lightGBM有效因子筛选与qlib自定义handler
持续行动1期 48/100,“AI技术应用于量化投资研究”。
lightGBM所代表的集成树模型,优点特别明显,就是快且质量不低,用于量化非常合适。关键它可以筛选因子。
01 重点因子筛选
get_feature_importance()就可以把因子的打分倒序列出来。
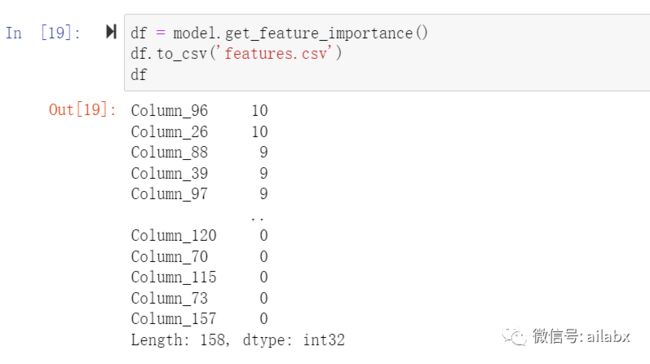
可以看出96和26两个因子得分最高。

这两个因子的公式如下:
当天的动量与成交量的动量之间30日的相关性:
Corr($close/Ref($close,1), Log($volume/Ref($volume, 1)+1), 30)
30天价格的标准差与价格之比:
Std($close, 30)/$close
02 自定义handler
alpha158是qlib内置的handler,为了方便,我们直接使用dataloader来加域数据,便于增删因子。
def load_dataset2(features):
feature_tuple = features
label_tuple = (["Ref($close, -2)/Ref($close, -1) - 1"], ["LABEL0"])
qdl = QlibDataLoader(config={
'feature': feature_tuple,
'label': label_tuple,
})
data_handler_config = {
"start_time": "2010-01-01",
"end_time": "2020-08-01",
"instruments": 'csi300',
}
dh = DataHandlerLP(data_loader=qdl, **data_handler_config,
)
ds = DatasetH(dh, segments=segments)
return ds
使用自己的dataset后出现了比较“诡异”的结果,就是无论如何增减因子,pred_score都是一样的,自然就没有结果。
查明原因如下,需要对label列去除na, 并且CSZScoreNorm正则化。
_DEFAULT_LEARN_PROCESSORS = [
{"class": "DropnaLabel"},
{"class": "CSZScoreNorm", "kwargs": {"fields_group": "label"}},
]
03 qlib模型的思考
qlib内置了model zoo,但从实际上看,因子挖掘才是最重要的,而不是model。简单对比了lightGBM和xgboost,没有什么特别。
之前看了kaggle竞赛获奖的一些model,都是针对数据进行了优化,但不是模型层面的,对于表格型的数据,使用GBDT这样的树模型比深度学习无论从效率上,可解释性上都有优势。
这里会引出一个结论,就是我们一直在提的,qlib还重要吗?框架到底有没有引入负担。框架一定会引入负担,就看我们想怎么用了。
从交易的视角qlib不符合,qlib更像机器学习的“科研”项目。
更合适的场景,我可能选定一个股票池,甚至是电子货币,然后对其标注,然后使用模型进行训练,能够指导买卖。另外,完全没必要每天都满仓,现在qlib就是满仓轮动,这个也很奇怪。
核心逻辑——找到更好的数据来源,比如另类数据;找到更好的因子——因子挖掘能力。模型也许会提升一点点,对于大的私募机构有用,对于普通散户,意义有限。
04 “杠铃”模式
塔勒布专门研究随机性,不确定性,他是交易员出身的学者。
他研究不确定性的同时,还赚到大钱,这才是人生赢家——真正的躬身入局。
他给出一个很好的启发:前面的分享我们说ABZ计划,B计划让普通人有机会探索更多的可能性,而“杠铃”模式的启发是,让B计划有实现阶段跃迁的可能性。
理性的我们总在规避风险,这是对的。比如不碰P2P,BTC。但是,如果从杠铃模式的角度,这不是最优的。是规避的风险,但人生也很平庸。把90%的资源用于追求平稳,而用10%去拥抱高收益的事情。如果你的仓位是100万,那么10万本金参与电子货币,也许是可以的。
——梦想还是要有的,万一实现了呢?
