学懂 Python NumPy
目录
- NumPy ndarray:多维数组对象
-
- 创建 ndarrays
- ndarrays 的数据类型
- NumPy arrays 的算术运算
- 索引、切片
- 布尔索引
- Fancy Indexing
- 数组转置和轴变换
- Universal Functions
- References
NumPy(Numerical Python 的缩写)是 Python 最重要的数值计算工具包之一。对 NumPy arrays 和它面向数组(array-oriented)语法的理解对于我们学习其它面向数组的工具,如 pandas,非常有帮助。
NumPy 的重要性之一体现在它的高效:
- NumPy 在内部的一整块连续内存上存储数据,和其它内置的 Python 对象是独立的。
- NumPy 在整个数组上执行复杂的操作,而不需要使用
for循环。
我们可以将 NumPy 数组与普通的列表做个直观比较:
import numpy as np
array = np.arange(1000000)
lst = list(range(1000000))
%time for _ in range(10): array2 = array * 2
"""
Out: Wall time: 20.3 ms
"""
%time for _ in range(10): lst2 = [x * 2 for x in lst]
"""
Out: Wall time: 860 ms
"""
基于 NumPy 的算法通常比基于纯 Python 的算法要快 10 到 100 倍且需要更少的内存。
NumPy ndarray:多维数组对象
NumPy ndarray 使得我们能够像操作标量元素那样对整个数据块同时执行操作:
data = np.random.randn(2, 3)
data
"""
Out: array([[ 0.3974317 , -0.36370616, -0.12016064],
[-0.84256279, 1.17084537, -1.21551024]])
"""
data * 10
"""
Out: array([[ 3.97431698, -3.63706157, -1.20160639],
[ -8.42562789, 11.70845371, -12.15510239]])
"""
data 中的每个元素都被乘 10。
data + data
"""
Out: array([[ 0.7948634 , -0.72741231, -0.24032128],
[-1.68512558, 2.34169074, -2.43102048]])
"""
对应位置的值相加。
一个 ndarray 是对同质数据(homogeneous data)的多维容器,即所有元素都必须为相同的数据类型。每个 array 有一个 shape 属性,是一个表明每个维度大小的元组;还有一个 dtype 属性,是一个描述 array 中元素数据类型的对象:
data.shape
"""
Out: (2, 3)
"""
data.dtype
"""
Out: dtype('float64')
"""
这篇文章中提到的
array、NumPy array、ndarray一般都指的是ndarray对象。
创建 ndarrays
创建 ndarrays 最简单的方式是使用 array 函数。它接受一个序列数据类型输入并产生对应的 Numpy array 对象,它会自动推断 dtype,我们也可以指定需要的 dtype。例如:
lst1 = [2, 5, 6.6, 8.8]
arr1 = np.array(lst1)
arr1
"""
Out: array([2. , 5. , 6.6, 8.8])
"""
arr3 = np.array([1, 2, 3], dtype=np.float64)
arr3
"""
Out: array([1., 2., 3.])
"""
嵌套的序列将会被转换为多维数组:
lst2 = [[1, 2, 3, 4], [5, 6, 7, 8]]
arr2 = np.array(lst2)
arr2
"""
Out: array([[1, 2, 3, 4],
[5, 6, 7, 8]])
"""
NumPy array arr2 有两个维度且和输入数据的形状相同:
arr2.ndim
"""
Out: 2
"""
arr2.shape
"""
Out: (2, 4)
"""
当然,还有许多其他方法来创建 arrays,例如 zeros、ones、empty。如果要用这些方法创建一个更高维度的数组,需用一个元组传入形状:
np.zeros(10)
"""
Out: array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
"""
np.empty((2, 3, 2))
"""
Out: array([[[7.87207675e-312, 3.16202013e-322],
[0.00000000e+000, 0.00000000e+000],
[1.11261502e-306, 6.23747610e-042]],
[[1.32412862e-071, 4.25120408e+174],
[3.38134561e-061, 4.47167199e-062],
[3.11864886e-033, 1.03194271e+166]]])
"""
关于 np.empty:返回的不一定是全零值,也有可能返回一些像上面结果中的 “garbage” 值。
arange 是 range 函数的 NumPy array 版本:
np.arange(15)
"""
Out: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
"""
还有几个常见的创建 array 函数,我们总结在下表:
| Function | Description |
|---|---|
ones_like |
产生与输入序列相同形状和数据类型的 全 1 array |
zeros_like |
产生与输入序列相同形状和数据类型的 全 0 array |
full |
产生与输入序列相同形状和数据类型的 array,且值都设定为指定的 fill value |
eye, identity |
产生 N×N 的方阵(对角元素为 1,其余为 0) |
ndarrays 的数据类型
dtypes 体现了 NumPy 在与来自其它系统的数据交互时的灵活性。大多数情况下它们直接提供了到磁盘的映射,使得从磁盘读写二进制流数据非常容易、高效。
我们可以使用 astype 方法来 cast array 从一个 dtype 变为另一个:
arr = np.array([1, 2, 3, 4, 5])
arr.dtype
"""
Out: dtype('int32')
"""
float_arr = arr.astype(np.float64)
float_arr.dtype
"""
Out: dtype('float64')
"""
如果将浮点类型转换为整型,小数部分将被舍弃:
arr = np.array([2.2, 3.3, 5.5, 6.6, -2.6, -1.2])
arr.astype(np.int32)
"""
Out: array([ 2, 3, 5, 6, -2, -1])
"""
关于 astype:调用 astype 总会创建一个新的 array。类似上面这个例子,此时 arr 仍然是浮点类型的数组。
NumPy arrays 的算术运算
正如我们开篇看到的,任何相同形状 array 的运算都执行的是逐元素运算。array 与标量的运算,将会把标量与每个 array 的元素进行运算:
arr = np.array([[1., 2., 3.], [4., 5., 6.]])
1 / arr
"""
Out: array([[1. , 0.5 , 0.33333333],
[0.25 , 0.2 , 0.16666667]])
"""
相同形状 arrays 之间的比较会产生一个布尔类型的 array:
arr2 = np.array([[0., 4., 1.], [7., 2., 12.]])
arr2 > arr
"""
Out: array([[False, True, False],
[ True, False, True]])
"""
不同形状 arrays 之间的运算被称为广播(broadcasting),在《NumPy 中的广播》中有深入介绍。
索引、切片
对于一维的 array,索引、切片操作与列表很相似:
arr = np.arange(10)
arr[5]
arr[5:8]
但如果我们给一个切片赋一个标量值,那么这个值会被广播到切片所在的区域,列表是不支持这个操作的:
arr[5:8] = 12
arr
"""
Out: array([ 0, 1, 2, 3, 4, 12, 12, 12, 8, 9])
"""
另一个区别则是,array 的切片是原来 array 的 views,也就是说,任何对切片的修改将会反映到原来的 array 上,切片只是 array 对应位置的一个引用而已:
arr = np.arange(10)
arr_slice = arr[5:8]
arr_slice[:] = 12
arr
"""
Out: array([ 0, 1, 2, 3, 4, 12, 12, 12, 8, 9])
"""
如果想要切片不影响原来的 array,我们可以对原来的 array 浅拷贝,即 arr[5:8].copy()。
对于高维的 arrays,索引切片方式也与多维列表类似,但对于下面这个二维 array:
arr2d = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
如果我们想要索引 3 这个元素,那么以下两种方法是等价的:
arr2d[0][2]
arr2d[0, 2]
下图是索引一个二维 array 时的说明。一定要理解 axis 0 和 axis 1 所表征的维度方向,这非常重要。
如果我们这样索引:arr2d[:2],那么会沿着 axis 0 的方向进行切片,即会选择 arr2d 的前两行。因此,arr2d[1, :2] 表示选择第二行的前两个元素(前两列)。
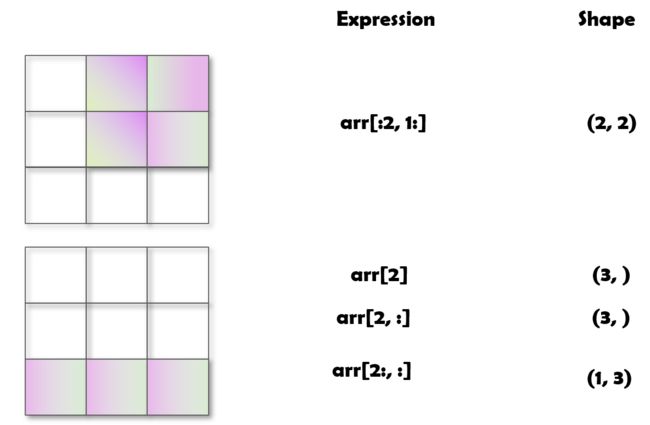
下图是对一个二维 array 切片时的说明,注意切片的形状。

对于下面的三维数组:
arr3d = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]])
arr3d[1, 0] 将会返回以下标(0,1)开始的所有值,即 arr3d[1, 0] 和 arr3d[1, 0, :] 是等价的:
arr3d[1, 0]
"""
Out: array([7, 8, 9])
"""
arr3d[1, 0, :]
"""
Out: array([7, 8, 9])
"""
布尔索引
我们现在一个数据数组和一个含有重复名字的名字数组,每个名字对应数据数组的每一行:
names = np.array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'])
data = np.random.randn(7, 4)
data
"""
Out: array([[-0.07886997, 0.37234627, 0.31932189, 0.26765547],
[-1.03868927, 1.46724026, -0.41127238, 1.61015587],
[ 0.64143545, 0.32256838, -1.05380508, -1.65091133],
[ 0.29179757, 0.07600414, 0.1945481 , -0.16866199],
[-1.16282294, 0.08139801, 0.56793365, 1.67821034],
[-0.64465594, -2.58643856, -1.2286194 , -1.22592116],
[ 1.06513352, 1.34415864, -0.01389475, -1.59164928]])
"""
我们想要选出所有对应 'Bob' 的行。
和算术运算类似,我们拿 names 与 'Bob' 进行比较,会产生一个布尔类型的 array:
names == 'Bob'
"""
Out: array([ True, False, False, True, False, False, False])
"""
这个布尔数组可以被当作索引来使用:
data[names == 'Bob']
"""
Out: array([[-0.07886997, 0.37234627, 0.31932189, 0.26765547],
[ 0.29179757, 0.07600414, 0.1945481 , -0.16866199]])
"""
将布尔索引与其它整数索引结合:
data[names == 'Bob', 2:]
"""
Out: array([[ 0.31932189, 0.26765547],
[ 0.1945481 , -0.16866199]])
"""
如果要选择除了 'Bob' 之外的所有行,可以用 != 或者 ~:
names != 'Bob'
"""
Out: array([False, True, True, False, True, True, True])
"""
data[~(names == 'Bob')]
"""
Out:
array([[-1.03868927, 1.46724026, -0.41127238, 1.61015587],
[ 0.64143545, 0.32256838, -1.05380508, -1.65091133],
[-1.16282294, 0.08139801, 0.56793365, 1.67821034],
[-0.64465594, -2.58643856, -1.2286194 , -1.22592116],
[ 1.06513352, 1.34415864, -0.01389475, -1.59164928]])
"""
更灵活的索引可以结合布尔运算符,比如 & 和 | (注意,这里不能使用 and 或者 or):
mask = (names == 'Bob') | (names == 'Will')
mask
"""
Out: array([ True, False, True, True, True, False, False])
"""
data[mask]
"""
Out: array([[-0.07886997, 0.37234627, 0.31932189, 0.26765547],
[ 0.64143545, 0.32256838, -1.05380508, -1.65091133],
[ 0.29179757, 0.07600414, 0.1945481 , -0.16866199],
[-1.16282294, 0.08139801, 0.56793365, 1.67821034]])
"""
将所有小于 0 的值设为 0:
data[data < 0] = 0
data
"""
Out: array([[0. , 0.37234627, 0.31932189, 0.26765547],
[0. , 1.46724026, 0. , 1.61015587],
[0.64143545, 0.32256838, 0. , 0. ],
[0.29179757, 0.07600414, 0.1945481 , 0. ],
[0. , 0.08139801, 0.56793365, 1.67821034],
[0. , 0. , 0. , 0. ],
[1.06513352, 1.34415864, 0. , 0. ]])
"""
Fancy Indexing
用整数数组来索引 arrays。
我们构造如下 array:
arr = np.empty((8, 4))
for i in range(8):
arr[i] = i
arr
"""
Out: array([[0., 0., 0., 0.],
[1., 1., 1., 1.],
[2., 2., 2., 2.],
[3., 3., 3., 3.],
[4., 4., 4., 4.],
[5., 5., 5., 5.],
[6., 6., 6., 6.],
[7., 7., 7., 7.]])
"""
我们可以以任意顺序选择我们想要的行:
arr[[4, 2, 0, 6]]
"""
Out: array([[4., 4., 4., 4.],
[2., 2., 2., 2.],
[0., 0., 0., 0.],
[6., 6., 6., 6.]])
"""
也可以使用负数,负数索引的含义和列表是一样的:
arr[[-3, -5, -7]]
"""
Out: array([[5., 5., 5., 5.],
[3., 3., 3., 3.],
[1., 1., 1., 1.]])
"""
如果我们索引传入的是多个整数数组:
arr = np.arange(32).reshape((8, 4))
arr
"""
Out: array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23],
[24, 25, 26, 27],
[28, 29, 30, 31]])
"""
arr[[1, 5, 7, 2], [0, 3, 1, 2]]
"""
Out: array([ 4, 23, 29, 10])
"""
将会产生一个一维数组,其中的元素为(1,0)、(5,3)、(7,1)、(2,2)处的元素。
Keep in mind:和切片不同,fancy indexing 总是将数据拷贝到一个新 array。
数组转置和轴变换
转置是 reshape 的一种特殊形式,在当前数据上直接进行,并不进行任何拷贝。
arr = np.arange(15).reshape((3, 5))
arr
"""
Out: array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
"""
arr.T
"""
Out: array([[ 0, 5, 10],
[ 1, 6, 11],
[ 2, 7, 12],
[ 3, 8, 13],
[ 4, 9, 14]])
"""
当在进行矩阵运算时,转置操作经常用到,例如,矩阵内积:
arr = np.random.randn(6, 3)
arr
"""
Out: array([[ 0.44650803, 1.29229044, -0.65040862],
[-1.01441007, -0.46894967, -0.59353694],
[-1.80465512, 0.22833974, -1.52639209],
[-0.55433815, -1.59511554, 0.8003678 ],
[ 1.44873546, -1.54600204, 0.57683049],
[ 2.24300625, 2.02873595, 0.22277911]])
"""
np.dot(arr.T, arr)
"""
array([[11.92237956, 3.83560368, 3.95798378],
[ 3.83560368, 10.99235288, -2.62721412],
[ 3.95798378, -2.62721412, 4.12814284]])
"""
对于高维数组,transpose 方法接受一个 axis number 的元组来对轴进行变换:
arr = np.arange(24).reshape((2, 3, 4))
arr
"""
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
"""
将 axis 0 与 axis 1 的顺序对调,axis 2 不变:
arr.transpose((1, 0, 2))
"""
array([[[ 0, 1, 2, 3],
[12, 13, 14, 15]],
[[ 4, 5, 6, 7],
[16, 17, 18, 19]],
[[ 8, 9, 10, 11],
[20, 21, 22, 23]]])
"""
Universal Functions
Universal Functions ufunc 在 ndarrays 中的数据上执行逐元素的运算。我们可以类比为普通函数输入多个标量值,然后计算输出多个标量值。
arr = np.arange(10)
np.sqrt(arr)
"""
array([0. , 1. , 1.41421356, 1.73205081, 2. ,
2.23606798, 2.44948974, 2.64575131, 2.82842712, 3. ])
"""
类似 np.sqrt 和 np.exp 被叫作 unary ufuncs。因为它们只接受一个 array 输入,然后输出一个 array 结果。其他的 ufunc 类似 add 和 maximum 接受两个 arrays 输入,然后输出一个 array 结果,因此叫作 binary ufuncs。
x = np.random.randn(8)
y = np.random.randn(8)
np.maximum(x, y)
"""
array([-1.18502715, 0.99289309, 0.84686036, 1.15207002, 0.08148611,
1.07507789, 0.60318306, 1.13771542])
"""
当然也有返回值是多个 arrays 的函数,例如 modf:
arr = np.random.randn(7) * 5
arr
"""
array([-7.91696074, -3.72120665, 4.97830112, 2.50999445, -5.46463993,
-5.72923015, 2.4777145 ])
"""
remainder, whole_part = np.modf(arr)
remainder
"""
array([-0.91696074, -0.72120665, 0.97830112, 0.50999445, -0.46463993,
-0.72923015, 0.4777145 ])
"""
whole_part
"""
array([-7., -3., 4., 2., -5., -5., 2.])
"""
ufuncs 还有一个 out 参数,来让我们在原地对 array 进行操作。例如 np.sqrt(arr, arr) 将会把计算结果返回给 arr。
常见的 ufuncs 总结:
Unary ufuncs:
abs,fabssqrtsquareexplog,log2,log10(log是以 e 为底)sign:计算每个元素的符号(1 为正,0 为 0,-1 为负)ceilfloormodfisnan,isfinite,isinfcos,sin,tan,tanh,arccos
Binary ufuncs:
addsubtractmultiplydividepowermaximum,minimummodcopysign
References
Python for Data Analysis, 2 n d ^{\rm nd} nd edition. Wes McKinney.