[深度学习论文笔记]Brain tumor segmentation with self-ensembled,deeply-supervised 3D U-net neural networks
Brain tumor segmentation with self-ensembled,deeply-supervised 3D U-net neural networks: a BraTS 2020 challenge solution.
使用自集成、深度监督的3D U-net神经网络的脑肿瘤分割:BraTS 2020挑战解决方案
论文:https://arxiv.org/abs/2011.01045
代码:https://github.com/lescientifik/open brats2020
BraTS 2020 proceedings (LNCS) paper
摘要:
脑肿瘤分割是患者疾病管理的一项重要任务。为了实现这项任务的自动化和标准化,作者在多模态脑肿瘤分割挑战(BraTS) 2020训练数据集上训练了多个U-net类的神经网络,主要采用深度监督和随机加权法。从两个不同的训练管道训练两个独立的模型集成,并且每个产生一个脑肿瘤分割图。然后将每个患者的这两个标签映射合并,从而考虑每个集合对特定肿瘤区域的表现。作者在在线验证数据集上的性能如下:dice分数分别为0.81、0.91和0.85;增强肿瘤、全肿瘤和肿瘤核心的豪斯多夫(95%)分别为20.6、4.3、5.7毫米。同样,解决方案在最终测试数据集上获得了0.79、0.89和0.84的dice分数,以及20.4、6.7和19.5毫米的豪斯多夫(95%),使方法跻身前十名。总的来说,方法在每个肿瘤区域都取得了良好和平衡的效果。
问题动机:
1.1临床概述:
胶质瘤是成人患者中最常见的原始脑肿瘤,表现出不同程度的侵袭性和预后。磁共振成像(MRI)是全面评估肿瘤异质性所必需的,通常使用以下序列:T1加权序列(T1)、使用钆对比剂的T1加权对比增强序列(T1Gd)、T2加权序列(T2)和液体衰减反转恢复(FLAIR)序列。
磁共振成像可以定义四个不同的肿瘤亚区:“增强肿瘤”(ET),对应于T1Gd相对于T1序列的相对高信号区;“非增强肿瘤”(NET)和“坏死肿瘤”(NCR),与T1相比,T1-Gd均为低信号;最后是“瘤周水肿”,在FLAIR序列中是高强度的。这些几乎同质的子区域可以聚集在一起,构成三个“语义上”有意义的肿瘤子区域:ET是第一个聚类,ET、NET和NCR的添加代表“肿瘤核心”(TC)区域,ED到TC的添加代表“整个肿瘤”(WT)。图1使用3D切片提供了每个序列和肿瘤子体积的示例。
![[深度学习论文笔记]Brain tumor segmentation with self-ensembled,deeply-supervised 3D U-net neural networks_第1张图片](http://img.e-com-net.com/image/info8/3fb46ad1038d4efcbe7af746236eb8c0.jpg)
图1:BraTS 2020训练数据集中的一个脑瘤例子。红色:增强肿瘤(ET),绿色:非增强肿瘤/坏死肿瘤(NET/NCR),黄色:瘤周水肿(ED)。左上:T2加权序列,右上:T1加权序列,左下:T1加权增强对比序列,右下:FLAIR序列,中间:T1加权增强对比序列,并覆盖labelmap
准确描述每个肿瘤亚区域对于患者的疾病管理是至关重要的,特别是在手术后的情况下。事实上,根据放射治疗肿瘤组(RTOG),放射肿瘤学家需要对肿瘤进行分割,包括手术切除腔、增强肿瘤残余和周围水肿。正确的分割也可以通过使用放射组学或基于深度学习的方法揭示预后因素
1.2多模态脑肿瘤分割挑战2020
多模态脑肿瘤分割挑战2020分为三个不同的任务:分割不同的肿瘤子区域,根据术前磁共振成像扫描预测患者的整体生存率,以及评估分割中的不确定性度量。分割的挑战在于准确描绘肿瘤的ET、TC和WT部分。主要的评估指标是重叠指标和距离指标。常用的dice相似系数(DSC)衡量两组之间的重叠。在真实标签比较的上下文中,它可以定义如下:

TP为真阳性(正确分类体素的数量),FP为假阳性,FN为假阴性。有趣的是,这个指标对图像中的背景不敏感。Hausdorff距离与Dice度量是互补的,因为它测量两个轮廓的边缘之间的最大距离。它极大地惩罚了离群值:预测可以表现出几乎体素完美的重叠,但如果单个体素远离参考分割,Hausdorff距离将会很高。因此,这个指标可能看起来比Dice指数更复杂,但却能够方便地评估细分的临床相关性。例如,如果肿瘤分割包含远处健康的脑组织,就需要放射肿瘤学家进行手动纠正,以防止对患者造成灾难性的后果,即使Dice度量的整体重叠已经足够好了。
2、方法
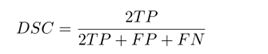
设计了两个独立的训练管道,采用基于3D U-Net的共同神经网络体系结构,略有变化(如下所述)。这两种不同的训练方法是分开的,以促进网络预测的多样性。下面将介绍每个管道的具体细节,分别称为管道A和管道B。
2.1神经网络架构
经过对神经网络体系结构的探索,所选择的网络使用了一种编码器解码器体系结构,这一构架的灵感主要来自Cicek等人[3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation]的3D U-Net体系结构的启发。使用的架构如图2所示。
![[深度学习论文笔记]Brain tumor segmentation with self-ensembled,deeply-supervised 3D U-net neural networks_第2张图片](http://img.e-com-net.com/image/info8/03a18dba3738400c90019d4742c7e4cb.jpg)
图2:神经网络架构:3D Unet稍加修改
在以下描述中,stage被定义为不改变特征图的空间维度的任意数量的卷积。所有卷积之后是归一化层和非线性激活(ReLU层)。由于训练过程中的批处理规模小,且在非医学数据集上具有良好的理论性能,作者使用组归一化 (A)和实例归一化化 (B)替代批量归一化。
编码器有四个阶段。每个阶段由两个3x3x3卷积组成。第一次卷积将卷积核的数量增加到预设值(第1阶段为48个),而第二次卷积保持输出通道的数量不变。在每个阶段之间,通过MaxPool层进行空间降采样,内核大小为2x2x2,步幅为2。每次空间降采样后,卷积核的数量增加一倍。最后一级后,进行2个膨胀率为2的3x3x3膨胀卷积,然后与最后一级输出连接。
网络的解码器部分与编码器几乎是对称的。在每个阶段之间,采用三线性插值进行空间上采样。共享相同空间大小的编码器和解码器之间的快捷连接是通过串联来执行的。执行最低空间分辨率的解码器阶段仅由一个3x3x3卷积组成。最后一个卷积层使用了带有3个输出通道和一个sigmoid激活的1x1x1内核。
Brats挑战去年获胜者[Two-Stage Cascaded U-Net: 1st Place Solution to BraTS Challenge 2019 Segmentation Task]将他们的下采样步骤限制在3步。作者假设,在输入量有限(128x128x128)的情况下,进一步对特征图进行降采样会导致空间信息的不可挽回的丢失。由于编码器的最后一个阶段比第一个阶段占用更少的GPU内存,所以作者使用膨胀技巧[DeepLab:Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution,and Fully Connected CRFs]以与第四阶段相同的空间分辨率执行伪第五阶段。
3D attention U-Nets也接受了训练,使用在每个编码阶段末尾添加的卷积块注意力模块。
2.2损失函数
受到2019年获奖方案的简洁性的启发,我们只使用dice损失 (A)来训练神经网络。损失L是分批和通道计算的,没有加权:
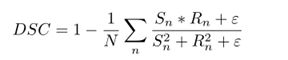
其中n为输出通道数,S为sigmoid激活后的神经网络输出,R为ground truth label, 平滑因子(在实验中设置为1)。对于多样性,管道B使用了一个略微不同的dice损失公式,没有将分母平方。同样,直接对最终的肿瘤区域(ET、TC和WT)进行优化,而不是对其成分(ET、NET-NCR、ED)进行优化。神经网络输出的是一个3通道的体积,每个通道代表每个肿瘤区域的概率图。
深监督在扩张卷积之后,以及解码器的每个阶段(最后阶段除外)之后执行。深监督是通过增加一个额外的1x1x1卷积与sigmoid激活和三线性上采样来实现的。像主要输出一样,每一个额外的卷积产生一个3通道的体积,每个通道代表每个肿瘤区域(ET, TC和WT)的概率图。最后的损失是主要输出损失和四个辅助损失的未加权总和。
2.3图像预处理
由于磁共振成像强度因制造商、采集参数和序列的不同而不同,因此输入图像需要标准化。将所有强度值裁剪到体积非零体素分布的1%和99% (A)后,分别对每个MRI序列进行最小-最大缩放。管道B分别对每个IRM序列的非零体素进行z分数归一化。
然后使用最小的包含整个大脑的边界框将图像裁剪成可变大小,并随机重新裁剪成固定大小的128x128x128补丁。这样就可以移除原始区域中大部分无用的背景,并从几乎完整的视角了解每个脑瘤。
2.4数据增强技术:
为了防止过拟合,根据预先设定的概率,在两条管道上应用实时数据增强技术。增量及其各自的应用概率为:
-输入通道缩放:将每个体素乘以0.9和1.1之间的均匀采样因子(a: 80%的概率,B: 20%)。
-输入通道强度移位:在-0.1和0.1之间添加一个恒定的均匀采样(a:未执行,B: 20%的概率)。
-加性高斯噪声,使用标准差为0.1的中心正态分布。
-输入通道下降:一个输入通道的所有体素值被随机设置为零(A: 16%的概率,B:不执行)。
-沿每个空间轴随机翻转(A: 80%的概率,B: 50%)
2.5训练细节
模型由五重交叉验证产生。验证集仅用于在训练期间监控网络性能,并在训练过程结束时对其性能进行基准测试。
管道A: 对于每一个fold,神经网络被训练200个epoch,初始学习率为1e-4,在100个epoch之后逐步减少余弦衰减。批次大小为1,使用Ranger优化器。在经历了200个时期之后,执行了一个受快速随机加权平均 [There are many consistent explanations of unlabeled data: why you should average]启发的训练方案。初始学习率恢复到初始值的一半(5e-5),并在余弦衰减下进行另外30个epoch的训练。每隔3个epoch,模型重量就会被节省下来。这个过程重复了5次,总共增加了150个期。最后,将节省下来的权重取平均值,有效地创建了一个新的“自集成”模型。采用Adam优化器进行随机加权平均程序,没有权重衰减。
管道B: 最大训练迭代次数设置为400次。保留的最佳模型为验证集上损失值最小的模型。一批3个亚当优化器和初步学习1e-4和没有重量衰减。采用余弦退火调整学习率。(CosineAnnealingLR 余弦退火调整学习率)
![[深度学习论文笔记]Brain tumor segmentation with self-ensembled,deeply-supervised 3D U-net neural networks_第3张图片](http://img.e-com-net.com/image/info8/0bfb15ec014f498392babb57329f48d3.jpg)
共同点:为了训练更大的神经网络,使用了float 16 precision (FP16),减少了内存消耗,加快了训练过程,并可能导致额外的性能。
2.6推论
推理以两步的方式执行。首先,通过简单的预测平均,分别集成每个管道中可用的模型。因此,每个案例创建两个标签映射,每个管道创建一个标签映射。
对于管道A,每一折有三个不同的模型:3D attention U-net版本,在训练数据集的未过滤版本上训练的U-net版本,以及在训练数据集的过滤子集上训练的U-net版本。
过滤过程基于以前的训练运行:在训练过程结束时训练损失高的案例被标记为潜在错误,并从完整的训练集中移除,从而创建一个“清洗”版本的训练数据集。对于管道B, 5个交叉验证的模型(每折一个)被集成。然后,根据每个集成在在线验证集上的单独性能合并两个标签映射,如下所述。
第一步 对于每个管道,初始体积像训练数据一样进行预处理,然后裁剪到最小的大脑范围,最后进行零填充,使每个空间维度都能被8整除。测试时间增强(TTA)使用16种不同的增强方法对交叉验证生成的每个模型进行,每个样本总共有80个预测。只在轴向平面上使用翻转和90-180-270°旋转,因为在其他平面上的旋转导致在局部验证集上的性能更差。最后的预测是对预测进行平均,使用0.5的阈值对预测进行二值化。
然后以一种直接的方式进行Label map重建:不影响ET预测,从ET标记和TC标记之间的布尔运算中推断出肿瘤的净内区,同样地,对于TC和WT标记之间的水肿也是如此(NonEnhanching=TC–ET; edema(水肿) = WT–TC)。
第二步 第一步给每个案例两个标签。基于在线验证数据集,管道B的集成的平均全肿瘤dice度量始终高于管道A的集成。作者假设来自管道B的模型更好地预测水肿。为了保持A的ET和TC的分数不变,ET和NET/NCR模型中预测标签必须保持不变。如果A预测背景或水肿,B分别预测水肿或背景,则保留B预测标签。合并过程如表1所示。
![[深度学习论文笔记]Brain tumor segmentation with self-ensembled,deeply-supervised 3D U-net neural networks_第4张图片](http://img.e-com-net.com/image/info8/edc41a785d504ff9bf4dfa18ba434364.jpg)
表1:两个标签的合并过程。0:背景,1:坏死和非增强肿瘤核心,2:瘤周水肿,4:增强肿瘤
2.7管道A的消融实验
针对管道A进行了有无数据集过滤和有无注意力块的实验。交叉验证的结果见表2。这两种策略都没有明显的好处,因此作者决定为这个管道的每折保留两个最佳可用模型。

表2 :消融实验:训练集交叉验证的结果。
3、实验结果
3.1在线验证数据集
表3显示了在线验证数据的结果。模型产生了大于0.8的dice分数。对于每个肿瘤区域。作者的两遍合并策略对管道A的集成ET和TC分割性能没有影响,但大大提高了WT分割。单通道策略已经对三个肿瘤区域产生了良好的性能。与其他肿瘤亚区相比,ET的豪斯多夫距离值较大,这是由于某些病例中缺少ET标记所致。因此,即使预测ET的一个体素也会导致对该指标的重大惩罚。在线验证集中的分割肿瘤示例如图3所示。根据每个患者的平均dice分数(三个肿瘤子区域的平均值),很难从视觉上最好地区分平均结果。然而,生成的最差掩模显示出明显的错误: 造影剂增强的动脉被错误地标记为增强肿瘤。
![[深度学习论文笔记]Brain tumor segmentation with self-ensembled,deeply-supervised 3D U-net neural networks_第5张图片](http://img.e-com-net.com/image/info8/6c4a6ec2fd1b4692b9fc042e405aa1d8.jpg)
表3:合并策略的完整BraTs 20在线验证数据的性能
![[深度学习论文笔记]Brain tumor segmentation with self-ensembled,deeply-supervised 3D U-net neural networks_第6张图片](http://img.e-com-net.com/image/info8/55d8e72b492644398336d4f63b604fe8.jpg)
图3:从左到右:来自训练集的真实标签示例,并从解决方案中为在线验证集中的三名患者生成分割;分别为:最佳平均dice分数(ET:0.95,WT:0.96,TC:0.98)、平均dice(ET:0.73,WT:0.92,TC:0.93)和最差平均dice(ET:0.23,WT:0.95,TC:0.13)。红色:增强肿瘤(ET),绿色:非增强肿瘤/坏死肿瘤(NET/NCR),黄色:瘤周水肿(ED)
3.2测试数据集
在测试数据集上的最终结果显示在表2中。这些结果将作者排在细分挑战的前10名。TC、Hausdorff距离的验证数据集和测试数据集之间的显著差异是显而易见的,而所有其他指标都显示出微小但基本拟合。
![[深度学习论文笔记]Brain tumor segmentation with self-ensembled,deeply-supervised 3D U-net neural networks_第7张图片](http://img.e-com-net.com/image/info8/0a7eccbda2544e23913d36e2ae3b9f81.jpg)
表4 :BraTs 20测试数据的性能
4、讨论
作者对BraTs 20挑战的解决方案是基于精心设计的标准方法:作者使用3D U-net神经网络,使用Dice Loss和深监督进行实时数据增强训练,并使用测试时间增强和模型预测集成进行推断。
尝试了许多现代的“先进方法”: 短的附加残差连接,稠密块,基于反向残差瓶颈的较新的神经网络主干,像biFPN层这样的较新的解码器结构,或者使用医疗十项全能的大脑数据集的半监督设置。
这些改进都没有导致本地验证集的显著改进。作者假设这可能是由于GPU内存限制。实际上,虽然这些层以相对较小的参数成本提高了模型的精度,但它显著增加了模型的激活映射的大小,迫使我们使用更小的网络(减少每个卷积层的输出通道数量)。减少patch的大小不是一个选项,因为这很可能会由于缺少上下文而降低网络性能。此外,所有这些添加都导致了训练时间的显著增加,减少了挑战有限时间内的可搜索空间。
训练结束时的随机加权平均是作者使用的最显著的改进。这个训练计划是半监督训练的残余。作者没有衡量它的真正潜力,但希望它能产生一个更具普遍性的模型,以防止在训练集上过拟合,并记住噪声标签。事实上,高学习率可以防止这种行为,作者希望他们的训练受益于多次学习率改变。
值得注意的是,虽然作者的结果在BraTS 2020挑战中不是最先进的,但方法的分割性能在肿瘤分割的评分者间一致的通常范围内,并且可能已经具有临床应用价值。作为一个例子,图4放大了图3的前两个注释的肿瘤分割(分别是手动真实标签注释和最佳验证情况)
![[深度学习论文笔记]Brain tumor segmentation with self-ensembled,deeply-supervised 3D U-net neural networks_第8张图片](http://img.e-com-net.com/image/info8/93c95fb7e4594cdda937f3097c239e9e.jpg)
图4:图3左首两个小插图的放大版本:来自训练集的真实标签。右:从作者的解决方案中为验证集上的最佳平均dice分数患者生成了分段。红色:增强肿瘤(ET),绿色:非增强肿瘤/坏死肿瘤(NET/NCR),黄色:瘤周水肿(ED)。有趣的是,两者显示出相同的模式:中央非增强肿瘤核心与周围增强环和弥漫性瘤周水肿。
总结:
脑肿瘤分割的任务虽然具有挑战性,但可以使用类似3D U-Net的神经网络架构,通过精心制作的预处理、训练和推理过程,以良好的精度解决。我们开放了我们的训练渠道,允许未来的研究人员基于我们的发现,并提高我们的细分性能。