coggle1-2月打卡之LightGBM实战
文章目录
-
-
- 任务1:模型训练与预测
- 任务2:模型保存与加载
- 任务3:分类、回归和排序任务
- 任务4:可视化树模型
- 任务5:模型调参(网格、随机、贝叶斯)
-
- 使用categorical_feature
- 不使用category_feature时
- 任务6:模型微调与参数衰减
- 任务7:特征筛选方法
- 任务8:自定义损失函数
- 任务9:模型部署与加速(可选,不参与积分)
-
任务1:模型训练与预测
- 步骤1:导入
LightGBM库 - 步骤2:使用
LGBMClassifier对iris进行训练。 - 步骤3:将预测的模型对iris进行预测。
# 安装LightGBM
!pip install lightgbm
# 导入
import lightgbm as lgb
import pandas as pd
import json
from sklearn import datasets
# 导入鸢尾花数据集
iris = datasets.load_iris()
iris.data.shape
#构建数据集
from sklearn.model_selection import train_test_split as TTS
#将iris划分为训练集和测试机
train_data_all,test_data, train_y_all, test_y = TTS(iris.data, iris.target, test_size=0.2, random_state=42, shuffle=True)
train_data, val_data, train_y, val_y = TTS(train_data_all, train_y_all, test_size=0.2, random_state=42, shuffle=True)
train_data.shape
#构建LGB的训练集
lgb_train = lgb.Dataset(train_data, train_y)
lgb_val = lgb.Dataset(val_data, val_y)
#设置模型参数
params = {
"objective":"multiclass",
"num_classes":3,
"verbosity":-1
}
# 训练模型
booster = lgb.train(params, train_set=lgb_train, valid_sets=lgb_val, num_boost_round=10)
## 结果:
#[1] valid_0's multi_logloss: 0.998257
#[2] valid_0's multi_logloss: 0.87888
#[3] valid_0's multi_logloss: 0.802809
#[4] valid_0's multi_logloss: 0.723778
#[5] valid_0's multi_logloss: 0.65558
#[6] valid_0's multi_logloss: 0.60953
#[7] valid_0's multi_logloss: 0.553635
#[8] valid_0's multi_logloss: 0.499817
#[9] valid_0's multi_logloss: 0.471947
#[10] valid_0's multi_logloss: 0.438747
#[11] valid_0's multi_logloss: 0.404308
#[12] valid_0's multi_logloss: 0.387417
#使用训练的模型对iris进行预测
from sklearn.metrics import accuracy_score
import numpy as np
train_preds = np.argmax(booster.predict(train_data), axis=1)
test_preds = np.argmax(booster.predict(test_data), axis=1)
#测试结果
print("Train Accuracy Score: %.2f"%accuracy_score(train_y, train_preds))
print("Test Accuracy Score: %.2f"%accuracy_score(test_y, test_preds))
# 结果:
# Train Accuracy Score: 0.96
# Test Accuracy Score: 0.97
任务2:模型保存与加载
参考资料
- 步骤1 :将任务1训练得到的模型,使用pickle进行保存。
- 步骤2 :将任务1训练得到的模型,使用txt进行保存。
- 步骤3 :加载步骤1和步骤2的模型,并进行预测。
#模型保存
import pickle
pickle.dump(booster,open('model.pickle','wb'))
#使用txt进行保存
booster.save_model('model.txt')
#加载模型,并进行预测
model_pickle = pickle.load(open('model.pickle','rb'))
y_pred_pickle = np.argmax(model_pickle.predict(test_data), axis=1)
print("y_pred_pickle:",y_pred_pickle)
# txt读取
model_txt = lgb.Booster(model_file='model.txt')
y_pred_txt = np.argmax(model_txt.predict(test_data), axis=1)
print("y_pred_txt:",y_pred_txt)
#output->
# y_pred_pickle: [1 0 2 1 2 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0]
# y_pred_txt: [1 0 2 1 2 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0]
任务3:分类、回归和排序任务
https://github.com/microsoft/LightGBM/blob/master/examples/python-guide/sklearn_example.py
https://github.com/microsoft/LightGBM/blob/master/examples/python-guide/simple_example.py
-
步骤1 :学习
LightGBM中sklearn接口的使用,导入分类、回归和排序接口。 -
步骤2 :学习
LightGBM中原生train接口的使用。 -
步骤3 :二分类任务
-
使用make_classification,创建一个二分类数据集。
-
使用sklearn接口完成训练和预测。
-
使用原生train接口完成训练和预测。
TwoClassData = make_classification(n_samples=10000,n_features=20,
n_informative=2,
n_redundant=0,
n_repeated=0,
n_classes=2,
n_clusters_per_class=2,
# weights=[0.05,0.1,0.1,0.5],
flip_y=0.4,
class_sep=1.0,
hypercube=True,
shift=0.0,
scale=1.0,
shuffle=True,
random_state=420)
# 划分测试集和验证集
from sklearn.model_selection import train_test_split as TTS
TDF = pd.DataFrame(TwoClassData[0])
TDF['label'] = TwoClassData[1]
print(TDF.label.value_counts())
X_train, X_val, y_train, y_val = TTS(TDF.drop(['label'], axis=1), TDF.label, test_size=0.3, random_state=42)
# 使用原生的LGBM API需要将数据转换成lgbm中Datasets格式,如下:
lgb_train = lgb.Dataset(X_train, y_train)
lgb_validate = lgb.Dataset(X_val, y_val)
from sklearn.metrics import accuracy_score
#使用原生API
params_naive = {
"learning_rate":0.1,
"max_bin":150,
"num_leaves":32,
"max_depth":11,
"lambda_l1":0.1,
"lambda_l2":0.2,
"objective":"binary",
# "num_class":2,
"verbose": -1 # <0 显示致命的, =0 显示错误 (警告), >0 显示信息
}
model = lgb.train(params=params_naive, train_set=lgb_train, num_boost_round=300, valid_sets=[lgb_train, lgb_validate], callbacks=[early_stopping(10), log_evaluation(10)])
#Save the model
model.save_model('model_classifier_lgb,txt')
#Load the model
# model = lgb.Booster(model_file='model_classifier_lgb.txt')
#predict the X_val data
y_pred = model.predict(X_val)
y_pred = y_pred.flatten()
# extract the predicted class labels
y_pred = np.where(y_pred > 0.5, 1, 0)
#metirc the model
print("The accuracy score of prediction is ", accuracy_score(y_val, y_pred))
# 正确率有点低!!
#Using sklearn API
params_sklearn = {
'learning_rate':0.1,
'max_bin':150,
'num_leaves':32,
'max_depth':11,
'reg_alpha':0.1,
'reg_lambda':0.2,
'objective':'binary',
'n_estimators':300,
'verbose':-1
}
watchlist = [(X_train, y_train), (X_val, y_val)]
#Using sklearn API to train the model
clf = lgb.LGBMClassifier(**params_sklearn)
clf.fit(X_train, y_train, eval_set=watchlist, callbacks=[early_stopping(10), log_evaluation(10)])
# save the model
# clf.save_model("model_classifier_sklearn.txt")
# load the model
# clf = lgb.Booster('model_classifier_sklearn.txt')
# predict the X_val data
y_pred_sklearn = clf.predict(X_val)
#metirc the model
print("The accuracy score of prediction is ", accuracy_score(y_val, y_pred_sklearn))
-
步骤4 :多分类任务
-
使用make_classification,创建一个多分类数据集。
-
使用sklearn接口完成训练和预测。
-
使用原生train接口完成训练和预测。
data = make_classification(n_samples=10000,n_features=20,
n_informative=4,
n_redundant=2,
n_repeated=0,
n_classes=5,
n_clusters_per_class=2,
weights=[0.05,0.1,0.1,0.5],
flip_y=0.4,
class_sep=1.0,
hypercube=True,
shift=0.0,
scale=1.0,
shuffle=True,
random_state=420)
# 划分测试集和验证集
from sklearn.model_selection import train_test_split as TTS
df = pd.DataFrame(data[0])
df['label'] = data[1]
print(df.label.value_counts())
X_train, X_val, y_train, y_val = TTS(df.drop(['label'], axis=1), df.label, test_size=0.3, random_state=42)
# 使用原生的LGBM API需要将数据转换成lgbm中Datasets格式,如下:
lgb_train = lgb.Dataset(X_train, y_train)
lgb_validate = lgb.Dataset(X_val, y_val)
from sklearn.metrics import accuracy_score
#使用原生API
params_naive = {
"learning_rate":0.1,
"max_bin":150,
"num_leaves":32,
"max_depth":11,
"lambda_l1":0.1,
"lambda_l2":0.2,
"objective":"multiclass",
"num_class":5,
"verbose": -1 # <0 显示致命的, =0 显示错误 (警告), >0 显示信息
}
model = lgb.train(params=params_naive, train_set=lgb_train, num_boost_round=300, valid_sets=[lgb_train, lgb_validate], callbacks=[early_stopping(10), log_evaluation(10)])
#Save the model
model.save_model('model_classifier_lgb,txt')
#Load the model
# model = lgb.Booster(model_file='model_classifier_lgb.txt')
#predict the X_val data
y_pred = np.argmax(model.predict(X_val), axis=1)
#metirc the model
print("The accuracy score of prediction is ", accuracy_score(y_val, y_pred))
# Using sklearn API
params_sklearn = {
'learning_rate':0.1,
'max_bin':150,
'num_leaves':32,
'max_depth':11,
'reg_alpha':0.1,
'reg_lambda':0.2,
'objective':'multiclass',
'n_estimators':300,
'verbose':-1
}
watchlist = [(X_train, y_train), (X_val, y_val)]
#Using sklearn API to train the model
clf = lgb.LGBMClassifier(**params_sklearn)
clf.fit(X_train, y_train, eval_set=watchlist, callbacks=[early_stopping(10), log_evaluation(10)])
# save the model
# clf.save_model("model_classifier_sklearn.txt")
# load the model
# clf = lgb.Booster('model_classifier_sklearn.txt')
# predict the X_val data
y_pred_sklearn = clf.predict(X_val)
#metirc the model
print("The accuracy score of prediction is ", accuracy_score(y_val, y_pred_sklearn))
-
步骤5:回归任务
-
使用make_regression,创建一个回归数据集。
-
使用sklearn接口完成训练和预测。
-
使用原生train接口完成训练和预测。
from sklearn.datasets import make_regression
X, Y = make_regression(n_samples=10000, n_features=20, n_targets=1, noise=1.5, random_state=420)
X = pd.DataFrame(X)
Y = pd.DataFrame(Y)
X_train, X_val, y_test, y_val = TTS(X, Y, test_size=0.3, random_state=420, shuffle=True)
from sklearn.metrics import mean_absolute_error as mae
#LGB API
params_lgb = {
'boosting_type': 'gbdt',
'objective':'mae',
'n_jobs':8,
'subsample': 0.5,
'subsample_freq': 1,
'learning_rate': 0.01,
'num_leaves': 2**11-1,
'min_data_in_leaf': 2**12-1,
'feature_fraction': 0.5,
'max_bin': 100,
'n_estimators': 2500,
'boost_from_average': False,
"random_seed":420,
"verbose": -1 # <0 显示致命的, =0 显示错误 (警告), >0 显示信息
}
lgb_train = lgb.Dataset(X_train, y_train)
lgb_validate = lgb.Dataset(X_val, y_val)
reg_lgb = lgb.train(params=params_lgb, train_set=lgb_train, valid_sets=[lgb_train, lgb_validate], num_boost_round=300,callbacks=[early_stopping(10), log_evaluation(10)])
# save the model
reg_lgb.save_model('reg_lgb.txt')
# load the model
# reg_lgb = lgb.Booster('reg_lgb.txt')
# predict the result
y_pred = reg_lgb.predict(X_val)
#metrics the model
print("The mse of the model is",mae(y_val, y_pred)**0.5)
params_sklearn = {
'boosting_type': 'gbdt',
'objective':'mae',
'n_jobs':8,
'subsample': 0.5,
'subsample_freq': 1,
'learning_rate': 0.01,
'num_leaves': 2**11-1,
'min_data_in_leaf': 2**12-1,
'feature_fraction': 0.5,
'max_bin': 100,
'n_estimators': 2500,
'boost_from_average': False,
"random_seed":420,
"verbose": -1 # <0 显示致命的, =0 显示错误 (警告), >0 显示信息
}
reg_sklearn = lgb.LGBMRegressor(**params_sklearn)
reg_sklearn.fit(X_train, y_train,
eval_set=[(X_val, y_val)],
callbacks=[early_stopping(100), log_evaluation(100)])
y_pred_sklearn = reg_sklearn.predict(X_val)
print("The mse of the model is",mae(y_val, y_pred_sklearn)**0.5)
任务4:可视化树模型
参考:决策树模型,XGBoost,LightGBM和CatBoost模型可视化
1、首先安装graphviz
使用pip install python-graphviz进行直接安装,后续不需要再将graphviz添加到环境变量中。(如果仍然报错,可以将graphviz包下的bin文件夹路径添加到系统PATH中,WIN+R输入cmd进入命令行后输入dot -version,没报错的话则说明添加到系统PATH成功,此时重启 Jupyter Lab 或 Jupyter Notebook即可。
2、LightGBM模型可视化
在lgb中,对应的可视化函数是lightgbm.create_tree_digraph。以iris数据为例,训练一个lgb分类模型并可视化。
#导入库
import lightgbm as lgb
import pandas as pd
import numpy as np
import graphviz
from sklearn import tree
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split as TTS
from sklearn.metrics import accuracy_score
# 导入鸢尾花数据集
iris = load_iris()
target = iris.target
feature_names = ["calyx length", "calyx width", "petal length", "petal width"]
data = pd.DataFrame(iris.data, columns=feature_names)
data
#将iris划分为训练集和测试机
train_data_all,test_data, train_y_all, test_y = TTS(data, target, test_size=0.2, random_state=42, shuffle=True)
train_data, val_data, train_y, val_y = TTS(train_data_all, train_y_all, test_size=0.2, random_state=42, shuffle=True)
#构建LGB的训练集
lgb_train = lgb.Dataset(train_data, train_y)
lgb_val = lgb.Dataset(val_data, val_y)
#设置模型参数
params = {
"objective":"multiclass",
"num_classes":3,
"verbosity":-1
}
# 训练模型
booster = lgb.train(params, train_set=lgb_train, valid_sets=lgb_val, num_boost_round=12)
#使用训练的模型对iris进行预测
train_preds = np.argmax(booster.predict(train_data), axis=1)
test_preds = np.argmax(booster.predict(test_data), axis=1)
#测试结果
print("Train Accuracy Score: %.2f"%accuracy_score(train_y, train_preds))
print("Test Accuracy Score: %.2f"%accuracy_score(test_y, test_preds))
#绘制特征重要程度图
ax = lgb.plot_importance(booster)
plt.show;
#可视化分类树模型
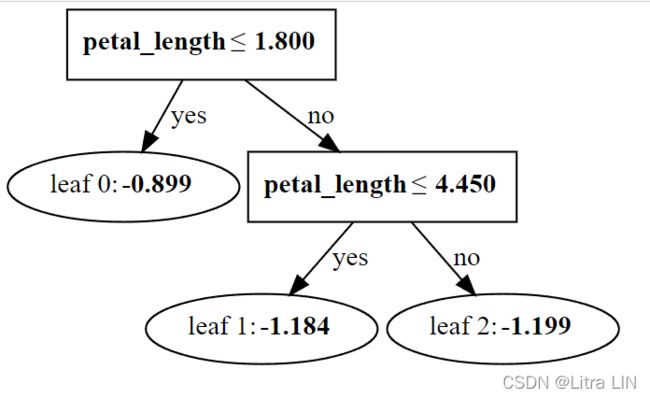
lgb.create_tree_digraph(booster, tree_index=0,orientation='vertical')

任务5:模型调参(网格、随机、贝叶斯)
- 步骤1 :运行以下代码得到训练集和验证集
import pandas as pd, numpy as np, time
from sklearn.model_selection import train_test_split
# 读取数据
data = pd.read_csv("https://cdn.coggle.club/kaggle-flight-delays/flights_10k.csv.zip")
# 提取有用的列
data = data[["MONTH","DAY","DAY_OF_WEEK","AIRLINE","FLIGHT_NUMBER","DESTINATION_AIRPORT",
"ORIGIN_AIRPORT","AIR_TIME", "DEPARTURE_TIME","DISTANCE","ARRIVAL_DELAY"]]
data.dropna(inplace=True)
# 筛选出部分数据
data["ARRIVAL_DELAY"] = (data["ARRIVAL_DELAY"]>10)*1
# 进行编码
cols = ["AIRLINE","FLIGHT_NUMBER","DESTINATION_AIRPORT","ORIGIN_AIRPORT"]
for item in cols:
data[item] = data[item].astype("category").cat.codes +1
# 划分训练集和测试集
train, test, y_train, y_test = train_test_split(data.drop(["ARRIVAL_DELAY"], axis=1), data["ARRIVAL_DELAY"], random_state=10, test_size=0.25)

- 步骤2 :构建LightGBM分类器,并设置树模型深度分别为[3,5,6,9],设置训练集和验证集,分别记录下验证集AUC精度。
#导入库
import lightgbm as lgb
import pandas as pd
import numpy as np
import graphviz
from sklearn import tree
import matplotlib.pyplot as plt
from sklearn.metrics import roc_auc_score
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split as TTS
from sklearn.metrics import accuracy_score
### 构建LightGBM分类器
#使用sklearn API
def test_depth(max_depth):
gbm = lgb.LGBMClassifier(max_depth=max_depth)
gbm.fit(train, y_train,
eval_set=[(test, y_test)],
eval_metric='binary_logloss',
callbacks=[lgb.early_stopping(5)])
#eval_metric默认值:LGBMRegressor 为“l2”,LGBMClassifier 为“logloss”,LGBMRanker 为“ndcg”。
#使用binary_logloss或者logloss准确率都是一样的。默认logloss
y_pred = gbm.predict(test)
# 计算准确率
accuracy = accuracy_score(y_test,y_pred)
auc_score=roc_auc_score(y_test,gbm.predict_proba(test)[:,1])#predict_proba输出正负样本概率值,取第二列为正样本概率值
print("max_depth=",max_depth,"accuarcy: %.2f%%" % (accuracy*100.0),"auc_score: %.2f%%" % (auc_score*100.0)+"\n"+"*"*100)
test_depth(3)
test_depth(5)
test_depth(6)
test_depth(9)
Training until validation scores don't improve for 5 rounds
Did not meet early stopping. Best iteration is:
[98] valid_0's binary_logloss: 0.429334
max_depth= 3 accuarcy: 81.90% auc_score: 76.32%
****************************************************************************************************
Training until validation scores don't improve for 5 rounds
Early stopping, best iteration is:
[60] valid_0's binary_logloss: 0.430826
max_depth= 5 accuarcy: 81.98% auc_score: 75.54%
****************************************************************************************************
Training until validation scores don't improve for 5 rounds
Early stopping, best iteration is:
[65] valid_0's binary_logloss: 0.429341
max_depth= 6 accuarcy: 81.69% auc_score: 75.63%
****************************************************************************************************
Training until validation scores don't improve for 5 rounds
Early stopping, best iteration is:
[52] valid_0's binary_logloss: 0.429146
max_depth= 9 accuarcy: 81.94% auc_score: 76.07%
****************************************************************************************************
- 步骤3 :构建LightGBM分类器,在fit函数中将category变量设置为categorical_feature,训练并记录下分别记录下验证集AUC精度。
参考资料1
参考资料2
lightgbm处理类别特征
lightgbm的categorical_feature(类别特征)使用:lightbm相比xgboost的一个改进之处在于对于类别特征的处理,不再粗腰将类别特征转为ont-hot.
具体流程为:
- 1、可以使用pd.DataFrame存放特征X, 每一列表示一个特征,将类别特征设置为:
X[cat_cols].astype('category'),这样模型在后面fit的时候会自动识别类别特征 - 2、在模型的fit方法中传入参数
categorical_feature, 指明哪些列是类别特征. - 3、类别特征的值必须是从0开始的连续整数, 比如0,1,2,…, 不能是负数.
使用categorical_feature
#导入库
import lightgbm as lgb
import pandas as pd
import numpy as np
import graphviz
from sklearn import tree
import matplotlib.pyplot as plt
from sklearn.metrics import roc_auc_score
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split as TTS
from sklearn.metrics import accuracy_score
#隐藏警告
import warnings
warnings.filterwarnings('ignore')
import pandas as pd, numpy as np, time
from sklearn.model_selection import train_test_split
# 读取数据
data = pd.read_csv("https://cdn.coggle.club/kaggle-flight-delays/flights_10k.csv.zip")
# 提取有用的列
data = data[["MONTH","DAY","DAY_OF_WEEK","AIRLINE","FLIGHT_NUMBER","DESTINATION_AIRPORT",
"ORIGIN_AIRPORT","AIR_TIME", "DEPARTURE_TIME","DISTANCE","ARRIVAL_DELAY"]]
data.dropna(inplace=True)
# 筛选出部分数据
data["ARRIVAL_DELAY"] = (data["ARRIVAL_DELAY"]>10)*1
# 进行编码
categorical_feats = ["AIRLINE","FLIGHT_NUMBER","DESTINATION_AIRPORT","ORIGIN_AIRPORT"]
for f_ in categorical_feats:
data[f_] = data[f_].astype('category') # 这里将类别特诊的类型转换为'category'
# 划分训练集和测试集
train, test, y_train, y_test = train_test_split(data.drop(["ARRIVAL_DELAY"], axis=1), data["ARRIVAL_DELAY"], random_state=10, test_size=0.25)
#sklaern API
params_sklearn = {
"boosting_type" : 'gbdt',
"num_leaves" : 31,
"max_depth" : 5,
"learning_rate" : 0.1,
"objective" : "binary",
"min_child_samples" : 20,
"verbose" : -1
}
gbm = lgb.LGBMClassifier(**params_sklearn)
gbm = gbm.fit(train, y_train, eval_set=[(test, y_test)], eval_metric='binary_logloss',categorical_feature=categorical_feats,
callbacks=[lgb.early_stopping(5)])
y_proba = gbm.predict_proba(test)
y_pred = gbm.predict(test)
#compute auc
print("Auc is %.2f "%(roc_auc_score(y_test, y_proba[:,1]))+"\t Accuracy score is %.2f"%(accuracy_score(y_test, y_pred)))
#结果:
Training until validation scores don't improve for 5 rounds
Early stopping, best iteration is:
[37] valid_0's binary_logloss: 0.422765
Auc is 0.77 Accuracy score is 0.82
使用LightGBM naive API
#Using the lightgbm API
params_lgb = {
"boosting_type" : 'gbdt',
"num_leaves" : 31,
"max_depth" : 5,
"learning_rate" : 0.1,
"objective" : "binary",
"min_child_samples" : 20,
"verbose" : -1
}
lgb_train = lgb.Dataset(train, y_train,free_raw_data=False, categorical_feature=categorical_feats)
lgb_eval = lgb.Dataset(test, y_test, reference=lgb_train,free_raw_data=False, categorical_feature=categorical_feats)
#model
gbm = lgb.train(params_lgb,
lgb_train,
num_boost_round=10,
valid_sets=lgb_eval, #验证集设置
#feature_name=feature_name, #特征命名
categorical_feature=categorical_feats,
callbacks=[lgb.early_stopping(stopping_rounds=5)]) #设置分类变量
y_pred = gbm.predict(test,num_iteration=gbm.best_iteration) #The difference with sklearn API is lgb navie API has not predict_proba, its preidct output the probability of the predicted class
pred =[1 if x >0.5 else 0 for x in y_pred]
#compute auc
print("AUC is %.2f"%(roc_auc_score(y_test, y_pred))+"\t Accuracy is %.2f"%(accuracy_score(y_test, pred)))
Training until validation scores don't improve for 5 rounds
Did not meet early stopping. Best iteration is:
[10] valid_0's binary_logloss: 0.441938
AUC is 0.77 Accuracy is 0.81
#和使用sklearn API差别不大。
不使用category_feature时
#不适用categorical_feature
import pandas as pd, numpy as np, time
from sklearn.model_selection import train_test_split
# 读取数据
data = pd.read_csv("https://cdn.coggle.club/kaggle-flight-delays/flights_10k.csv.zip")
# 提取有用的列
data = data[["MONTH","DAY","DAY_OF_WEEK","AIRLINE","FLIGHT_NUMBER","DESTINATION_AIRPORT",
"ORIGIN_AIRPORT","AIR_TIME", "DEPARTURE_TIME","DISTANCE","ARRIVAL_DELAY"]]
data.dropna(inplace=True)
# 筛选出部分数据
data["ARRIVAL_DELAY"] = (data["ARRIVAL_DELAY"]>10)*1
# 进行编码
cols = ["AIRLINE","FLIGHT_NUMBER","DESTINATION_AIRPORT","ORIGIN_AIRPORT"]
for item in cols:
data[item] = data[item].astype("category").cat.codes +1
# 划分训练集和测试集
train, test, y_train, y_test = train_test_split(data.drop(["ARRIVAL_DELAY"], axis=1), data["ARRIVAL_DELAY"], random_state=10, test_size=0.25)
#Using the lightgbm API
params_lgb = {
"boosting_type" : 'gbdt',
"num_leaves" : 31,
"max_depth" : 5,
"learning_rate" : 0.1,
"objective" : "binary",
"min_child_samples" : 20,
"verbose" : -1
}
lgb_train = lgb.Dataset(train, y_train,free_raw_data=False)
lgb_eval = lgb.Dataset(test, y_test, reference=lgb_train,free_raw_data=False)
#model
gbm = lgb.train(params_lgb,
lgb_train,
num_boost_round=10,
valid_sets=lgb_eval, #验证集设置
#feature_name=feature_name, #特征命名
callbacks=[lgb.early_stopping(stopping_rounds=5)]) #设置分类变量
y_pred = gbm.predict(test,num_iteration=gbm.best_iteration) #The difference with sklearn API is lgb navie API has not predict_proba, its preidct output the probability of the predicted class
pred =[1 if x >0.5 else 0 for x in y_pred]
#compute auc
print('AUC = %.2f'%(roc_auc_score(y_test, y_pred))+"\t Accuracy = %.2f"%(accuracy_score(y_test, pred)))
#结果
Training until validation scores don't improve for 5 rounds
Did not meet early stopping. Best iteration is:
[10] valid_0's binary_logloss: 0.462207
AUC = 0.72 Accuracy = 0.81
综上,我们可以看出,使用了category_feature后,AUC提升了0.05,accuracy_score基本不变。
- 步骤4 :学习网格搜索原理,使用GridSearchCV完成其他超参数搜索,其他超参数设置可以选择learning_rate、num_leaves等。
三种参数优化方法原理见:网格搜索、随机搜索和贝叶斯调参总结与实践
from sklearn.model_selection import GridSearchCV
#定义自己的网格搜索函数
def GridSearch(clf, params, X, y):
gscv = GridSearchCV(clf, params, scoring='neg_mean_squared_error', n_jobs=1, cv=5)
gscv.fit(X, y)
print("The best result: ", gscv.cv_results_)
print("The best params: ", gscv.best_params_)
#实验
params_sklearn = {
"boosting_type" : 'gbdt',
"max_depth" : 5,
"learning_rate" : 0.1,
"objective" : "binary",
"min_child_samples" : 20,
"verbose" : -1,
"random_state": 420,
}
gbm = lgb.LGBMClassifier(**params_sklearn)
#网格搜索的参数
params_grid = {
'max_depth':range(3,9),
'num_leaves':range(20,50),
'reg_lambda': np.arange(0.1, 1.0, 0.2),
'reg_alpha': np.arange(0.1, 1.0, 0.2),
'learning_rate':np.arange(0.1, 0.01, -0.05)
}
GridSearch(gbm, params_grid, train, y_train)
- 步骤4 :学习网格搜索原理,使用
GridSearchCV完成其他超参数搜索,其他超参数设置可以选择learning_rate、num_leaves等。
from sklearn.model_selection import GridSearchCV
#定义自己的网格搜索函数
def GridSearch(clf, params, X, y):
gscv = GridSearchCV(clf, params, scoring='neg_mean_squared_error', n_jobs=1, cv=5)
gscv.fit(X, y)
print("The best result: ", gscv.cv_results_)
print("The best params: ", gscv.best_params_)
#实验
params_sklearn = {
"boosting_type" : 'gbdt',
'max_depth':3,
"learning_rate" : 0.1,
"objective" : "binary",
"min_child_samples" : 20,
"metric" : ['binary_logloss','auc'],
"verbose" : -1,
'reg_lambda': 0.1,
'reg_alpha': 0.2,
"random_state": 420,
}
gbm = lgb.LGBMClassifier(**params_sklearn)
#网格搜索的参数
params_grid = {
'num_leaves':range(30,50),
'max_depth': range(4,8),
}
gscv = GridSearch(gbm, params_grid, train, y_train)
#The best params: {'max_depth': 6, 'num_leaves': 40}
#Timing 16.8s
- 步骤5 :学习随机搜索原理,使用
GridSearchCV完成其他超参数搜索,其他超参数设置可以选择learning_rate、num_leaves等。
#随机搜索,和网格搜索代码一致,除了更改GridSearchCV为RandomizedSearchCV
from sklearn.model_selection import RandomizedSearchCV
#定义自己的网格搜索函数
def RandomizedSearch(clf, params, X, y):
rscv = RandomizedSearchCV(clf, params, scoring='neg_mean_squared_error', n_jobs=1, cv=5)
rscv.fit(X, y)
print("The best result: ", rscv.cv_results_)
print("The best params: ", rscv.best_params_)
#实验
params_sklearn = {
"boosting_type" : 'gbdt',
'max_depth':3,
"learning_rate" : 0.1,
"objective" : "binary",
"min_child_samples" : 20,
"metric" : ['binary_logloss','auc'],
"verbose" : -1,
'reg_lambda': 0.1,
'reg_alpha': 0.2,
"random_state": 420,
}
gbm = lgb.LGBMClassifier(**params_sklearn)
#网格搜索的参数
params_randm = {
'num_leaves':range(30,50),
'max_depth': range(4,8),
}
rscv = RandomizedSearch(gbm, params_randm, train, y_train)
#The best params: {'num_leaves': 49, 'max_depth': 7}
#Timing:2.8s
- 步骤6 :学习贝叶斯调参原理,使用BayesianOptimization完成超参数搜索,具体过程可以参考https://blog.csdn.net/qq_42283960/article/details/88317003
#设定贝叶斯优化的黑盒函数LGB_bayesian
def LGB_bayesian(
num_leaves, # int
min_data_in_leaf, # int
learning_rate,
min_sum_hessian_in_leaf, # int
feature_fraction,
lambda_l1,
lambda_l2,
min_gain_to_split,
max_depth):
# LightGBM expects next three parameters need to be integer. So we make them integer
num_leaves = int(num_leaves)
min_data_in_leaf = int(min_data_in_leaf)
max_depth = int(max_depth)
assert type(num_leaves) == int
assert type(min_data_in_leaf) == int
assert type(max_depth) == int
param = {
'num_leaves': num_leaves,
'max_bin': 63,
'min_data_in_leaf': min_data_in_leaf,
'learning_rate': learning_rate,
'min_sum_hessian_in_leaf': min_sum_hessian_in_leaf,
'bagging_fraction': 1.0,
'bagging_freq': 5,
'feature_fraction': feature_fraction,
'lambda_l1': lambda_l1,
'lambda_l2': lambda_l2,
'min_gain_to_split': min_gain_to_split,
'max_depth': max_depth,
'save_binary': True,
'seed': 1337,
'feature_fraction_seed': 1337,
'bagging_seed': 1337,
'drop_seed': 1337,
'data_random_seed': 1337,
'objective': 'binary',
'boosting_type': 'gbdt',
'verbose': 1,
'metric': 'auc',
'is_unbalance': True,
'boost_from_average': False,
"verbosity":-1
}
lgb_train = lgb.Dataset(train,
label=y_train)
lgb_valid = lgb.Dataset(test,label=y_test,reference=lgb_train)
num_round = 500
gbm= lgb.train(param, lgb_train, num_round, valid_sets = [lgb_valid],callbacks=[lgb.early_stopping(stopping_rounds=5)])
predictions = gbm.predict(test,num_iteration=gbm.best_iteration)
score = roc_auc_score(y_test, predictions)
return score
bounds_LGB = {
'num_leaves': (5, 20),
'min_data_in_leaf': (5, 20),
'learning_rate': (0.01, 0.3),
'min_sum_hessian_in_leaf': (0.00001, 0.01),
'feature_fraction': (0.05, 0.5),
'lambda_l1': (0, 5.0),
'lambda_l2': (0, 5.0),
'min_gain_to_split': (0, 1.0),
'max_depth':(3,15),
}
#将它们全部放在BayesianOptimization对象中
from bayes_opt import BayesianOptimization
LGB_BO = BayesianOptimization(LGB_bayesian, bounds_LGB, random_state=13)
print(LGB_BO.space.keys)#显示要优化的参数
import warnings
import gc
pd.set_option('display.max_columns', 200)
init_points = 5
n_iter = 5
print('-' * 130)
with warnings.catch_warnings():
warnings.filterwarnings('ignore')
LGB_BO.maximize(init_points=init_points, n_iter=n_iter, acq='ucb', xi=0.0, alpha=1e-6)
任务6:模型微调与参数衰减
- 步骤0 :读取任务5的数据集,并完成数据划分。
- 步骤1 :学习使用LightGBM微调的步骤逐步完成1k数据分批次训练,训练集分批次验证集不划分,记录下验证集AUC精度。
数据分批处理:
import pandas as pd, numpy as np, time
import lightgbm as lgb
from sklearn.model_selection import train_test_split
# 读取数据
data = pd.read_csv("https://cdn.coggle.club/kaggle-flight-delays/flights_10k.csv.zip")
# 提取有用的列
data = data[["MONTH","DAY","DAY_OF_WEEK","AIRLINE","FLIGHT_NUMBER","DESTINATION_AIRPORT",
"ORIGIN_AIRPORT","AIR_TIME", "DEPARTURE_TIME","DISTANCE","ARRIVAL_DELAY"]]
data.dropna(inplace=True)
# 筛选出部分数据
data["ARRIVAL_DELAY"] = (data["ARRIVAL_DELAY"]>10)*1
# 进行编码
cols = ["AIRLINE","FLIGHT_NUMBER","DESTINATION_AIRPORT","ORIGIN_AIRPORT"]
for item in cols:
data[item] = data[item].astype("category").cat.codes +1
# 划分训练集和测试集
train, test, y_train, y_test = train_test_split(data.drop(["ARRIVAL_DELAY"], axis=1), data["ARRIVAL_DELAY"], random_state=10, test_size=0.2)
train_data = pd.concat([train, y_train], axis=1)
test_data = pd.concat([test, y_test], axis=1)
#重建索引
train_data = train_data.reset_index(drop=True)
#分批次训练,每一批训练数据两为959,一共分为8批数据
batch_size = 8
train_batch = []
batch_num = train_data.shape[0] // batch_size # 959
out_data = train_data.shape[0] - batch_num * batch_size # 1
gbm = None
for batch in range(batch_size):
if batch != 7:
train_batch.append(train_data.iloc[batch*batch_num:(batch+1)*batch_num-1,:])
else:
train_batch.append(train_data.iloc[batch*batch_num:-1,:])
lgb_train = lgb.Dataset(label=train_batch[batch].ARRIVAL_DELAY, data=train_batch[batch].drop('ARRIVAL_DELAY', axis=1))
lgb_eval = lgb.Dataset(test, y_test)
#训练增量模型->通过init_model & keep_training_booster两个参数实例化
params_lgb = {
"boosting_type" : 'gbdt',
"num_leaves" : 31,
"max_depth" : 5,
"metric" : ['binary_logloss','auc'],
"learning_rate" : 0.1,
"objective" : "binary",
"min_child_samples" : 20,
"verbose" : -1
}
gbm =lgb.train(params_lgb,
lgb_train,
num_boost_round=10,
valid_sets=lgb_eval,
init_model=gbm, #如果gbm变为None,那就是在上次训练的基础上接着训练
callbacks=[lgb.early_stopping(stopping_rounds=5)],
keep_training_booster=True) #增量训练
#输出模型评估分数
score_train = dict([(s[1], s[2]) for s in gbm.eval_train()])
score_valid = dict([(s[1], s[2]) for s in gbm.eval_valid()])
print("当前模型在训练集的得分是:binary_logloss=%.4f, auc=%.4f"%(score_train['binary_logloss'], score_train['auc']))
print("当前模型在验证集的得分是:binary_logloss=%.4f, auc=%.4f"%(score_valid['binary_logloss'], score_valid['auc']))
print('\n')
print("Processing Sussesifully! ")
Training until validation scores don't improve for 5 rounds
Did not meet early stopping. Best iteration is:
[10] valid_0's binary_logloss: 0.469446 valid_0's auc: 0.685584
当前模型在训练集的得分是:binary_logloss=0.4413, auc=0.8513
当前模型在验证集的得分是:binary_logloss=0.4694, auc=0.6856
Training until validation scores don't improve for 5 rounds
Did not meet early stopping. Best iteration is:
[20] valid_0's binary_logloss: 0.452407 valid_0's auc: 0.718817
当前模型在训练集的得分是:binary_logloss=0.4276, auc=0.8282
当前模型在验证集的得分是:binary_logloss=0.4524, auc=0.7188
Training until validation scores don't improve for 5 rounds
Did not meet early stopping. Best iteration is:
[30] valid_0's binary_logloss: 0.442653 valid_0's auc: 0.735925
当前模型在训练集的得分是:binary_logloss=0.4284, auc=0.7823
当前模型在验证集的得分是:binary_logloss=0.4427, auc=0.7359
Training until validation scores don't improve for 5 rounds
Early stopping, best iteration is:
[32] valid_0's binary_logloss: 0.440702 valid_0's auc: 0.737068
当前模型在训练集的得分是:binary_logloss=0.3987, auc=0.8301
当前模型在验证集的得分是:binary_logloss=0.4428, auc=0.7309
Training until validation scores don't improve for 5 rounds
Early stopping, best iteration is:
[38] valid_0's binary_logloss: 0.442734 valid_0's auc: 0.730401
当前模型在训练集的得分是:binary_logloss=0.4456, auc=0.7739
当前模型在验证集的得分是:binary_logloss=0.4477, auc=0.7226
Training until validation scores don't improve for 5 rounds
Did not meet early stopping. Best iteration is:
[50] valid_0's binary_logloss: 0.444845 valid_0's auc: 0.730959
当前模型在训练集的得分是:binary_logloss=0.3867, auc=0.8373
当前模型在验证集的得分是:binary_logloss=0.4458, auc=0.7302
Training until validation scores don't improve for 5 rounds
Early stopping, best iteration is:
[58] valid_0's binary_logloss: 0.441577 valid_0's auc: 0.739175
当前模型在训练集的得分是:binary_logloss=0.4018, auc=0.8340
当前模型在验证集的得分是:binary_logloss=0.4427, auc=0.7385
Training until validation scores don't improve for 5 rounds
Early stopping, best iteration is:
[64] valid_0's binary_logloss: 0.441751 valid_0's auc: 0.740202
当前模型在训练集的得分是:binary_logloss=0.4318, auc=0.7743
当前模型在验证集的得分是:binary_logloss=0.4433, auc=0.7387
Processing Sussesifully!
- 步骤2 :学习使用LightGBM学习率衰减的方法,使用指数衰减&阶梯衰减,记录下验证集AUC精度。
学习率衰减
#导入库
import lightgbm as lgb
import pandas as pd
import numpy as np
import graphviz
from sklearn import tree
import matplotlib.pyplot as plt
from sklearn.metrics import roc_auc_score
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split as TTS
from sklearn.metrics import accuracy_score
#隐藏警告
import warnings
warnings.filterwarnings('ignore')
import pandas as pd, numpy as np, time
from sklearn.model_selection import train_test_split
# 读取数据
data = pd.read_csv("https://cdn.coggle.club/kaggle-flight-delays/flights_10k.csv.zip")
# 提取有用的列
data = data[["MONTH","DAY","DAY_OF_WEEK","AIRLINE","FLIGHT_NUMBER","DESTINATION_AIRPORT",
"ORIGIN_AIRPORT","AIR_TIME", "DEPARTURE_TIME","DISTANCE","ARRIVAL_DELAY"]]
data.dropna(inplace=True)
# 筛选出部分数据
data["ARRIVAL_DELAY"] = (data["ARRIVAL_DELAY"]>10)*1
# 进行编码
cols = ["AIRLINE","FLIGHT_NUMBER","DESTINATION_AIRPORT","ORIGIN_AIRPORT"]
for item in cols:
data[item] = data[item].astype("category").cat.codes +1
# 划分训练集和测试集
train, test, y_train, y_test = train_test_split(data.drop(["ARRIVAL_DELAY"], axis=1), data["ARRIVAL_DELAY"], random_state=10, test_size=0.25)
lgb_train = lgb.Dataset(train, y_train, free_raw_data = False)
lgb_test = lgb.Dataset(test, y_test, free_raw_data = False)
params_lgb = {
"boosting_type" : 'gbdt',
"num_leaves" : 31,
"max_depth" : 5,
"metric" : ['binary_logloss','auc'],
"learning_rate" : 0.1,
"objective" : "binary",
"min_child_samples" : 20,
"verbose" : -1
}
gbm = None
# decay learning rates
# learning_rates accepts:
# 1. list/tuple with length = num_boost_round
# 2. function(curr_iter)
gbm = lgb.train(params_lgb,
lgb_train,
num_boost_round=10,
init_model=gbm,
learning_rates=lambda iter: 0.05 * (0.99 ** iter),
valid_sets=lgb_test)
print('Finished 20 - 30 rounds with decay learning rates...')
# change other parameters during training
gbm = lgb.train(params_lgb,
lgb_train,
num_boost_round=10,
init_model=gbm,
valid_sets=lgb_test,
callbacks=[lgb.reset_parameter(bagging_fraction=[0.7] * 5 + [0.6] * 5)])
print('Finished 30 - 40 rounds with changing bagging_fraction...')
[1] valid_0's binary_logloss: 0.507864 valid_0's auc: 0.679773
[2] valid_0's binary_logloss: 0.502682 valid_0's auc: 0.690961
[3] valid_0's binary_logloss: 0.498704 valid_0's auc: 0.693954
[4] valid_0's binary_logloss: 0.495317 valid_0's auc: 0.690265
[5] valid_0's binary_logloss: 0.49185 valid_0's auc: 0.692502
[6] valid_0's binary_logloss: 0.48925 valid_0's auc: 0.694694
[7] valid_0's binary_logloss: 0.486458 valid_0's auc: 0.695307
[8] valid_0's binary_logloss: 0.483654 valid_0's auc: 0.701753
[9] valid_0's binary_logloss: 0.481802 valid_0's auc: 0.703548
[10] valid_0's binary_logloss: 0.479875 valid_0's auc: 0.703218
Finished 20 - 30 rounds with decay learning rates...
Finished 30 - 40 rounds with changing bagging_fraction...
任务7:特征筛选方法
- 步骤0 :读取任务5的数据集,并完成数据划分。
- 步骤1 :使用
LightGBM计算特征重要性,并筛选最重要的3个特征。
def get_feature_importance_pair(gbm_model):
feature_name_list = gbm_model.feature_name()
importance_list = list(gbm_model.feature_importance())
feature_importance_pair = [(fe, round(im, 2)) for fe, im in zip(feature_name_list, importance_list)]
# 重要性从高到低排序
feature_importance_pair = sorted(feature_importance_pair, key=lambda x: x[1], reverse=True)
for pair in feature_importance_pair:
print('Feature:\t{}\t{}'.format(*pair))
return feature_importance_pair
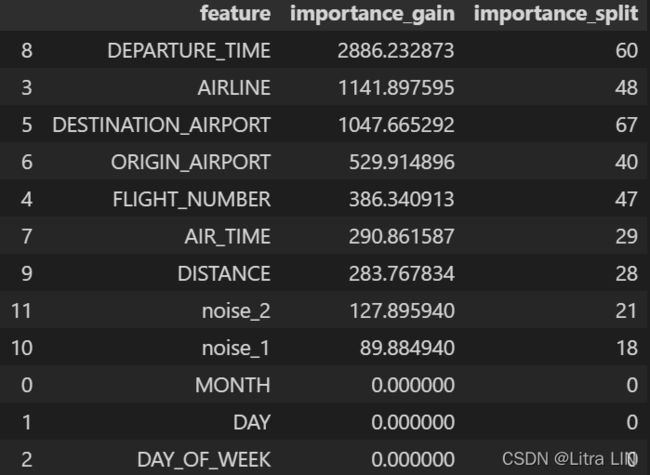
Feature: DEPARTURE_TIME 92
Feature: AIRLINE 80
Feature: DESTINATION_AIRPORT 72
Feature: ORIGIN_AIRPORT 46
Feature: DISTANCE 40
Feature: FLIGHT_NUMBER 37
Feature: AIR_TIME 30
Feature: MONTH 0
Feature: DAY 0
Feature: DAY_OF_WEEK 0
[('DEPARTURE_TIME', 92),
('AIRLINE', 80),
('DESTINATION_AIRPORT', 72),
('ORIGIN_AIRPORT', 46),
('DISTANCE', 40),
('FLIGHT_NUMBER', 37),
('AIR_TIME', 30),
('MONTH', 0),
('DAY', 0),
('DAY_OF_WEEK', 0)]
-
步骤2 : 学习排列重要性,并通过排列重要性计算出最重要的3个特征,
要求你手动实现其过程。
- https://scikit-learn.org/stable/modules/permutation_importance.html
- https://www.kaggle.com/dansbecker/permutation-importance
def get_feature_importance_pair(gbm_model):
feature_name_list = gbm_model.feature_name_
importance_list = list(gbm_model.feature_importances_)
feature_importance_pair = [(fe, round(im, 2)) for fe, im in zip(feature_name_list, importance_list)]
# 重要性从高到低排序
feature_importance_pair = sorted(feature_importance_pair, key=lambda x: x[1], reverse=True)
for pair in feature_importance_pair:
print('Feature:\t{}\t{}'.format(*pair))
return feature_importance_pair
params_sklearn = {
"boosting_type" : 'gbdt',
"num_leaves" : 40,
"max_depth" : 6,
"metric" : ['binary_logloss','auc'],
"learning_rate" : 0.1,
"n_estimators": 200,
"objective" : "binary",
"min_child_samples" : 20,
"verbose" : -1,
"reg_alpha": 0.1,
"reg_lambda": 0.2,
}
gbm = lgb.LGBMClassifier(**params_sklearn)
gbm = gbm.fit(train, y_train, eval_set=[(test, y_test)],callbacks=[lgb.early_stopping(5)])
get_feature_importance_pair(gbm)
Training until validation scores don't improve for 5 rounds
Early stopping, best iteration is:
[19] valid_0's binary_logloss: 0.439497 valid_0's auc: 0.754382
Feature: DEPARTURE_TIME 106
Feature: DESTINATION_AIRPORT 99
Feature: ORIGIN_AIRPORT 92
Feature: AIRLINE 70
Feature: DISTANCE 66
Feature: FLIGHT_NUMBER 65
Feature: AIR_TIME 57
Feature: MONTH 0
Feature: DAY 0
Feature: DAY_OF_WEEK 0
[('DEPARTURE_TIME', 106),
('DESTINATION_AIRPORT', 99),
('ORIGIN_AIRPORT', 92),
('AIRLINE', 70),
('DISTANCE', 66),
('FLIGHT_NUMBER', 65),
('AIR_TIME', 57),
('MONTH', 0),
('DAY', 0),
('DAY_OF_WEEK', 0)]
- **步骤3:**学习null importance重要性,并手动实现其过程,计算出最重要的3个特征。
- https://www.kaggle.com/ogrellier/feature-selection-with-null-importances
import eli5
from eli5.sklearn import PermutationImportance
params_sklearn = {
"boosting_type" : 'gbdt',
"num_leaves" : 40,
"max_depth" : 6,
"metric" : ['binary_logloss','auc'],
"learning_rate" : 0.1,
"n_estimators": 200,
"objective" : "binary",
"min_child_samples" : 20,
"verbose" : -1,
"reg_alpha": 0.1,
"reg_lambda": 0.2,
}
gbm = lgb.LGBMClassifier(**params_sklearn)
gbm = gbm.fit(train, y_train, eval_set=[(test, y_test)],callbacks=[lgb.early_stopping(5)])
perm = PermutationImportance(gbm, random_state=1).fit(test, y_test)
eli5.show_weights(perm, feature_names = test.columns.tolist())
Training until validation scores don't improve for 5 rounds
Early stopping, best iteration is:
[19] valid_0's binary_logloss: 0.439497 valid_0's auc: 0.754382

- 步骤3:学习null importance重要性,并手动实现其过程,计算出最重要的3个特征。
- https://www.kaggle.com/ogrellier/feature-selection-with-null-importances
#导入库
import lightgbm as lgb
import pandas as pd
import numpy as np
import graphviz
from sklearn import tree
import matplotlib.pyplot as plt
from sklearn.metrics import roc_auc_score
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split as TTS
from sklearn.metrics import accuracy_score
#隐藏警告
import warnings
warnings.filterwarnings('ignore')
import pandas as pd, numpy as np, time
from sklearn.model_selection import train_test_split
# 读取数据
data = pd.read_csv("https://cdn.coggle.club/kaggle-flight-delays/flights_10k.csv.zip")
# 提取有用的列
data = data[["MONTH","DAY","DAY_OF_WEEK","AIRLINE","FLIGHT_NUMBER","DESTINATION_AIRPORT",
"ORIGIN_AIRPORT","AIR_TIME", "DEPARTURE_TIME","DISTANCE","ARRIVAL_DELAY"]]
data.dropna(inplace=True)
# 筛选出部分数据
data["ARRIVAL_DELAY"] = (data["ARRIVAL_DELAY"]>10)*1
# 进行编码
cols = ["AIRLINE","FLIGHT_NUMBER","DESTINATION_AIRPORT","ORIGIN_AIRPORT"]
for item in cols:
data[item] = data[item].astype("category").cat.codes +1
#我们做两个随机的噪声项进去,看看噪声项的表现是怎么样的
data["noise_1"] = np.random.normal(size=data.shape[0])#正态分布
data["noise_2"] = np.random.randint(100,size=data.shape[0])#随机整数
# 划分训练集和测试集
# train, test, y_train, y_test = train_test_split(data.drop(["ARRIVAL_DELAY"], axis=1), data["ARRIVAL_DELAY"], random_state=10, test_size=0.25)
# lgb_train = lgb.Dataset(train, y_train, free_raw_data = False)
# lgb_test = lgb.Dataset(test, y_test, free_raw_data = False)
def get_feature_importances(data, shuffle, seed=None):
#特征
train_features = [f for f in data if f not in ['ARRIVAL_DELAY']]
y = data['ARRIVAL_DELAY'].copy()
#在制造Null importance时打乱
if shuffle:
#为了打乱时不影响原始数据,我们采取了.copy().sample(frac=1.0)
y = data['ARRIVAL_DELAY'].copy().sample(frac=1.0)
train_lgb = lgb.Dataset(data[train_features], y, free_raw_data=False, silent=True)
params_lgb = {
"boosting_type" : 'gbdt',
"num_leaves" : 40,
"max_depth" : 6,
"learning_rate" : 0.1,
"objective" : "binary",
"min_child_samples" : 20,
"verbose" : -1,
'random_state':seed,
'n_jobs':4,
}
#训练
clf = lgb.train(params_lgb, train_set=train_lgb, num_boost_round=10)
#Get feature importance
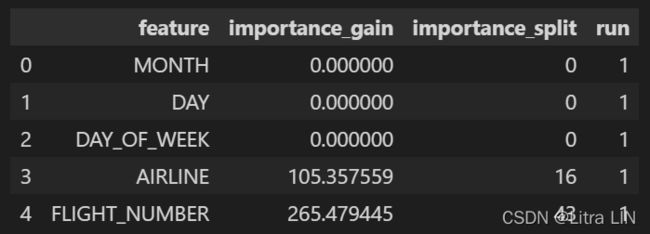
imp_df = pd.DataFrame()
imp_df["feature"] = list(train_features)
imp_df["importance_gain"] = clf.feature_importance(importance_type='gain')
imp_df["importance_split"] = clf.feature_importance(importance_type='split')
return imp_df
#我们先来看下原始的feature_importance好了
actual_imp = get_feature_importances(data=data,shuffle=False)
actual_imp.sort_values("importance_gain",ascending=False)
null_imp_df = pd.DataFrame()
nb_runs = 80
import time
start = time.time()
dsp = ''
for i in range(nb_runs):
# 获取当前轮feature impotance
imp_df = get_feature_importances(data=data, shuffle=True)
imp_df['run'] = i + 1
# 加到合集上去
null_imp_df = pd.concat([null_imp_df, imp_df], axis=0)
# 擦除旧信息
for l in range(len(dsp)):
print('\b', end='', flush=True)
# 显示当前轮信息
spent = (time.time() - start) / 60
dsp = 'Done with %4d of %4d (Spent %5.1f min)' % (i + 1, nb_runs, spent)
print(dsp, end='', flush=True)
null_imp_df.head()
import matplotlib.gridspec as gridspec
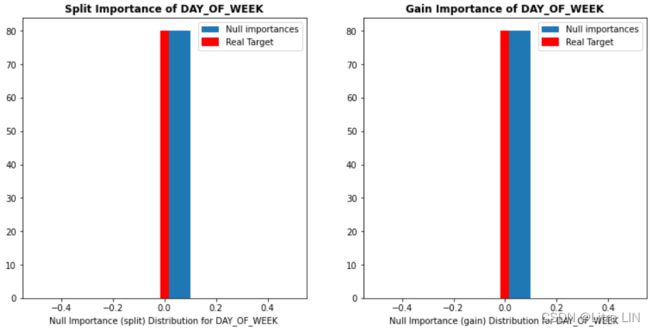
def display_distributions(actual_imp_df_, null_imp_df_, feature_):
plt.figure(figsize=(13, 6))
gs = gridspec.GridSpec(1, 2)
# Plot Split importances
ax = plt.subplot(gs[0, 0])
a = ax.hist(null_imp_df_.loc[null_imp_df_['feature'] == feature_, 'importance_split'].values, label='Null importances')
ax.vlines(x=actual_imp_df_.loc[actual_imp_df_['feature'] == feature_, 'importance_split'].mean(),
ymin=0, ymax=np.max(a[0]), color='r',linewidth=10, label='Real Target')
ax.legend()
ax.set_title('Split Importance of %s' % feature_.upper(), fontweight='bold')
plt.xlabel('Null Importance (split) Distribution for %s ' % feature_.upper())
# Plot Gain importances
ax = plt.subplot(gs[0, 1])
a = ax.hist(null_imp_df_.loc[null_imp_df_['feature'] == feature_, 'importance_gain'].values, label='Null importances')
ax.vlines(x=actual_imp_df_.loc[actual_imp_df_['feature'] == feature_, 'importance_gain'].mean(),
ymin=0, ymax=np.max(a[0]), color='r',linewidth=10, label='Real Target')
ax.legend()
ax.set_title('Gain Importance of %s' % feature_.upper(), fontweight='bold')
plt.xlabel('Null Importance (gain) Distribution for %s ' % feature_.upper())
display_distributions(actual_imp_df_=actual_imp, null_imp_df_=null_imp_df, feature_='DEPARTURE_TIME')

display_distributions(actual_imp_df_=actual_imp, null_imp_df_=null_imp_df, feature_='noise_1')

display_distributions(actual_imp_df_=actual_imp, null_imp_df_=null_imp_df, feature_='DAY_OF_WEEK')
任务8:自定义损失函数
https://gitee.com/mirrors/lightgbm/blob/master/examples/python-guide/advanced_example.py
步骤0 :读取任务5的数据集,并完成数据划分。
步骤1 :自定义损失函数,预测概率小于0.1的正样本(标签为正样本,但模型预测概率小于0.1),梯度增加一倍。
步骤2 :自定义评价函数,阈值大于0.8视为正样本(标签为正样本,但模型预测概率大于0.8)。
#自定义目标函数和评估指标
##自定义目标函数
def loglikehood(preds, train_data):
labels = train_data.get_label()
preds = 1./(1.+np.exp(-preds)) #sigmoid函数
grad=[(p-l) if p>=0.1 else 2*(p-l) for (p,l) in zip(preds,labels) ] #一阶导数
hess=[p*(1.-p) if p>=0.1 else 2*p*(1.-p) for p in preds ] #二阶导数
return grad, hess
def binary_error(preds, train_data):
labels = train_data.get_label()
preds = 1./(1.+np.exp(-preds))
return 'binary_error:', np.mean(labels != (preds > 0.8)), False
#开始训练
#Using the lightgbm API
params_lgb = {
"boosting_type" : 'gbdt',
"num_leaves" : 31,
"max_depth" : 5,
"learning_rate" : 0.1,
#"objective" : "binary",
"min_child_samples" : 20,
"verbose" : -1
}
#model
gbm = lgb.train(params_lgb,
lgb_train,
num_boost_round=10,
valid_sets=lgb_test, #验证集设置
#feature_name=feature_name, #特征命名
fobj=loglikehood, # 目标函数
feval=binary_error, # 评价指标
callbacks=[lgb.early_stopping(stopping_rounds=5)]) #设置分类变量
y_pred = gbm.predict(test,num_iteration=gbm.best_iteration) #The difference with sklearn API is lgb navie API has not predict_proba, its preidct output the probability of the predicted class
pred =[1 if x >0.5 else 0 for x in y_pred]
#compute auc
print('AUC = %.2f'%(roc_auc_score(y_test, y_pred))+"\t Accuracy = %.2f"%(accuracy_score(y_test, pred)))
Training until validation scores don't improve for 5 rounds
Early stopping, best iteration is:
[1] valid_0's binary_error:: 0.209341
AUC = 0.68 Accuracy = 0.79
任务9:模型部署与加速(可选,不参与积分)
https://treelite.readthedocs.io/en/latest/tutorials/import.html
步骤1 :训练模型,将模型保存为txt
步骤2 :使用treelite加载模型,导出为so,并进行预测。
#lightgbm模型打包
import treelite
import treelite_runtime
#将树模型导出为treelite
model = treelite.Model.load('model.txt', model_format='lightgbm')
#部署源存档:
model.export_srcpkg(platform='unix', toolchain='gcc',
pkgpath='./mymodel.zip', libname='mymodel.so',
verbose=True)
#部署共享库:
model.export_lib(toolchain='gcc', libpath='./mymodel.so', verbose=True)
#对目标进行预测
predictor = treelite_runtime.Predictor('./mymodel.so', verbose=True)
batch = treelite_runtime.Batch.from_npy2d(X)
out_pred = predictor.predict(batch)