卷积神经网络基础
3.1 卷积神经网络(CNN)原理
为什么需要卷积神经网络
原因之一:图像特征数量对神经网络效果压力
假设下图是一图片大小为28 * 28 的黑白图片时候,每一个像素点只有一个值(单通道)。那么总的数值个数为 784个特征。

那现在这张图片是彩色的,那么彩色图片由RGB三通道组成,也就意味着总的数值有28 28 3 = 2352个值。

从上面我们得到一张图片的输入是2352个特征值,即神经网路当中与若干个神经元连接,假设第一个隐层是10个神经元,那么也就是23520个权重参数。
如果图片再大一些呢,假设图片为1000 1000 3,那么总共有3百万数值,同样接入10个神经元,那么就是3千万个权重参数。这样的参数大小,神经网络参数更新需要大量的计算不说,也很难达到更好的效果,大家就不倾向于使用多层神经网络了。
所以就有了卷积神经网络的流行,那么卷积神经网络为什么大家会选择它。那么先来介绍感受野以及边缘检测的概念。
注:另有卷积网络感受野的概念,也是为什么使用卷积的原因
3.1.1 卷积神经网络的组成
- 定义
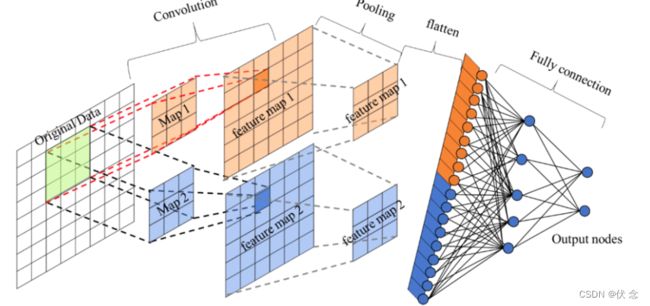
- 卷积神经网络由一个或多个卷积层、池化层以及全连接层等组成。与其他深度学习结构相比,卷积神经网络在图像等方面能够给出更好的结果。这一模型也可以使用反向传播算法进行训练。相比较其他浅层或深度神经网络,卷积神经网络需要考量的参数更少,使之成为一种颇具吸引力的深度学习结构。
我们来看一下卷积网络的整体结构什么样子。

其中包含了几个主要结构
- 卷积层(Convolutions)
- 池化层(Subsampling)
- 全连接层(Full connection)
- 激活函数
3.1.2 卷积层
- 目的
- 卷积运算的目的是提取输入的不同特征,某些卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网路能从低级特征中迭代提取更复杂的特征。
- 参数:
- size:卷积核/过滤器大小,选择有1 1, 3 3, 5 * 5(为什么是奇数个)
- padding:零填充,Valid 与Same
- stride:步长,通常默认为1
- 计算公式

3.1.2.1 卷积运算过程
对于之前介绍的卷积运算过程,我们用一张动图来表示更好理解些。一下计算中,假设图片长宽相等,设为N
- 一个步长,3 X 3 卷积核运算
假设是一张5 X 5 的单通道图片,通过使用3 X 3 大小的卷积核运算得到一个 3 X 3大小的运算结果(图片像素数值仅供参考)
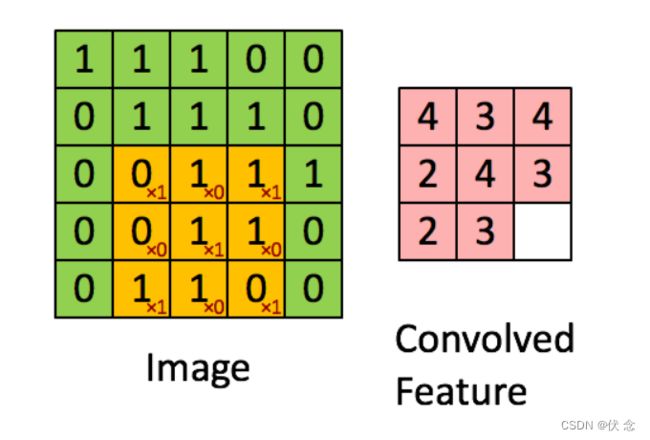
我们会发现进行卷积之后的图片变小了,假设N为图片大小,F为卷积核大小
相当于N - F + 1 = 5 - 3 + 1 = 3N−F+1=5−3+1=3
如果我们换一个卷积核大小或者加入很多层卷积之后,图像可能最后就变成了1 X 1 大小,这不是我们希望看到的结果。并且对于原始图片当中的边缘像素来说,只计算了一遍,二对于中间的像素会有很多次过滤器与之计算,这样导致对边缘信息的丢失。
- 缺点
- 图像变小
- 边缘信息丢失
3.1.3 padding-零填充
零填充:在图片像素的最外层加上若干层0值,若一层,记做p =1。
- 为什么增加的是0?
因为0在权重乘积和运算中对最终结果不造成影响,也就避免了图片增加了额外的干扰信息。
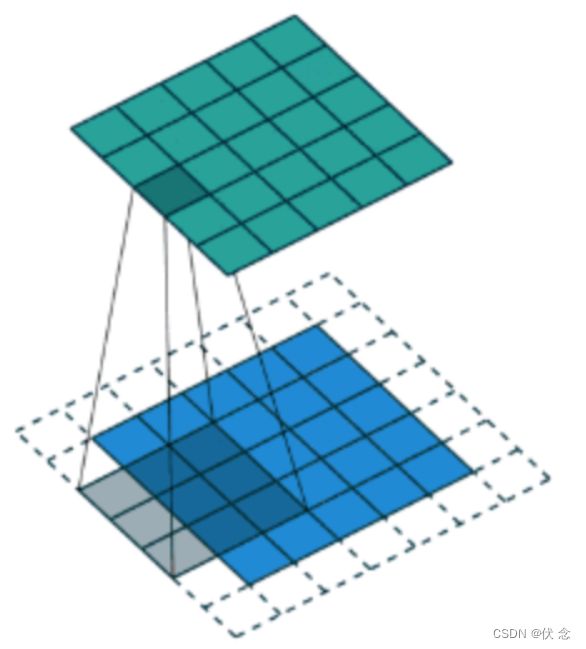
这张图中,还是移动一个像素,并且外面增加了一层0。那么最终计算结果我们可以这样用公式来计算:
5 + 2 * p - 3 + 1 = 55+2∗p−3+1=5
P为1,那么最终特征结果为5。实际上我们可以填充更多的像素,假设为2层,则
5 + 2 * 2 - 3 + 1 = 75+2∗2−3+1=7,这样得到的观察特征大小比之前图片大小还大。所以我们对于零填充会有一些选择,该填充多少?
3.1.3.1 Valid and Same卷积
有两种两种形式,所以为了避免上述情况,大家选择都是Same这种填充卷积计算方式
- Valid :不填充,也就是最终大小为
- (N - F + 1) * (N - F + 1)(N−F+1)∗(N−F+1)
- Same:输出大小与原图大小一致,那么 NN变成了N + 2PN+2P
- (N + 2P - F + 1) * (N + 2P - F + 1)(N+2P−F+1)∗(N+2P−F+1)
那也就意味着,之前大小与之后的大小一样,得出下面的等式
(N + 2P - F + 1) = N(N+2P−F+1)=N
P = \frac{F -1}{2}P=2F−1
所以当知道了卷积核的大小之后,就可以得出要填充多少层像素。
3.1.3.2 奇数维度的过滤器
通过上面的式子,如果F不是奇数而是偶数个,那么最终计算结果不是一个整数,造成0.5,1.5.....这种情况,这样填充不均匀,所以也就是为什么卷积核默认都去使用奇数维度大小
-
1 1,3 3, 5 5,7 7
-
另一个解释角度
- 奇数维度的过滤器有中心,便于指出过滤器的位置
当然这个都是一些假设的原因,最终原因还是在F对于计算结果的影响。所以通常选择奇数维度的过滤器,是大家约定成俗的结果,可能也是基于大量实验奇数能得出更好的结果。
3.1.4 stride-步长
以上例子中我们看到的都是每次移动一个像素步长的结果,如果将这个步长修改为2,3,那结果如何?

这样如果以原来的计算公式,那么结果
N + 2P - F + 1 = 6 + 0 -3 +1 = 4N+2P−F+1=6+0−3+1=4
但是移动2个像素才得出一个结果,所以公式变为
\frac{N + 2P - F}{2} + 1 = 1.5 + 1 = 2.52N+2P−F+1=1.5+1=2.5,如果相除不是整数的时候,向下取整,为2。这里并没有加上零填充。
所以最终的公式就为:
对于输入图片大小为N,过滤器大小为F,步长为S,零填充为P,
(\frac{N + 2P - F}{S} + 1),(\frac{N + 2P - F}{S} + 1)(SN+2P−F+1),(SN+2P−F+1)
3.1.5 多通道卷积
当输入有多个通道(channel)时(例如图片可以有 RGB 三个通道),卷积核需要拥有相同的channel数,每个卷积核 channel 与输入层的对应 channel 进行卷积,将每个 channel 的卷积结果按位相加得到最终的 Feature Map。
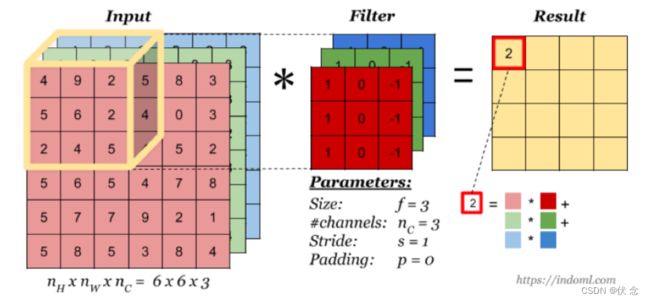
3.1.5.1 多卷积核(多个Filter)
当有多个卷积核时,可以学习到多种不同的特征,对应产生包含多个 channel 的 Feature Map, 例如上图有两个 filter,所以 output 有两个 channel。这里的多少个卷积核也可理解为多少个神经元。
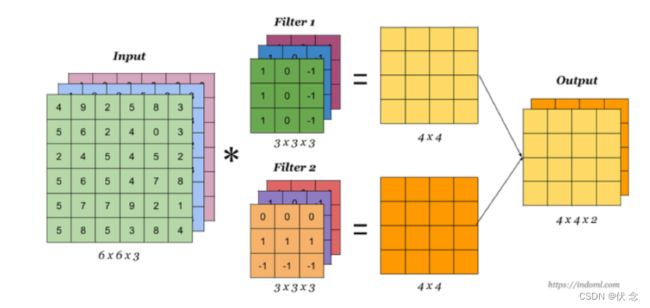
相当于我们把多个功能的卷积核的计算结果放在一起,能够检测到图片中不同的特征(边缘检测)
3.1.6 卷积总结
我们来通过一个例子看一下结算结果,以及参数的计算
- 假设我们有10 个Filter,每个Filter3 X 3 X 3(计算RGB图片),并且只有一层卷积,那么参数有多少?
计算:每个Filter参数个数为:3 3 3 + 1 bias = 28个权重参数,总共28 * 10 = 280个参数,即使图片任意大小,我们这层的参数也就这么多。
- 假设一张200 200 3的图片,进行刚才的FIlter,步长为1,最终为了保证最后输出的大小为200 * 200,需要设置多大的零填充
(\frac{N + 2P - F}{s} + 1) = N(sN+2P−F+1)=N
P = \frac{(N -1) * s + F - N}{2} = \frac{199 + 3 - 200}{2} = 1P=2(N−1)∗s+F−N=2199+3−200=1
卷积层充当特征提取的角色,但是并没有减少图片的特征数量,在最后的全连接层依然面临大量的参数,所以需要池化层进行特征数量的减少
3.1.7 池化层(Pooling)
池化层主要对卷积层学习到的特征图进行亚采样(subsampling)处理,主要由两种
- 最大池化:Max Pooling,取窗口内的最大值作为输出
- 平均池化:Avg Pooling,取窗口内的所有值的均值作为输出
意义在于:
- 降低了后续网络层的输入维度,缩减模型大小,提高计算速度
- 提高了Feature Map 的鲁棒性,防止过拟合
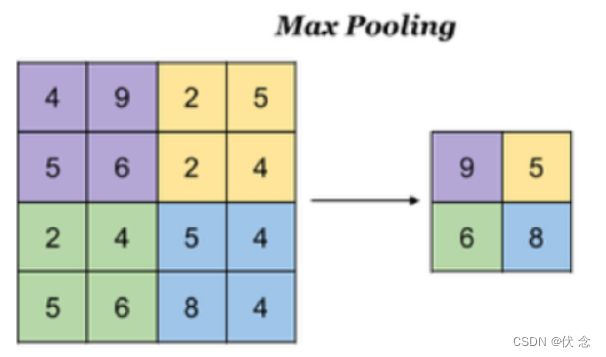
对于一个输入的图片,我们使用一个区域大小为2 2,步长为2的参数进行求最大值操作。同样池化也有一组参数,f, sf,s,得到2 2的大小。当然如果我们调整这个超参数,比如说3 * 3,那么结果就不一样了,通常选择默认都是f = 2 * 2, s = 2f=2∗2,s=2
池化超参数特点:不需要进行学习,不像卷积通过梯度下降进行更新。
如果是平均池化则:

3.1.8 全连接层
卷积层+激活层+池化层可以看成是CNN的特征学习/特征提取层,而学习到的特征(Feature Map)最终应用于模型任务(分类、回归):
- 先对所有 Feature Map 进行扁平化(flatten, 即 reshape 成 1 x N 向量)
- 再接一个或多个全连接层,进行模型学习
2.2 梯度下降算法改进
2.2.1 优化遇到的问题
- 梯度消失
- 局部最优
2.2.1.1 梯度消失
在梯度函数上出现的以指数级递增或者递减的情况分别称为梯度爆炸或者梯度消失。
假设g(z) = z, b^{[l]} = 0g(z)=z,b[l]=0,对于目标输出有:\hat{y} = W^{[L]}W^{[L-1]}...W^{[2]}W^{[1]}Xy^=W[L]W[L−1]...W[2]W[1]X
- 对于W^{[l]}W[l]的值大于 1 的情况,激活函数的值将以指数级递增;
- 对于W^{[l]}W[l]的值小于 1 的情况,激活函数的值将以指数级递减。
在计算梯度时,根据不同情况梯度函数也会以指数级递增或递减,导致训练导数难度上升,梯度下降算法的步长会变得非常小,需要训练的时间将会非常长。
2.2.1.2 局部最优
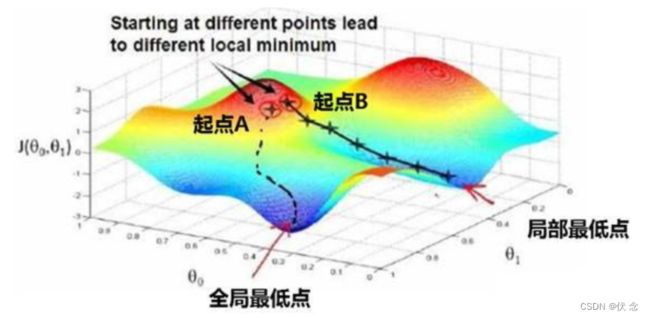
鞍点(saddle)是函数上的导数为零,但不是轴上局部极值的点。通常梯度为零的点是上图所示的鞍点,而非局部最小值。减少损失的难度也来自误差曲面中的鞍点,而不是局部最低点。

- 在训练较大的神经网络、存在大量参数,并且成本函数被定义在较高的维度空间时,困在极差的局部最优基本不会发生
- 鞍点附近的平稳段会使得学习非常缓慢,而这也是需要后面的动量梯度下降法、RMSProp 以及 Adam 优化算法能够加速学习的原因,它们能帮助尽早走出平稳段。
解决办法有多种形式,通常会结合一些形式一起进行
-
初始化参数策略(第一部分第四节提到)
-
Mini梯度下降法
- 梯度下降算法的优化
- 学习率衰减
2.2.2 参数初始化策略(复习)
由于在z={w}_1{x}_1+{w}_2{x}_2 + ... + {w}_n{x}_n + bz=w1x1+w2x2+...+wnxn+b公式中,当输入的数量n较大时,如果每个w_iwi的值都小一些,这样它们的和得到的zz也会非常大,所以会造成我们之前在第一部分最后一节当中介绍的。所以都会初始化比较小的值。
2.2.3 批梯度下降算法(Batch Gradient Descent)
- 定义:批梯度下降法(btach),即同时处理整个训练集。
其在更新参数时使用所有的样本来进行更新。对整个训练集进行梯度下降法的时候,我们必须处理整个训练数据集,然后才能进行一步梯度下降,即每一步梯度下降法需要对整个训练集进行一次处理,如果训练数据集很大的时候,处理速度就会比较慢。
所以换一种方式,每次处理训练数据的一部分进行梯度下降法,则我们的算法速度会执行的更快。
2.2.3.1 Mini-Batch Gradient Descent
- 定义:Mini-Batch 梯度下降法(小批量梯度下降法)每次同时处理固定大小的数据集。
不同
- 种类:
- mini-batch 的大小为 1,即是随机梯度下降法(stochastic gradient descent)
使用 Mini-Batch 梯度下降法,对整个训练集的一次遍历(epoch)只做 mini-batch个样本的梯度下降,一直循环整个训练集。
2.2.3.2 批梯度下降与Mini-Batch梯度下降的区别
batch梯度下降法和Mini-batch 梯度下降法代价函数的变化趋势如下:

那么对于梯度下降优化带来的影响
2.2.3.3 梯度下降优化影响
- batch 梯度下降法:
- 对所有 m 个训练样本执行一次梯度下降,每一次迭代时间较长,训练过程慢;
- 相对噪声低一些,成本函数总是向减小的方向下降。
- 随机梯度下降法(Mini-Batch=1):
- 对每一个训练样本执行一次梯度下降,训练速度快,但丢失了向量化带来的计算加速;
- 有很多噪声,需要适当减小学习率,成本函数总体趋势向全局最小值靠近,但永远不会收敛,而是一直在最小值附近波动。
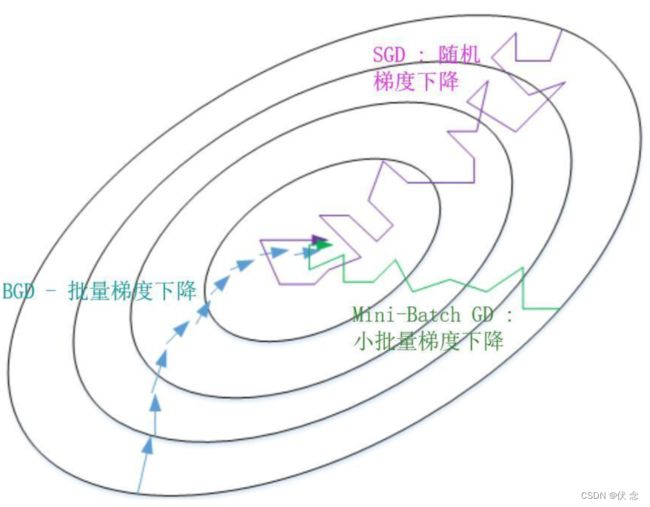
因此,选择一个合适的大小进行 Mini-batch 梯度下降,可以实现快速学习,也应用了向量化带来的好处,且成本函数的下降处于前两者之间。
2.2.3.4 大小选择
- 如果训练样本的大小比较小,如m\le2000m≤2000时,选择 batch 梯度下降法;
- 如果训练样本的大小比较大,选择 Mini-Batch 梯度下降法。为了和计算机的信息存储方式相适应,代码在 mini-batch 大小为 2 的幂次时运行要快一些。典型的大小为2^6, 2^7,2^8,2^926,27,28,29,mini-batch 的大小要符合 CPU/GPU 内存计算机制。
需要根据经验快速尝试,找到能够最有效地减少成本函数的值。
那么第二种方式是通过优化梯度下降过程,会比梯度下降算法的速度更快些
2.2.7 Adam算法
Adam 优化算法(Adaptive Moment Estimation,自适应矩估计)将 Momentum 和 RMSProp 算法结合在一起。
假设用每一个 mini-batch 计算 dW、db,第tt次迭代时:
v_{dW} = \beta_1 v_{dW} + (1 - \beta_1) dWvdW=β1vdW+(1−β1)dW
v_{db} = \beta_1 v_{db} + (1 - \beta_1) dbvdb=β1vdb+(1−β1)db
v^{corrected}_{dW^{[l]}} = \frac{v_{dW^{[l]}}}{1 - (\beta_1)^t}vdW[l]corrected=1−(β1)tvdW[l]
s_{dW} = \beta_2 s_{dW} + (1 - \beta_2) {(dW)}^2sdW=β2sdW+(1−β2)(dW)2
s_{db} = \beta_2 s_{db} + (1 - \beta_2) {(db)}^2sdb=β2sdb+(1−β2)(db)2
s^{corrected}_{dW^{[l]}} = \frac{s_{dW^{[l]}}}{1 - (\beta_1)^t}sdW[l]corrected=1−(β1)tsdW[l]
其中ll为某一层,tt为移动平均第次的值
Adam 算法的参数更新:

2.2.8 TensorFlow Adam算法API
- tf.train.AdamOptimizer(learning_rate=0.001, beta1=0.9, beta2=0.999,epsilon=1e-08,name='Adam')
Adam 优化算法有很多的超参数:
- 学习率\alphaα:需要尝试一系列的值,来寻找比较合适的
- β1:常用的缺省值为 0.9
- β2:Adam 算法的作者建议为 0.999
- ϵ:Adam 算法的作者建议为epsilon的默认值1e-8
注:β1、β2、ϵ 通常不需要调试
2.2.9 学习率衰减
如果设置一个固定的学习率 α
- 在最小值点附近,由于不同的 batch 中存在一定的噪声,因此不会精确收敛,而是始终在最小值周围一个较大的范围内波动。
- 如果随着时间慢慢减少学习率 α 的大小,在初期 α 较大时,下降的步长较大,能以较快的速度进行梯度下降;而后期逐步减小 α 的值,即减小步长,有助于算法的收敛,更容易接近最优解。
最常用的学习率衰减方法:\alpha = \frac{1}{1 + decay\_rate * epoch\_num} * \alpha_0α=1+decay_rate∗epoch_num1∗α0
其中,decay_rate为衰减率(超参数),epoch_num为将所有的训练样本完整过一遍的次数。
还有一种指数衰减
- \alpha = 0.95^{epoch\_num} * \alpha_0α=0.95epoch_num∗α0
对于大型的数据模型,需要使用这些方式去自动进行学习率衰减。而一些小型网络可以直接手动进行调整
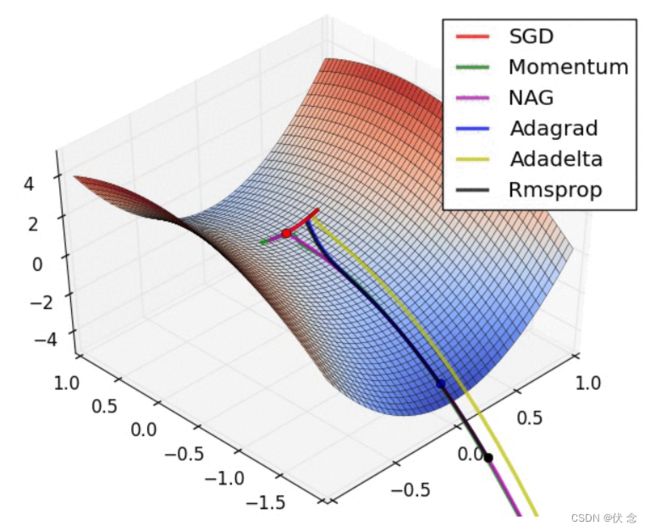
那么最后我们来看一张动态度,表示不同优化的算法的效果图
2.2.10 其它非算法优化的方式-标准化输入
对网络输入的特征进行标准化,能够缓解梯度消失或者梯度爆炸
- 标准化公式:
- x = \frac{x - \mu}{\sigma}x=σx−μ
这个公式其实与特征工程中的处理是一样的,\muμ为平均值,\sigmaσ为标准差。标准化的目的是所有特征的平均值为0,标准差为1。这属于机器学习基本的内容不过多进行叙述。

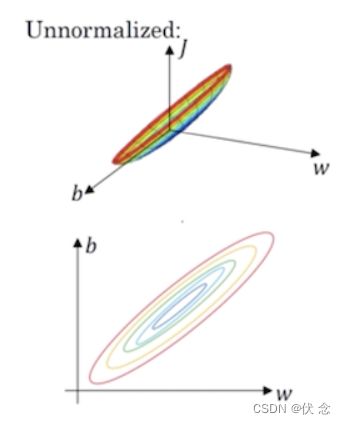
那么这种有什么好处?主要是对于损失函数带来的好处.
- 标准化前的损失函数
- 标准化后的损失函数
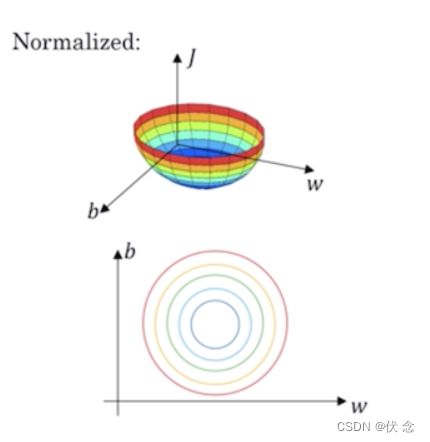
这样的话,对于梯度下降无论从哪个位置开始迭代,都能以相对较少的迭代次数找到全局最优解。可以加速网络的学习。
理解这个原理,其实还是最初的这样的公式:z={w}_1{x}_1+{w}_2{x}_2 + ... + {w}_n{x}_n + bz=w1x1+w2x2+...+wnxn+b
如果激活函数的输入X近似设置成均值为 0,标准方差为 1,神经元输出 z 的方差就正则化到1了。虽然没有解决梯度消失和爆炸的问题,但其在一定程度上确实减缓了梯度消失和爆炸的速度。
2.2.11 神经网络调优
我们经常会涉及到参数的调优,也称之为超参数调优。目前我们从第二部分中讲过的超参数有
- 算法层面:
- 学习率\alphaα
- \beta1,\beta2, \epsilonβ1,β2,ϵ: Adam 优化算法的超参数,常设为 0.9、0.999、10^{-8}10−8
- \lambdaλ:正则化网络参数,
- 网络层面:
- hidden units:各隐藏层神经元个数
- layers:神经网络层数
2.2.11.1 调参技巧
对于调参,通常采用跟机器学习中介绍的网格搜索一致,让所有参数的可能组合在一起,得到N组结果。然后去测试每一组的效果去选择。
假设我们现在有两个参数
\alphaα: 0.1,0.01,0.001,\betaβ:0.8,0.88,0.9
这样会有9种组合,[0.1, 0.8], [0.1, 0.88], [0.1, 0.9]…….
- 合理的参数设置
- 学习率\alphaα:0.0001、0.001、0.01、0.1,跨度稍微大一些。
- 算法参数\betaβ, 0.999、0.9995、0.998等,尽可能的选择接近于1的值
注:而指数移动平均值参数:β 从 0.9 (相当于近10天的影响)增加到 0.9005 对结果(1/(1-β))几乎没有影响,而 β 从 0.999 到 0.9995 对结果的影响会较大,因为是指数级增加。通过介绍过的式子理解S_{100} = 0.1Y_{100} + 0.1 * 0.9Y_{99} + 0.1 * {(0.9)}^2Y_{98} + ...S100=0.1Y100+0.1∗0.9Y99+0.1∗(0.9)2Y98+...
2.2.11.2 运行
通常我们有这么多参数组合,每一个组合运行训练都需要很长时间,但是如果资源允许的话,可以同时并行的训练多个参数模型,并观察效果。如果资源不允许的话,还是得一个模型一个模型的运行,并时刻观察损失的变化
所以对于这么多的超参数,调优是一件复杂的事情,怎么让这么多的超参数范围,工作效果还能达到更好,训练变得更容易呢?
2.2.12 批标准化(Batch Normalization)
Batch Normalization论文地址:https://arxiv.org/abs/1502.03167
其中最开头介绍是这样的:
训练深度神经网络很复杂,因为在训练期间每层输入的分布发生变化,因为前一层的参数发生了变化。这通过要求较低的学
习率和仔细的参数初始化来减慢训练速度,并且使得训练具有饱和非线性的模型变得非常困难。我们将这种现象称为** 内部协
变量偏移** ,并通过 **标准化层** 输入来解决问题。我们的方法的优势在于使标准化成为模型体系结构的一部分,并为每
个培训小批量执行标准化。批量标准化允许我们使用更高的学习率并且不太关心初始化。它还可以充当调节器,在某些情况
下可以消除对Dropout的需求。应用于最先进的图像分类模型,批量标准化实现了相同的精度,培训步骤减少了14倍,并
且显着地超过了原始模型。使用批量标准化网络的集合,我们改进了ImageNet分类的最佳发布结果:达到4.9%的前5个
验证错误(和4.8%的测试错误),超出了人类评估者的准确性。
2.2.12.2 过程图

每一层中都会有两个参数\beta, \gammaβ,γ。
注:原论文的公式图

2.4.2.2 为什么批标准化能够是优化过程变得简单
我们之前在原文中标记了一个问题叫做叫做"internal covariate shift"。这个词翻译叫做协变量偏移,但是并不是很好理解。那么有一个解释叫做 在网络当中数据的分布会随着不同数据集改变 。这是网络中存在的问题。那我们一起来看一下数据本身分布是在这里会有什么问题。

也就是说如果我们在训练集中的数据分布如左图,那么网络当中学习到的分布状况也就是左图。那对于给定一个测试集中的数据,分布不一样。这个网络可能就不能准确去区分。这种情况下,一般要对模型进行重新训练。
Batch Normalization的作用就是减小Internal Covariate Shift 所带来的影响,让模型变得更加健壮,鲁棒性(Robustness)更强。即使输入的值改变了,由于 Batch Normalization 的作用,使得均值和方差保持固定(由每一层\gammaγ和\betaβ决定),限制了在前层的参数更新对数值分布的影响程度,因此后层的学习变得更容易一些。Batch Normalization 减少了各层 W 和 b 之间的耦合性,让各层更加独立,实现自我训练学习的效果
2.3.13.3 BN总结
Batch Normalization 也起到微弱的正则化效果,但是不要将 Batch Normalization 作为正则化的手段,而是当作加速学习的方式。Batch Normalization主要解决的还是反向传播过程中的梯度问题(梯度消失和爆炸)。
2.5 CNN网络实战技巧
学习目标
我们来看一个个问题如果我们要做一个具体场景的计算机视觉任务,那么从头开始训练一个网络是合适的选择吗?怎么样才能避免浪费过多的计算时间?
2.5.1 迁移学习(Transfer Learning)
2.5.1.1 介绍
- 定义
- 迁移学习就是利用数据、任务或模型之间的相似性,将在旧的领域学习过或训练好的模型,应用于新的领域这样的一个过程。
- 两个任务的输入属于同一性质:要么同是图像、要么同是语音或其他
迁移学习到底在什么情况下使用呢?有两个方面需要我们考虑的
- 1、当我们有海量的数据资源时,可以不需要迁移学习,机器学习系统很容易从海量数据中学习到一个鲁棒性很强的模型。但通常情况下,我们需要研究的领域可获得的数据极为有限,在少量的训练样本上精度极高,但是泛化效果极差。
- 2、训练成本,很少去从头开始训练一整个深度卷积网络,从头开始训练一个卷积网络通常需要较长时间且依赖于强大的 GPU 计算资源。
2.5.1.2 方法
- 最常见的称呼叫做fine tuning,即微调
- 已训练好的模型,称之为Pre-trained model
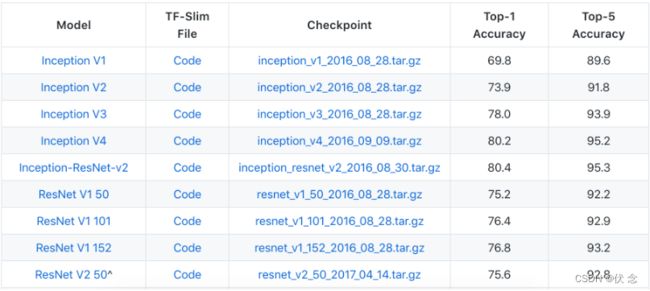
通常我们需要加载以训练好的模型,这些可以是一些机构或者公司在ImageNet等类似比赛上进行训练过的模型。TensorFlow同样也提供了相关模型地址:models/research/slim at master · tensorflow/models · GitHub
下图是其中包含的一些模型:
2.5.1.3 过程
这里我们举一个例子,假设有两个任务A和B,任务 A 拥有海量的数据资源且已训练好,但并不是我们的目标任务,任务 B 是我们的目标任务。下面的网络模型假设是已训练好的1000个类别模型

而B任务假设是某个具体场景如250个类别的食物识别,那么该怎么去做
- 1、建立自己的网络,在A的基础上,修改最后输出结构,并加载A的模型参数
- 2、根据数据大小调整
- 如果B任务数据量小,那么我们可以选择将A模型的所有的层进行freeze(可以通过Tensorflow的trainable=False参数实现),而剩下的输出层部分可以选择调整参数训练
- 如果B任务的数据量大,那么我们可以将A中一半或者大部分的层进行freeze,而剩下部分的layer可以进行新任务数据基础上的微调