掩膜(mask)的学习总结
mask
一、什么是掩膜
首先我们从物理的角度来看看mask到底是什么过程。在半导体制造中,许多芯片工艺步骤采用光刻技术,用于这些步骤的图形“底片”称为掩膜(也称作“掩模”),其作用是:在硅片上选定的区域中对一个不透明的图形模板遮盖,继而下面的腐蚀或扩散将只影响选定的区域以外的区域。
图像掩膜与其类似,用选定的图像、图形或物体,对处理的图像(全部或局部)进行遮挡,来控制图像处理的区域或处理过程。用于覆盖的特定图像或物体称为掩模或模板。
光学图像处理中,掩模可以足胶片、滤光片等。数字图像处理中,掩模为二维矩阵数组,有时也用多值图像
二、掩膜的用法
数字图像处理中,图像掩模主要用于:
2.1 提取感兴趣区:用预先制作的感兴趣区掩膜与待处理图像相乘,得到感兴趣区图像,感兴趣区内图像值保持不变,而区外图像值都为0;
2.2 屏蔽作用:用掩膜对图像上某些区域作屏蔽,使其不参加处理或不参加处理参数的计算,或仅对屏蔽区作处理或统计;
2.3 结构特征提取:用相似性变量或图像匹配方法检测和提取图像中与掩膜相似的结构特征;
2.4 特殊形状图像的制作。
三、掩膜运算的一个小实例
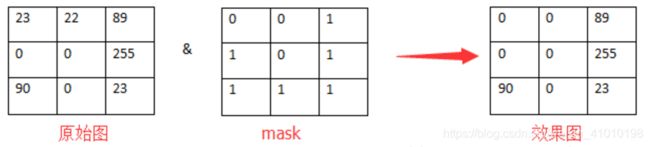
以图和掩膜的与运算为例:
原图中的每个像素和掩膜中的每个对应像素进行与运算。比如1 & 1 = 1;1 & 0 = 0;
比如一个3 * 3的图像与3 * 3的掩膜进行运算,得到的结果图像就是:
四、小结
1.图像中,各种位运算,比如与、或、非运算与普通的位运算类似。
2.如果用一句话总结,掩膜就是两幅图像之间进行的各种位运算操作。
按照上述定义,非线性激活函数Relu(根据输出的正负区间进行简单粗暴的二分)、dropout机制(根据概率进行二分)都可以理解为泛化的mask操作。
从任务适应性上,mask在图像和自然语言处理中都广为应用,其应用包括但不局限于:图像兴趣区提取、图像屏蔽、图像结构特征提取、语句padding对齐的mask、语言模型中sequence mask等。
从使用mask的具体流程上,其可以作用于数据的预处理(如原始数据的过滤)、模型中间层(如relu、drop等)和模型损失计算上(如padding序列的损失忽略)。
尽管上述操作均可统称为mask,但其具体的算法实现细节需要根据实际需求进行设计,下面利用pytroch来实现几个典型的例子。
实例1:图像兴趣区提取
通过mask张量定义兴趣区(或非兴趣区)位置张量,将非兴趣区上的张量元素用0值填充。
import torch
a = torch.randint(0, 255, (2, 3, 3)) # 两张单通道的图像张量
print(a)
# tensor([[[ 77, 58, 134],
# [ 83, 187, 36],
# [103, 183, 138]],
# [[223, 19, 7],
# [ 55, 167, 77],
# [231, 223, 37]]])
mask = torch.tensor([[1, 0, 0], [0, 1, 0], [0, 0, 1]]).bool() # 1为感兴趣区域位置,0为非感兴趣,可将其值填为0
b=a.masked_fill_(~mask, 0) # 注意按照上述定义,需取反~
print(b)
# tensor([[[ 77, 0, 0],
# [ 0, 187, 0],
# [ 0, 0, 138]],
# [[223, 0, 0],
# [ 0, 167, 0],
# [ 0, 0, 37]]])实例2:文本Embedding层中对padding的处理
在NLP中,虽然CNN特征抽取器要求文本长度为定长,而RNN和Tranformer特征抽取器虽然可应对不定长的文本序列,但为了在batch维度上进行并行化处理,一般还是选择将文本进行长度对齐,即过长序列进行截断,而长度不足序列进行padding操作。padding操作只是数据维度上的对齐,其并不应该对整个网络的计算贡献任何东西,所以必须进行mask操作。
在pytorch中的词嵌入对象Embedding中,直接通过设定padding_idx参数,即可自动对指定的pad编号进行mask操作,即将padding_idx对象的词向量元素均设为0,从而使得该词对网络的正向传播和梯度反向传播均失活,从而达到了mask的目的。
import torch
import torch.nn as nn
a = torch.tensor([[1,2,3], [2,1,0]]) # 2段文本数据
net = nn.Embedding(num_embeddings=5, embedding_dim=5, padding_idx=0) # 词嵌入层
b = net(a) # 进行词嵌入
print(b)
# tensor([[[-1.8167, 0.0701, 2.0281, -0.7096, 1.0128],
# [ 2.3647, 1.0678, 0.0383, 0.3265, -0.1237],
# [ 1.0633, 0.4248, 2.0323, -0.3140, -0.5124]],
# [[ 2.3647, 1.0678, 0.0383, 0.3265, -0.1237],
# [-1.8167, 0.0701, 2.0281, -0.7096, 1.0128],
# [ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]]],
# grad_fn=)
# 会发现padding=0处的张量均变为了0 import torch
import torch.nn as nn
a = torch.tensor([[1,2,3], [2,1,0]])
net = nn.Embedding(num_embeddings=10, embedding_dim=5) # 并未设置padding_index参数
a_ = net(a) # 观察结果,发现果然没有全为0的词向量
mask = (a!=0).float().unsequeeze(-1) # 手动得到mask张量,注意要升维
b = a_ * mask # 会发现得到了上述的效果
# tensor([[[ 0.2723, -0.2836, 0.0061, 1.0740, -1.1754],
# [-0.6695, -0.9080, 0.7244, 0.3022, 0.5039],
# [ 1.8236, -1.1954, -0.3024, 0.0857, -0.2242]],
# [[-0.6695, -0.9080, 0.7244, 0.3022, 0.5039],
# [ 0.2723, -0.2836, 0.0061, 1.0740, -1.1754],
# [ 0.0000, 0.0000, 0.0000, -0.0000, -0.0000]]],
# grad_fn=)
实例3:padding的损失计算问题
对于文本序列中的NLP,其中
在pytorch中的损失计算对象CrossEntropyLoss等中,直接通过设定ignore_index参数,即可自动忽略
下面是pytorch中的一个简单的例子:
import torch
import torch.nn as nn
targets = torch.tensor([1, 2, 0]) # 某个时间步batch中各样本的labels
preds = torch.tensor([[1.4, 0.5, 1.1], [0.7, 0.4, 0.2], [2.4, 0.2, 1.4]]) # 某个时间步的batch*preds
criterion1 = nn.CrossEntropyLoss() # 不屏蔽padding
criterion2 = nn.CrossEntropyLoss(ignore_index=0) # 不屏蔽padding
loss1 = criterion1(preds, targets)
# 返回 tensor(1.1362)
loss2 = criterion2(preds, targets)
# 返回 tensor(1.5088) , 例子中该损失只考虑了2个样本
下面,手动实现下该机制:
import torch
import torch.nn as nn
import torch.nn.functional as F
targets = torch.tensor([1, 2, 0]) # 某个时间步batch中各样本的labels
preds = torch.tensor([[1.4, 0.5, 1.1], [0.7, 0.4, 0.2], [2.4, 0.2, 1.4]]) # 某个时间步的batch*preds
def pad_loss(pred, target, pad_index=None):
if pad_index == None: # 不考虑padding的mask
mask = torch.ones_like(target, dtype=torch.float)
else:
mask = (target != pad_index).float()
nopd = mask.sum().item() # 实际计算的样本label数
target = torch.zeros(pred.shape).scatter(dim=1, index=target.unsqueeze(-1), source=torch.tensor(1)) # 对labels进行one-hot编码
target_ = target * mask.unsqueeze(-1) # 对labels进行mask
loss = -(F.log_softmax(pred, dim=-1) * target_.float()).sum()/nopd # NLL损失
return loss
loss1 = pad_loss(preds, preds)
# 返回 tensor(1.1362)
loss2 = pad_loss(preds, preds, pad_index=0)
# 返回 tensor(1.5088)
实例4:self-attention对padding的处理
Transformer中提出的self-attention机制可以通过文本内部两两元素进行信息的提取,在其中计算各score的softmax权重时,不能将padding处的文本考虑进来(因为这些文本并不存在)。所以在进行softmax前需要进行mask操作(如下图)。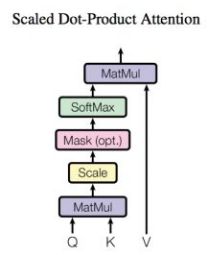
其具体策略是,将padding的文本处的score设定为负的极大值,这样最终的权重接近于0,从而这些文本不会对attention后生成的向量其作用。
import torch
import torch.nn as nn
import torch.nn.functional as F
a = torch.tensor([2,1,0]) # 文本序列
score = torch.tensor([1.2, 2.3, 4]) # score结果
mask = (a == 0).bool() # 生成mask
score_ = F.softmax(score.masked_fill(mask, -np.inf), dim=-1) # padding处填充-inf,从而对softmax结果没影响
# tensor([0.2497, 0.7503, 0.0000])
实例5:序列生成模型中对后续未知文本的处理
在Transformer中Decoder部分的self-attention处,由于是模型的目的在于序列生成,所以无论在训练过程中需要特意将后续文本进行mask,不让模型看到。
此时的mask操作称为针对序列的sequence mask,其以文本序列长度为单位,生成一个上三角矩阵矩阵,其中上三角元素为0,其余元素为1,表示在当前word处(即矩阵的对角元)模型看不到后面的words。
import numpy as np
import torch
def sequence_mask(size):
mask_shape = (size, size)
return torch.from_numpy(np.tril(np.ones(mask_shape),k=0))
实例6:mask的联合操作
比如在Transformer的Decoder中self-attention中,既需要对&位运算,以迭加效果。
def combine_mask(batch_text, inpad_index=0):
"""
batch_text: 文本batch, Batch * Sequence
"""
pad_mask = batch_text != inpad_index # Batch * Sequence
sequence_len = batch_text.shape[1] # 时间步长
sequence_mask = torch.tensor(np.tril(np.ones((sequence_len, sequence_len)), k=0)).byte() # Sequence * Sequence
mask = pad_mask.unsqueeze(-2) & sequence_mask # Batch * Sequence * Sequence 注意将pad_mask升维
return mask