Tensorflow2.0 自定义训练
文章目录
- 前言
- 一、自动微分运算 tf.GradientTape
- 二、tf.keras.metrics模块
-
- 1.tf.keras.metrics.Mean
- 2.tf.keras.metrics.SparseCategoricalAccuracy
- 三、自定义训练实战,手写数字识别
- 总结
前言
Tensorflow2.0中tf.keras 封装的实在是太好了,定义好模型后直接使用model.fit函数就可以完成训练,不过有时需要对数据进行一些特殊处理,或者多输入多输出的情况,或者还需要自定义loss和accuracy的情况,就需要使用自定义训练。
以下是本篇文章正文内容,下面案例可供参考
一、自动微分运算 tf.GradientTape
import tensorflow as tf
w=tf.Variable([[1.0]])
with tf.GradientTape() as t:
loss=w*w
grad=t.gradient(loss,w)#求loss对w的导数
grad
运行结果:
![]()
loss等于w的平方,loss对w求导为2w,w=1,所以loss对w的导数为2
也可以对常量求导
w=tf.constant(3.0)
with tf.GradientTape() as t:
t.watch(w)
loss=w*w
t.gradient(loss,w)
运行结果:
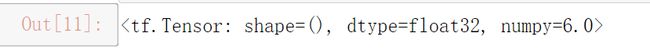
例子中的watch函数把需要计算梯度的变量w加进来了.
默认情况下GradientTape的资源在调用gradient函数后就被释放,无法再次调用,若想多次调用,则将persistent参数设置为True
w=tf.constant(3.0)
with tf.GradientTape(persistent=True) as t:
t.watch(w)
y=w*w
z=y*y
t.gradient(y,w),t.gradient(z,w)
运行结果:
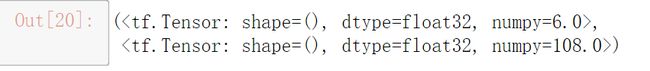
y对w求导为2w,z对w求导为4w^3 带入可得到导数值 6,108
二、tf.keras.metrics模块
1.tf.keras.metrics.Mean
用来求解均值,每调用一次就计算之前所有调用过的数的均值
示例:
m=tf.keras.metrics.Mean('acc')
m(10)
![]()
目前均值是10
m(20)
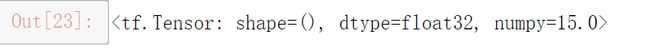
目前均值是15 (10+20)/2
m([30,40])
![]()
也可以直接传参一个列表
目前均值是25 (10+20+30+40)/4
在代码中执行,不会中途每次都打印一次结果,只得到最终的结果可以调用m.result()
m.result()
![]()
重置里面的值,使用reset_states方法
m.reset_states()
m.result()
![]()
重置为0
2.tf.keras.metrics.SparseCategoricalAccuracy
Tensorflow封装好的计算正确率的方法,每次调用也会将前面所计算出的正确率求平均,与tf.keras.metrics.Mean类似,传入参数不同,计算的的正确率的平均值
代码如下(示例):
a=tf.keras.metrics.SparseCategoricalAccuracy('acc')
labels=[0,1,2,3]
pred=[[0.8,0.05,0.05,0.1],
[0.05,0.8,0.05,0.1],
[0.15,0.15,0.65,0.05],
[0.05,0.65,0.2,0.1]]
例如有四条数据,标签是一维,输出值是二维的4*4的矩阵,第一个4代表四条数据,第二个四代表四类,四分类问题模型最终经过softmax激活函数输出四个概率分布值,概率最大值对应的索引为判别的类别
查看预测类别,调用tf.argmax
tf.argmax(pred,axis=1)
![]()
可见预测类别是0 1 2 1 真实类别是 0 1 2 3
计算正确率
a(labels,pred)
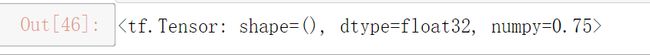
正确率是0.75
注:该方法不是计算正确率,而是计算前边得出的正确率的均值,该例子是第一次调用,则正确率的平均值则为当前正确率,若又调用一次,该次正确率为1,则输出的是(0.75+1)/2=0.875
三、自定义训练实战,手写数字识别
import tensorflow as tf
(train_image,train_lables),(test_image,test_labels)=tf.keras.datasets.mnist.load_data()#载入数据,若第一次调用则需要等待一小会下载
#都除以255将数据从0-255变为0-1,并指定其数据类型
train_image=tf.cast(train_image/255,tf.float32)
test_image=tf.cast(test_image/255,tf.float32)
#指定标签类型为int64
train_labels=tf.cast(train_lables,tf.int64)
test_labels=tf.cast(test_labels,tf.int64)
#封装为dataset
train_dataset=tf.data.Dataset.from_tensor_slices(
(train_image,train_labels)
)
test_dataset=tf.data.Dataset.from_tensor_slices(
(test_image,test_labels)
)
#将训练数据打乱并设置batch批次
train_dataset=train_dataset.shuffle(60000).batch(64)
test_dataset=test_dataset.batch(64)
#建立模型
model=tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(512,activation='relu'),
tf.keras.layers.Dense(256,activation='relu'),
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dense(10,activation='softmax')
])
#优化器
optimizer=tf.keras.optimizers.Adam()
#计算损失的函数,多分类交叉熵,类别是离散值,例如0 1 2 3
loss_fn=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False)
#计算训练集与测试集平均损失与正确率
train_loss=tf.keras.metrics.Mean('train_loss')
train_acc=tf.keras.metrics.SparseCategoricalAccuracy('train_acc')
test_loss=tf.keras.metrics.Mean('test_loss')
test_acc=tf.keras.metrics.SparseCategoricalAccuracy('test_acc')
#每一步训练
def train_step(model,images,labels):
with tf.GradientTape() as t:
pred=model(images)
loss_step=loss_fn(labels,pred)
#求梯度
grads =t.gradient(loss_step,model.trainable_variables)
#反向传播
optimizer.apply_gradients(zip(grads,model.trainable_variables))
#求损失平均值与正确率平均值
train_loss(loss_step)
train_acc(labels,pred)
#每一步测试
def test_step(model,images,labels):
pred=model(images)
loss_step=loss_fn(labels,pred)
test_loss(loss_step)
test_acc(labels,pred)
#训练
def train():
for epoch in range(5):
for(images,labels) in train_dataset:
train_step(model,images,labels)
for(images,labels) in test_dataset:
test_step(model,images,labels)
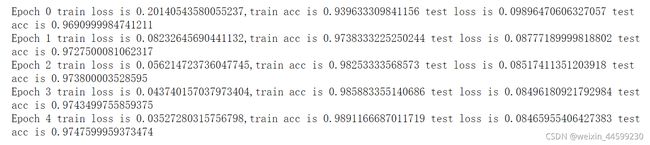
print("Epoch {} train loss is {},train acc is {} test loss is {} test acc is {}".format(epoch,train_loss.result(),train_acc.result(),
test_loss.result(),test_acc.result()))
train_loss.reset_states()
train_acc.reset_states()
train()
总结
本文主要介绍了tensorflow的自定义训练,举了几个关于tf.GradientTape,tf.keras.metrics模块的示例,最后附上实战代码,希望能够帮助到大家