Python基于Imagehash及OpenCV的图像视频数据媒资检索
前言:
前段时间参加了一个关于图像视频检索的比赛,抽空总结一下思路,并在结尾附上参赛代码以及对应数据集。
链接:媒体融合创新创意大赛 比赛主链接 复赛名单链接
截至目前只公布了Top10,复赛参加后暂无更多的消息,可能主办方也鸽了(不是)。
结果出来了,被榜上的大佬们反复蹂躏,榜单在这。
一、比赛要求介绍
1.1 数据集介绍
提供数据集为:
- db:
包含3186个长度为10秒左右的随机视频,模拟视频数据库。
- image:
从db中截取的图片,并进行相应处理,处理方式包括:
原始视频中某一帧,用于图像查询视频,变换类型说明如下:
- black_pad: 基于原图片上下添加黑边
- bw: 颜色变换-黑白
- color: 颜色变换-彩色
- crop: 图片裁减
- cut: 子片段(对于图片无效)
- logo: 随机位置增加logo
- mohu: 变得模糊
- ori: 无变换,可以理解为原切图
- shuiyin: 增加全屏的水印
- zimu: 下方增加字幕
分为训练集(每种类1000个图片)和测试集(每种类200个图片)
- video:
基于db视频采取与image相同处理方式的视频,训练集与测试集相同。
1.2 要求介绍
这里不做比赛简介的复述了,采用大白话的方式进行说明:
设计一种算法,官方测试时指定新的db文件夹,以及随机混合10种类型的图片和视频文件夹,以路径作为参数传入指定脚本中,经过处理运算后得到一个匹配对照文件以及耗时文件。运行时提供必要的显卡和cuda环境作为支持。为避免环境问题,参赛方以docker镜像的方式提供算法模型。
代码按照要求应分为三个py文件,build.py、query_image.py、query_video.py
- build.py:进行你想要的预处理,不计入时间
- query_image.py:db和image文件夹路径作为参数传入,生成匹配文档和耗时文档
- query_video.py:db和video文件夹路径作为参数传入,生成匹配文档和耗时文档
主要难度:
混合类型的图像或音频,算法泛用性难度大大增加;官方测试时仅一张T4显卡作为运算主力,耗时问题;还有一个CV和深度学习处理能力为0的本人(我是菜狗)。
二、算法思路
2.1 选取方法
既然提供了显卡和cuda环境,本能的想到了什么目标识别、聚类、相似度匹配巴拉巴拉的一大堆,感觉要狠狠的torch起来,但是查阅了很多论文和开源项目代码,发现我能找到的或者我能理解并复现的一些技术,并不适合当前数据集的要求,进而在选择技术方法方面花费了较长时间。
最终采取了图像相似度的方式,也就是基于图像hash值对比的方式进行图片检索,在本次数据集的数量级范围内理论可行。Imagehash官方的库中有各种hash值计算的函数,包括但不限于ahash、dhash、phash、whash等,其中我们根据实验数据进行测试,排除了ahash、dhash等简单数值运算的方式,选取了whash基于小波变换的方式。
2.2 WHash原理及实现
whash算法核心思路:
- 灰度化
- Resize=>8*8,平滑 (在最终提交版本选取了16*16的大小,提高了精度,但降低了效率)
- 小波变换获取不同的低频特征
- 二值化获得二值图
- 合并得到 fingerprint
- 比较不同图片的 fingerprint(ImageHash 格式)
- 比较海明距(同为 ImageHash 格式可以直接与或运算得到计算结果)
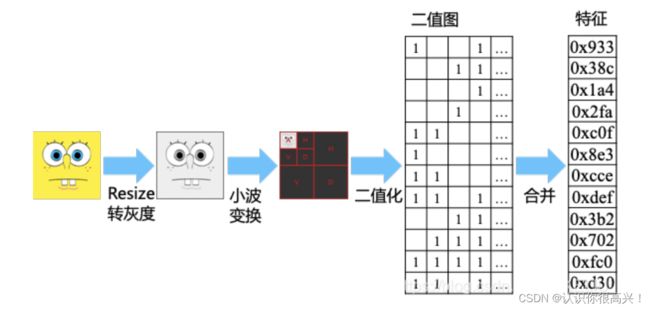 小波变换中会进行多次迭代,对whash原理想要详细了解的同学可以看以下的源码,但是感觉一些底层函数在这部分源码中也没有讲清楚,这里更像是判断并计算,感兴趣的小伙伴们可以深入了解一下。
小波变换中会进行多次迭代,对whash原理想要详细了解的同学可以看以下的源码,但是感觉一些底层函数在这部分源码中也没有讲清楚,这里更像是判断并计算,感兴趣的小伙伴们可以深入了解一下。
def whash(image, hash_size = 8, image_scale = None, mode = 'haar', remove_max_haar_ll = True):
"""
Wavelet Hash computation.
based on https://www.kaggle.com/c/avito-duplicate-ads-detection/
@image must be a PIL instance.
@hash_size must be a power of 2 and less than @image_scale.
@image_scale must be power of 2 and less than image size. By default is equal to max
power of 2 for an input image.
@mode (see modes in pywt library):
'haar' - Haar wavelets, by default
'db4' - Daubechies wavelets
@remove_max_haar_ll - remove the lowest low level (LL) frequency using Haar wavelet.
"""
import pywt
if image_scale is not None:
assert image_scale & (image_scale - 1) == 0, "image_scale is not power of 2"
else:
image_natural_scale = 2**int(numpy.log2(min(image.size)))
image_scale = max(image_natural_scale, hash_size)
ll_max_level = int(numpy.log2(image_scale))
level = int(numpy.log2(hash_size))
assert hash_size & (hash_size-1) == 0, "hash_size is not power of 2"
assert level <= ll_max_level, "hash_size in a wrong range"
dwt_level = ll_max_level - level
image = image.convert("L").resize((image_scale, image_scale), Image.ANTIALIAS)
pixels = numpy.asarray(image) / 255.
# Remove low level frequency LL(max_ll) if @remove_max_haar_ll using haar filter
if remove_max_haar_ll:
coeffs = pywt.wavedec2(pixels, 'haar', level = ll_max_level)
coeffs = list(coeffs)
coeffs[0] *= 0
pixels = pywt.waverec2(coeffs, 'haar')
# Use LL(K) as freq, where K is log2(@hash_size)
coeffs = pywt.wavedec2(pixels, mode, level = dwt_level)
dwt_low = coeffs[0]
# Substract median and compute hash
med = numpy.median(dwt_low)
diff = dwt_low > med
return ImageHash(diff)
2.3 宏观思路:
我们现在手里的武器:
掌握了一种叫Whash的函数,把图片传入函数,返回一个可以描述一张图片的“特征码”,凭借对比“特征码”的异同之处来判断是不是同一张图片或者相似图片。
我们需要解决的问题:
给你一个图片或者视频,说出这是数据库的哪一个视频。
2.3.1 思路描述:
将db数据库的视频切帧,每隔10帧左右保存一张图片,然后根据图片生成对应的“特征码”,全部处理后,我们会获得3186个视频中出现过的事物的全部信息,也就是“特征码”,大概60000个“特征码”,采用十六进制存储为csv格式,大小为13M左右。这部分预处理交给build.py去做
判断图片来自哪个视频:
加载处理过的60000个特征码,把目标图片传入Whash函数,获得特征码,进行比较,选取差别(汉明距最小)的目标“特征值”,返回该“特征值”来自的db数据视频id。
判断视频是db中哪个视频:
比图片多一步预处理,将待查找视频切取某一帧,后续简化为图片查找。
2.3.2 面临的问题:
1)不同种类的泛用性
测试时需要传入各种处理过的不同类型,尽管Whash的鲁棒性较强,抗干扰能力也还可以,但是某些类型,如“黑边”“裁切”图片准确率极低。
2)遍历的复杂度
查询每一张图片都需要进行遍历获得所有汉明距离,而“特征码”不同点的随机性,以及“非存在性”使得索引或者传统查找方式难以使用。
“非存在性”人话版:
假设待查找特征码为10001,我们当然想要寻找标号为10001的特征码,然而因为切帧并不一定就正好切到原图,就算切到原图,经过变换后也基本不可能是10001。
假设我们站在上帝视角,最相近的图片特征码为“10004”,汉名距离为3,事实便是:我们要查的数据不存在数据库中,我们只能找最相近的某一个值,而这个“最”怎么避免遍历查找便是问题,而且不同图片查找后汉明距离这一数据不能得到有效利用,只能废弃。
“特征码不同点的随机性”人话版:
此时我们想到能否让数据库数据排好队,我们从第一位赶着来,但是问题又来了,这个图片特征码为10001,而上帝视角的我们又知道了,最相似的图片是20101,距离为3。我们不知道哪一位是变的,因此从哪一位开始对比似乎都显得不合适。
经过小组讨论(一共就两个人),我们探讨了似乎可行的方案,但并未实施落地,原理如下

PS:1、采用size=16的whash值长度位256位0或1,但存储时采用16进制。
2、汉明距离大于20基本不可能是原图。
我们不关心0和1的具体位置,允许你是0我是1的情况存在,只不过这样我们的“汉明距离”便会增加1。基于以上理论,我们将256位数据分段,统计每段0和1的个数,比如说分了四段,1的个数分别为 20,38,54,19(0~64取值),现在我们拿到了一个带查找特征码,他的分段数据为:17,12,52,22。那我们便可以根据第二段差距过大的原因,直接否决他们是原图的可能性。
有同学可能要问了,这不还是比较吗,但请注意,分段数据是可以排序的,我们建立类似树状的结构,1,1,1,1->1,1,1,2---->>>>64,64,64,64
拿到一个图片,我们计算每段01个数,假如为30,30,30,30,那我们进行遍历查找的数据可能只需要是20,20,20,20到40,40,40,40这部分的数据。
但是在实际操作中还是存在一定的技术难度,比如构建数据结构,每段容错只给10是否合理,截至提交时依旧采用遍历方式(太菜了)。
3)该方式无法使用GPU加速
暂时没有研究过“汉明距离”遍历计算以及生成hash值如何使用gpu加速的问题。
2.4 准确率优化
2.4.1种类判断:
1. 非敏感类型
WHash 算法对黑白、颜色反转、Logo、模糊、水印、字幕这几类不敏感,原因如下:黑白、颜色反转因为统一转换为灰度图的原因,颜色信息会被丢弃,因此来自颜色的干扰不会产生影响;
Logo、模糊、水印因为在获取低频信息以及迭代时会丢弃掉这些影响,放大了部分低频信息;字幕会对图片特征值获取产生部分影响,但是从实际结果来看,海明距仅增加 1 到 2,可以忽略。
2. 敏感类型
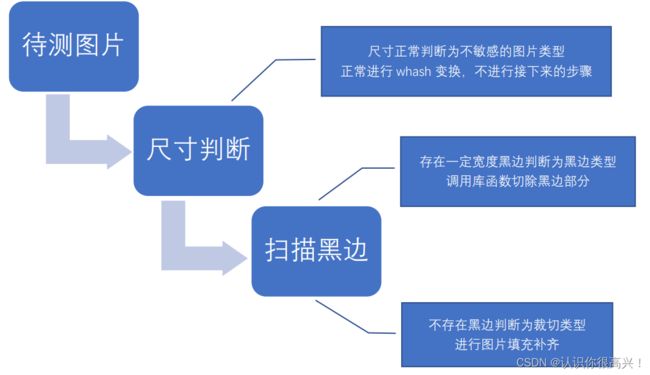
只需要处理 Crop,black-pad 两种类型的图片或视频,思路步骤如下:
2.4.2 后续处理
1. 黑边类型
扫描黑边采用像素扫描的方式,从左上和左下的第一个像素点进行扫描,并向中心渐进。默认存在黑边,记录黑边的“宽度”,直到发现某一行出现大量非黑色像素点停止记录,观察“黑边”宽度(即已经扫描过的行数),若小于某临界值,则认为不存在黑边。若在临界值之上,则判定存在黑边。
黑边图片可以直接根据记录的“黑边宽度”,使用 OpenCV 的裁切函数删除黑边区域。
2. 裁切类型
这部分处理花费了很多心思,困难有二:
1)主要难以判断是否是裁切类图片或者视频;
2)裁切视频或图片该如何在3000个视频正确匹配,基于像素遍历扫描还是基于深度学习?
当时并没有很好的方案能够进行适配。但注意到所有的测试集与 DB 样本集中,除了竖屏视频,其余视频样本长宽比均维持在1280*720 类似的比例,裁切类型则会生成比例不定的任意类型图片,且大小不会过小,借助这一特点, 可以尝试判断图片比例,按照图片比例进行筛选,从而分离出裁切类型。
2.4.3 裁切图片预处理
裁切图片需要进行补全操作 OpenCV 库中提供了这几个常见的补全方式:
- Original:原裁切图
- REPLICATE: 复制边缘上的像素颗粒,所有的维度都使用当前的点
- REFLECT: 进行以边界为对称轴的翻转,即 4321|123456|6543 的方式
- REFLECT_101: 按行进行中间值翻转 即 543|1234567|345 的方式
- WRAP: 外包装法即 123|123456|456 的方式,相当于进行了边缘部分的复制
- CONSTANT: 进行常数的补全操作, 例如参数 value=0,表示使用颜色 0 进行补全操作

根据扩充效果,首先排除 CONSTANT 方法,单一的色块堆叠(无论什么颜色)会对 Whash 算法造成巨 大误差(先前去除黑边就是为了避免该误差)。
接下来则是运行测试样例,统计不同扩充方式对图片匹配准确率提升的大小。测试时挑选了原本无法正确匹配的裁剪类图片100 张,分别使用 REPLICATE、REFLECT、REFLECT_101、WRAP 四种算法进行边界填充,REPLICATE 算法表现最好,再次成功识别了42张(裁切类型直接匹配准确率不足30%,这还是裁切部分不算太多的情况下,相当惨淡),其余算法均在35张左右。
三、核心代码介绍
因为详细代码过长,此处不进行全部粘贴,文末会附上代码和数据集的下载链接
3.1 build.py
def cut_video(file_path, save_path):
"""
指定视频文件目录 file_path
指定存放目录 save_path
功能:根据指定目录,获取视频并生成同名文件夹,文件夹下存放切帧图片
file_path/test_video.mp4 --> save_path/test_video/1.jpg--n.jpg
切图文件夹名会与视频文件夹名保持一致 切图名由数字 1 开始递增
"""
passdef get_hash(main_path, save_path):
"""
指定数据库的切图路径,生成hash值,并在指定位置保存为csv文件
变量说明:
关于HASH
hash针对的是一张图片,在本函数中,三个hash变量所代表的内容如下:
all_hash:文件夹下所有视频的所有帧的hash
per_hash:某个视频的所有帧的 hash
pic_hash:某个视频的某一帧的 hash
即多个pic_hash组成per_hash,多个per_hash组成all_hash
关于 PATH
结构:main_path/video_1/1.jpg
main_path: 总路径,包含诸如 video_1、video_2等文件夹
per_path: 精确到 video_1文件夹
pic_names: 精确到video_1的 jpg们
"""
pass
build.py运行时需要传入db文件夹位置,并指定cache文件夹,用来存放切图和hash值文件
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--db', type=str, help='请输入文件夹名称')
parser.add_argument('--cache', type=str, help='请输入文件夹名称')
args = parser.parse_args()
video_cut_path = os.path.join(args.cache, 'video_cut')
hash_data_path = os.path.join(args.cache, 'hash_data')
cut_video(args.db, video_cut_path)
get_hash(video_cut_path, hash_data_path)
print('处理完毕,请运行query_image.py与query_video.py')
return
3.2 query_image.py
def auto_core(img_dir_name, rows):
"""
此为 auto_detection()的核心匹配函数,部分变量释义请参考该函数
为了便于计算时间且使代码较为清晰易读,我们进行了核心函数分离
"""
pass
def auto_detection(full_path, result_path, csv_file):
"""
思路:
根据build.py 中生成 csv文件中的 hash值,从full_path中读取图片,
匹配获得最相似的hash值,将全部结果输出在result_path目录中,会生成两个
文件,依次是匹配对照表result.csv以及time_cost.txt
target_list: 存储匹配到的文件名列表 (即我认为与 3 号文件匹配,这里就会存储 3)
dir_name_list: 指定匹配的图片名列表
all_dist: 每个匹配项的海明距离列表
因为在数据处理时,维持文件名不变,所以在csv中观察名称是否一一对应即可判断是否匹配成功
"""
auto_core(img_dir_name, rows)
passdef deal_bp_and_shape(full_pic_path, write_path):
"""
因比赛方案中存在两种难以处理图片
crop裁切类图片:hash值会因为裁切图片位移错位而失去准确度,
black_padding附加黑边类图片:黑边会在hash值中生成过多代表黑色的数值导致汉明距离异常增大
共同特点:图片长宽异常,长宽像素点个数与db数据库中过的图片不一致
处理方式:
黑边类:
自上而下自左而右扫描图片,遇到非纯黑点停止,判断已扫描的行数,大于定值即视为黑边图
因为扫描时存储了已扫描行数,上下对称切除黑边即可
裁切类:
考虑到判断是否为裁切较为困难,出于节约时间的考虑,根据比赛数据,我们采用了直接判断图像像素大小的方式
但是该方式缺点不言而喻,希望后续可以改进
工作流程:
1、在judge_pic()函数中判断是否为长宽比异常图片,因为在本次数据集中,长宽比异常时必定属于以上两类类型
2、异常图片传入本函数deal_bp_and_shape(),先扫描黑边,如判定存在黑边,切除黑边进行下一张判断
判定无黑边,则使用cv2.copyMakeBorder()扩充方式补全四周,补全后大小为标准图片大小
实践证明:对于本次数据集,对称补全后的图片准确率上升20%以上,不失为一种处理方式,但不具备推广性。
"""
pass
def judge_pic(image_path, img_pre_path):
"""
处理方式以及原理参考deal_bp_and_shape()函数备注
"""
deal_bp_and_shape(full_pic_path, write_path)
passquery_image.py执行时需要传入先前的cache参数,指定结果输出文件位置result,指定待查找图片位置img
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--cache', type=str, help='请输入文件夹名称')
parser.add_argument('--result', type=str, help='请输入文件夹名称')
parser.add_argument('--img', type=str, help='请输入文件夹名称')
args = parser.parse_args()
hash_data_path = os.path.join(args.cache, 'hash_data', 'data.csv')
img_pre_path = os.path.join(args.cache, 'img_pre_path')
img_res_path = os.path.join(args.result, 'img_res_path')
time_start = time.time() # 计时开始
print('计时开始,正在预处理请稍后')
judge_pic(args.img, img_pre_path)
auto_detection(img_pre_path, img_res_path, hash_data_path)
time_end = time.time() # 计时结束
# 写入txt文件
time_cost = time_end - time_start
with open(os.path.join(img_res_path, 'time_cost.txt'), 'w', encoding='gbk') as f:
f.write('所在文件夹所有图片匹配总耗时' + str(round(time_cost * 1000, 2)) + '毫秒')
print('已写入', os.path.join(img_res_path, 'time_cost.txt'), '文件,编码集为gbk')
print('匹配完毕,请前往', img_res_path, '文件夹查看')
return3.3 query_video.py
与query_image.py极为相似,多出一步待测视频切帧的步骤:
def cut_video_for_once(file_path, save_path):
"""
视频检索核心与图片检索相同,每个视频切帧一张
即化简为图片检索思路
"""
pass四、执行说明
4.1 运行 build.py
- --db: db 样本池的完全路径
- --cache: 指定一个文件夹存放预处理相关数据,同样需要输入完全路径
jupyter或linux请执行:
python build.py --db /data/db --cache /data/cache cache
文件夹会自动创建,事先手动创建也可,下同
4.2 运行 query_image.py
- --cache: build 中指定的 cache 完全路径
- --result: 运行结果存放路径,从中查询匹配结果 result.csv 及时间花费 time_cost.txt
- --img: 指定待查找图片文件夹的完全路径
jupyter或linux请执行:
python query_image.py --cache /data/cache --result /data/result --img /data/image
4.3:运行 query_video.py
- --cache: build 中指定的 cache 完全路径
- --result: 运行结果存放路径,从中查询匹配结果 result.csv 及时间花费 time_cost.txt
- --video: 指定待查找视频文件夹的完全路径
jupyter或linux请执行:
python query_video.py --cache /data/cache --result /data/result --img /data/video
4.4pycharm传参方式

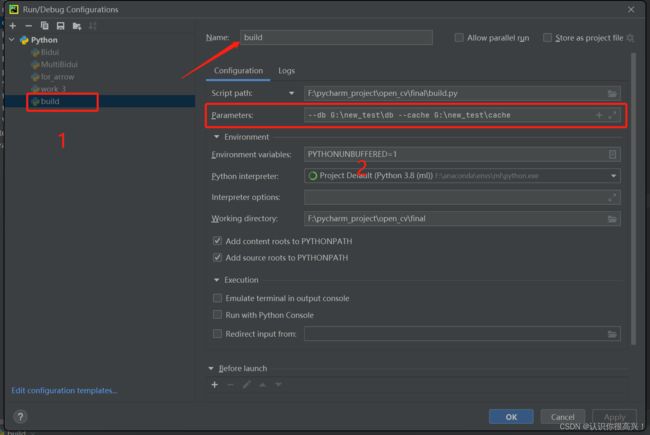
4.5 build执行如下
此时正在切图
 此时正在生成对应hash值
此时正在生成对应hash值
处理完毕
4.6 query_image.py执行如下
第一行的预处理可能会持续稍久一点,因为此时会判断是否存在黑边和裁切类型,并且尝试除去黑边和补全裁切。

匹配完毕并保存匹配文件到指定目录。
4.6 query_image.py执行如下
此时正在视频切帧

此时正在匹配
 匹配完成并保存匹配文件到指定目录
匹配完成并保存匹配文件到指定目录

4.7 观察结果

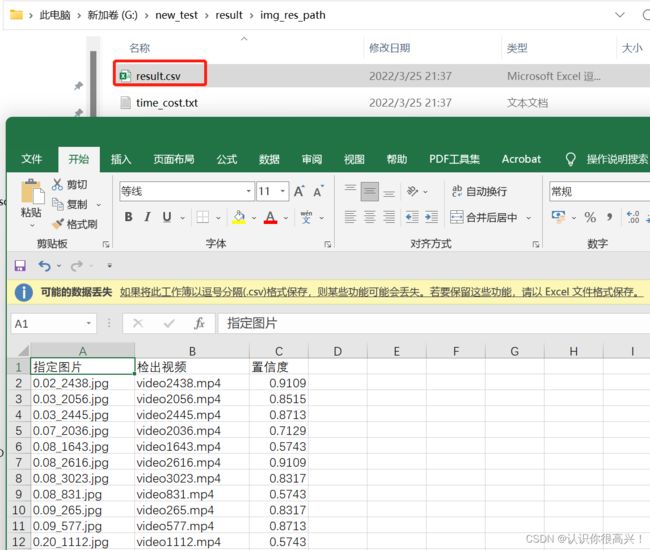
五、后续说明
5.1 数据集方面
数据集分为:
- 总数据集(分卷压缩)
- tiny数据集(200个db、200个image、video)
5.2 代码方面
代码分为:
- for_windows建议在pycharm中按指定传参方式运行
- for_docker根据镜像和dockerfile搭建环境并挂载外部数据
额外提供一个创建数据库及对应image、video的代码方式,首先随意手动创建一个db,然后填入3186个视频的总数据地址,会根据名称自动建库,代码不在赘述,相信应该较为浅显易懂。
额外提供一个检测准确率的代码方式,指定csv文件地址,调整好正确的列名,即可计算准确率。
代码及数据集链接:喜欢本文的请点赞收藏一波吧
提取码:3b51