python评分卡3_woe与IV分箱实现
本系列分以下章节:
python评分卡1_woe与IV值
python评分卡2_woe与IV分箱方法
python评分卡3_woe与IV分箱实现
python评分卡4_logistics原理与解法_sklearn英译汉
python评分卡5_Logit例1_plot_logistic_l1_l2_sparsity
python评分卡6_Logit例2plot_logistic_path
1.Python第三方库
打开网址:https://pypi.org 在搜寻框中输入 woe,如下图所示:  跳转到:
跳转到:
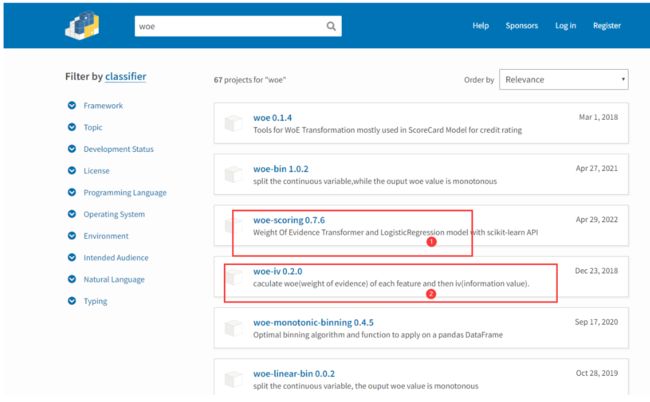
如图所示,选择woe-scoring与woe-iv这两个包
1.1选woe-scoring
优点:
1).对于1,时间较为新,我现在写博客是2022-05-08,技术要努力学新的,新的通常兼容旧的功能,并根据旧的使用经验做了改进。
2).评分卡后期要结合Logistic回归模型,
Weight Of Evidence Transformer and LogisticRegression model with scikit-learn API翻译成中文:
证据转换器的权重和使用scikit-learn中API的Logistic回归模型
不足:
1).包太新,关于这个包的网上资料较少,甚至这个包的说明文档都没有
2).这个时候需要去github.com去寻找资料,幸运的是找到了,下面一起学习翻一下
3).包的依赖较为新,有时候需要重新安装更新一系列包
1.2选woe-iv
优点:
1).相关性强 aculate woe(weight of evidence) of each feature and then iv(information value).译文为计算每个特征的woe(证据权重),然后计算iv(信息值)。
不足:
1).时间久远,功能可能没有最新的包完善
2).不一定兼容现在的环境配置
2.woe-scoring 使用说明
2.1 WOE-Scoring
Monotone Weight Of Evidence Transformer and LogisticRegression model with scikit-learn API
证据转换器的单调权重和使用scikit-learn中API的Logistic回归模型
2.2 Quickstart 快速入门
2.2.1 Install the package: 安装包
pip install woe-scoring
2.2.2 Use WOETransformer: 使用woe转换器
import pandas as pd
from woe_scoring import WOETransformer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
使用数据集介绍
代码数据连接
PassengerId: 乘客在数据集中的编号
Survived:是否存活(0代表否,1代表是)
Pclass:社会阶级(1代表上层阶级,2代表中层阶级,3代表底层阶级)
Name:船上乘客的名字
Sex:船上乘客的性别
Age:船上乘客的年龄(可能存在 NaN)
SibSp:乘客在船上的兄弟姐妹和配偶的数量
Parch:乘客在船上的父母以及小孩的数量
Ticket:乘客船票的编号
Fare:乘客为船票支付的费用
Cabin:乘客所在船舱的编号(可能存在 NaN)
Embarked:乘客上船的港口(C 代表从 Cherbourg 登船,Q 代表从 Queenstown 登船,S 代表从 Southampton 登船)
df
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | 1 | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | 0 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | 0 | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | 0 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | 0 | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | 0 |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | 0 | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | 0 |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | 1 | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | 887 | 0 | 2 | Montvila, Rev. Juozas | 1 | 27.0 | 0 | 0 | 211536 | 13.0000 | NaN | 0 |
| 887 | 888 | 1 | 1 | Graham, Miss. Margaret Edith | 0 | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | 0 |
| 888 | 889 | 0 | 3 | Johnston, Miss. Catherine Helen "Carrie" | 0 | NaN | 1 | 2 | W./C. 6607 | 23.4500 | NaN | 0 |
| 889 | 890 | 1 | 1 | Behr, Mr. Karl Howell | 1 | 26.0 | 0 | 0 | 111369 | 30.0000 | C148 | 0 |
| 890 | 891 | 0 | 3 | Dooley, Mr. Patrick | 1 | 32.0 | 0 | 0 | 370376 | 7.7500 | NaN | 2 |
891 rows × 12 columns
df = pd.read_csv('titanic_data.csv')
df['Sex']=df['Sex'].apply(lambda x: 1 if x=='male' else 0 )
df['Embarked']=df['Embarked'].apply(lambda x: 1 if x=='C' else x).apply(lambda x: 2 if x=='Q' else 0 )
train, test = train_test_split(
df, test_size=0.3, random_state=42, stratify=df["Survived"]
)
cat_cols = [
"PassengerId",
"Survived",
"Name",
"Ticket",
"Cabin",
]
special_cols= [
"Pclass",
"Sex",
"SibSp",
"Parch",
"Embarked",
]
encoder = WOETransformer(
max_bins=8,
min_pct_group=0.1,
diff_woe_threshold=0.1,
cat_features=cat_cols,
special_cols=special_cols,
n_jobs=-1,
merge_type='chi2',
)
encoder.fit(train, train["Survived"])
encoder.save("train_dict.json")
enc_train = encoder.transform(train)
enc_test = encoder.transform(test)
model = LogisticRegression()
model.fit(enc_train, train["Survived"])
test_proba = model.predict_proba(enc_test)[:, 1]
#test_proba
2.2.3 Use CreateModel: 使用创立的model
import pandas as pd
from woe_scoring import CreateModel
from sklearn.model_selection import train_test_split
df = pd.read_csv('titanic_data.csv')
df['Sex']=df['Sex'].apply(lambda x: 1 if x=='male' else 0 )
df['Embarked']=df['Embarked'].apply(lambda x: 1 if x=='C' else x).apply(lambda x: 2 if x=='Q' else 0 )
train, test = train_test_split(
df, test_size=0.3, random_state=42, stratify=df["Survived"]
)
cat_cols = [
"PassengerId",
"Survived",
"Name",
"Ticket",
"Cabin",
]
model = CreateModel(
max_vars=0.8,
special_cols=special_cols,
n_jobs=-1,
random_state=42,
class_weight='balanced',
cv=3,
)
model.fit(train, train["Survived"])
model.save_reports("/")
test_proba = model.predict_proba(test[model.feature_names_])
D:\d_programe\Anaconda3\lib\site-packages\statsmodels\tsa\tsatools.py:142: FutureWarning: In a future version of pandas all arguments of concat except for the argument 'objs' will be keyword-only
x = pd.concat(x[::order], 1)
Optimization terminated successfully.
Current function value: 0.462147
Iterations 6
D:\d_programe\Anaconda3\lib\site-packages\statsmodels\tsa\tsatools.py:142: FutureWarning: In a future version of pandas all arguments of concat except for the argument 'objs' will be keyword-only
x = pd.concat(x[::order], 1)
3.woe-iv
3.1 项目描述
首先我们看下包的项目描述,这是我们了解Python第三方库最快的途径
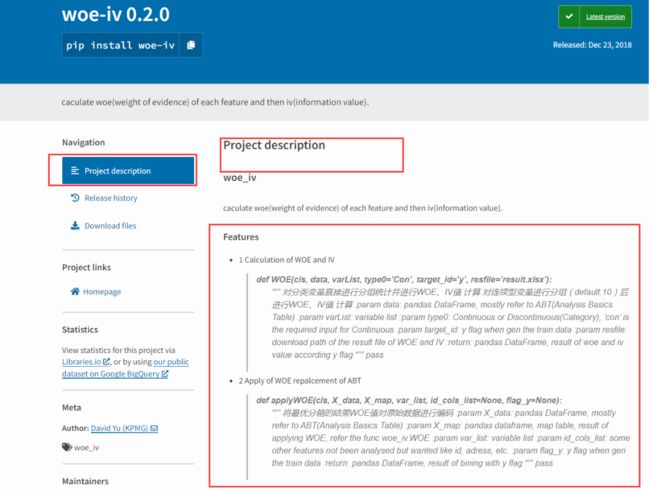
Features 特征
Calculation of WOE and IV 计算woe和iv
def WOE(cls, data, varList, type0=’Con’, target_id=’y’, resfile=’result.xlsx’):
“”" 对分类变量直接进行分组统计并进行WOE、IV值 计算 对连续型变量进行分组(default:10)后进行WOE、IV值 计算 :
param data: pandas DataFrame, mostly refer to ABT(Analysis Basics Table) :
param varList: variable list :
param type0: Continuous or Discontinuous(Category), ‘con’ is the required input for Continuous :
param target_id: y flag when gen the train data :
param resfile: download path of the result file of WOE and IV :
return: pandas DataFrame, result of woe and iv value according y flag
“”"
定义函数 WOE(……):
“”"
参数 data: 变量是pandas DataFrame类型,主要参考ABT(分析基础表):
参数 varList: 变量是list类型 :
参数 type0: 连续或者非连续(类别) , 当值‘con’时要求输入的是连续型变量
参数 target_id: 生成列车数据时的y标志:
参数 resfile: WOE和IV结果文件的下载路径;
return返回值): pandas DataFrame结构类型, 根据y标志计算的woe和iv值结果;
“”"
2 Apply of WOE repalcement of ABT 应用WOE替代ABT(分析基础表)
def applyWOE(cls, X_data, X_map, var_list, id_cols_list=None, flag_y=None):
“”“将最优分箱的结果WOE值对原始数据进行编码 :
param X_data: pandas DataFrame, mostly refer to ABT(Analysis Basics Table) :
param X_map: pandas dataframe, map table, result of applying WOE, refer the func woe_iv.WOE :
param var_list: variable list :
param id_cols_list: some other features not been analysed but wanted like id, adress, etc. :
param flag_y: y flag when gen the train data :
return: pandas DataFrame, result of bining with y flag
“””
参数 X_data: pandas DataFrame结构类型, mostly refer to ABT(Analysis Basics Table) :
参数 X_map: pandas dataframe结构类型, map table, result of applying WOE, refer the func woe_iv.WOE :
参数 var_list: 变脸是 list 结构类型:
参数 id_cols_list: some other features not been analysed but wanted like id, adress, etc. :
参数 flag_y: y flag when gen the train data :
返回值: pandas DataFrame结构类型, result of bining with y flag
4.Python编码计算iv 与woe
4.1 函数构造
import pandas as pd, numpy as np, os, re, math, time
# to check monotonicity of a series 检验序列的单调性
def is_monotonic(temp_series):
return all(temp_series[i] <= temp_series[i + 1] for i in range(len(temp_series) - 1)) or all(temp_series[i] >= temp_series[i + 1] for i in range(len(temp_series) - 1))
def prepare_bins(bin_data, c_i, target_col, max_bins):
force_bin = True
binned = False
remarks = np.nan
# ----------------- Monotonic binning -----------------
for n_bins in range(max_bins, 2, -1):
try:
bin_data[c_i + "_bins"] = pd.qcut(bin_data[c_i], n_bins, duplicates="drop")
monotonic_series = bin_data.groupby(c_i + "_bins")[target_col].mean().reset_index(drop=True)
if is_monotonic(monotonic_series):
force_bin = False
binned = True
remarks = "binned monotonically"
break
except:
pass
# ----------------- Force binning -----------------
# creating 2 bins forcefully because 2 bins will always be monotonic
if force_bin or (c_i + "_bins" in bin_data and bin_data[c_i + "_bins"].nunique() < 2):
_min=bin_data[c_i].min()
_mean=bin_data[c_i].mean()
_max=bin_data[c_i].max()
bin_data[c_i + "_bins"] = pd.cut(bin_data[c_i], [_min, _mean, _max], include_lowest=True)
if bin_data[c_i + "_bins"].nunique() == 2:
binned = True
remarks = "binned forcefully"
if binned:
return c_i + "_bins", remarks, bin_data[[c_i, c_i+"_bins", target_col]].copy()
else:
remarks = "couldn't bin"
return c_i, remarks, bin_data[[c_i, target_col]].copy()
# calculate WOE and IV for every group/bin/class for a provided feature 计算所提供功能的每个组/箱/类的WOE和IV
def iv_woe_4iter(binned_data, target_col, class_col):
if "_bins" in class_col:
binned_data[class_col] = binned_data[class_col].cat.add_categories(['Missing'])
binned_data[class_col] = binned_data[class_col].fillna("Missing")
temp_groupby = binned_data.groupby(class_col).agg({class_col.replace("_bins", ""):["min", "max"],
target_col: ["count", "sum", "mean"]}).reset_index()
else:
binned_data[class_col] = binned_data[class_col].fillna("Missing")
temp_groupby = binned_data.groupby(class_col).agg({class_col:["first", "first"],
target_col: ["count", "sum", "mean"]}).reset_index()
temp_groupby.columns = ["sample_class", "min_value", "max_value", "sample_count", "event_count", "event_rate"]
temp_groupby["non_event_count"] = temp_groupby["sample_count"] - temp_groupby["event_count"]
temp_groupby["non_event_rate"] = 1 - temp_groupby["event_rate"]
temp_groupby = temp_groupby[["sample_class", "min_value", "max_value", "sample_count",
"non_event_count", "non_event_rate", "event_count", "event_rate"]]
if "_bins" not in class_col and "Missing" in temp_groupby["min_value"]:
temp_groupby["min_value"] = temp_groupby["min_value"].replace({"Missing": np.nan})
temp_groupby["max_value"] = temp_groupby["max_value"].replace({"Missing": np.nan})
temp_groupby["feature"] = class_col
if "_bins" in class_col:
temp_groupby["sample_class_label"]=temp_groupby["sample_class"].replace({"Missing": np.nan}).astype('category').cat.codes.replace({-1: np.nan})
else:
temp_groupby["sample_class_label"]=np.nan
temp_groupby = temp_groupby[["feature", "sample_class", "sample_class_label", "sample_count", "min_value", "max_value",
"non_event_count", "non_event_rate", "event_count", "event_rate"]]
"""
**********get distribution of good and bad 得到好的和坏的分布
"""
temp_groupby['distbn_non_event'] = temp_groupby["non_event_count"]/temp_groupby["non_event_count"].sum()
temp_groupby['distbn_event'] = temp_groupby["event_count"]/temp_groupby["event_count"].sum()
temp_groupby['woe'] = np.log(temp_groupby['distbn_non_event'] / temp_groupby['distbn_event'])
temp_groupby['iv'] = (temp_groupby['distbn_non_event'] - temp_groupby['distbn_event']) * temp_groupby['woe']
temp_groupby["woe"] = temp_groupby["woe"].replace([np.inf,-np.inf],0)
temp_groupby["iv"] = temp_groupby["iv"].replace([np.inf,-np.inf],0)
return temp_groupby
"""
- iterate over all features. 迭代所有功能。
- calculate WOE & IV for there classes.计算这些类别的woe与iv值
- append to one DataFrame woe_iv.追加到数据帧woe_iv中。
"""
def var_iter(data, target_col, max_bins):
woe_iv = pd.DataFrame()
remarks_list = []
for c_i in data.columns:
if c_i not in [target_col]:
# check if binning is required. if yes, then prepare bins and calculate woe and iv.
"""
----logic---
binning is done only when feature is continuous and non-binary. 仅当数据是连续型,且不是二进制时才会处理
Note: Make sure dtype of continuous columns in dataframe is not object. 确保dataframe中连续列的数据类型不是object。
"""
c_i_start_time=time.time()
if np.issubdtype(data[c_i], np.number) and data[c_i].nunique() > 2:
class_col, remarks, binned_data = prepare_bins(data[[c_i, target_col]].copy(), c_i, target_col, max_bins)
agg_data = iv_woe_4iter(binned_data.copy(), target_col, class_col)
remarks_list.append({"feature": c_i, "remarks": remarks})
else:
agg_data = iv_woe_4iter(data[[c_i, target_col]].copy(), target_col, c_i)
remarks_list.append({"feature": c_i, "remarks": "categorical"})
# print("---{} seconds. c_i: {}----".format(round(time.time() - c_i_start_time, 2), c_i))
woe_iv = woe_iv.append(agg_data)
return woe_iv, pd.DataFrame(remarks_list)
# after getting woe and iv for all classes of features calculate aggregated IV values for features.
def get_iv_woe(data, target_col, max_bins):
func_start_time = time.time()
woe_iv, binning_remarks = var_iter(data, target_col, max_bins)
print("------------------IV and WOE calculated for individual groups.------------------")
print("Total time elapsed: {} minutes".format(round((time.time() - func_start_time) / 60, 3)))
woe_iv["feature"] = woe_iv["feature"].replace("_bins", "", regex=True)
woe_iv = woe_iv[["feature", "sample_class", "sample_class_label", "sample_count", "min_value", "max_value",
"non_event_count", "non_event_rate", "event_count", "event_rate", 'distbn_non_event',
'distbn_event', 'woe', 'iv']]
iv = woe_iv.groupby("feature")[["iv"]].agg(["sum", "count"]).reset_index()
print("------------------Aggregated IV values for features calculated.------------------")
print("Total time elapsed: {} minutes".format(round((time.time() - func_start_time) / 60, 3)))
iv.columns = ["feature", "iv", "number_of_classes"]
null_percent_data=pd.DataFrame(data.isnull().mean()).reset_index()
null_percent_data.columns=["feature", "feature_null_percent"]
iv=iv.merge(null_percent_data, on="feature", how="left")
print("------------------Null percent calculated in features.------------------")
print("Total time elapsed: {} minutes".format(round((time.time() - func_start_time) / 60, 3)))
iv = iv.merge(binning_remarks, on="feature", how="left")
woe_iv = woe_iv.merge(iv[["feature", "iv", "remarks"]].rename(columns={"iv": "iv_sum"}), on="feature", how="left")
print("------------------Binning remarks added and process is complete.------------------")
print("Total time elapsed: {} minutes".format(round((time.time() - func_start_time) / 60, 3)))
return iv, woe_iv.replace({"Missing": np.nan})
4.2 函数调用
Step-1 : 加载数据
代码数据连接
data=pd.read_csv("data.csv")
print(data.shape)
(1000, 8)
step-2 调用get_iv_woe函数
iv, woe_iv = get_iv_woe(data.copy(), target_col="bad_customer", max_bins=20)
print(iv.shape, woe_iv.shape)
------------------IV and WOE calculated for individual groups.------------------
Total time elapsed: 0.009 minutes
------------------Aggregated IV values for features calculated.------------------
Total time elapsed: 0.009 minutes
------------------Null percent calculated in features.------------------
Total time elapsed: 0.009 minutes
------------------Binning remarks added and process is complete.------------------
Total time elapsed: 0.01 minutes
(7, 5) (49, 16)
D:\d_programe\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py:3444: PerformanceWarning: indexing past lexsort depth may impact performance.
exec(code_obj, self.user_global_ns, self.user_ns)
D:\d_programe\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py:3444: PerformanceWarning: indexing past lexsort depth may impact performance.
exec(code_obj, self.user_global_ns, self.user_ns)
注意:确保dataframe中连续列的数据类型不是object。如果是object,它将被认为是分类的,将不会处理
参考引用:
1.https://github.com/klaudia-nazarko
2.https://pypi.org/project/woe-iv/
3.https://pypi.org/project/woe-scoring/