LSTM分类模型
LSTM文本分类模型
本文主要固定一个文本分类的流程。分为三个部分:
- 数据处理。对分类文本数据集做简单的预处理。
- 模型数据准备。处理上一步的结果,得到模型的输入样本。
- 模型搭建和训练流程。模型使用BiLSTM;训练过程可以使用cpu或者GPU。traniner.py的use_cuda参数来控制。
程序架构如下:
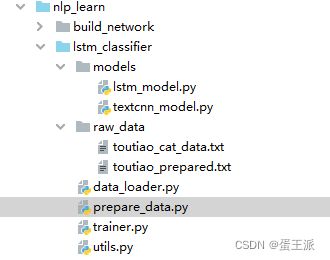
主要包括一个原始的分类文件(头条新闻)。
一个预处理脚本prepare_data.py
一个数据处理脚本data_loader.py
一个训练过程脚本trainer.py
一个模型文件lstm_model.py–使用BiLSTM
分类流程
数据预处理
将原始的文本进行预处理,原始文件形式如下:

处理后文件如下,形式为 内容文本\t类别名称

只需要运行 prepare_data.py即可生成处理后的文件。注意输入路径。具体代码为
# -*- coding: utf-8 -*-
"""
@Time : 2022/2/26 11:44
@Auth : hcb
@File :prepare_data.py
@IDE :PyCharm
@Motto:ABC(Always Be Coding)
"""
import os
from tqdm import tqdm
class PrepareData(object):
def __init__(self):
self.base_dir = os.path.join(os.path.dirname(__file__), "raw_data")
self.raw_data_path = os.path.join(self.base_dir, "toutiao_cat_data.txt")
self.prepared_data_path = os.path.join(self.base_dir, "toutiao_prepared.txt")
def obtain_raw_data(self):
""""""
with open(self.raw_data_path, "r", encoding="utf8") as reader:
all_lines = reader.readlines()
prepared_data = []
print("正在处理数据...")
for line in tqdm(all_lines):
info = self.deal_data(line)
if info:
prepared_data.append(info)
# 保存处理好的数据
with open(self.prepared_data_path, "w", encoding="utf8") as writer:
for info in prepared_data:
# print(info)
writer.write(info + "\n")
@staticmethod
def deal_data(line):
""""""
line_split = line.split("_!_")
label_name = line_split[2]
content = line_split[3]
desc = line_split[4]
text = content + " " + desc
text = text.replace("\t", " ")
text = text.replace("\n", " ")
if text and label_name:
return text + "\t" + label_name
else:
return None
if __name__ == '__main__':
prepared_obj = PrepareData()
prepared_obj.obtain_raw_data()
模型数据生成
将上一步的文件进一步处理,得到模型的输入–训练和测试。中间涉及词典生成、自定义数据类等操作。目标是self.train_dataloader和self.test_dataloader。具体程序为:
# -*- coding: utf-8 -*-
"""
@Time : 2022/2/26 11:44
@Auth : hcb
@File :data_loader.py
@IDE :PyCharm
@Motto:ABC(Always Be Coding)
"""
import torch
import os
import jieba
from torch.utils.data import DataLoader, Dataset
import numpy as np
from tqdm import tqdm
from sklearn.cross_validation import train_test_split
class BaseData():
__doc__ = "生产训练集和测试集数据迭代器"
def __init__(self, args):
self.base_dir = os.path.join(os.path.dirname(__file__), "raw_data")
self.raw_data_path = os.path.join(self.base_dir, "toutiao_prepared.txt")
# self.prepared_data_path = os.path.join(self.base_dir, "toutiao_prepared.txt")
self.use_char = True
self.word2id = {}
self.id2word = {}
self.label2id = {}
self.id2label = {}
self.batch_size = args.batch_size
self.max_seq_len = args.max_seq_len
self.enforced_sorted = True
self.train_dataloader = None
self.test_dataloader = None
self.trainset_idx, self.testset_idx = self.obtain_dataset() # 主程序
self.obtain_dataloader()
def obtain_dataset(self):
"""
处理数据
:return: 训练集和测试集的索引矩阵
"""
with open(self.raw_data_path, "r", encoding="utf8") as reader:
all_lines = reader.readlines()
# 处理成样本和标签
dataset = []
for line in tqdm(all_lines, desc="处理数据"):
sample_text, sample_label = self.clean_data(line)
dataset.append((sample_text, sample_label))
# 划分训练集和测试集
train_set, test_set = train_test_split(dataset, test_size=0.5, random_state=10) # 选总数据一半作为数据集
train_set, test_set = train_test_split(train_set, test_size=0.15, random_state=10)
# 根据训练集构建vocab
self.build_vocab(train_set)
trainset_idx = self.trans_data(train_set)
testset_idx = self.trans_data(test_set)
return trainset_idx, testset_idx
def obtain_dataloader(self):
"""
根据索引矩阵生产数据的迭代器
:return:
train_dataloader: 训练集迭代器
test_dataloader: 测试集迭代器
"""
train_dataset = MyData(self.trainset_idx)
test_dataset = MyData(self.testset_idx)
# droplast设为True 防止最后一个batch数量不足
self.train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=self.batch_size, drop_last=True,
collate_fn=self.coll_batch)
self.test_dataloader = DataLoader(test_dataset, shuffle=True, batch_size=self.batch_size, drop_last=True,
collate_fn=self.coll_batch)
def clean_data(self, line):
"""
分词并清洗数据
:param line:
:return:
sample_text: ["刘亦菲", "漂亮",“美女”]
label: "娱乐"
"""
text, label = line.split("\t")[0], line.split("\t")[1]
if self.use_char:
sample_text = list(text)
else:
sample_text = jieba.lcut(text)
return sample_text, label
def build_vocab(self, data_info):
"""
构建词汇表字典
:param data_info:
:return:
"""
tokens = []
labels = set()
for text, label in data_info:
tokens.extend(text)
labels.add(label)
tokens = sorted(set(tokens))
tokens.insert(0, "" )
tokens.insert(1, "" )
labels = sorted(labels)
self.word2id = {word:idx for idx, word in enumerate(tokens)}
self.id2word = {idx:word for idx, word in enumerate(tokens)}
self.label2id = {label: idx for idx, label in enumerate(labels)}
self.id2label = {idx: label for idx, label in enumerate(labels)}
def trans_data(self, data_set):
"""
根据词汇表字典将文本转成索引矩阵
:param data_set:
:return:
"""
data_set_idx = []
for text, label in data_set:
text_idx = [self.word2id[word] if word in self.word2id else self.word2id["" ] for word in text]
label_idx = self.label2id[label]
data_set_idx.append((text_idx, label_idx))
return data_set_idx
def coll_batch(self, batch):
"""
对每个batch进行处理
:param batch:
:return:
"""
# 每条样本的长度
current_len = [len(data[0]) for data in batch]
if self.enforced_sorted:
index_sort = list(reversed(np.argsort(current_len)))
batch = [batch[index] for index in index_sort]
current_len = [min(current_len[index], self.max_seq_len) for index in index_sort]
# 对每个batch进行padding
max_length = min(max(current_len), self.max_seq_len)
batch_x = []
batch_y = []
for item in batch:
sample = item[0]
if len(sample) > max_length:
sample = sample[0:max_length]
else:
sample.extend([0] * (max_length-len(sample)))
batch_x.append(sample)
batch_y.append([item[1]])
return {"sample": torch.tensor(batch_x), "label": torch.tensor(batch_y), "length": current_len}
class MyData(Dataset):
def __init__(self, data_set):
self.data = data_set
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return len(self.data)
# if __name__ == '__main__':
# data_obj = BaseData(args=1)
模型构造
本程序只是为了搭建一个分类的流程框架。模型选用了简单的lstm模型。后续可以自己更换其他模型。
lstm_model.py
# -*- coding: utf-8 -*-
"""
@Time : 2022/2/26 14:30
@Auth : hcb
@File :lstm_model.py
@IDE :PyCharm
@Motto:ABC(Always Be Coding)
"""
import torch
import torch.nn as nn
import torch.autograd as autograd
import torch.nn.functional as F
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
class LSTMClassifier(nn.Module):
def __init__(self, args):
super(LSTMClassifier, self).__init__()
self.args = args
self.hidden_dim = args.hidden_dim
self.word_embeddings = nn.Embedding(args.vocab_num, args.embedding_dim)
self.lstm = nn.LSTM(args.embedding_dim, args.hidden_dim, batch_first=True, bidirectional=True)
self.hidden2label = nn.Linear(args.hidden_dim * 2, args.class_num)
self.hidden = self.init_hidden()
def init_hidden(self):
# the first is the hidden h
# the second is the cell c
if self.args.use_cuda:
return (autograd.Variable(torch.zeros(2, self.args.batch_size, self.hidden_dim)).cuda(),
autograd.Variable(torch.zeros(2, self.args.batch_size, self.hidden_dim)).cuda())
else:
return (autograd.Variable(torch.zeros(2, self.args.batch_size, self.hidden_dim)),
autograd.Variable(torch.zeros(2, self.args.batch_size, self.hidden_dim)))
def forward(self, sentence, lengths=None):
""""""
if not lengths:
self.hidden = self.init_hidden()
embeds = self.word_embeddings(sentence)
x = embeds
lstm_out, self.hidden = self.lstm(x, self.hidden)
y = self.hidden2label(lstm_out[:,-1]) # 分类选择所有行的最后一个隐层
log_probs = F.log_softmax(y)
else:
self.hidden = self.init_hidden()
embeds = self.word_embeddings(sentence)
x = embeds
x_pack = pack_padded_sequence(x, lengths, batch_first=True, enforce_sorted=True)
lstm_out, self.hidden = self.lstm(x_pack, self.hidden)
lstm_out, output_lens = pad_packed_sequence(lstm_out, batch_first=True)
y = self.hidden2label(lstm_out[:,-1]) # 分类选择所有行的最后一个隐层
log_probs = F.log_softmax(y)
return log_probs
训练过程
最终是开始训练和测试:
# -*- coding: utf-8 -*-
"""
@Time : 2022/2/26 14:38
@Auth : hcb
@File :trainer.py
@IDE :PyCharm
@Motto:ABC(Always Be Coding)
"""
import argparse
import os
from data_loader import BaseData
from models import lstm_model
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import Adam
from tqdm import tqdm
import torch
from sklearn.metrics import classification_report
def train(args):
# 定义模型优化器 损失函数等
model = lstm_model.LSTMClassifier(args)
if args.use_cuda:
model = model.cuda()
optimizer = Adam(model.parameters(), lr=args.lr)
loss_function = nn.NLLLoss()
train_dataloader = args.dataloader.train_dataloader
test_dataloader = args.dataloader.test_dataloader
model.train()
for epoch in tqdm(range(args.epoch_num)):
print(f"epoch {epoch}...")
for train_info in tqdm(train_dataloader):
optimizer.zero_grad()
# model.hidden = model.init_hidden()
data = train_info["sample"]
label = train_info["label"]
length = train_info["length"]
if args.use_cuda:
data = data.cuda()
label = label.cuda()
# print("data_size", data.size())
predict_label = model(data)
label = label.view(args.batch_size,) # [30, 1] --> [30]
loss_batch = loss_function(predict_label, label)
loss_batch.backward()
# print("loss", loss_batch)
optimizer.step()
print(f"evaluation...epoch_{epoch}:")
true_label, pred_label = [], []
loss_sum = 0.0
with torch.no_grad():
for test_info in test_dataloader:
data = test_info["sample"]
label = test_info["label"]
length = test_info["length"]
# 保存真实标签
label_list = label.view(1, -1).squeeze().numpy().tolist()
true_label.extend(label_list)
if args.use_cuda:
data = data.cuda()
label = label.cuda()
predict_label = model(data)
predict_label_list = torch.argmax(predict_label, dim=1).cpu().numpy().tolist()
pred_label.extend(predict_label_list)
label = label.view(args.batch_size, )
loss_sum += loss_function(predict_label, label)
print(classification_report(true_label, pred_label))
print(f"epoch:{epoch} test data loss: {loss_sum}.")
def main():
args = argparse.ArgumentParser()
args.add_argument("--model", default="lstm", choices=["textcnn", "lstm"])
args.add_argument("--batch_size", type=int, default=50)
args.add_argument("--lr", type=float, default=0.001)
args.add_argument("--max_seq_len", type=int, default=80)
args.add_argument("--enforced_sorted", type=bool, default=True)
args.add_argument("--embedding_dim", type=int, default=128)
args.add_argument("--hidden_dim", type=int, default=128)
args.add_argument("--num_layer", type=int, default=2)
args.add_argument("--epoch_num", type=int, default=5)
args.add_argument("--use_cuda", type=bool, default=True)
args = args.parse_args()
data_load = BaseData(args)
setattr(args, "dataloader", data_load)
setattr(args, "vocab_num", len(data_load.word2id))
setattr(args, "class_num", len(data_load.label2id))
train(args)
if __name__ == '__main__':
main()
备注
程序可以正常运行,后续还会优化扩展。头条数据可以从这里下载:
分类数据