pytorch 图像分割的交并比_深度学习黑客竞赛神器:基于 PyTorch 图像特征工程的深度学习图像增强...


概述
当我们没有足够的数据时,图像增强是一个非常有效的方法
我们可以在任何场合使用图像增强进行深度学习——黑客竞赛、工业项目等等
我们还将使用PyTorch建立一个图像分类模型,以了解图像增强是如何形成图片的
介绍
在深度学习黑客竞赛中表现出色的技巧(或者坦率地说,是任何数据科学黑客竞赛) 通常归结为特征工程。当您获得的数据不足以建立一个成功的深度学习模型时,你能发挥多少创造力?
我是根据自己参加多次深度学习黑客竞赛的经验而谈的,在这次深度黑客竞赛中,我们获得了包含数百张图像的数据集——根本不足以赢得甚至完成排行榜的顶级排名。那我们怎么处理这个问题呢?
答案?好吧,那要看数据科学家的技能了!这就是我们的好奇心和创造力脱颖而出的地方。这就是特征工程背后的理念——在现有特征的情况下,我们能多好地提出新特征。当我们处理图像数据时,同样的想法也适用。
这就是图像增强的主要作用。这一概念不仅仅局限于黑客竞赛——我们在工业和现实世界中深度学习模型项目中都使用了它!
 image_augmentation
image_augmentation
图像增强功能帮助我扩充现有数据集,而无需费时费力。而且我相信您会发现这项技术对您自己的项目非常有帮助。
因此,在本文中,我们将了解图像增强的概念,为何有用以及哪些不同的图像增强技术。我们还将实现这些图像增强技术,以使用PyTorch构建图像分类模型。
这是我的PyTorch初学者系列文章的第五篇。您可以在此处访问以前的文章:
A Beginner-Friendly Guide to PyTorch and How it Works from Scratch
文章地址:https://www.analyticsvidhya.com/blog/2019/09/introduction-to-pytorch-from-scratch/?utm_source=blog&utm_medium=image-augmentation-deep-learning-pytorch
Build an Image Classification Model using Convolutional Neural Networks in PyTorch
文章地址:https://www.analyticsvidhya.com/blog/2019/10/building-image-classification-models-cnn-pytorch/?utm_source=blog&utm_medium=image-augmentation-deep-learning-pytorch
Deep Learning for Everyone: Master the Powerful Art of Transfer Learning using PyTorch
文章地址:https://www.analyticsvidhya.com/blog/2019/10/how-to-master-transfer-learning-using-pytorch/?utm_source=blog&utm_medium=image-augmentation-deep-learning-pytorch
4 Proven Tricks to Improve your Deep Learning Model’s Performance
文章地址:https://www.analyticsvidhya.com/blog/2019/11/4-tricks-improve-deep-learning-model-performance/?utm_source=blog&utm_medium=image-augmentation-deep-learning-pytorch
目录
为什么需要图像增强?
不同的图像增强技术
选择正确的增强技术的基本准则
案例研究:使用图像增强解决图像分类问题
为什么需要图像增强?
深度学习模型通常需要大量的数据来进行训练。通常,数据越多,模型的性能越好。但是获取海量数据面临着自身的挑战。不是每个人都有大公司的雄厚财力。
缺少数据使得我们的[深度学习模型](https://courses.analyticsvidhya.com/courses/computer-vision-using-deep-learning-version2?utm_source=blog&utm_medium=image-augmentation-deep -learning-pytorch)可能无法从数据中学习模式或功能,因此在未见过的数据上可能无法提供良好的性能。
那么在那种情况下我们该怎么办?我们可以使用图像增强技术,而无需花费几天的时间手动收集数据。
图像增强是生成新图像以训练我们的深度学习模型的过程。这些新图像是使用现有的训练图像生成的,因此我们不必手动收集它们。
 Image-Augmentation
Image-Augmentation
有多种图像增强技术,我们将在下一节讨论一些常见的和使用最广泛的技术。
不同的图像增强技术
图像旋转
图像旋转是最常用的增强技术之一。它可以帮助我们的模型对对象方向的变化变得健壮。即使我们旋转图像,图像的信息也保持不变。汽车就是一辆汽车,即使我们从不同的角度看它:
 Screenshot-from-2019-11-26-13-05-26
Screenshot-from-2019-11-26-13-05-26
因此,我们可以使用此技术,通过从原始图像创建旋转图像来增加数据量。让我们看看如何旋转图像:
# 导入所有必需的库我将使用此图像(https://drive.google.com/file/d/1Ld4gDh-XjEZiCmQjvFV1WFBgC6LyvNB0/view?usp=sharing)演示不同的图像增强技术。你也可以根据自己的要求尝试其他图片。
我们先导入图像并将其可视化:
# reading the image using its path Screenshot-from-2019-11-26-13-09-10
Screenshot-from-2019-11-26-13-09-10
这是原始图像。现在让我们看看如何旋转它。我将使用skimage 库的旋转功能来旋转图像:
'Rotated Image')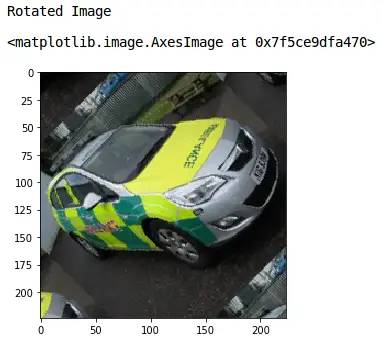 Screenshot-from-2019-11-26-13-10-26
Screenshot-from-2019-11-26-13-10-26
很好!将模式设置为“wrap”,用图像的剩余像素填充输入边界之外的点。
平移图像
可能会出现图像中的对象没有完全居中对齐的情况。在这些情况下,可以使用图像平移为图像添加平移不变性。
通过移动图像,我们可以更改对象在图像中的位置,从而使模型更具多样性。最终将生成更通用的模型。
图像平移是一种几何变换,它将图像中每个对象的位置映射到最终输出图像中的新位置。
在移位操作之后,输入图像中的位置(x,y)处的对象被移位到新位置(X,Y):
X = x + dx
Y = y + dy
其中,dx和dy分别是沿不同维度的位移。让我们看看如何将shift应用于图像:
# 应用平移操作 Screenshot-from-2019-11-26-13-17-05
Screenshot-from-2019-11-26-13-17-05
translation超参数定义图像应移动的像素数。这里,我把图像移了(25,25)个像素。您可以随意设置此超参数的值。
我再次使用“wrap”模式,它用图像的剩余像素填充输入边界之外的点。在上面的输出中,您可以看到图像的高度和宽度都移动了25像素。
翻转图像
翻转是旋转的延伸。它使我们可以在左右以及上下方向上翻转图像。让我们看看如何实现翻转:
#flip image left-to-right Screenshot-from-2019-11-26-13-23-12
Screenshot-from-2019-11-26-13-23-12
在这里,我使用了NumPy的fliplr 函数从左向右翻转图像。它翻转每一行的像素值,并且输出确认相同。类似地,我们可以沿上下方向翻转图像:
# 上下翻转图像 Screenshot-from-2019-11-26-13-24-51
Screenshot-from-2019-11-26-13-24-51
这就是我们可以翻转图像并制作更通用的模型的方法,该模型将学习到原始图像以及翻转后的图像。向图像添加随机噪声也是图像增强技术。让我们通过一个例子来理解它。
给图像添加噪点
图像噪声是一个重要的增强步骤,使我们的模型能够学习如何分离图像中的信号和噪声。这也使得模型对输入的变化更加健壮。
我们将使用“skipage”库的“random_noise”函数为原始图像添加一些随机噪声
我将噪声的标准差取为0.155(您也可以更改此值)。请记住,增加此值将为图像添加更多噪声,反之亦然:
# 要添加到图像中的噪声的标准差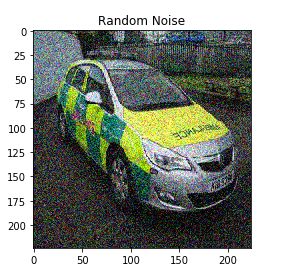
我们可以看到随机噪声已添加到原始图像中。试一下不同的标准偏差的值,看看得到的不同结果。
模糊图像
所有摄影爱好者都会立即理解这个想法。
图像有不同的来源。因此,每个来源的图像质量都将不同。有些图像的质量可能很高,而另一些则可能很差劲。
在这种情况下,我们可以使图像模糊。那将有什么帮助?好吧,这有助于使我们的深度学习模型更强大。
让我们看看我们如何做到这一点。我们将使用高斯滤波器来模糊图像:
# 模糊图像
Sigma是高斯滤波器的标准差。我将其视为1。sigma值越高,模糊效果越强。将* Multichannel *设置为true可确保分别过滤图像的每个通道。
同样,您可以尝试使用不同的sigma值来更改模糊度。
这些是一些图像增强技术,有助于使我们的深度学习模型健壮且可推广。这也有助于增加训练集的大小。
我们即将完成本教程的实现部分。在此之前,让我们看看一些基本的准则,以决定正确的图像增强技术。
选择正确的增强技术的基本准则
我认为在根据您试图解决的问题来决定增强技术时,有一些准则是很重要的。以下是这些准则的简要概述:
任何模型构建过程的第一步都是确保输入的大小与模型所期望的大小相匹配。我们还必须确保所有图像的大小应该相似。为此,我们可以调整我们的图像到适当的大小。
假设您正在处理一个分类问题,并且样本数据量相对较少。在这种情况下,可以使用不同的增强技术,如图像旋转、图像噪声、翻转、移位等。请记住,所有这些操作都适用于对图像中对象位置无关紧要的分类问题。
如果您正在处理一个对象检测任务,其中对象的位置是我们要检测的,这些技术可能不合适。
图像像素值的标准化是保证模型更好更快收敛的一个很好的策略。如果模型有特定的要求,我们必须根据模型的要求对图像进行预处理。
现在,不用再等了,让我们继续到模型构建部分。我们将应用本文讨论的增强技术生成图像,然后使用这些图像来训练模型。
我们将研究紧急车辆与非紧急车辆的分类问题。如果你看过我以前的PyTorch文章(https://www.analyticsvidhya.com/blog/author/pulkits/?utm_source=blog&utm_medium=image-augmentation-deep-learning-pytorch),你应该熟悉问题的描述。
该项目的目标是将车辆图像分为紧急和非紧急两类。你猜对了,这是一个图像分类问题。
您可以 从这里:https://drive.google.com/file/d/1EbVifjP0FQkyB1axb7KQ26yPtWmneApJ/view
下载数据集。
加载数据集
我们开始吧!我们先把数据装入notebook。然后,我们将应用图像增强技术,最后,建立一个卷积神经网络(CNN)模型。
卷积神经网络参考地址:https://www.analyticsvidhya.com/blog/2018/12/guide-convolutional-neural-network-cnn/?utm_source=blog&utm_medium=image-augmentation-deep-learning-pytorch
让我们导入所需的库:
# 导入库现在,我们将读取包含图像名称及其相应标签的CSV文件:
# 加载数据集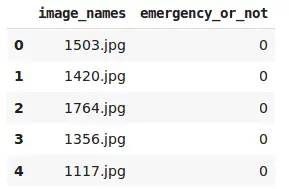 Screenshot-from-2019-11-27-13-04-48
Screenshot-from-2019-11-27-13-04-48
0表示该车为非紧急车辆,1表示该车为紧急车辆。现在让我们从数据集中加载所有图像:
# 加载图像数据集中共有1646幅图像。让我们把这些数据分成训练和验证集。我们将使用验证集来评估模型在未见过的数据上的性能:
0.1, random_state = 我将“test_size”保持为0.1,因此10%的数据将随机选择作为验证集,剩下的90%将用于训练模型。训练集有1481个图像,这对于训练深度学习模型来说是相当少的。
因此,接下来,我们将增加这些训练图像,以增加训练集,并可能提高模型的性能。
增强图像
我们将使用前面讨论过的图像增强技术:
final_train_data = []
final_target_train = []
for i in tqdm(range(train_x.shape[0])):
final_train_data.append(train_x[i])
final_train_data.append(rotate(train_x[i], angle=45, mode = 'wrap'))
final_train_data.append(np.fliplr(train_x[i]))
final_train_data.append(np.flipud(train_x[i]))
final_train_data.append(random_noise(train_x[i],var=0.2**2))
for j in range(5):
final_target_train.append(train_y[i])
我们为训练集中的1481张图像中的每一张生成了4张增强图像。让我们以数组的形式转换图像并验证数据集的大小:
len(final_target_train), len(final_train_data)
final_train = np.array(final_train_data)
final_target_train = np.array(final_target_train)
这证实了我们已经增强了图像并增加了训练集的大小。让我们将这些增强图像进行可视化:
1,ncols= Screenshot-from-2019-11-27-14-06-46
Screenshot-from-2019-11-27-14-06-46
这里的第一个图像是来自数据集的原始图像。其余四幅图像分别使用不同的图像增强技术(旋转、从左向右翻转、上下翻转和添加随机噪声)生成的。
我们的数据集现在已经准备好了。是时候定义我们的深度学习模型的结构,然后在增强过的训练集上对其进行训练了。我们先从PyTorch中导入所有函数:
# PyTorch 库和模块我们必须将训练集和验证集转换为PyTorch格式:
# 将训练图像转换为torch格式同样,我们将转换验证集:
# 将验证图像转换为torch格式模型结构
接下来,我们将定义模型的结构。这有点复杂,因为模型结构包含4个卷积块,然后是4个全连接层:
0)让我们定义模型的其他超参数,包括优化器、学习率和损失函数:
# defining the model Screenshot-from-2019-11-27-14-24-41
Screenshot-from-2019-11-27-14-24-41
训练模型
为我们的深度学习模型训练20个epoch:
0) Screenshot-from-2019-11-27-14-26-37
Screenshot-from-2019-11-27-14-26-37
这是训练阶段的summary。你会注意到,随着epoch的增加,训练loss会减少。让我们保存已训练的模型的权重,以便将来在不重新训练模型的情况下使用它们:
'model.pt')如果您不想在您的终端训练模型,您可以使用此链接:https://drive.google.com/open?id=14r5joYfivbX49TvyfLGUFYYYTZsv8OmJ下载已训练了20个epoch的模型的权重。
接下来,让我们加载这个模型:
'model.pt')测试我们模型的性能
最后,让我们对训练集和验证集进行预测,并检查各自的准确度:
0)训练集的准确率超过91%!很有希望。但是,让我们拭目以待吧。我们需要对验证集进行相同的检查:
# 预测验证集验证准确性约为78%。很好!
尾注
当我们开始获得的训练数据较少时,我们可以使用图像增强技术。
在本文中,我们介绍了大多数常用的图像增强技术。我们学习了如何旋转,移动和翻转图像。我们还学习了如何为图像添加随机噪声或使其模糊。然后,我们讨论了选择正确的增强技术的基本准则。
您可以在任何图像分类问题上尝试使用这些图像增强技术,然后比较使用增强和不使用增强的性能。随时在下面的评论部分中分享您的结果。
而且,如果您不熟悉深度学习,计算机视觉和图像数据,那么建议您完成以下课程:
使用深度学习2.0的计算机视觉
(https://courses.analyticsvidhya.com/courses/computer-vision-using-deep-learning-version2?utm_source=blog&utm_medium=image-augmentation-deep-learning-pytorch)
原文链接:https://www.analyticsvidhya.com/blog/2019/12/image-augmentation-deep-learning-pytorch/
推荐阅读
(点击标题可跳转阅读)
干货 | 公众号历史文章精选
我的深度学习入门路线
我的机器学习入门路线图
重磅!
AI有道年度技术文章电子版PDF来啦!
扫描下方二维码,添加 AI有道小助手微信,可申请入群,并获得2020完整技术文章合集PDF(一定要备注:入群 + 地点 + 学校/公司。例如:入群+上海+复旦。

长按扫码,申请入群
(添加人数较多,请耐心等待)
最新 AI 干货,我在看 