SPARQL查询语言概念及语法
前言
看这篇文章之前,如果对RDF了解不够可以先看我的这篇文章,对RDF及其序列化方法进行了详细介绍。本篇文章是对瞿裕忠老师的《语义网技术体系》部分章节的学习笔记。
RDF是W3C推荐的数据存储方式,现实世界中的数据量是巨大的,将RDF图序列化后,对这些RDF文档的存储是一个问题,同时,如果要从这些文档中找到自己想要的信息,就需要一个便于使用的查询语言,那就是SPARQL。
对于RDF数据库和SPARQL的理解可以参照传统关系型数据库。例如:小明是五年级二班的学生,今年8岁。这样一个信息,
用传统关系数据库表示为:
| 姓名 | 年级 | 班级 | 年龄 |
|---|---|---|---|
| 小明 | 五年级 | 二班 | 8 |
用RDF序列化之后为:

可见,对于同样的信息,传统关系型数据库采用图表的方式存储,RDF文档使用RDF图的形式存储;进一步的,传统关系型数据库采用SQL查询数据库中的数据,而对于RDF文档构成的数据库,使用SPARQL查询语言。值得一提的是,SPARQL本身并不只是一个查询语言,它是定义在RDF数据库或者Web上查询和操纵RDF数据的一组语言和协议,而SPARQL查询语言是其中的核心。
文章目录
- 1. SPARQL的基本图模式
-
- 1.1 三元组模式
- 1.2 基本图模式示例
- 2. SPARQL查询语言常用语法
-
- 2.1 SPARQL常用关键字
-
- 1) 基本图模式
- 2) 图模式的组合
- 3) 属性路径
- 4) 结果的组织
- 5) 数据集的选取
- 6) 其他查询形式
- 2.2 SPARQL代码示例
-
-
- 例1. 最简单的查询
- 例2. FILTER过滤器
- 例3. NOT EXISTS
- 例4. 图模式合并
- 例5. OPTIONAL
- 例6. UNION
- 例7. 符号 ‘\’
- 例8. 符号 ‘|’
- 例9. 符号 ‘^’
- 例10. ORDER BY & ASC & DESC
- 例11. DISTINCT
- 例12. LIMIT & OFFSET
- 例13. FROM & FROM NAMED & GRAPH
- 例14. ASK & CONSTRUCT & DESCRIBE
-
- 3. 在Python中使用SPARQL语言
-
- 3.1 rdflib 简要介绍
- 3.2 创建RDF文档
- 3.3 SPARQL查询RDF文档
- 3.4 g.bind()使用举例
1. SPARQL的基本图模式
SPARQL查询基于的是图模式的匹配。图模式是SPARQL中的核心概念,基本图模式是SPARQL最简单的图模式。
1.1 三元组模式
一个基本图模式就是一个三元组模式的集合,这对应到RDF中即是,一个RDF图是一个RDF三元组的集合。显然,二者在形式上非常类似,三元组模式也是由主语、谓语和宾语组成,唯一的不同是,三元组模式中的主语和宾语还可以是变量。在SPARQL中,变量以问号(?)或者($)美元符号开头,例如:?x, ?name。
在一个基本图模式中,三元组模式通常通过共有变量连接起来,也就是说,基本图模式表示成的有向图一般是连通的。
1.2 基本图模式示例
以下将分别用图示和代码说明基本图模式。
图示

图中 ?x 和 ?y 是两个变量,通过图(b)查询的图模式在图(a)所示的待查数据中匹配,得到了变量 ?x 和 ?y 的值。
代码
SELECT ?name ?mbox
WHERE
{?x foaf:name ?name.
?x foaf:mbox ?mbox}
如代码中所示,花括号及其之间的部分是由2个三元组模式组成的基本图模式(为了简化,所有URI的前缀定义都被省略)
2. SPARQL查询语言常用语法
学习语法,千言万语不如一个代码示例来的清晰,下面我首先列出SPARQL常用的关键字及其介绍,然后分类给出代码示例。
2.1 SPARQL常用关键字
1) 基本图模式
| 关键字 | 介绍 |
|---|---|
| SELECT | 指出需要在结果中提供其绑定的变量 |
| WHERE | 指出需要去匹配的图模式 |
| FILTER | 引导一个过滤器,实质上是一个布尔函数,当返回值为真时,相应结果才会被返回 |
2) 图模式的组合
| 关键字 | 介绍 |
|---|---|
| OPTIONAL | 意味着并不强制要求这个图模式必须被匹配,当这个图模式不能匹配时,并不会因此去除整条结果 |
| UNION | 其连接的图模式并不要求被同时匹配,只要其中一个被匹配便可返回结果 |
| NOT EXISTS | 与FILTER连用,当不存在指定的图模式时返回true |
3) 属性路径
| 关键字 | 介绍 |
|---|---|
| / | 分隔路径属性,用于当只有路径的首尾顶点显示在查询中时 |
| | | 连接可以互相替代的两个属性 |
| ^ | 用来表示路径中的一个反向的属性 |
| ! | 表示否定 |
| ?、+、* | 属性路径 |
4) 结果的组织
| 关键字 | 介绍 |
|---|---|
| ORDER BY | 对查询结果按照指定的变量进行排序 |
| ASC | 升序排序 |
| DESC | 降序排序 |
| DISTINCT | 消除重复的查询结果 |
| LIMIT | 限制返回的结果条数 |
| OFFSET | 跳过固定条数的结果 |
| GROUP BY | 对查询结果分组 |
| HAVING | 分组过滤 |
| COUNT | 计数 |
| SUM | 求和 |
| AVG | 求平均 |
5) 数据集的选取
| 关键字 | 介绍 |
|---|---|
| FROM | 重新指定缺省图 |
| FROM NAMED | 指定具名图 |
| GRAPH | 使用具名图 |
6) 其他查询形式
| 关键字 | 介绍 |
|---|---|
| ASK | 不关心变量绑定的结果,而是关心一个查询图模式是否至少能找到一种匹配,找的到则返回True |
| CONSTRUCT | 基于查询的结果构造一个新的RDF图 |
| DESCRIBE | 获取关于一个特定URI标识的资源的所有RDF数据 |
2.2 SPARQL代码示例
例1. 最简单的查询

基本图模式查询可以视作三元组模式查询的合取查询。
例2. FILTER过滤器

如果要求某个变量必须绑定到字符串类型的字面量,并且与指定的正则表达式相匹配,可以使用regex。这里的regex(?title, “^电子商务”)是用来判断变量 ?title 是否绑定到一个字符串类型的字面量,并且该字面量的词汇形式以“电子商务”作为前缀。
例3. NOT EXISTS

将一个图模式是否能够找到匹配来作为另一个图模式中的过滤器。
例4. 图模式合并
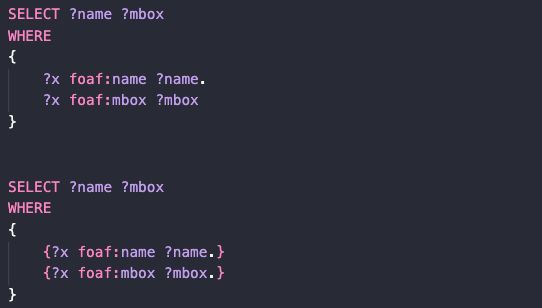
以上两段代码的结果是完全相同的,简单的给出多个图模式意味着他们的合取,即相当于将这些图模式合并。
例5. OPTIONAL

如果OPRIONAL关键字后的模式没有得到匹配,仍然不会因此去除整条结果。
例6. UNION

只要UNION连接的两个模式中有一个得到了匹配,则返回结果
例7. 符号 ‘\’

图中两段代码是等价的,当我只关心路径的起点和终点的时候,就可以直接这样写,忽略其中间节点,在这里就是 ?y。
例8. 符号 ‘|’
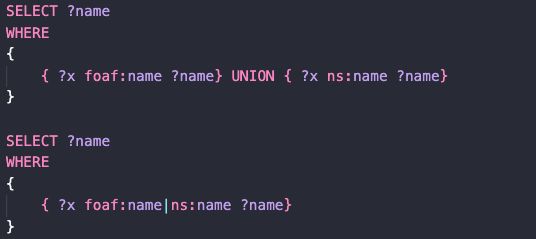
以上两段代码是等价的,可以看到 ‘|’ 也就类似于逻辑语言中的“或”。
例9. 符号 ‘^’

上面两段代码是等价的,‘^’ 表示一个反向的属性。
例10. ORDER BY & ASC & DESC

这段代码的结果将会依照 ?name 升序排列。
例11. DISTINCT

第一段代码的结果中可能会有重复的结果,第二段代码加入了DISTINCT关键字,其结果将各不相同,不会有重复。
例12. LIMIT & OFFSET
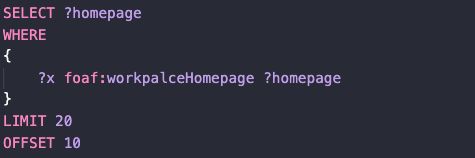
这段代码的结果将会直接跳过前10条结果,然后返回从第11条开始的不超过20条结果。
例13. FROM & FROM NAMED & GRAPH

查询总是在一个数据集上执行的,它由多个RDF图组成,包括一个缺省图和多个具名图。在不做任何指定的情况下,查询总是在缺省图上进行。对于一个具体的本地RDF数据库或者网络上的SPARQL端口而言,缺省图通常是预先设定好的,因此在查询中就不必再显示指定。缺省图的指定通过关键字FROM实现。以上的代码中,将缺省图重新指定。

当我们指定多个缺省图时,缺省图将是这多个图的合并。
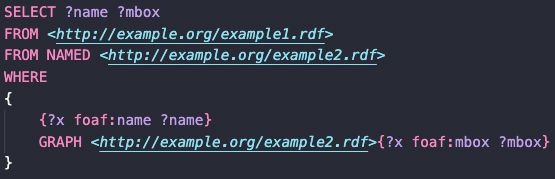
FROM NAMED关键字可以指定具名图,指定具名图的意义在于可以将一部分图模式放在缺省图以外的RDF图上去匹配,而对于具名图的使用要借助GRAPH关键字。在以上的代码中,第一个图模式会在缺省图中匹配,而第二个图模式会在GRAPH关键字指出的具名图中匹配。

有时候我们需要知道某个模式到底在哪个RDF图中可以得到匹配。如以上代码所示,GRAPH后的图模式将会在声明出的所有具名图中一一匹配,如果再某个具名图中模式得到了匹配,则这个具名图的URI将会被绑定到变量 ?g 上。通过这样一种方式,查询者不但不需要知道具体应该在哪个具名图中查询,而且还可以得知可以在哪个具名图中查到结果。
例14. ASK & CONSTRUCT & DESCRIBE
![]()
如果图模式得到匹配,ASK将会返回True,否则返回False。
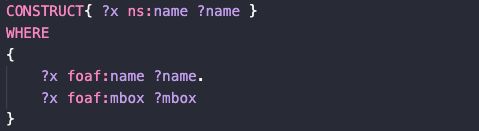
如代码所示,CONSTRUCT和WHERE各引导了一个图模式,这两个图模式共享变量,其中,CONSTRUCT引导的图模式也叫做图模板,输出的结果将会依照这个图模板,然后使用从WHERE引导的图模式匹配的变量,进而生成新的RDF图。
![]()
这条查询将返回描述 http://ws.nju.edu.cn/people/gcheng 这个URI表示的资源的全部RDF数据。

这条查询出了返回 http://ws.nju.edu.cn/people/gcheng 标识资源的 RDF 数据之外,还将匹配关键字 WHERE 引出的图模式,并对于绑定到变量 ?x 和 ?y 的每个资源(其标识可以是URI,也可以是空白节点),也会获取其RDF数据,最终将所有这些 RDF 数据合并返回。
3. 在Python中使用SPARQL语言
学习任何一门语言切忌纸上谈兵,学到了就要使用,对于SPARQL语言的使用以及RDF文档的创建,大多使用程序实现,我们基本不会去手动写RDF文档,同时我们的SPARQL查询语句也常常嵌套在工程代码之中。在这里我介绍如何利用Python实现RDF文件的创建及查询,这里的文件可能在本地也可能在远端。
在Python中实现SPARQL语言操作需要借助Python库rdflib,这里结合例子讲一些常用用法。
3.1 rdflib 简要介绍
from rdflib import Graph, Literal, RDF, OWL, RDFS, URIRef, Namespace
from rdflib.namespace import FOAF , XSD
以上列出的就是常用的rdflib功能,其中Graph是最重要的一类,以下通过表格简单介绍,然后结合后面例子中的注释就可以知道详细用法。
| 名称 | 功能 |
|---|---|
| Literal | 创建字面量 |
| URIRef | 创建URI资源链接 |
| Namespace | 声明命名空间并取别名 |
| OWL, RDF, RDFS, FOAF, XSD | 命名空间 |
| Graph函数 | 功能 |
|---|---|
| g=Graph() | 声明一个对象 |
| g.add() | 向RDF图中添加三元组 |
| g.parse() | 解析RDF文件,有属性format可以指定文件格式 |
| g.remove() | 移除三元组 |
| g.bind() | 绑定命名空间到一个更易读的字符串,如FOAF到"foaf",在输出中生效,使输出更加易读 |
| g.serialize() | 将RDF图序列化并存储,有属性format指定存储的RDF文档格式 |
| g.triples | 模糊匹配,参数是一个三元组,通过对三元组中的某一个或两个赋值为None,从而实现模糊匹配 |
3.2 创建RDF文档
from rdflib import Graph, FOAF, Namespace, URIRef, Literal
#创建RDF图对象
g = Graph()
#声明命名空间
authors = Namespace("http://www.book.org/authors#")
#添加节点
a = URIRef(authors["a"])
b = URIRef(authors["b"])
c = URIRef(authors["c"])
#添加三元组
g.add((a,FOAF.name,Literal("Yuzhong Qu")))
g.add((a,FOAF.mbox,Literal("" )))
g.add((b,FOAF.name,Literal("Wei Hu")))
g.add((b,FOAF.mbox,Literal("" )))
g.add((c,FOAF.mbox,Literal("" )))
#序列化生成的RDF图并存储,第一个参数是存储地址,根据自己实际情况改写
#这里的serialize如果不加地址直接放在print函数里输出,会输出整个序列化后的RDF文档
g.serialize("./SPARQL/data/rdf1.ttl",format="turtle")
print("Already Stored!")
生成的RDF文档如下:

3.3 SPARQL查询RDF文档
from unittest import result
from rdflib import Namespace, FOAF, URIRef, Literal, Graph
import numpy as np
#创建RDF图对象
g = Graph()
#加载待查询的RDF文档
g.parse("./SPARQL/data/rdf1.ttl",format="turtle")
#格式一:在一行显示查询语句,不可跨行
# q = "SELECT ?name ?mbox WHERE { ?x foaf:name ?name. ?x foaf:mbox ?mbox}"
#格式二:多行显示查询语句,格式清晰
q = """
SELECT ?name ?mbox
WHERE
{ ?x foaf:name ?name.
?x foaf:mbox ?mbox}
"""
#查询
result = g.query(q)
#获取查询结果的方式一
# result_np = np.asarray(list(result))
# for v in result_np:
# print(v)
#获取查询结果的方式二
for row in result:
print(f"{row.name} have {row.mbox}")
查询之后以方式一输出结果如下:
![]()
查询之后以方式二输出结果如下:
![]()
query函数的返回值是什么?
从官方文档看到,query函数的返回值根据查询类型的不同有三种情况:
select: 返回查询结果的行组成的一个对象
ask:返回一个bool值
construct和describe:根据情况返回三元组构成的图
我们这里主要讨论常用的select,对于query的返回值在官方文档里已经说的很清楚了,我们关注的是对返回值的利用,方式有两种,对应代码中的方式一和方式二:
a) 先将结果转化为Python的list,然后将list转化为numpy的数组,然后进行操作。在讲结果转化为list之后,就可以想象此时的结果是一个二维数组。
b) 通过我们在查询时使用的变量名,对于返回的每一行结果可以直接查询相应的匹配。
3.4 g.bind()使用举例
- 不使用g.bind()
from rdflib import Graph, FOAF, Namespace, URIRef, Literal
#创建RDF图对象
g = Graph()
#声明命名空间
authors = Namespace("http://www.book.org/authors#")
ns = Namespace("http://www.ns.org/authors#")
#g.bind("foaf",FOAF)
#g.bind("ns",ns)
#添加节点
a = URIRef(authors["a"])
b = URIRef(authors["b"])
#添加三元组
g.add((a,FOAF.name,Literal("Yuzhong Qu")))
g.add((b,ns.name,Literal("Wei Hu")))
#序列化生成的RDF图并存储
g.serialize("./data/rdf3.ttl",format="turtle")
print("Already Stored!")
生成的RDF文档如下:

- 使用g.bind()
from rdflib import Graph, FOAF, Namespace, URIRef, Literal
#创建RDF图对象
g = Graph()
#声明命名空间
authors = Namespace("http://www.book.org/authors#")
ns = Namespace("http://www.ns.org/authors#")
g.bind("foaf",FOAF)
g.bind("ns",ns)
#添加节点
a = URIRef(authors["a"])
b = URIRef(authors["b"])
#添加三元组
g.add((a,FOAF.name,Literal("Yuzhong Qu")))
g.add((b,ns.name,Literal("Wei Hu")))
#序列化生成的RDF图并存储
g.serialize("./data/rdf3.ttl",format="turtle")
print("Already Stored!")
生成的RDF文档如下:

显然,当使用g.bind()时,生成的RDF文档的可读性会高很多。