语义分割系列26-VIT+SETR——Transformer结构如何在语义分割中大放异彩
SETR:《Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspectivewith Transformers》
重新思考语义分割范式,使用Transformer实现语义分割。
论文链接:SETR
VIT:《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》
首次提出使用Transformer进行图像分类。
至于为什么要在介绍SETR的同时介绍Vision Transformer,因为SETR本质上是使用VIT做backbone提取特征,使用传统的decoder来实现语义分割任务。
本文将介绍以下内容:
- Vision Transformer如何将Transformer应用于图像、为什么Vision Transformer能在图像领域中大放异彩?
- Self-Attention 和 Multi-Head Self-Attention是如何实现的,为什么MSA效果会好?
- SETR如何结合Vision Transformer来实现语义分割。
- Vision Transformer代码实现、SETR代码实现。
目录
论文部分
引文
Vision Transformer
SETR
Camvid数据集测试
SETR model
Dataset
Train
Result
Inference
论文部分
引文
Transformer模型早在2017年就已提出,用于机器翻译等任务。在当时也以《Attention is all you need》一文惊艳了大众,至那以后,Transformer与Attention在各个任务中所向披靡。Transformer和Attention机制的成功,也启发了语义分割领域的工作研究。陆续提出了基于Spatial Attention机制的Non-Local机制,基于Channel Attention和Spatial Attention机制的DANet,以及后续许多简化Attention繁杂计算的CrissCross Attention、Interlaced Sparse Self-Attention、EM Attention等等。但这些机制还是依赖于传统的CNN结构,还未有纯Transformer结构应用于图像领域。
直到Vision Transformer的出现,An Image is Worth 16x16 Words,VIT的出现将纯Transformer结构引入到图像分类中,将图像分块、嵌入以后使用Transformer进行计算,通过MLP来实现分类,并在ImageNet中取得优秀的效果。
VIT的出现启发了语义分割领域,Transformer这种基于Attention的机制,比起CNN需要使用卷积来提升感受野的操作,Attention无疑更加优秀。在任意层,Transformer就能实现全局的感受野,建立全局依赖。而且,CNN网络往往需要将原始图像的分辨率采用到8倍甚至32倍,这样就会损失一些信息,而Transformer无需进行下采样就能实现特征提取,保留了图像的更多信息。
因此,SETR采取了VIT作为语义分割encoder-decoder结构中的encoder结构,作为编码器来提取图像特征。SETR在论文提交当天在ADE20K任务中获得了第一名的成绩,这证明SETR在语义分割任务中确实能够获得十分优秀的效果。
Vision Transformer
 图1 Vision Transformer model
图1 Vision Transformer model
由于Transformer结构最先被设计用于机器翻译,而文本中的数据类型为序列结构。所以,当Transformer用于图像时,图像也需要被处理成一个序列。也就是图中的Linear Projection of Flattened Patches,将一张图像分成9个patch。为了保留图像patch的顺序,需要对每一个patch标上序号,也就是Position Embedding,VIT中,将这个Position信息加到每一个图像patch中。这样,每一个图像patch中就包含了他的位置信息。
经过嵌入的image patched,输入到Transformer Encoder(右图)结构中,首先进行Layer Norm,再输入到Multi-Head Self-Attention(MSA)中进行计算注意力,经过残差模块,再输入到Layer Norm、MLP、计算残差,这样经过L个Transformer结构得到最终输出。最后,将这个输出结果输入到一个MLP中,得到预测结果。
其中,MSA是是Transformer的最重要的一环,Transformer为何如此有效主要归功于MSA结构。MSA顾名思义,由多个Self-Attention结构堆叠,称为多头-自注意力。
对于Self-Attention
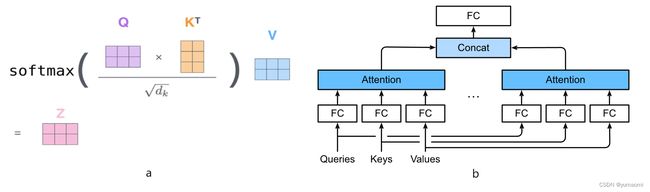 图2 Attention机制和MSA机制
图2 Attention机制和MSA机制

而对于MSA,可以理解为多个计算多个Self-Attention的结果,将结果进行拼接,得到MSA的输出。
当然,这里可能会有一个问题,为什么需要计算多个Self Attention?
因为,在计算Self Attention时,数据维度导致了计算量过大,同时在高纬度空间内学习特征也比较困难。而MSA在计算Self Attention时,需要对数据进行一个降维(或者叫“截断”),这样只选到了原始数据中的一部分,计算出来的Attention自然不够全面。因此,计算多个经过降维(截断)的Self Attention,每一个attention计算过程并行,且参数不共享,保证计算结果的全面性和效率。同时,这里也有一个优势,多个Self Attention计算时,能够在不同的特征子空间内计算其Attention,使结果更加丰富,模型对数据特征的理解也更加深入。
import torch
from torch import nn
from einops import rearrange, repeat
from einops.layers.torch import Rearrange
# Multi-Head Self-Attention
class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim = -1)
self.dropout = nn.Dropout(dropout)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
qkv = self.to_qkv(x).chunk(3, dim = -1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
attn = self.attend(dots)
attn = self.dropout(attn)
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)
if __name__ == "__main__":
MSA = Attention(dim=256, heads = 8, dim_head = 64, dropout = 0.).cpu()
# 1 is batch, 1024 is data, 256 is channels
img = torch.randn(1, 1024, 256).cpu()
preds = MSA(img)
print(preds.shape)下面也给出VIT作为语义分割encoder部分的代码实现,输出为四个 [batch, channels, h, w]。前三个,为中间的Transformer层输出,用于设计辅助损失。最后一个为最终输出,用于输出分割结果。
import torch
from torch import nn
from einops import rearrange, repeat
from einops.layers.torch import Rearrange
# helpers
def pair(t):
return t if isinstance(t, tuple) else (t, t)
# classes
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim = -1)
self.dropout = nn.Dropout(dropout)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
qkv = self.to_qkv(x).chunk(3, dim = -1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
attn = self.attend(dots)
attn = self.dropout(attn)
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0., out_indices = (9, 14, 19, 23)):
super().__init__()
self.out_indices = out_indices
assert self.out_indices[-1] == depth - 1
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))
]))
def forward(self, x):
out = []
for index, (attn, ff) in enumerate(self.layers):
x = attn(x) + x
x = ff(x) + x
if index in self.out_indices:
out.append(x)
return out
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, dim, depth, heads, mlp_dim, channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0., out_indices = (9, 14, 19, 23)):
super().__init__()
image_height, image_width = pair(image_size)
patch_height, patch_width = pair(patch_size)
assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (image_height // patch_height) * (image_width // patch_width)
patch_dim = channels * patch_height * patch_width
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.Linear(patch_dim, dim),
)
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout, out_indices=out_indices)
self.out = Rearrange("b (h w) c->b c h w", h=image_height//patch_height, w=image_width//patch_width)
def forward(self, img):
x = self.to_patch_embedding(img)
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)
out = self.transformer(x)
for index, transformer_out in enumerate(out):
# delete cls_tokens and transform output to [b, c, h, w]
out[index] = self.out(transformer_out[:,1:,:])
return out
import torch
if __name__ == "__main__":
v = ViT(image_size = (256, 256), patch_size = 256//16, dim = 1024, depth = 24, heads = 16, mlp_dim = 2048, dropout = 0.1, emb_dropout = 0.1, out_indices = (9, 14, 19, 23)).cpu()
img = torch.randn(1, 3, 256, 256).cpu()
preds = v(img)
for output in preds:
print(output.size())
"""
output:
transformer layer 9: torch.Size([1, 1024, 16, 16]) for aux loss
transformer layer 14: torch.Size([1, 1024, 16, 16]) for aux loss
transformer layer 19: torch.Size([1, 1024, 16, 16]) for aux loss
transformer layer 23: torch.Size([1, 1024, 16, 16]) for segmentation
"""SETR
回到本文主题,VIT的成功启发了SETR。
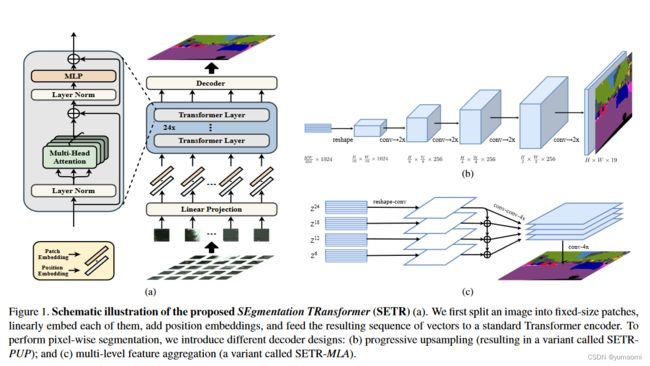 图3 SETR model
图3 SETR model
在这里(图3),a中采用了VIT结构。 假设一张图像x(H×W×3)大小,如果直接输入到VIT中,序列化成H×W×3,这对于Transformer的二次复杂度而言,运算量可能过大,因此,作者在这里做了一个下采样操作,将图像x映射成(H/16×W/16×3),这样就可以得到H×W×3/256的序列大小。将序列嵌入并编码位置后,得到最终的输入E = {e1 + p1, e2 + p2, · · · , eL + pL},其中e是embedding,p是positon information,L为序列长度。
如上文提到,Vit的输出为 [1, 1024, 16, 16] 大小,也就是[batch, channels, h, w],传统的语义分割的encoder输出模型。在这里,同样需要对结果进行上采样。
作者设计了三种上采样模式来完成,分别为:
- Naive mode:直接上采样16倍,16->256。
- Progressive UPsampling(PUP)通过卷积->2倍上采样->卷积->2倍上采样...的逐步上采样模式(图3 b)。
- Multi-Level feature Aggregation (MLA)获取Transformer中间层结果,聚合后4倍上采样。
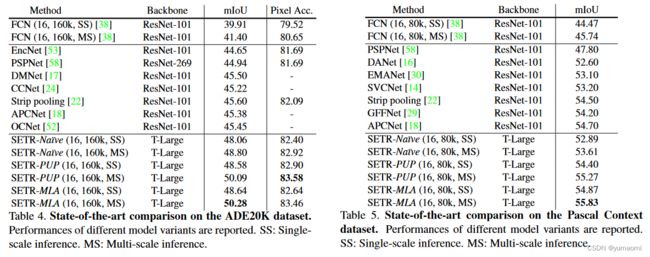
作者也在ADE20K、Pascal VOC等数据集上测试了几个上采样模块的结果。PUP和MLA结果会比Naive更好,同时,两者之间差距并不是很大。

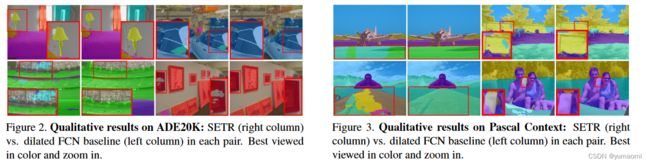
在各个数据集中,SETR也获得比FCN baseline更好的效果。这说明SETR能够较好完成语义分割任务。
作者也可视化了中间层的中间结果,可以看到Transformer结构确实能够学到图像中的一些信息。

注:SETR模型在Camvid测试中给出。
Camvid数据集测试
SETR model
import torch
from torch import nn
from einops import rearrange, repeat
from einops.layers.torch import Rearrange
# helpers
def pair(t):
return t if isinstance(t, tuple) else (t, t)
# classes
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim = -1)
self.dropout = nn.Dropout(dropout)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
qkv = self.to_qkv(x).chunk(3, dim = -1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
attn = self.attend(dots)
attn = self.dropout(attn)
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0., out_indices = (9, 14, 19, 23)):
super().__init__()
self.out_indices = out_indices
assert self.out_indices[-1] == depth - 1
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))
]))
def forward(self, x):
out = []
for index, (attn, ff) in enumerate(self.layers):
x = attn(x) + x
x = ff(x) + x
if index in self.out_indices:
out.append(x)
return out
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, dim, depth, heads, mlp_dim, channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0., out_indices = (9, 14, 19, 23)):
super().__init__()
image_height, image_width = pair(image_size)
patch_height, patch_width = pair(patch_size)
assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (image_height // patch_height) * (image_width // patch_width)
patch_dim = channels * patch_height * patch_width
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.Linear(patch_dim, dim),
)
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout, out_indices=out_indices)
self.out = Rearrange("b (h w) c->b c h w", h=image_height//patch_height, w=image_width//patch_width)
def forward(self, img):
x = self.to_patch_embedding(img)
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)
out = self.transformer(x)
for index, transformer_out in enumerate(out):
# delete cls_tokens and transform output to [b, c, h, w]
out[index] = self.out(transformer_out[:,1:,:])
return out
class PUPHead(nn.Module):
def __init__(self, num_classes):
super(PUPHead, self).__init__()
self.UP_stage_1 = nn.Sequential(
nn.Conv2d(1024, 256, 3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True)
)
self.UP_stage_2 = nn.Sequential(
nn.Conv2d(256, 256, 3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True)
)
self.UP_stage_3= nn.Sequential(
nn.Conv2d(256, 256, 3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True)
)
self.UP_stage_4= nn.Sequential(
nn.Conv2d(256, 256, 3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True)
)
self.cls_seg = nn.Conv2d(256, num_classes, 3, padding=1)
def forward(self, x):
x = self.UP_stage_1(x)
x = self.UP_stage_2(x)
x = self.UP_stage_3(x)
x = self.UP_stage_4(x)
x = self.cls_seg(x)
return x
class SETR(nn.Module):
def __init__(self, num_classes, image_size, patch_size, dim, depth, heads, mlp_dim, channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0., out_indices = (9, 14, 19, 23)):
super(SETR, self).__init__()
self.out_indices = out_indices
self.num_classes = num_classes
self.VIT = ViT( image_size=image_size, patch_size=patch_size, dim=dim, depth=depth, heads=heads, mlp_dim=mlp_dim,
channels = channels, dim_head = dim_head, dropout = dropout, emb_dropout = emb_dropout, out_indices = out_indices)
self.Head = nn.ModuleDict()
for index, indices in enumerate(self.out_indices):
self.Head["Head"+str(indices)] = PUPHead(num_classes)
def forward(self, x):
VIT_OUT = self.VIT(x)
out = []
for index, indices in enumerate(self.out_indices):
# 最后一个是最后层的输出
out.append(self.Head["Head"+str(indices)](VIT_OUT[index]))
return out
if __name__ == "__main__":
# VIT-Large 设置了16个patch
SETRNet = SETR(num_classes=3, image_size=256, patch_size=256//16, dim=1024, depth = 24, heads = 16, mlp_dim = 2048, out_indices = (9, 14, 19, 23)).cpu()
img = torch.randn(1, 3, 256, 256).cpu()
preds = SETRNet(img)
for output in preds:
print("output: ",output.size())
Dataset
# 导入库
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import optim
from torch.utils.data import Dataset, DataLoader, random_split
import warnings
warnings.filterwarnings("ignore")
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
import albumentations as A
from albumentations.pytorch.transforms import ToTensorV2
torch.manual_seed(17)
# 自定义数据集CamVidDataset
class CamVidDataset(torch.utils.data.Dataset):
def __init__(self, images_dir, masks_dir):
self.transform = A.Compose([
A.Resize(256, 256),
A.HorizontalFlip(),
A.VerticalFlip(),
A.Normalize(),
ToTensorV2(),
])
self.ids = os.listdir(images_dir)
self.images_fps = [os.path.join(images_dir, image_id) for image_id in self.ids]
self.masks_fps = [os.path.join(masks_dir, image_id) for image_id in self.ids]
def __getitem__(self, i):
# read data
image = np.array(Image.open(self.images_fps[i]).convert('RGB'))
mask = np.array( Image.open(self.masks_fps[i]).convert('RGB'))
image = self.transform(image=image,mask=mask)
return image['image'], image['mask'][:,:,0]
def __len__(self):
return len(self.ids)
# 设置数据集路径
DATA_DIR = r'../database/camvid/camvid/' # 根据自己的路径来设置
x_train_dir = os.path.join(DATA_DIR, 'train_images')
y_train_dir = os.path.join(DATA_DIR, 'train_labels')
x_valid_dir = os.path.join(DATA_DIR, 'valid_images')
y_valid_dir = os.path.join(DATA_DIR, 'valid_labels')
train_dataset = CamVidDataset(
x_train_dir,
y_train_dir,
)
val_dataset = CamVidDataset(
x_valid_dir,
y_valid_dir,
)
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True,drop_last=True)
val_loader = DataLoader(val_dataset, batch_size=4, shuffle=True,drop_last=True)Train
# 在模型训练前,建议先加载vit的权重
model = SETR(num_classes=32, image_size=256, patch_size=256//16, dim=1024, depth = 24, heads = 16, mlp_dim = 2048).cuda()
from d2l import torch as d2l
from tqdm import tqdm
import pandas as pd
import monai
from torchcontrib.optim import SWA
# training loop 100 epochs
epochs_num = 100
# 选用SGD优化器来训练
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
schedule = monai.optimizers.LinearLR(optimizer, end_lr=0.05, num_iter=int(epochs_num*0.75))
# 使用SWA优化 来提升SGD的效果
steps_per_epoch = int(len(train_loader.dataset) / train_loader.batch_size)
swa_start = int(epochs_num*0.75)
optimizer = SWA(optimizer, swa_start=swa_start*steps_per_epoch, swa_freq=steps_per_epoch, swa_lr=0.05)
# 损失函数选用多分类交叉熵损失函数
lossf = nn.CrossEntropyLoss(ignore_index=255)
def evaluate_accuracy_gpu(net, data_iter, device=None):
if isinstance(net, nn.Module):
net.eval() # Set the model to evaluation mode
if not device:
device = next(iter(net.parameters())).device
# No. of correct predictions, no. of predictions
metric = d2l.Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
# Required for BERT Fine-tuning (to be covered later)
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
output = net(X)
pred = output[-1]
metric.add(d2l.accuracy(pred, y), d2l.size(y))
return metric[0] / metric[1]
# 训练函数
def train_ch13(net, train_iter, test_iter, loss, optimizer, num_epochs, schedule, swa_start=swa_start, devices=d2l.try_all_gpus()):
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1], legend=['train loss', 'train acc', 'test acc'])
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
# 用来保存一些训练参数
loss_list = []
train_acc_list = []
test_acc_list = []
epochs_list = []
time_list = []
lr_list = []
for epoch in range(num_epochs):
# Sum of training loss, sum of training accuracy, no. of examples,
# no. of predictions
metric = d2l.Accumulator(4)
for i, (X, labels) in enumerate(train_iter):
timer.start()
if isinstance(X, list):
X = [x.to(devices[0]) for x in X]
else:
X = X.to(devices[0])
gt = labels.long().to(devices[0])
net.train()
optimizer.zero_grad()
result = net(X)
pred = result[-1]
seg_loss = loss(result[-1], gt)
aux_loss_1 = loss(result[0], gt)
aux_loss_2 = loss(result[1], gt)
aux_loss_3 = loss(result[2], gt)
loss_sum = seg_loss + 0.2*aux_loss_1 + 0.3*aux_loss_2 + 0.4*aux_loss_3
l = loss_sum
loss_sum.sum().backward()
optimizer.step()
acc = d2l.accuracy(pred, gt)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,(metric[0] / metric[2], metric[1] / metric[3], None))
if optimizer.state_dict()['param_groups'][0]['lr']>0.05:
schedule.step()
test_acc = evaluate_accuracy_gpu(net, test_iter)
if (epoch + 1) >= swa_start:
if epoch == 0 or epoch % 5 == 5 - 1 or epoch == num_epochs - 1:
# Batchnorm update
optimizer._reset_lr_to_swa()
optimizer.swap_swa_sgd()
optimizer.bn_update(train_iter, net, device='cuda')
test_acc = evaluate_accuracy_gpu(net, test_iter)
optimizer.swap_swa_sgd()
animator.add(epoch + 1, (None, None, test_acc))
print(f"epoch {epoch+1}/{epochs_num} --- loss {metric[0] / metric[2]:.3f} --- train acc {metric[1] / metric[3]:.3f} --- test acc {test_acc:.3f} --- lr {optimizer.state_dict()['param_groups'][0]['lr']} --- cost time {timer.sum()}")
#---------保存训练数据---------------
df = pd.DataFrame()
loss_list.append(metric[0] / metric[2])
train_acc_list.append(metric[1] / metric[3])
test_acc_list.append(test_acc)
epochs_list.append(epoch+1)
time_list.append(timer.sum())
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
df['epoch'] = epochs_list
df['loss'] = loss_list
df['train_acc'] = train_acc_list
df['test_acc'] = test_acc_list
df["lr"] = lr_list
df['time'] = time_list
df.to_excel("../blork_file/savefile/test.xlsx")
#----------------保存模型-------------------
if np.mod(epoch+1, 5) == 0:
torch.save(net, f'../blork_file/checkpoints/test{epoch+1}.pth')
# 保存下最后的model
torch.save(net, f'../blork_file/checkpoints/test.pth')
train_ch13(model, train_loader, val_loader, lossf, optimizer, epochs_num, schedule=schedule)
Result
Transformer比较难训练,作者这里只训练了一半。
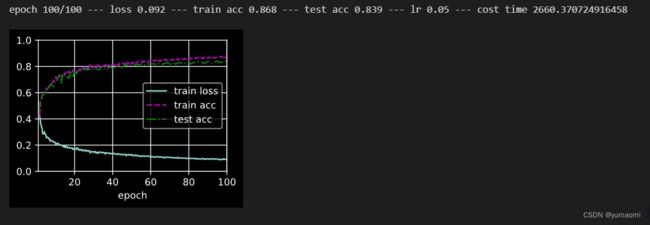
Inference
这里还做了一点Inference的实现,发现效果其实比较一般,损失函数选择mIoU可能会比交叉熵会好一点,或者将一部分类别删掉简化一下也会好一点。
import torch
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
import torch.nn as nn
# 截取模型
# 读取老模型
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 剪枝掉多余的decoder
class prune_model(nn.Module):
def __init__(self, encode, decode):
super(prune_model, self).__init__()
self.encode = encode
self.decode = decode
def forward(self, x):
x = self.encode(x)
x = self.decode(x[-1])
return x
model = torch.load(r"../checkpoints/test_last.pth")
# 创建新模型
new_model = prune_model(model.VIT, model.Head.Head23).to(device)
model = new_model#.cpu()
NCLASSES = 32
Cam_COLORMAP = [[128, 0, 0], [0, 128, 0], [128, 128, 0],
[0, 0, 128], [128, 0, 128], [0, 128, 128], [128, 128, 128],
[64, 0, 0], [192, 0, 0], [64, 128, 0], [192, 128, 0],
[64, 0, 128], [192, 0, 128], [64, 128, 128], [192, 128, 128],
[0, 64, 0], [128, 64, 0], [0, 192, 0], [128, 192, 0],
[0, 64, 128], [0, 32, 128],[0, 16, 128],[0, 64, 64],[0, 64, 32],
[0, 64, 16],[64, 64, 128],[0, 32, 16],[32,32,32],[16,16,16],[32,16,128],
[192,16,16],[32,32,196],
]
#32类
Cam_CLASSES = ['Animal','Archway','Bicyclist','Bridge','Building','Car','CartLuggagePram','Child',
'Column_Pole','Fence','LaneMkgsDriv','LaneMkgsNonDriv','Misc_Text','MotorcycleScooter',
'OtherMoving','ParkingBlock','Pedestrian','Road','RoadShoulder','Sidewalk','SignSymbol',
'Sky', 'SUVPickupTruck','TrafficCone','TrafficLight', 'Train','Tree','Truck_Bus', 'Tunnel',
'VegetationMisc', 'Void','Wall']
assert len(Cam_COLORMAP) == len(Cam_CLASSES) == 32
image = Image.open("../database/camvid/camvid/train_images/0001TP_008100.png").convert("RGB")
image = image.resize((256, 256))
temp = image
image = np.array(image)
Transform = A.Compose([
A.Resize(256, 256),
A.HorizontalFlip(),
A.Normalize(),
ToTensorV2(),
])
image = Transform(image=image)
image = image['image'].view(1, 3, 256, 256)
image = image.cuda()
preds = model(image)
out = np.array(preds.argmax(1).view(1, 256, 256).permute(1,2,0).view(256,256).cpu().detach().numpy())
seg_img = np.zeros((256, 256, 3))
colors = Cam_COLORMAP
colors[0][0] = 0
colors[0][1] = 0
colors[0][2] = 0
for c in range(NCLASSES):
seg_img[:,:,0] += ((out[:,:] == c )*( colors[c][0] )).astype('uint8')
seg_img[:,:,1] += ((out[:,:] == c )*( colors[c][1] )).astype('uint8')
seg_img[:,:,2] += ((out[:,:] == c )*( colors[c][2] )).astype('uint8')
seg_img = Image.fromarray(np.uint8(seg_img))
image = Image.blend(temp,seg_img,0.5)
image = image.resize((960, 720), Image.BILINEAR)
plt.figure(figsize=(10, 8))
plt.imshow(image)
plt.show()
结果比较抽象,不过有大部分确实是预测到了而已。

本文总结
- 本文介绍了Vision Transformer和SETR在语义分割中的应用。
- 在介绍Vision Transformer时,还顺带讲解了Multi-Head Self-Attention的实现原理,以及为何MSA会比Self-Attention有效果。
- 对于SETR,本质是VIT+Decoder结构,其中Decoder主要由三种设计:Naive PUP MLA,本文只实现了PUP结构。
- 基于SETR在Camvid数据集上完成了一部分训练和推理(虽然我们的推理结果比较一般,这Transformer模型也确实比较难以训练)。但作者确实是在总多数据集上得到了比较好的一个效果。说明Transformer结构应用在语义分割领域是可行的。