18]、Stanza(使用中文模型)[19]和基于BLSTM的NER模型进行了比较。由于HanLP和Stanza无法训练,它们的召回率极低,导致f1分数较低。表4表明,我们通过增强数据训练的基于变压器的模型获得了与基于BLSTM的模型相当的结果,而我们的模型显示了明显更快的推理速度。我们还可以发现,第4.1.1节中提到的数据增强策略在f1-分数中使我们的模型提高了约0.03。

4.2.2. Evaluation of SID
我们在[9]中使用了基于bert增强的基于分类器的模型,并与我们提出的模型进行了比较。结果表明,我们的模型的准确率提高了10.63%(0.8703vs0.7640)。数据量的限制可能是限制BERT性能的主要因素。
4.2.3. Evaluation of CoRef
如表5所示,我们将我们的模型与Stanza(中文)和随机选择策略进行了比较。因为Stanza只能使用其预测的NER作为共参考分辨率的输入,所以我们也用PerNER预测的输入作为比较来评估我们的模型。可以发现,Stanza的表现最差,这可能是由于其在PerNER任务中的召回率极低所致。我们提出的预测输入和地面真实输入模型的f1分数分别比随机选择高22.13%和40.12%。

4.2.4. Evaluation of Emotion Classification
在小说综合中,我们只在对话中使用情绪控制,所有的叙述都被设置为中性情绪。基于此,我们只在对话中评估了我们的情感分类方法。此外,非中性情绪比中性情绪对听力的影响更大,因此非中性标签的指标也被考虑在内。相比之下,我们选择了一个朴素贝叶斯分类器作为基线。可以发现,与基线相比,我们的模型在总体对话准确性上仅高0.1,但在非中性结果中高0.3。

4.2.5. Cascade with Emotional Multi-Speaker TTS
我们最初建立这样一个章节理解系统的目的是构建一个基于TTS的高质量和高效的有声读物制作管道。为了评估其端到端性能,我们将由我们提出的基于TTS的制作管道与人工制作的有声读物进行了比较。S级有声读物是由专业的制作团队制作的,有各种背景音乐,合适的音效,和高质量的各种声音的录音。A级有声读物由业余制作团队制作,由专业配音演员制作,但很少进行后期处理。B级有声读物是由个别制作人制作的,没有经过后处理。
表7中的有声读物评价测试3的质量分数表明,我们提出的系统达到了与b级有声读物相当的质量。演示文稿可以在摘要中找到。

5. CONCLUSION
本文介绍了一种中国小说的章节理解系统,这是在有声读物制作领域的一种创新方法。对于该系统中的每个组件,实验结果表明,我们的模型比独立的基线具有更好的性能。用多说话者情感TTS系统实现我们提出的系统,可以产生与b级人工TTS系统质量分数相当的有声读物。
未来的潜在工作包括调整我们用其他语言提出的系统,并将情绪分类扩展到复合情绪。此外,还可以研究多任务的端到端结构,以避免在管道结构中的错误传播。