Qlib来啦:策略篇(一)

量化投资与机器学习微信公众号,是业内垂直于量化投资、对冲基金、Fintech、人工智能、大数据等领域的主流自媒体。公众号拥有来自公募、私募、券商、期货、银行、保险、高校等行业30W+关注者,荣获2021年度AMMA优秀品牌力、优秀洞察力大奖,连续2年被腾讯云+社区评选为“年度最佳作者”。
完整源代码请点击阅读原文
在QIML公众号官方GitHub查看
QIML官方GitHub上线
https://github.com/QuantWorld2022
希望大家多Follow,多给星⭐️
历史推文
Qlib来啦:数据篇(一)

Qlib来啦:数据篇(二)

Qlib来啦:模型训练篇

前言
在之前的文章中,我们介绍了使用配置文件进行模型训练。一个典型的配置文件中,主要由两大部分组成:
qlib_init:指定数据存储的位置
task:训练任务的详细配置,主要包括model, dataset, record的配置
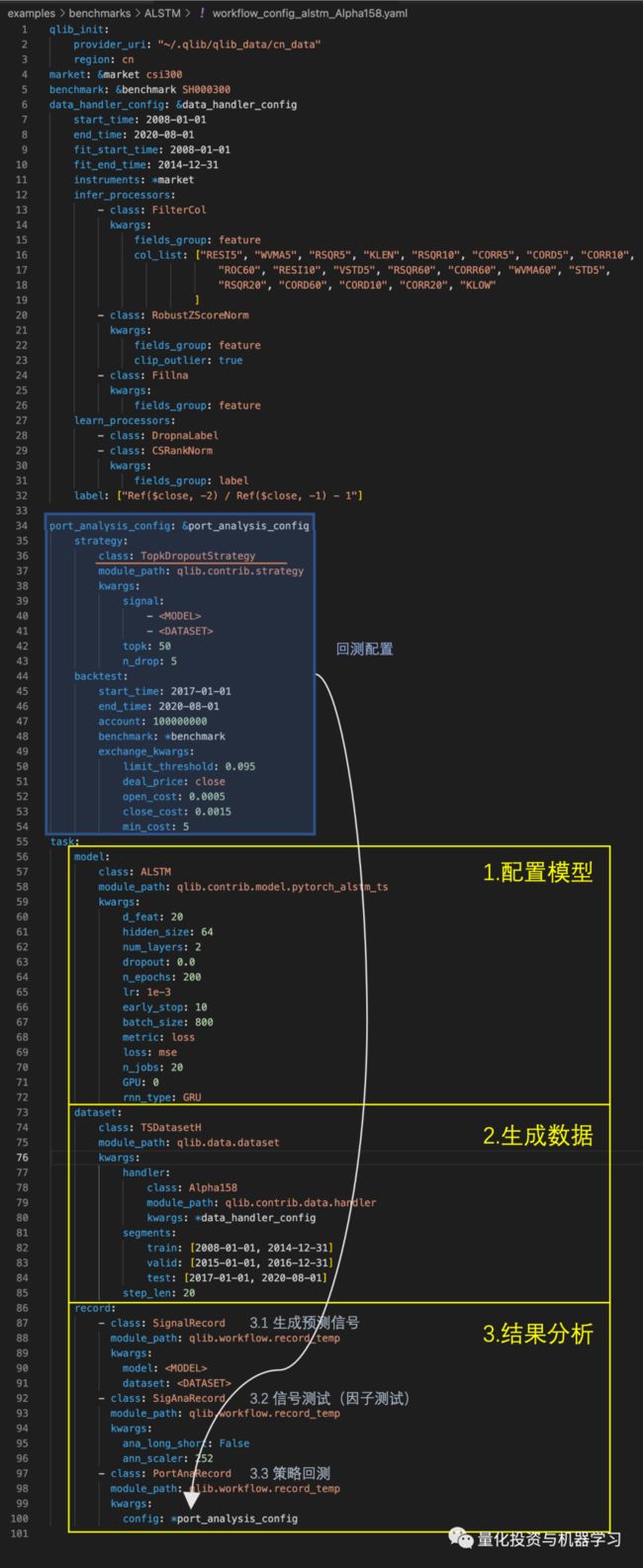
如下图标示,task中三个核心的配置,也正是研究的三个主要步骤:
在model中详细定义需要训练的模型;
在dataset中详细定义股票池、特征及训练目标等信息;
record部分主要用于定义模型训练完之后,对结果进行分析的流程。针对多因子量化研究的场景,一个典型的结果分析流程包括:
使用SignalRecord,针对测试集数据,使用训练完的模型生成预测值;
使用SigAnaRecord,对预测结果进行因子分析,计算IC、ICIR等指标;
使用PortAnaRecord,对预测结果进行策略回测,如下图中使用了Qlib内置的TopKDropout策略,计算策略回测的绩效指标。
回测结果
运行完PortAnaRecord,回测结果会存储在mlruns文件夹下的以下文件中:
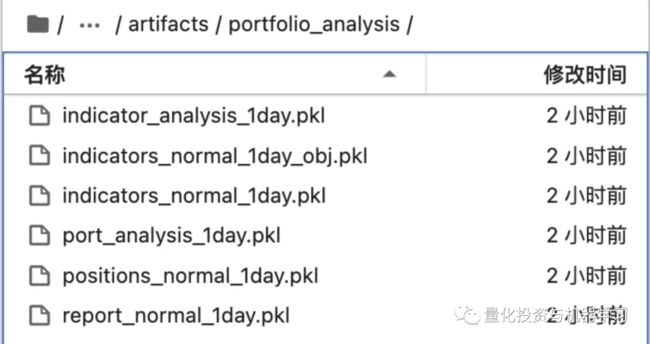
我们可以使用recorder读取回测结果:
from qlib.workflow import R
R.list_experiments() # 列出当前所有experiments
recorder = R.get_recorder(recorder_id='ff8c69f711204e8a9ea57ad165b09f25', experiment_name="gbdt_csi300_test")
# RankIc序列
recorder.load_object('sig_analysis/ric.pkl')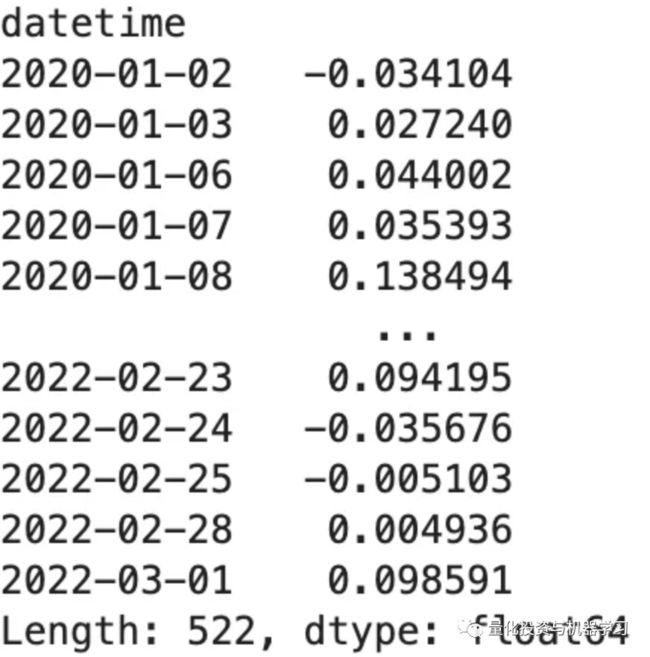
# 回测报告(净值,交易成本等)
recorder.load_object('portfolio_analysis/report_normal_1day.pkl')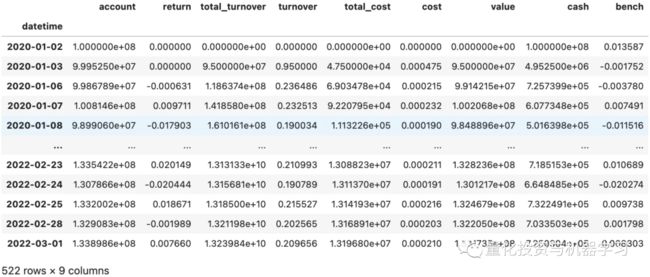
关于策略类-BaseStrategy
在上面的回测中,使用了Qlib内置的TopKDropout策略。Qlib中策略的实现需要继承策略的基类BaseStrategy,策略的核心逻辑需要在generate_trade_decision的函数中实现。BaseStrategy有三个重要的属性:
level_infra: LevelInfrastructure, 一些通用的基础组件,比如交易日历trader_calendar
common_infra: CommonInfrastructure, 通过它可以获得当前持仓trade_position,及交易所组件exchange
trade_exchange:交易所组件
当前,我们只需要知道,这些属性主要是为了策略回测过程中获取相关信息所用。回测时会自动创建这些组件。
@property
def trade_calendar(self) -> TradeCalendarManager:
return self.level_infra.get("trade_calendar")
@property
def trade_position(self) -> BasePosition:
return self.common_infra.get("trade_account").current_position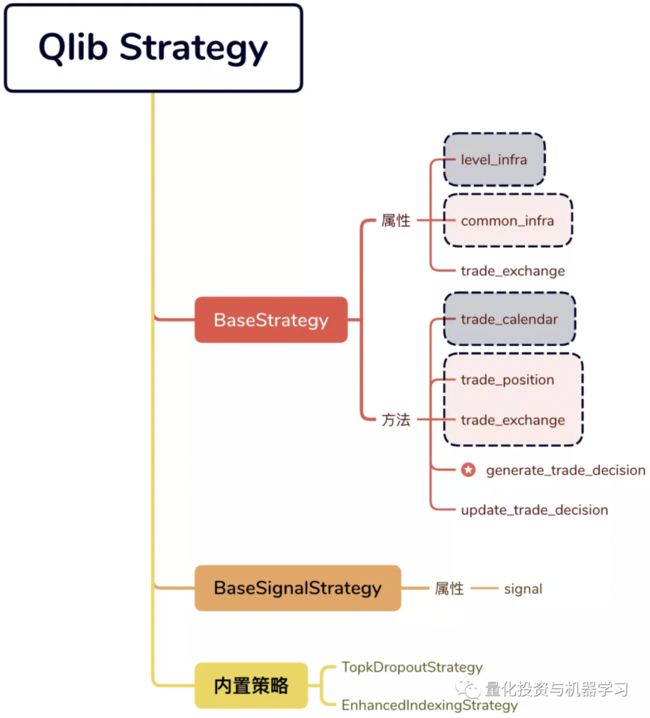
当我们看TopKDropout的源码时,我们发现TopKDropout是继承自BaseSignalStrategy。BaseSignalStrategy也是BaseStrategy的一个子类,它与BaseStrategy最大的区别是属性中增加了signal,signal就是某个时间对某个股票的预测,比如上面预测结果pred就是signal:
df_signal = recorder.load_object('pred.pkl')
df_signal.head()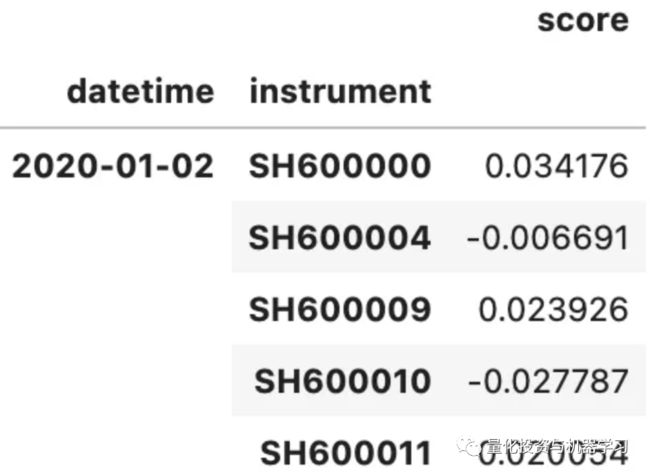
Signal
BaseSignalStrategy在初始化时,signal参数可以接受多种形式,但最终都会由create_signal_from转化成Signal类。Signal类的下有一个重要的方法get_signal,用在策略回测过程中获取指定时间的预测信号。
from qlib.contrib.strategy.signal_strategy import create_signal_from
signal = create_signal_from(df_signal)
signal.get_signal('2020-01-10', '2020-01-10')学习TopkDropoutStrategy源码
分析一下TopkDropoutStrategy策略的源码,最核心的就是generate_trade_decision。如果大家熟悉常用的回测框架,如zipline,就可以把generate_trade_decision看作是zipline里的handle_data。在回测时,历史上每一天都会调用该方法,并返回TradeDecisionWO(可以看做是Order列表),策略执行器(BaseExecutor)会根据TradeDecisionWO执行交易并更新当前账户信息及持仓,并把这次的执行结果(execute_result)返回给策略。以下是简化的运行流程:
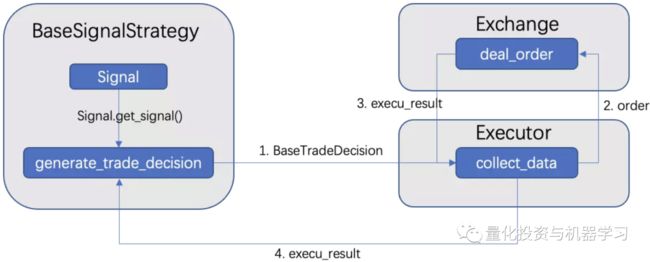
如果要实现自定义策略,就需要完成以下三个步骤:
1、继承BaseSignalStrategy
2、实现generate_trade_decision
3、把每日的Order通过TradeDecisionWO返回
仅使用策略回测功能
得益于Qlib的松耦合设计,我们可以单独使用策略回测功能。在分析PorAnaRecord的源码时,我们发现其中回测调用了qlib.backtest.backtest函数。这个函数除了一些基本的回测设置参数外,还需要传入策略strategy和执行器executor。
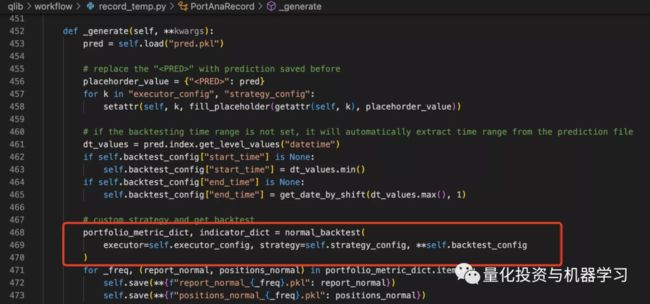
backtest函数具体的调用路径如下,可以看到在最后一步collect_data_loop的源码,就是我们在学习TopkDropoutStrategy源码文中作图展示的逻辑。
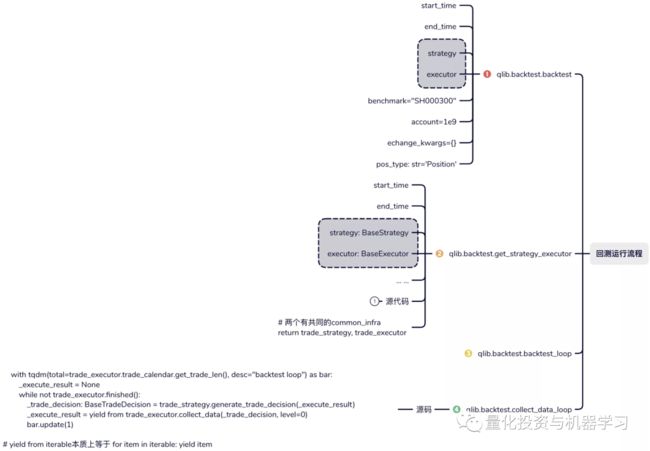
backtest中必须要传入executor,但在qlib.contrib.evaluate.backtest_daily中,对backtest进行了进一步的包装。其内部默认实例化一个简单的SimulatorExecutor,所以如果需要单独进行策略回测可以直接使用backtest_daily。下面我们看一个例子:
from pprint import pprint
import pandas as pd
from qlib.utils.time import Freq
from qlib.utils import flatten_dict
from qlib.contrib.evaluate import backtest_daily
from qlib.contrib.evaluate import risk_analysis
from qlib.contrib.strategy import TopkDropoutStrategy
CSI300_BENCH = "SH000300"
STRATEGY_CONFIG = {
"topk": 50,
"n_drop": 5,
# pred_score, pd.Series
"signal": df_signal,
}
strategy_obj = TopkDropoutStrategy(**STRATEGY_CONFIG)
report_normal, positions_normal = backtest_daily(
start_time="2020-01-02", end_time="2022-03-01", strategy=strategy_obj
)
analysis = dict()
# default frequency will be daily (i.e. "day")
analysis["excess_return_without_cost"] = risk_analysis(report_normal["return"] - report_normal["bench"])
analysis["excess_return_with_cost"] = risk_analysis(report_normal["return"] - report_normal["bench"] - report_normal["cost"])
analysis_df = pd.concat(analysis) # type: pd.DataFrame
pprint(analysis_df)总结
1、Qlib中的策略基于BaseStrategy实现,BaseStrategy可以通过level_infra和common_infra获得账户信息及交易日历等;
2、如果在模型训练过程中直接进行策略回测分析,可以使用PortAnaRecord;
3、策略回测功能也可以单独使用,需要以下几个步骤:
准备需要回测的策略
调用backtest_daily函数
Qlib中还有指数增加策略,运行时需要因子暴露/风险模型/组合优化器,这些qlib都进行了实现,下一篇我们详细分享qlib中的指数增强策略。
完整源代码请点击阅读原文
在QIML公众号官方GitHub查看
QIML官方GitHub上线
https://github.com/QuantWorld2022
希望大家多Follow,多给星⭐️