大数据学习路线
大数据学习路线
文章目录
- 大数据学习路线
- 前言
- 零、学习路线图
- 一、基础部分
-
- 1.Java
- 2.Mysql
- 3.Linux
- 二、Hadoop生态
-
- 1.Hadoop基础
- 2.Zookeeper
- 3.HDFS
- 4.YARN
- 5.MapReduce
- 6.Hive
- 7.HBase
- 三、Spark生态
-
- 1.Scala
- 2.Spark
- 3.Kafka
- 四、Flink生态
- 五、其他相关平台
- 六、项目实战
- 总结
前言
以下学习路线图属于个人学习总结,以自身学习技术栈的时间先后排序,现分享给大家,欢迎大家留言建议,共同进步。
PS:目前居住二线省会城市,所属金融行业,从事大数据开发工程师岗位。
零、学习路线图
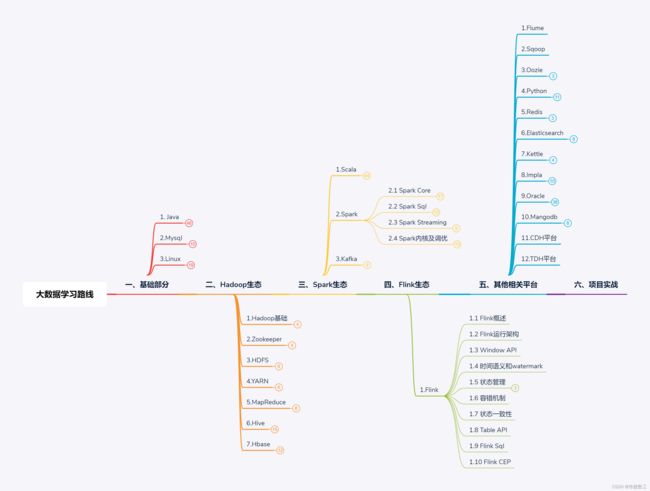
以上学习路线图为个人整理,仅供参考,如有需要可私信,转发完整路线图。
一、基础部分
1.Java
重要等级:★★★★★
目前编程语言较多,如C、Java、Scala、 Python等,大家可自行搜索TIOBE语言排行榜。
tiobe编程语言排行榜
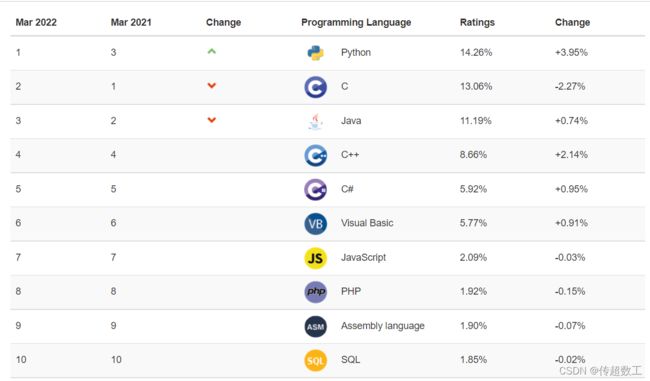
Java语言占比基本都是前三位置,学习大数据的话优先考虑学习Java, 对于大数据学习而言,不一定要精通Java, 但是一定要熟悉Java。
Java特点是面向对象、跨平台、健壮性等特点, 具有封装、继承、多态三大特征,现阶段适用范围较广,各类行业各类公司基本都在使用Java作为首选开发语言。
对于初学者而言,一定要掌握好Java,不管是对于后期的Hadoop学习,还是对于其他编程语言Scala或Python都非常有帮助。
2.Mysql
重要等级:★★★★
作为关系型数据库的代表,mysql地位同样重要。在数据库中,数据按照特定的格式将数据存储起来,用户可以对数据库中的数据进行增加,修改,删除及查询操作。
目前中小企业一般使用mysql作为数据库,考虑到mysql数据量达到500万性能会下降,一般大型公司都考虑使用Oracle, 更安全稳定,一般国企和上市公司都是用oralce。
对于基础学习,掌握好mysql更易上手,数据库的原理是相通的,如数据定义语言(DDL)、数据查询语言(DQL)、内置函数等。
3.Linux
重要等级:★★★★
一般我们平常使用电脑都是Windows系统,对于大数据开发人员而言,每天都会使用linux, 各种环境部署,上传各种自定义函数jar包,基本都是在linux上进行操作。
Linux系统一般有4个主要部分:内核、shell、文件系统和应用程序,我们需要熟悉linux各种常用的操作命令,如改变文件所属用户、文件查找、文本编辑等。
二、Hadoop生态
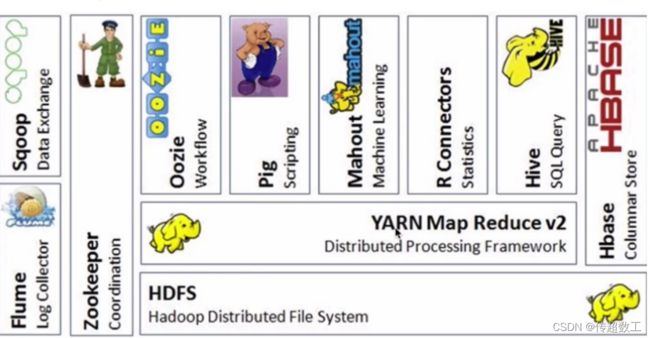
1.Hadoop基础
重要等级:★★★★
该部分了解即可,既然选择从事大数据行业了,首先就要了解什么是大数据?大数据有哪些特点?大数据能解决哪些问题?
其次需要了解Hadoop生态圈有哪些组件?分别是干什么的?
最后需要熟悉Hadoop环境怎么部署?分别有哪些配置文件?各自又是干什么的?对于环境部署,现在一般公司选用CDH或TDH、阿里云、华为云等,其原理是共通的,虽然是从事大数据开发,但是很多中小公司没有专门的运维人员,需要大数据开发人员负责运维,所以熟悉大数据开发环境同等重要。
2.Zookeeper
重要等级:★★★★
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务框架,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。
它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。在大数据技术体系中应用场景较多,重点了解底层执行原理及选举机制。
3.HDFS
重要等级:★★★★★
相当于电脑的“磁盘”,HDFS是一种数据分布式保存机制,数据被保存在计算机集群上,主要用于存储数据。
具有多种特点,如数据写入一次,读取多次,可以运行在廉价的机器集群上,扩展性较强,同时支持HA机制,容错性较高。目前用于文件存储,HDFS 为Hive、HBase等工具提供了基础。
4.YARN
重要等级:★★★★★
相当于电脑的“内存”和“CPU”,YARN是下一代MapReduce,即MRv2,是在第一代MapReduce基础上演变而来的,主要是为了解决原始Hadoop扩展性较差,不支持多计算框架而提出的。
YARN是 hadoop 2.0 引入的集群资源管理系统。用户可以将各种服务框架部署在 YARN 上,由 YARN 进行统一地管理和资源分配。YARN具有多重优势,如具有向后兼容性、支持多个框架、框架升级更容易。理解YARN底层机制,就不难理解Spark on Yarn 模式执行机制。
5.MapReduce
重要等级:★★★
MapReduce是一种分布式计算模型,用以进行大数据量的计算,是一种离线计算框架。
这个 MapReduce 的计算过程简而言之,就是将大数据集分解为成若干个小数据集,每个(或若干个)数据集分别由集群中的一个结点(一般就是一台主机)进行处理并生成中间结果,然后将每个结点的中间结果进行合并, 形成最终结果。
可以从编写wordcount开始,了解其执行原理。虽然现在大多优先使用Spark或Flink作为计算框架,MapReduce使用场景不多,但是掌握好MapReduce,对于理解大数据思想及执行机制非常重要。
6.Hive
重要等级:★★★★★
Hive是一个基于Hadoop的开源数据仓库工具,用于存储(HDFS)和处理(MapReduce)海量结构化数据,利用其灵活的SQL语法帮助我们进行复杂统计分析。
Hive的数据存储在HDFS上,hive默认使用MapReduce作为SQL的计算引擎,支持调整执行引擎为Spark。Hive主要应用于离线场景,在数仓中基本都会用到Hive,要求会进行表相关的DDL及DQL操作,使用简单的内置函数,编写自定义函数(UDF/UDAF/UDTF)。
7.HBase
重要等级:★★★
HBase是一个建立在HDFS之上,面向列的NoSQL数据库,用于快速读/写大量数据。HBase使用Zookeeper进行管理,确保所有组件都正常运行。数据被保存在 HDFS (分布式文件系统)上,由 HDFS 保证其高容错性。
HBase 是基于 Apache Hadoop 的面向列的 NoSQL数据库,是 Google 的 BigTable 的开源实现。Hadoop 是一个高容错、高延时的分布式文件系统和高并发的批处理系统,不适用于提供实时计算,而 HBase 是可以提供实时计算的分布式数据库,以k-v键值对形式存在,支持增删改查。
PS: 熟练掌握“基础部分” 及“Hadoop生态”包含技术体系,基本可以胜任数仓开发工程师岗位,主要针对离线的业务场景,目前一二线城市该岗位需求较多,二线城市薪资10K-20K,一线城市薪资稍微高点。
三、Spark生态
1.Scala
重要等级:★★★★
考虑Spark底层都是基于Scala语言编写,在学习Spark框架之前建议优先学习Scala,Spark的兴起,带动Scala语言的发展。
Scala 是 Scalable Language 的简写,是一门多范式的编程语言,Scala支持面向对象和函数式编程。Scala源代码(.scala)会被编译成Java字节码(.class),然后运行于JVM之上,并可以调用现有 的Java类库,实现两种语言的无缝对接。
Scala 在设计时参考了Java的设计思想,可以说Scala是源于java,同时将函数式编程语言的特点融合到JAVA中, 如果学过Java,掌握Scala相对容易,重点需要搞清楚Scala 和 java相同点和不同点。以前面试时还被问到过不同点,可见其重要性。
2.Spark
重要等级:★★★★★
Spark是一种通用的大数据计算框架,正如传统大数据技术Hadoop的MapReduce、Hive引擎。Spark生态包含Spark Core、Spark Sql、SparkStreaming、图计算、机器学习。 Spark使用强大的Scala语言开发,它还提供了对Scala、Python、Java(支持Java 8)和R语言的支持。
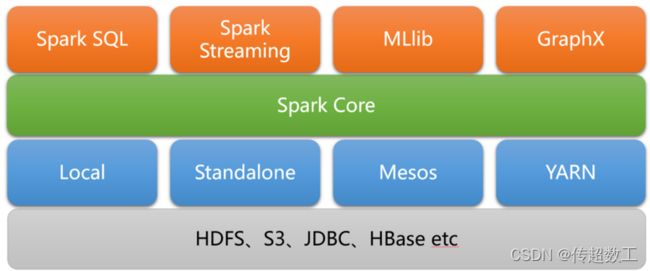
Spark运行速度快,支持使用Scala、Java、Python和R语言进行编程,可以通过Spark Shell进行交互式编程,同时提供了完整而强大的工具,包括SQL查询、流式计算、机器学习和图算法组件。例外可运行于独立的集群模式中,可运行于Hadoop中,也可运行于各类云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源。
对比Hadoop, Spark不能代替Hadoop,但可能代替MapReduce。Spark+Hadoop的组合,是目前多数公司的首选技术架构方式。
对比 MapReduce, Spark可以把多次使用的数据放到内存中, Spark 会的算法多(包含多种转换算子及行动算子),方便处理数据。同时, Spark大部分算子都没有shuffle阶段,不会频繁落地磁盘,降低磁盘IO。在代码编写方面,也不需要写那么复杂的MapReduce逻辑。
3.Kafka
重要等级:★★★★★
Apache Kafka是一个开源消息系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。Kafka最初是由LinkedIn公司开发,并于2011年初开源。2012年10月从Apache Incubator毕业。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
Kafka是一个分布式消息队列。Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)称为broker。无论是kafka集群,还是consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
在流式计算中,Kafka一般用来缓存数据,作为消息队列,目前应用较广,主要应用于实时场景。
四、Flink生态
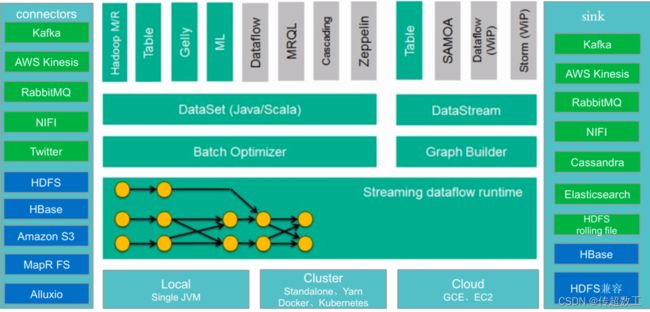
Apache Flink是一个分布式大数据处理引擎,可对有界数据流和无界数据流进行有状态计算。 可部署在各种集群环境,对各种大小的数据规模进行快速计算。
Flink虽然诞生的早(2010年),但是其实是起大早赶晚集,直到2015年才开始突然爆发热度。 在Flink被apache提升为顶级项目之后,阿里实时计算团队决定在阿里内部建立一个 Flink 分支 Blink,并对 Flink 进行大量的修改和完善,让其适应阿里巴巴这种超大规模的业务场景。目前Flink已被阿里购买,在国内大厂中实时计算场景中应用广泛。
第一代的计算引擎,无疑就是 Hadoop 承载的 MapReduce。第二代计算引擎, 如 Tez 以及更上层的 Oozie,支持 DAG 的框架。第三代的计算引擎以 Spark 为代表,特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及强调的实时计算。第四代计算引擎如 Flink,支持流计算以及更一步的实时性。
对比Spark,Spark是基于内存的批量运算,Flink是高可靠的exactly-once的流式运算。目前很多一线城市专门招聘Flink开发工程师,薪资较高,二三线城市招聘该岗位较少。
五、其他相关平台
大数据技术体系日新月异,对于各类大数据专业技术而言,没有绝对的好坏,只有适合自己就好。
对于第五部分内容,都是个人结合工作需要和自身了解,自行学习的部分。大家重点了解下大数据集群环境,现在应用较多的是CDH、TDH、阿里云,大家可以优先学习。
对于其他组件,如编程语言Python、搜索引擎Elasticsearch、ETL工具Kettle、数据库Oracle等,在这里就不做过多解读,大家根据自己需要学习了解。
六、项目实战
重要等级:★★★★★
从第一部分“基础部分”到第五部分“其他相关平台”,都是理论部分。对于理论的学习,最佳的方式就是结合实践。对于计算机学科而言,其特点就是实践性学科。通过实践,才能更好的掌握并理解理论,所以“项目实战”非常重要!!!
对于大数据从业者,面试时简历上都会要求编写项目经历,每个项目中要求写明该项目用到技术栈,面试时面试官通常都会对于你写明的技术点进行询问,询问方式基本都是由浅到深。只有对项目技术栈了然于胸,才能拿下offer。
对于大数据岗位,结合以上学习路线,一般包含项目类型如下:
类型一:Java相关项目(Java及mysql或Oracle)
类型二:数仓项目(Hadoop技术栈)
类型三:实时项目(Spark技术栈)
类型四:实时项目(Flink技术栈)
如果你准备面试数仓开发岗位,需要准备项目类型包含类型一及类型二;如果你准备面试大数据开发岗位,需要准备项目类型包含类型一、类型二及类型三;如果你准备面试专职Flink开发岗位,需要准备以上四种项目类型。
以上是对项目类型的说明,至于准备几个项目,按照个人从业年限项目个数不等。按照经验,至少准备两到三个项目。至于如何学习项目实战部分,推荐大家逛逛B站,很多实用的项目分享。
总结
以上就是个人的全部学习路线,按照时间轴分为基础部分、Hadoop生态、Spark生态、Flink生态、其他相关平台、项目实践。结合实际工作招聘需求和个人理解,分别做了相关说明。对于以上学习路线,如有不妥之处,欢迎大家批评指正。
缺什么补什么,这是基本原则。不管怎样,学习的过程都是从了解到深入,从深入到理解,从理解到掌握,都会有一个时间过程,最终都是要更好的理解并应用技术,实现个人价值。
预祝大家学习顺利,涨薪升职。欢迎大家探讨交流!