【论文笔记】多智能体强化学习值分解基础论文5篇
文章目录
-
- 引子
- IQL
- COMA
- VDN
- QMIX
- QTRAN
- 总结
引子
值分解可以说是解决多智能体强化学习的重要手段之一,本文主要涉及IQL、COMA、VDN、QMIX、QTRAN这五篇最经典的论文。
本文大致介绍每种方法最核心的思想,具体细节请读原文。
IQL
Multiagent Cooperation and Competition with Deep Reinforcement Learning, 2015
本文主要是基于Pong这个游戏环境,通过修改agent的收益,说明合作型agent独立地进行各自的Q-learning,依然可以有不错的效果。
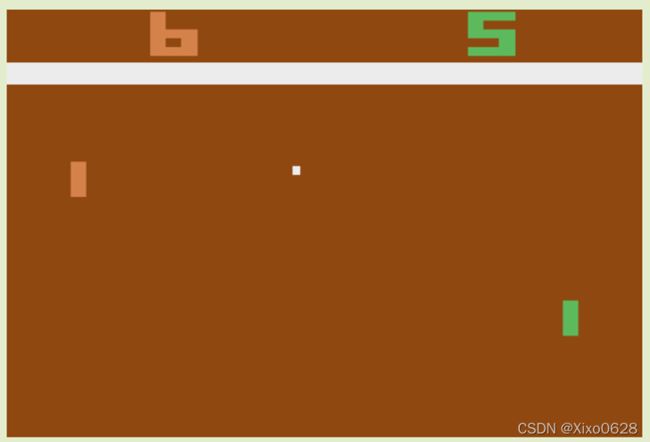

最上面的收益矩阵是原本游戏的收益矩阵,每当错过球时,对方得分自己扣分,是完全竞争型的博弈。当每次失球时,如果双方都获得-1,就是矩阵2,这时是一个完全合作的博弈,双方都希望小球尽可能保持一直被接到。
介于两种情况之间的就是矩阵3,对应的就是 ρ∈(-1,1),这是混合型的博弈。
IQL发现,在不修改除了reward外的任何参数、细节,agent都能取得不错的成绩。这说明IQL可以作为多智能体强化学习的baseline。
COMA
Counterfactual Multi-Agent Policy Gradients, 2017
使用一个集中式critic网络,在训练的过程中可以获取所有智能体的信息;
采用反事实基线(counterfactual baseline)来解决信用分配的问题;
Critic网络要能够对反事实基线进行高效的计算。

红色部分是只有在训练时才会被用到的,因为实际执行时,每个agent都是拿不到全局信息的。这也是CTDE(中心化训练、去中心化执行)方法的早期成果。
VDN
Value-Decomposition Networks For Cooperative Multi-Agent Learning,2017
VDN算是大名鼎鼎的QMIX算法的前身。

VDN算法强调的是把总的Q相信分解为多个Q之和,每个Q对应每个智能体的动作价值,也就是:
这种会导致一个结果,那就是这样累计求和的Q可能没有具体的意义、吃大锅饭导致有agent划水之类的结果。这些问题在QMIX中得到了比较好的解决。
QMIX
QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning, ICML2018

由于 VDN没有尽可能利用集中式训练的优势, 忽略了学习期间可用的任何额外状态信息,因此 QMIX 在近似(, )时额外使用了全局状态, 这样就可以基于全局状态进行训练,而不是像 VDN 那样仅仅拿1, … , 去训练。 QMIX 的 Loss 函数和 VDN 一样, 还是使用 DQN 那一套的 TD-error 来训练。
在中间网络中,每个agent都用GRU结合历史数据输出个人的动作价值,将每个Q值输入Mixing Network,得到Qtot。其中Mixing Network 的参数由St结合单层超网络得到。
这里放一下QMIX 最经典的约束条件:


也就是总Q关于每个agent的偏导都必须是正的。也就是,对于每个agent来说,追求自身收益的最大化是没有错误的(都对全局有不小于0的贡献)。
QTRAN
QTRAN: Learning to Factorize with Transformation for Cooperative Multi-Agent Reinforcement learning, ICML2019
QTRAN是相对复杂一点的论文,它在QMIX的理论上做了改进,但因为实际情况中的各种约束,导致最终实际效果不好。我们来看一下。
前面还说到 QMIX 在近似(, )时额外使用了全局状态,这样就可以
基于全局状态进行训练。但是如果直接将和[1, … , ]一起输入到神经网络
去得到, 由于我们前面限制了中的参数是非负的, 但这会对和的关系进行不必要的限制,因为我们只希望局部最优动作就是全局最优动作。QTRAN 聚焦于释放累加性和单调性的限制, 去分解所有可分解的任务。 其的思想在于只要保证个体最优动作̅和联合最优动作∗是相同的。
QTRAN 认为既然 VDN 和 QMIX 是通过累加或者单调近似得到的, 那
么就很有可能与真实的 ∗ 相差很远, 那我不如直接去学习一个真实的
∗ 。

这里的Qjt就是学习得到的,介于各个agent的收益Q之和和实际局面价值之间的联合补偿。这样就建立了局部Q和全局Q之间的联系。
这样就可以用建立的联系进行Loss计算:

总结
本段参考网易那篇关于值分解工作的总结:
VDN 与 QMIX 之所以通过累加和或者神经网络去近似(, ), 不是因为(, )不好得到, 而是因为(, )即使得到了, 由于 Decentralized Execution 中的部分可观察的限制, (, )无法被使用。
因此 VDN 与 QMIX 另辟蹊径, 通过去近似,然后在更新时利用神经网络的反向传递来更新。 而 QTRAN 呢则是直接学习一个, 同时创造了两个条件来约束和之间的关系, 从而通过该关系去更新。
都看到这里了,就请点个赞吧~