论文笔记SKEP: Sentiment Knowledge Enhanced Pre-training for Sentiment Analysis
SKEP: Sentiment Knowledge Enhanced Pre-training for Sentiment Analysis情感分析的情感知识增强预训练
Abstract
Sentiment Knowledge Enhanced Pre-training (SKEP),以学习多个情绪分析任务的统一情绪表示。在自动挖掘的知识的帮助下,SKEP进行情感掩蔽,构建三个情感知识预测目标,将词级、极性级和方面级的情感信息嵌入到预训练的情感表示中。In particular, the prediction of aspect-sentiment pairs is converted into multi-label classification, aiming to capture the dependency between words in a pair.
1 Introduction
情感分析涉及广泛任务,如句子层面的情感分类、方面层面的情绪分类、观点提取等。传统方法通常是分别研究这些任务
有许多具体的情感任务,这些任务通常取决于不同类型的情感知识,包括情感词,词极性和方面-情感对。我们假设,通过将这些知识整合到预训练过程中,学到的表示将更情绪化。
为了学习多个情绪分析任务的统一情绪表示,我们提出了Sentiment Knowledge Enhanced Pre-training(SKEP),其中包括sentiment knowledge about words,极性,和方面-情感对指导预训练的过程。首先从未标记的数据中自动挖掘情感知识(第3.1节)。With the knowled gemined,情感掩蔽(第3.2节)从输入文本中删除情感信息。然后,对预训练模型进行训练,以恢复具有三个情感目标的情感信息(第3.3节)。
SKEP将不同类型的情感知识整合在一起,为各种情感分析任务提供统一的情感表示。这是完全不同于传统的情绪分析方法,如下:
1)、SKEP为多个情感分析任务提供了统一的情感表示。
2)、在预训练过程中,三个情感知识预测目标被联合优化,以嵌入情感词,极性,方面-情感对的表示。尤其是方面情感对预测转换成多标签分类获取方面和情感之间的依赖关系。
3)、三种典型的情感任务SKEP 超越 RoBERTa (Liu et al.,2019)
2 BERT and RoBERTa
BERT (Devlin et al., 2019) is a self-supervised representation learning approach for pre-training a deep transformer encoder (Vaswani et al., 2017).BERT构建了一个自监督目标,称为masked language modeling (MLM) ,to pre-train the transformer encoder,并且只依赖于large-size unlabeled data.本文遵循BERT的方法来构造掩蔽目标进行预训练。
BERT learns a transformer encoder that 可以为输入序列的每个标记产生上下文表示.实际上,一个输入序列的第一个标记是一个特殊的分类标记【CLS】。[CLS]的最终隐藏状态通常用作输入序列的整体语义表示。In order to train the transformer encoder, MLM is proposed.类似于做完形填空,MLM根据占位符的预测序列中的屏蔽标记。 具体来说, parts of input tokens 被随机采样和替换。BERT统一选择15%的输入令牌。在这些抽样的令牌中,80%被替换为一个特殊的屏蔽令牌【MASK】,10%替换为随机令牌,其余10%保持不变。MLM目的是预测原始令牌在蒙面位置使用相应的最终状态。
RoBERTa在不改变神经元结构的情况下,优化的性能显著优于BERT,成为最优的预训练模型之一, RoBERTa还从标准bert中删除了下一个句子预测目标。为了验证我们的方法的有效性,本文使用RoBERTa作为一个强大的基线。
3 SKEP: Sentiment Knowledge Enhanced Pre-training

Figure 1: SKEP contains two parts: (1) 情感掩蔽识别输入序列中的的情感信息,基于自动挖掘的情感知识,并通过删除这些信息产生一个损坏的版本。 (2)情感预训练目标要求transformer从损坏的版本中恢复删除的信息。最上面的三个预测目标是共同优化的:情绪词(SW)预测(在x9上),词极性(SP)(在X6和X9),Aspect-Sentiment对(AP)的预测(x1) 笑脸符号表示正极性。值得注意的是,在x6上,只计算SP而不计算SW,因为其原词在x1上的 pair prediction 中已被预测.
SKEP, 通过自我监督训练将情感知识融入其中。图片1, SKEP包含情感掩蔽和情感预训练目标. 情感掩蔽(3.2节)基于自动挖掘情感知识(3.1节)识别输入序列的情感信息,并通过删除该信息产生一个损坏的版本。三个情感预训练目标(第3.3节)要求transformer 为损坏的版本恢复情感信息。
.因此,the transformer encoder可以与情绪的预训练目标训练,通过恢复情绪信息,using the final states of encoder ex1, …, exn.
3.1 无监督情感知识挖掘
SKEP 未标签数据中挖掘情感知识。挖掘方法基于 (PMI) (Turney, 2002).
PMI方法仅依赖于少量的情感种子词,给出了每个种子词的词极性WP(s)。它首先建立一个候选词对的集合,每个词对包含一个种子词,并满足预定义的词性模式。然后,一个词对的共现用PMI计算如下:

在这里,p(.)表示通过计数估计的概率。最后,一个词的极性是由其PMI得分和所有正种子及负种子之间的差异决定的。
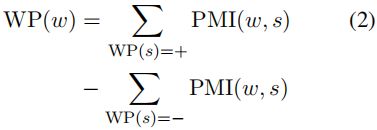
If WP(w) of a candidate word w is larger than 0,then w is a positive word, otherwise it is negative.
挖掘情感词后,通过简单的约束提取方面情感对。一个情感词与其最近的名词将被视为一个方面-情感对。 aspect word and the sentiment word 最大距离被经验地限制为不超过3令牌。
因此,所挖掘的情感知识G包含一组具有极性的情感词以及一组方面-情感对。研究主要集中在通过一种相对常见的挖掘方法将情感知识整合到预训练中的必要性。
3.2 Sentiment Masking情感掩蔽
目的是建立一个损坏的版本,每个输入序列的情感信息被掩盖。我们的情感掩蔽是以情感知识为导向的,与以往的随机词掩蔽有很大不同。这个过程包括情感检测和混合情感掩蔽。基于知识的情感检测通过匹配输入序列和挖掘的情感知识G来识别情感词和方面情感对。
1、情感词检测。
如果输入序列中的一个词也出现在知识库G中,那么这个词就被视为情感词。
2. Aspect-Sentiment Pair Detection.
类似于之前它的挖掘描述。 A detected sentiment word and its nearby noun word are considered as an aspect-sentiment pair candidate,and the maximum distance of these two words is limited to 3. 因此,如果这样的 candidate也被发现在挖掘的知识G,那么它被认为是一个方面感情对。
混合情感掩蔽情感检测 results in输入序列的三种标记类型:方面-情感对,情感词和普通标记。屏蔽序列的过程按以下步骤进行:
(1)、 Aspect-sentiment Pair Masking. 最多2个方面情绪对被随机选择 to mask。All tokens of a pair 同时被【MASK】替换。这种掩蔽提供了一种捕获an aspect word and a sentiment word的组合的方法。
(2)、 Sentiment Word Masking. 对于未屏蔽的情感词,随机选取其中的一部分,同时将其所有的标记替换为【MASK】。此步骤中屏蔽的令牌总数被限制为小于10%。
(3)、Common Token Masking.如果步骤2中的令牌数量不足,比如少于10%,this would be filled during this step with randomly-selected tokens. Here, random token masking is the same as RoBERTa
3.3 情感预训练目标
情感掩蔽产生损坏的令牌序列X~,其中他们的情感信息被替换为masked tokens。三个目标,Sentiment Word (SW):Lsw,Word Polarity (WP) Lwp,Aspect-sentiment Pair (AP): Lap ,联合优化。因此,总的训练前目标L是:
![]()
Sentiment Word Prediction 情感词预测是利用 transformer encoder的输出向量 exi来恢复情感词的屏蔽标记。exi被输入一个softmax层,该层在整个词汇表上产生一个归一化的概率向量 ˆyi.
sentiment word Lsw就是最大化原始情感词xi的概率如下:

W和b是输出层的参数。如果序列的i-th位置被屏蔽了感情词,则mi=1,否则它等于0。yi is the one-hot representation of the original token xi.
情感词在情感分析中起着关键性的作用,the representation learned here is expected to be more suitable for sentiment analysis.
Word Polarity Prediction
词的极性对于情绪分析是至关重要的。 Lwp is similar to Lsw。对于每个蒙面情感令牌xi~,Lwp使用最终状态 xi~ 计算其极性(正或负),然后目标的极性对应于原始情感词的极性。
Aspect-sentiment Pair Prediction
Aspect sentiment pairs 揭示更多的信息 ,为了捕获方面和情感之间的依赖关系,提出方面情感对目标。特别是成对出现的词并不互斥。这与BERT有很大不同,BERT假设令牌可以独立预测。
因此,我们用多标签分类进行方面-情感对预测。我们使用的分类令牌[CLS]的最终状态来预测对,这表示整个序列的representation。利用Sigmoid激活函数,它允许在输出中同时出现多个令牌。方面-情感对目标Lap表示如下:

x1表示[CLS]的输出向量。A是在一个损坏的序列中被屏蔽的方面-情感对的数量。 ˆya is the word probability normalized by sigmoid. ya是目标方面-情感对的稀疏表示。 ya的每个元素对应于词汇表中的一个标记,如果目标方面情绪对包含相应的标记,则等于1。由于ya等于1有多个元素,这里的预测是多标签分类。
4 Fine-tuning for Sentiment Analysis
我们验证了三个典型的情绪分析任务:句子级的情绪分类,方面级情绪分类和意见角色标记。On top of the pre-trained transformer encoder,增加了一个输出层来执行特定任务的预测。然后在具体任务的标记数据上微调网络。
Sentence-level Sentiment Classification 这个任务是分类输入句的情感极性。分类令牌【CLS】的最终状态向量用作输入语句的整体表示形式。 On top of the transformer encoder,增加了一个分类层来计算基于总体表示的情感概率。
Aspect-level Sentiment Classification 这个任务的目的是当给定一个上下文文本时,分析方面的细粒度情感。Thus, there are two parts in the input: aspect description and contextual text.这两个部分结合在一起用[SEP] ,and fed into the transformer encoder. This task also utilizes the final state of the first token [CLS] for classification.
Opinion Role Labeling 这个任务是从输入文本中检测细粒度的意见,比如: holder and target。在SRL4ORL (Marasovi´c and Frank, 2018)之后,这个任务被转换成序列标记,它使用BIOS方案进行标记,并添加一个CRF层来预测标签。
5 Experiment
5.1 Dataset and Evaluation数据集和评价

表1总结了实验中使用的数据集的统计数据。这些数据集包含三种类型的任务:
(1) 对于句子层面的情感分类,Standford Sentiment Treebank (SST-2) (Socher et al., 2013) and Amazon-2 (Zhang et al., 2015)。在Amazon-2中,原有训练数据有400k被保留下来用于开发。在准确度方面,性能被评估。
(2) 在SemanticEval2014Task4上对方面情感分类进行了评估。该任务包含餐厅领域和笔记本电脑领域,其准确性分别进行评估。
(3) .对于意见角色标签,MPQA2.0数据集。MPQA aims to extract the targets or the holders of the opinions.。在这里,我们遵循SRL4ORL中的评估方法。4-folder cross-validation is performed, and the F-1 scores of both holder and target are reported.
要执行SKEP的情绪预训练,Amazon-2的训练部分被使用,这是表1中最大的数据集。预训练只使用原始文本,没有任何情感注释。为了减少对人工构建的知识的依赖,并提供SKEP用最少的监督,我们只使用46情绪种子词。有关种子词的详细资料,请参阅附录。.
5.2 Experiment Setting

RoBERTa是baseline. For SKEP, the transformer encoder is first initialized初始化 with RoBERTa, then is pre-trained on sentiment unlabeled data. 输入序列被截为512个令牌。学习率保持为5e5,批量为8192。The number of epochs is set to 3. 对于每个数据集的微调,我们为每个参数组合用随机种子运行3次(Table 2),and choose the medium checkpoint 检查点for testing according to the performance on the development set.
5.3 Main Results

We compare our SKEP method with the strong pretraining baseline RoBERTa and previous SOTA.The result is shown in Table 3.
相比RoBERTa, SKEP 显著提高了性能 on both base and large settings. Even on RoBERTalarge,SKEP achieves an improvement of up to 2.4 points.SKEP 显著提高性能 on fine-grained tasks, aspect-level classification and opinion role labeling, which are supposed to be more difficult than sentence-level classification.这归功于 the aspect-sentiment knowledge对这些任务非常有效. Interestingly, “RoBERTabase + SKEP” always outperforms RoBERTalarge, except on Amazon-2. 由于Roberta的大版本在计算上很昂贵,所以SKEP的基础版本为应用提供了一个有效的模型.Compared with previous SOTA, SKEP在几乎所有数据集上都取得了新的最先进的结果,只有在SST-2上取得了不太满意的结果。
总体而言,通过各种情绪任务的比较,结果有力地验证了将情绪知识的预训练方法的必要性,以及我们提出的情绪预训练的方法的有效性。
5.4 Detailed Analysis

Effect of Sentiment Knowledge SKEP使用额外的情感数据进行进一步的预训练,并利用三个目标,以纳入三种类型的知识。表4比较了这些因素的贡献。 Further pre-training with random sub-word masking of Amazon, Robertabase obtains some improvements. 这证明了大尺寸具体任务未标记数据的价值。 However, the improvement is less evident compared with sentiment word masking. This indicates that the importance of sentiment word knowledge.进一步的改进时,单词极性和方面感情对目标的补充,得到了进一步改进时,确认这两种类型的知识的贡献 . Compare “+SW+WP+AP” with “+Random Token”, the improvements are consistently significant in all evaluated data and is up to about 1.5 points.
.总体而言,从目标的比较,我们得出结论,情绪知识是有帮助的,更多样化的知识导致更好的性能。这也鼓励我们在未来使用更多的知识类型,使用更好的挖掘方法。
提出多标签优化多标签分类的效果,是为了处理在方面情感对中的依赖。为了确认捕获的Aspect-sentiment对中的词的依赖性的必要性,我们还比较了它与标记被独立预测的方法,这是由AP-I表示的方法。AP-I使用softmax归一化,独立预测的 word of a pair作为情绪词预测。根据表4中包含AP-I的最后一行,独立预测一对词不会影响句子级分类的性能。这是合理的,因为句子级任务主要依赖于情感词。相比之下,在方面级别的分类和意见角色标签,多标签分类是有效的,提高到0.6点。这表明多标签分类确实能更好地捕捉方面和情感之间的依赖关系,以及处理这种依赖关系的必要性。

面向方面情感对预测的向量比较SKEP利用句子表示,这(句子表示)是分类标记[CLS]的最终状态,用于方面-感情对预测。我们称之为Sent-Vector方法。另一种方法是将两个词的最后一个向量串在一起,我们称之为pair-vector。如表6所示,这两个决策的性能非常接近。我们认为这归因于鲁棒性的预训练方法。由于使用一个单一的向量进行预测是更有效的,我们使用令牌[CLS]在SKEP的最终状态。

注意可视化表5显示了[CLS]标记在对输入句子进行分类时的注意分布。在SST-2的例子中,尽管Roberta给出了正确的预测,但它对情绪的关注是不准确的。在Sem-L一例中,Roberta没有注意到“amazing”这个词,而产生了一个错误的预测。相反,SKEP 在两种情况下都会产生正确的预测和对情绪信息的适当关注,这表明SKEP 具有更好的可解释性。
6 Related Work
具有极性的情感词被广泛用于情感分析,包括:sentence-level sentiment classification (Taboada et al., 2011;Shin et al., 2017; Lei et al., 2018; Barnes et al.,2019), aspect-level sentiment classification (Vo and Zhang, 2015), opinion extraction (Li and Lam,2017), emotion analysis (Gui et al., 2017; Fan et al.,2019) 等。
基于词典方法 (Turney,2002; Taboada et al., 2011) 直接利用情感词的极性进行分类。
传统的基于特征的方法在人工设计的特征中编码情感词信息,以改进监督模型(Pang et al., 2008;Agarwal et al., 2011).
相比之下,深度学习方法通过情感词的帮助来增强嵌入表示 (Shin et al., 2017),或通过语言正则化来吸收情感知识 (Qian et al., 2017; Fan et al.,2019).
Aspect-sentiment pair knowledge is also useful for aspect-level classification and opinion extraction. 以前的工作通常对这种类型的知识提供弱监督,either for aspect-level classification (Zeng et al., 2019) or for opinion extraction (Yang et al., 2017; Ding et al., 2017).
虽然多年来对情感知识的利用进行了研究,但大多数研究倾向于为每个情感分析任务建立特定的机制,因此采用不同的知识来支持不同的任务。而我们的方法采用不同的知识,在预训练情绪分析任务提供一个统一的情绪表示。
预训练方法显着提高了自然语言处理,使用大规模的未标记数据的自我监督训练。最近,这一研究领域取得了巨大的进展,提出了各种类型的方法,包括 including ELMO (Peters et al., 2018), GPT (Radford et al., 2018), BERT(Devlin et al., 2019), XLNet (Yang et al., 2019)等.
Among them, BERT pre-trains a bidirectional transformer by randomly masked word prediction, and have shown strong performance gains. RoBERTa (Liu et al., 2019) further improves BERT by robust optimization, and become one of the best pretraining methods. 受BERT的启发, some works propose fine-grained objectives beyond random word masking.SpanBERT (Joshi et al., 2019) 同时掩盖了文字的跨度masks the span of words at the same time. ERNIE (Sun et al.,2019) 建议屏蔽实体词proposes to mask entity words. On the other hand, pre-training for specific tasks is also studied. GlossBERT (Huang et al., 2019) exploits gloss knowledge提高词义消歧。SenseBERT (Levine et al., 2019) uses WordNet super-senses来改善单词上下文任务. A different ERNIE (Zhang et al., 2019) 利用实体知识进行实体链接和关系分类。