条件随机场CRF(持续更新ing...)
诸神缄默不语-个人CSDN博文目录
本文是作者学习CRF后的笔记。
最近更新时间:2022.11.17
最早更新时间:2022.11.15
条件随机场CRF是适宜于顺序预测任务的判别模型,可用于命名实体识别、词性标注等。
文章目录
- 1. linear-chain CRF
- 2. CRF目标函数
- 本文撰写过程中使用到的其他参考资料
1. linear-chain CRF
在序列预测任务中,用邻近(上下文)样本来辅助学习当前样本。
以Part-of-Speech Tagging任务为例:
任务示例:输入Bob drank coffee at Starbucks,标记为Bob (NOUN) drank (VERB) coffee (NOUN) at (PREPOSITION) Starbucks (NOUN)
本节限制特征仅取决于当前和前一个标签,而非句中任一标签:
特征函数feature function f i f_i fi(需要一堆):
- 输入:
- 句子 s s s
- 词语在句中的位置 i i i
- 当前词的标签 l i l_i li
- 前一个词的标签 l i − 1 l_{i-1} li−1
- 输出:实数(如0/1)
给每个feature function f j f_j fj分配一个权重 λ j \lambda_j λj
给出一个句子 s s s,对labeling的打分方式是对所有单词的所有feature function求和:
s c o r e ( l ∣ s ) = ∑ j = 1 m ∑ i = 1 n λ j f j ( s , i , l i , l i − 1 ) score(l | s) = \sum_{j = 1}^m \sum_{i = 1}^n \lambda_j f_j(s, i, l_i, l_{i-1}) score(l∣s)=j=1∑mi=1∑nλjfj(s,i,li,li−1)
将所有labeling的打分转换为概率(通过exponentiating and normalizing,即softmax):
p ( l ∣ s ) = e x p [ s c o r e ( l ∣ s ) ] ∑ l ’ e x p [ s c o r e ( l ’ ∣ s ) ] = e x p [ ∑ j = 1 m ∑ i = 1 n λ j f j ( s , i , l i , l i − 1 ) ] ∑ l ’ e x p [ ∑ j = 1 m ∑ i = 1 n λ j f j ( s , i , l ’ i , l ’ i − 1 ) ] p(l | s) = \frac{exp[score(l|s)]}{\sum_{l’} exp[score(l’|s)]} = \frac{exp[\sum_{j = 1}^m \sum_{i = 1}^n \lambda_j f_j(s, i, l_i, l_{i-1})]}{\sum_{l’} exp[\sum_{j = 1}^m \sum_{i = 1}^n \lambda_j f_j(s, i, l’_i, l’_{i-1})]} p(l∣s)=∑l’exp[score(l’∣s)]exp[score(l∣s)]=∑l’exp[∑j=1m∑i=1nλjfj(s,i,l’i,l’i−1)]exp[∑j=1m∑i=1nλjfj(s,i,li,li−1)]
Example Feature Functions:

CRF概率长得像逻辑回归→CRF就是逻辑回归的序列版:whereas logistic regression is a log-linear model for classification, CRFs are a log-linear model for sequential labels.
CRF和HMM:

算出CRF模型后,应用在新的句子上:
原始方法——算出所有 p ( l ∣ s ) p(l | s) p(l∣s)的值:太慢了
(polynomial-time) dynamic programming algorithm(由于linear-chain CRFs满足 optimal substructure 特性)(类似HMM的维特比算法)
2. CRF目标函数
在第一节中我们得到了:
p ( l ∣ s ) = e x p [ ∑ j = 1 m ∑ i = 1 n λ j f j ( s , i , l i , l i − 1 ) ] ∑ l ’ e x p [ ∑ j = 1 m ∑ i = 1 n λ j f j ( s , i , l ’ i , l ’ i − 1 ) ] p(l | s)= \frac{exp[\sum_{j = 1}^m \sum_{i = 1}^n \lambda_j f_j(s, i, l_i, l_{i-1})]}{\sum_{l’} exp[\sum_{j = 1}^m \sum_{i = 1}^n \lambda_j f_j(s, i, l’_i, l’_{i-1})]} p(l∣s)=∑l’exp[∑j=1m∑i=1nλjfj(s,i,l’i,l’i−1)]exp[∑j=1m∑i=1nλjfj(s,i,li,li−1)]
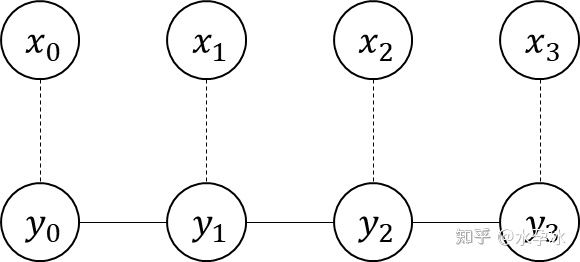
将 ∑ i = 1 n f j ( s , i , l ’ i , l ’ i − 1 ) ] \sum_{i = 1}^nf_j(s, i, l’_i, l’_{i-1})] ∑i=1nfj(s,i,l’i,l’i−1)]记为 f j ( x , y ) f_j(x,y) fj(x,y)(s,l)
CRF模型的定义式:
P ( y ∣ x ) = 1 Z ( x ) exp [ ∑ j λ j ( f j ( x , i ) ) ] P(y|x)=\frac{1}{Z(x)}\exp\Big[\sum_j\lambda_j\big(f_j(x,i)\big)\Big] P(y∣x)=Z(x)1exp[j∑λj(fj(x,i))]
(其中 Z ( x ) = ∑ y [ ∑ j λ j ( f j ( x , i ) ) ] Z(x)=\sum_y\Big[\sum_j\lambda_j\big(f_j(x,i)\big)\Big] Z(x)=∑y[∑jλj(fj(x,i))],可以看作所有可能的隐状态序列的score值之和)
我们的最终目标是找到能使得score值最大( P ( y ∣ x ) P(y|x) P(y∣x)最大)的隐状态序列。在定义好feature functions后,我们需要学习 λ \lambda λ
用梯度学习优化feature function的权重:
- 有一组句子-POS标签,随机初始化CRF权重
- 梯度下降
- 对每个feature function f i f_i fi,计算样本的 log p \log p logp关于 λ i \lambda_i λi的梯度: ∂ ∂ w j log p ( l ∣ s ) = ∑ j = 1 m f i ( s , j , l j , l j − 1 ) − ∑ l ’ p ( l ’ ∣ s ) ∑ j = 1 m f i ( s , j , l ’ j , l ’ j − 1 ) \frac{\partial}{\partial w_j} \log p(l | s) = \sum_{j = 1}^m f_i(s, j, l_j, l_{j-1}) - \sum_{l’} p(l’ | s) \sum_{j = 1}^m f_i(s, j, l’_j, l’_{j-1}) ∂wj∂logp(l∣s)=∑j=1mfi(s,j,lj,lj−1)−∑l’p(l’∣s)∑j=1mfi(s,j,l’j,l’j−1)
- 上式第一项是 f i f_i fi在真实标签下的贡献,第二项是在当前模型下的。(我们希望模型学到的VS模型当前状态)(其实我有点没看懂这啥意思)
- λ i = λ i + α [ ∑ j = 1 m f i ( s , j , l j , l j − 1 ) − ∑ l ’ p ( l ’ ∣ s ) ∑ j = 1 m f i ( s , j , l ’ j , l ’ j − 1 ) ] \lambda_i = \lambda_i + \alpha [\sum_{j = 1}^m f_i(s, j, l_j, l_{j-1}) - \sum_{l’} p(l’ | s) \sum_{j = 1}^m f_i(s, j, l’_j, l’_{j-1})] λi=λi+α[∑j=1mfi(s,j,lj,lj−1)−∑l’p(l’∣s)∑j=1mfi(s,j,l’j,l’j−1)]( α \alpha α是学习率)
本文撰写过程中使用到的其他参考资料
- Introduction to Conditional Random Fields(一篇国内的翻译:如何轻松愉快地理解条件随机场(CRF)? - 知乎
- 看了一半:全网最详细的CRF算法讲解 - 知乎
- 还没看
- 概率图之马尔可夫随机场(Markov Random Field,MRF)_zxhohai的博客-CSDN博客_markov random field
- 读懂概率图模型:你需要从基本概念和参数估计开始
- CRF条件随机场的原理、例子、公式推导和应用 - 知乎
- 全方位理解条件随机场(CRF):原理、应用举例、CRF++实现 - 知乎
- 条件随机场的肤浅理解_Researcher-Du的博客-CSDN博客_densecrf论文
- PGM:概率图模型Graphical Model_-柚子皮-的博客-CSDN博客_graphical model
- 马尔可夫随机场 MRF_-柚子皮-的博客-CSDN博客
- 【PGM】factor graph,因子图,势函数potential function,Template models - Loull - 博客园
- CRF和HMM_baihaisheng的博客-CSDN博客_crf hmm
- CRF(条件随机场)_二叉树不是树_ZJY的博客-CSDN博客
- Linear-chain CRF的推导 - 简书
- 没看懂的
- 条件随机场(CRF)的详细解释_deephub的博客-CSDN博客_crf
- 排版有问题的
- 自然语言处理序列模型——CRF条件随机场-51CTO.COM:缺公式
- 条件随机场入门:有错别字