手把手教你学Python之Numpy学习(一文掌握科学计算库-Numpy)
目录
多维数组对象-ndarray
ndarray对象的创建
ndarray对象的主要属性
ndarray对象的主要方法
索引和切片
Numpy中的通用函数
Numpy中的数学函数
Numpy生成随机数
Numpy中的统计方法
Numpy中其他常用方法
Numpy中的数组运算
Numpy的广播机制
数组间的集合运算
数组的连接
数组的分割
NumPy(Numerical Python)是高性能科学计算和数据分析的基础包。它极大的简化了多维数组的操纵和处理,大部分数据处理软件包都依赖于Numpy,例如pandas、matplotlib、scikit-learn等。
Numpy的一些特点:
-
NumPy 提供了对数组和矩阵进行快速运算的标准数学函数;
-
NumPy 提供了很多矢量运算的接口,比手动用循环实现速度要快很多;NumPy 开放源代码,由许多协作者共同维护开发。
-
……
Python标准库中默认不包含Numpy,推荐两种安装方式:
-
使用Anaconda软件,简化包的管理,自带Numpy、matplotlib等数据处理包;
-
使用pip命令安装:pip install numpy

多维数组对象-ndarray
NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是用于存放同类型元素的多维数组,ndarray 中的每个元素在内存中占有相同大小的区域。创建ndarray对象时,可以通过dtype指定数据类型,如果没有指定,则会根据元素内容自动确定。
ndarray对象的创建
创建ndarray的方法很多,例如可通过array()、asarray()将列表或元组转化为ndarray,通过arange()生成一组数,通过ones()、zeros()、full()生成元素相同的一些特殊数组,通过linspace()、logspace()分别生成等差和等比数组等,方法详细说明如下:
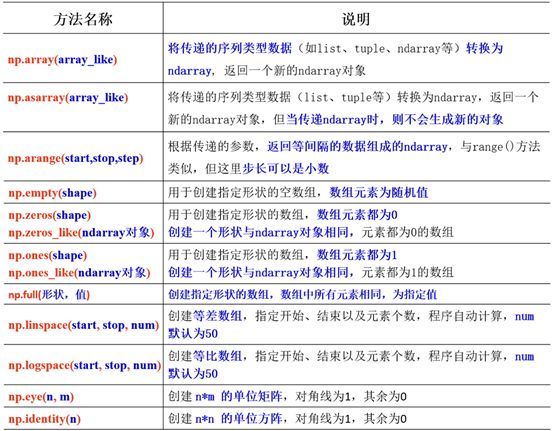
注意:指定数组形状时,只能是整数如8、12等表示一维数组中元素的个数,或者整数序列如[3,5],(2, 3, 4)等,序列的长度表示维度,每个元素的值表示对应维度上轴的大小。

ndarray对象的主要属性
多维数组对象ndarray的主要属性包括shape(形状)、ndim(维度)、size(元素个数)、dtype(元素类型)、itemsize(每个元素所占字节数)、nbytes(整个数组所占字节数)等。各自含义和用法如下:

ndarray对象的主要方法
多维数组对象ndarray的主要方法包括reshape(形状)、flatten(将多维数组压平为1维数组)、astype(指定元素类型)、sum(求和)、cumsum(累积求和)、max(求最大值)、min(求最小值)、mean(求平均值)等。方法的详细介绍及其用法如下:
 索引和切片
索引和切片
ndarray 对象的索引和切片操作,与序列的索引和切片操作类似。索引支持正向索引(从左到右,下标从0开始不断增大)和反向索引(从右到左,下标从-1开始不断减小)。切片操作可通过slice函数,设置start、stop和step参数进行;也可以通过冒号分隔切片参数 start:stop:step进行。对于多维数组来说,可以分别对每一个维度进行索引和切片,多个维度的索引和切片之间用逗号隔开。
序列进行切片操作后,会生成一个新的序列,相当于是将相应的元素复制出来组成了一个新的序列。与此不同,ndarray切片结果并不会单独生成一个新的ndarray,访问的仍然是原始的ndarray中的数据,因此对切片结果的修改会影响到原始数据。

下面以一个具体例子,来理解索引和切片的用法。
 此外,Numpy中还提供了一些特殊的索引方式,例如整数数组索引、布尔索引及花式索引。
此外,Numpy中还提供了一些特殊的索引方式,例如整数数组索引、布尔索引及花式索引。
整数数组索引主要用于同时访问多个无规律的元素,用整数数组作为索引,一个整数数组表示一个维度,有多少个维度就需要多少个整数数组,整数数组中用于存放各元素在这一维度的索引。

布尔索引通过布尔运算来获取符合一定条件的元素,对一个多维数组使用布尔运算时,会对数组中的每一个元素执行布尔运算,最终得到一个元素为True或False的多维数组,然后将这个多维布尔数组作为索引,此时会取出True对应位置上的数据。

花式索引根据索引数组的值作为目标数组的某个轴的下标来取值。对于使用一维整型数组作为索引,如果目标是一维数组,那么索引的结果就是对应位置的元素;如果目标是二维数组,那么就是对应下标的行。

如果需要按照自定义的顺序获取某些行列的数据,可使用np.ix_方法,用法为: a[np.ix_([行序],[列序])],注意和整数数组索引的区别。

Numpy中为我们提供了很多高性能的科学计算和数据分析函数,包括各种各样的数学函数、用于生成随机数和特定概率分布样本的函数、统计分析中经常用到的函数以及其他一些常用函数。
Numpy中的通用函数
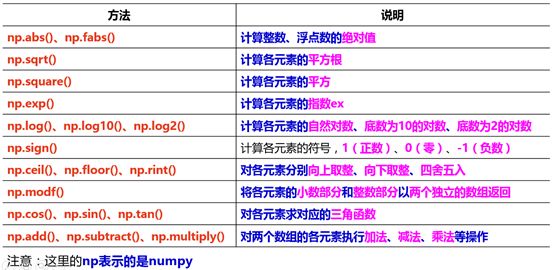
Numpy中的数学函数
Numpy中提供的数学函数含义大部分与数学库中的函数一致,当对多维数组执行数学函数时,会对里面的每一个元素执行相应的函数,并将结果保存到相应的位置,简单、高效。实际上,我们完全可以通过循环,使用数据库中的函数实现相同效果,但操作麻烦、性能不高。主要的数学函数及其作用如下:
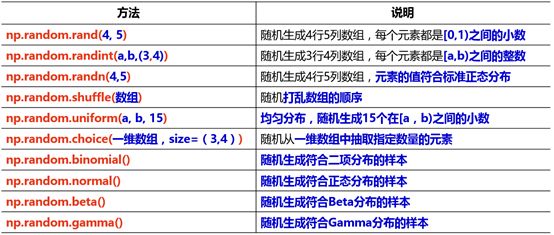
Numpy生成随机数
numpy.random模块对Python内置的random进行了补充,增加了一些用于高效生成多种概率分布的样本值的函数。常见的方法如下:
Numpy中的统计方法
Numpy中提供了大量的用于统计分析的方法,例如求和、求均值、求中位数、求方差、求标准差、求相关系数、去重等等,大部分方法既支持对整体数据运算,也支持对某一个维度进行运算。具体方法及其含义如下:

Numpy中其他常用方法
此外,Numpy中还有一些好用的方法,例如扩展数组、将数组保存到文件、判断数组中元素是否满足某一条件、对数据进行排序等等。具体方法及其含义如下:

Numpy中的数组运算
Numpy的广播机制
numpy 中两个数组之间支持加、减、乘、除等算术运算,实际上是对应位置的元素之间的运算。两个形状相同的数组间执行运算容易理解,两个形状不同的数组之间有时也能执行算术运算,此时会对数组进行扩展,使其形状相同,然后再执行算术运算,这种机制叫做广播。但并不是所有的数组之间都能执行算术运算。
广播的原则:如果两个数组的后缘维度(trailing dimension,即从末尾开始算起的维度)的轴长度相符,或其中的一方的长度为1,则认为它们是广播兼容的。广播会在缺失或长度为1的维度上进行。广播效果如图所示。
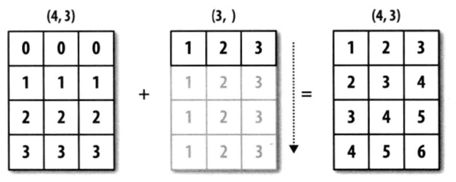
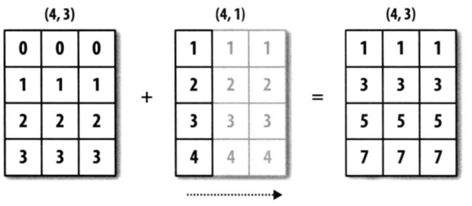
此外,多维数组还可以和标量进行运算,此时会将该标量和数组中的每一个元素执行运算,并将结果进行保存。举例如下:

对数组中的切片进行赋值时,也会根据广播机制,将值传到相应的位置上。这一点和Python中的序列有所不同。

数组间的集合运算
两个一维数组之间还可以执行常见的集合运算,例如求交集、并集、差集、异或集等,结果中如果包含重复数据会自动删除多余的数据。
-
np.intersect1d(a,b):交集,结果为同时在a和b中的元素组成的数组
-
np.setdiff1d(a,b): 差集,结果为在a中不在b中的元素组成的数组;
-
np.union1d(a,b): 并集,结果为在a或b中的元素组成的数组;
-
np.setxor1d(a,b): 异或集,结果为在a或b中,但不同时在a和b中的元素组成的数组;
-
np.in1d(a,b): 判断a中的元素是否在b中,结果为布尔类型数组;

数组的连接
-
np.concatenate((a,b)):沿指定轴连接两个或多个数组,要求指定轴上的元素个数相同,默认是按垂直连接,效果和 vstack 效果相同;
-
np.stack ((a,b)):沿新轴连接数组序列,数组a和b形状必须相同;
-
np.hstack ((a,b)):通过水平堆叠来生成数组;
-
np.vstack ((a,b)):通过垂直堆叠来生成数组。

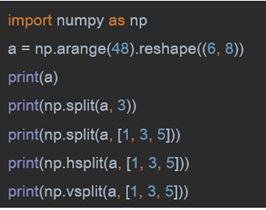
数组的分割
-
np.split():沿特定的轴将数组分割为子数组,如果是整数,就用该数平均切分,如果是数组,为沿轴对应位置切分(左开右闭);
-
np.hsplit():用于水平分割数组,通过指定要返回的相同形状的数组数量来拆分原数组;
-
np.vsplit():沿着垂直轴分割,其分割方式与hsplit用法相同。
更多关于手把手教你学Python的文章请关注微信公众号:手把手教你学编程。详细的视频讲解可查看 CSDN学院 里的手把手教你学Python系列视频:https://edu.csdn.net/lecturer/5686。