Proximal Policy Optimization(PPO)算法实现gym连续动作空间任务Pendulum-v0(pytorch)
目录
1.ppo算法概述
2.Pendulum-v0
3.代码实现
1.ppo算法概述
- PG算法
视频参考李宏毅强化学习课程:李宏毅深度强化学习(国语)课程(2018)_哔哩哔哩_bilibili

上图表示actor与环境交互的一次经过,从开始的状态s1,actor输出a1到环境状态变为s2...直到st环境判断一次游戏结束。我们收集到了一次的游戏轨迹称为一个episode。
那么我们可以计算完成这次episode的概率为:

序列τ所获得的奖励为每个阶段所得到的奖励的和,称为R(τ)。因此,在Actor的策略为π的情况下,所能获得的期望奖励为:

而我们的期望是调整Actor的策略π,使得期望奖励最大化,于是我们有了策略梯度的方法,既然我们的期望函数已经有了,我们只要使用梯度提升的方法更新我们的网络参数θ(即更新策略π)就好了,所以问题的重点变为了求参数的梯度。梯度的求解过程如下:

上面的过程中,我们首先利用log函数求导的特点进行转化,随后用N次采样的平均值来近似期望,最后,我们将pθ展开,将与θ无关的项去掉,即得到了最终的结果。
所以,一个PG方法的完整过程如下:

2.ppo
ppo是再PG算法的基础上加了策略更新的限制,即不允许下一次更新与上一次的策略相差太大。具体不在这赘述详细可以去看上面连接的李宏毅老师的视频。
下面代码的实现是采用clip ppo的方式。
2.Pendulum-v0
倒立摆摆摆问题是控制文献中的经典问题。在这个问题的版本中,钟摆从一个随机位置开始,目标是向上摆动,使其保持直立。

动作空间:
-2到2之间连续动作空间,表示向左或向右的方向和力度

输出的状态s:
这些观测值对应于摇锤末端的x-y坐标及其角速度。例:[x, y, Angular Velocity]
3.代码实现
代码使用pytorch框架,采用AC结构
1.引用的库
import gym
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np2.超参数
env = gym.make('Pendulum-v0')
EP_MAX = 10000
HORIZON = 128
LR_v = 2e-5
LR_pi = 2e-5
K_epoch = 8
GAMMA = 0.99
LAMBDA = 0.95
CLIP = 0.23.程序主干
ps :reward进行了修正目的是为了加速模型收敛
def main():
agent = Agent()
agent.load()
max_rewards = -1000000
for _ in range(EP_MAX):
s = env.reset()
start = True
rewards = 0
while start:
for i in range(HORIZON):
env.render()
a = agent.choose_action(torch.tensor([s], dtype=torch.float))
s_, r, done, info = env.step([a])
rewards += r
agent.push_data((s, a, (r + 8.1) / 8.1, s_, done))
if done:
start = False
break
s = s_
agent.updata()
if _ % 10 == 0:
print(_, ' ', rewards, ' ', agent.step)
if max_rewards < rewards:
max_rewards = rewards
agent.save()
if __name__ == '__main__':
main()4.pi网络和v网络搭建:
class Pi_net(nn.Module):
def __init__(self):
super(Pi_net, self).__init__()
self.net = nn.Sequential(
nn.Linear(3, 64),
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 256),
nn.ReLU(),
)
self.mu = nn.Linear(256, 1)
self.sigma = nn.Linear(256, 1)
self.optim = torch.optim.Adam(self.parameters(), lr=LR_pi)
def forward(self, x):
x = self.net(x)
mu = torch.tanh(self.mu(x)) * 2
sigma = F.softplus(self.sigma(x)) + 0.001
return mu, sigma这里要注意的是我们输出的动作是一个连续的动作,所以我们让神经网络输出期望(mu)和方差(sigma)根据mu和sigma使用torch.distributions.normal.Normal(mu, sigma)来构建一个正态分
布然后从中采用得出一个再-2到2之间的值。正因为我们要输出的动作大小有限制所以我们输出mu应当在-2到2之间。所以我们将输出的mu值经过tanh映射到-1到1之间再乘以2。同理由于方差为正所以让输出的方差经过softplus(RLUE的升级版)再加一个偏置就恒大于0了
class V_net(nn.Module):
def __init__(self):
super(V_net, self).__init__()
self.net = nn.Sequential(
nn.Linear(3, 64),
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 256),
nn.ReLU(),
nn.Linear(256, 1),
)
self.optim = torch.optim.Adam(self.parameters(), lr=LR_v)
def forward(self, x):
x = self.net(x)
return x4.构建agent
class Agent(object):
def __init__(self):
self.v = V_net()
self.pi = Pi_net()
self.old_pi = Pi_net() #旧策略网络
self.old_v = V_net() #旧价值网络 用于计算上次更新与下次更新的差别
#ratio
self.load()
self.data = [] #用于存储经验
self.step = 0
def choose_action(self, s):
with torch.no_grad():
mu, sigma = self.old_pi(s)
dis = torch.distributions.normal.Normal(mu, sigma) #构建分布
a = dis.sample() #采样出一个动作
return a.item()
def push_data(self, transitions):
self.data.append(transitions)
def sample(self):
l_s, l_a, l_r, l_s_, l_done = [], [], [], [], []
for item in self.data:
s, a, r, s_, done = item
l_s.append(torch.tensor([s], dtype=torch.float))
l_a.append(torch.tensor([[a]], dtype=torch.float))
l_r.append(torch.tensor([[r]], dtype=torch.float))
l_s_.append(torch.tensor([s_], dtype=torch.float))
l_done.append(torch.tensor([[done]], dtype=torch.float))
s = torch.cat(l_s, dim=0)
a = torch.cat(l_a, dim=0)
r = torch.cat(l_r, dim=0)
s_ = torch.cat(l_s_, dim=0)
done = torch.cat(l_done, dim=0)
self.data = []
return s, a, r, s_, done
def updata(self):
self.step += 1
s, a, r, s_, done = self.sample()
for _ in range(K_epoch):
with torch.no_grad():
'''loss_v'''
td_target = r + GAMMA * self.old_v(s_) * (1 - done)
'''loss_pi'''
mu, sigma = self.old_pi(s)
old_dis = torch.distributions.normal.Normal(mu, sigma)
log_prob_old = old_dis.log_prob(a)
td_error = r + GAMMA * self.v(s_) * (1 - done) - self.v(s)
td_error = td_error.detach().numpy()
A = []
adv = 0.0
for td in td_error[::-1]:
adv = adv * GAMMA * LAMBDA + td[0]
A.append(adv)
A.reverse()
A = torch.tensor(A, dtype=torch.float).reshape(-1, 1)
mu, sigma = self.pi(s)
new_dis = torch.distributions.normal.Normal(mu, sigma)
log_prob_new = new_dis.log_prob(a)
ratio = torch.exp(log_prob_new - log_prob_old)
L1 = ratio * A
L2 = torch.clamp(ratio, 1 - CLIP, 1 + CLIP) * A
loss_pi = -torch.min(L1, L2).mean()
self.pi.optim.zero_grad()
loss_pi.backward()
self.pi.optim.step()
loss_v = F.mse_loss(td_target.detach(), self.v(s))
self.v.optim.zero_grad()
loss_v.backward()
self.v.optim.step()
self.old_pi.load_state_dict(self.pi.state_dict())
self.old_v.load_state_dict(self.v.state_dict())
def save(self):
torch.save(self.pi.state_dict(), 'pi.pth')
torch.save(self.v.state_dict(), 'v.pth')
print('...save model...')
def load(self):
try:
self.pi.load_state_dict(torch.load('pi.pth'))
self.v.load_state_dict(torch.load('v.pth'))
print('...load...')
except:
pass一些注意的点:
计算价值网络的损失值我们需要真实的价值值,真实的价值值当前动作的回报加上放缩因子gamma乘以旧价值网络估计的下一次状态的价值量(设置新旧的网络是为了使target固定一段时间加速收敛和DQN的原理一样)。然后得到target我们就可以用MSE计算损失来更新价值网络的参数了!
更新策略网络,我们需要优势函数A和新旧策略得出的动作的概率的的比值ratio。优势函数A是通过计算上面的target和旧价值网络预测的当前状态的差所得来的。但是我们这里对A做了些“手脚”即将所算出来的差值再从后面累加。因为当前动作所带来的优势是下面所有动作的优势的总和所以可以做个累加,具体看上面代码比较好理解。ratio的计算就是用oldpi和新的pi得出的分布,分别取出action的概率log值(原因是pytorch的方法就是输出概率的log值)得到log值后我们用torch.exp(old - new)的到新旧概率的比值。然后计算ratio*A和torch.clamp(ratio, 1-clip, 1+clip)*A的值(clamp是使ratio限制在1-clip到1+clip之间,即为了不让更新的差异前后过大)然后再去其中的最小值求平均。而我们的目的是使下次计算的到的A越大越好。所以应当加-号。最后让优化器更新网络。
5.最终效果:
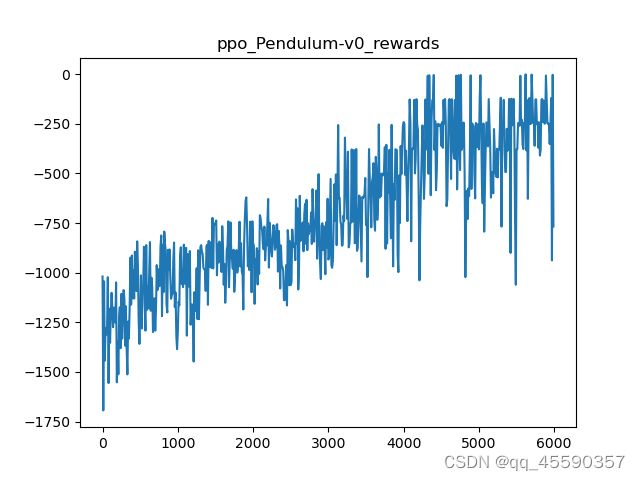
训练了大概6000局分数还在不断上升后面得分会越来越高。
训练10000局的结果

倒立摆终于立起来啦!!