带你读论文系列之计算机视觉--GoogLeNet V3
带你读论文系列之计算机视觉–GoogLeNet V3

化作天边的一朵云在窗外悄悄看着你。
闲谈
广东的天气异常热,重庆今日温度28度左右,而广东37度左右。九月的天,让我又进入的夏天。近期会频繁更新,原因是我假期太懒了,都是之前累积的论文,现在开始整理了。同时,我把相关文档整理一下,放在我的GitHub上,欢迎加星, 欢迎提问,欢迎指正错误, 同时也期待能够共同参与。
前言
重新思考计算机视觉中的Inception结构。
回顾
- GoogLeNet-V1主要采用了多尺度卷积核、1x1卷积操作、辅助损失函数;
- GoogLeNet-V2在V1的基础上加了BN层,使用小卷积核堆叠替换大卷积核;
GoogLeNet –V1 采用多尺度卷积核,1✖️1卷积操作,辅助损失函数,实现更深的22层卷积神经网络,夺得ILSVRC-2014 分类和检测冠军,定位亚军。
GoogLeNet-V2 基础上加入BN层,并将5*5卷积全面替换为2个3✖️3卷积堆叠的形式,进一步提高模型性能。
VGG网络模型大,参数多,计算量大,不适用于真实场景。
GoogLeNet比VGG 计算量小;GoogLeNet可用于有限资源下的场景。
论文:
Rethinking the Inception Architecture for Computer Vision
研究意义:
- 总结模型设计准则,为卷积神经网络模型设计提供参考;
- 提出3个技巧,结合Inception,奠定Inception系列最常用模型——Inception-V3;
论文详情
本文优点:
1.提出低分辨率分类的方法;
2.提出卷积分解提高效率
3.BN-auxiliary
4.LSR
GoogLeNet的Inception 架构也被设计为即使在内存和计算预算的严格限制下也能表现良好。例如,GoogLeNet仅使用了500 万个参数,相对于其前身AlexNet使用了6000万个参数,这意味着减少了12 倍。此外,VGGNet使用的参数比AlexNet多3倍。
摘要:
- 背景:自2014年以来,深度卷积神经网络成为主流,在多个任务中获得优异成绩;
- 问题:目前精度高的卷积神经网络,参数多,计算量大,存在落地困难问题;
- 解决:本文提出分解卷积及正则化策略,提升深度卷积神经网络速度和精度;
- 成果:单模型+single crop,top-5,5.6%; 模型融合+multi-crop,top-5,3.5%。
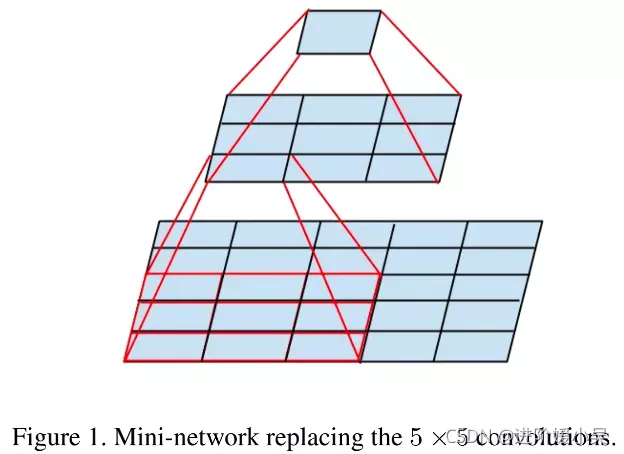
大卷集合分解成小卷积核堆叠。取代5×5卷积的小型网络。
解耦:
- 加快训练;
- 参数少了,可以用更多的卷积核;
分解成更小的卷积:
- 小卷积核,计算量小;
- 大卷积核,感受野大,可捕获更多信息;
- 小卷积核,会降低表达能力;
具有较大空间滤波器(例如5×5或7×7)的卷积在计算上往往不成比例地昂贵。例如,在一个有过滤器的网格上用5×5个过滤器进行卷积,比用同样数量的过滤器进行3×3卷积的计算成本高25/9=2.78 倍。当然,5×5的滤波器可以捕捉到前几层中更远的单元的激活信号之间的依赖关系,所以减少滤波器的几何尺寸是以很大的扩展性为代价的。


如果我们放大5✖️5卷积的计算图,我们会看到每个输出看起来像一个小的全连接网络,在其输入上滑动5✖️5块(如上figure 1)。由于我们正在构建视觉网络,因此利用平移不变性似乎很自然再次将全连接组件替换为两层卷积架构:第一层是3×3卷积,第二层是第一层3✖️3 输出网格顶部的全连接层(如上figure 1)。在输入激活网格上滑动这个小网络归结为用两层3✖️3卷积替换5✖️5 卷积(如上figure 4 和 figure 5)。
- 3✖️3是否还能分解?可用2✖️2?其实用3✖️1和1✖️3 分解更好;
- asymmetric 和2✖️2带来的参数减少分别为33%和11%。
通过使用不对称卷积,例如n✖️1,我们可以做得比2×2更好。例如,使用3✖️1卷积,然后再使用1✖️3卷积,就相当于用3✖️3 卷积的相同感受场滑动一个两层网络(见图3)。如果输入和输出滤波器的数量相等,在输出滤波器数量相同的情况下,两层的解决方案仍然便宜33%。相比之下,将3✖️3卷积分解为2✖️2 卷积只节省了11%的计算量。
- 一开始不要分解,效果不好!
- 特征图在12到20之间是比较好的!3.最好的参数是1✖️7,7✖️1;
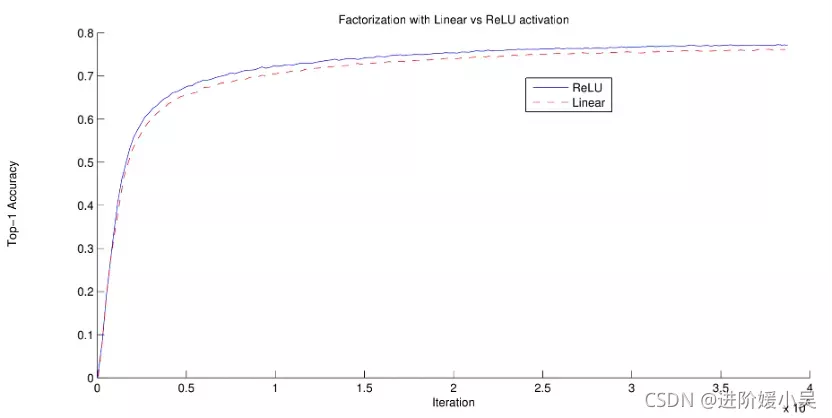
两个Inception模型之间的实验,其中一个使用分解为线性+ReLU layers,另一个使用两个ReLU层。经过386万次操作,前者稳定在76.2%,而后者在验证集上达到77.2%t op-1准确率。

取代3✖️3演算的小型网络。该网络的底层由3个输出单元的3✖️1卷积组成。
辅助分类器的效用
- 辅助分类层在早期起不到加速收敛作用;
- 收敛前,有无辅助分类,训练速度一样;
- 快收敛,有辅助分类的超过没有辅助分类的。
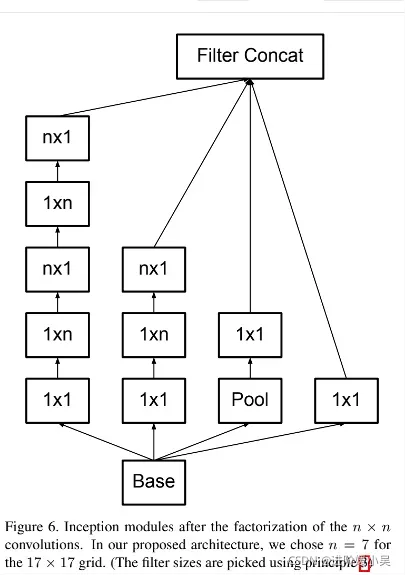

该架构用于最粗糙的(8✖️8)网格以促进高维表示。我们仅在最粗糙的网格上使用此解决方案,因为这是产生高维稀疏表示是最关键的地方,因为与空间聚合相比,局部处理(1✖️1卷积)的比率增加了。
V1中提到的辅助分类层有助于低层特征提取的假设是不正确的。
本文认为辅助分类起到正则的作用。如果辅助分支是批量归一化的或具有dropout层,则网络的主分类器性能更好。这也为批量归一化充当正则化器的猜想提供了微弱的支持证据。
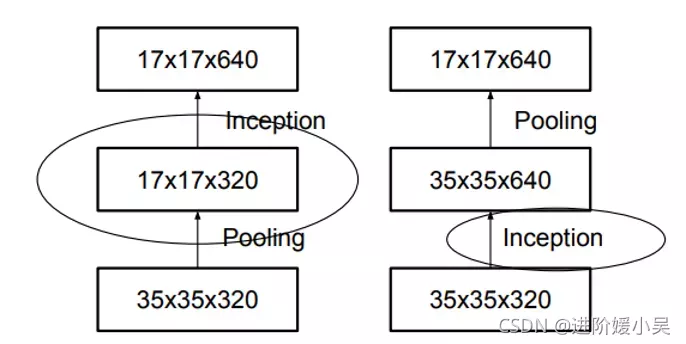
左图表示传统的池化方法,会损失特征图的信息,右图表示先将特征图增大再进行池化的过程,存在问题是计算亮过大;
解决办法:用卷积得到一半的特征图,池化得到一半的特征图,再进行拼接。
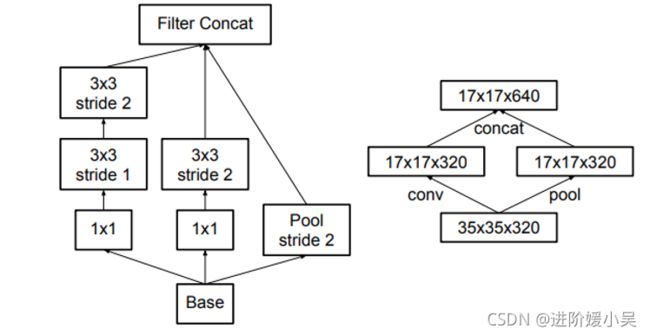
注意:该Inception-module用于35x35下降到17x17和17x17下降到8x8;
Inception模块,在扩展滤波器组的同时减小网格大小。它既便宜又避免瓶颈。右图表示相同的解决方案,但从网格大小而不是操作的角度来看。
实验

感受野大小不同但计算成本不变时的识别性能对比。
- 299×299感受野,第一层后的stride2和maximum pooling;
- 第一层后具有stride1和最大池化的151×151感受野;
- 79×79的感受野,第一层后有跨度1和无pooling。
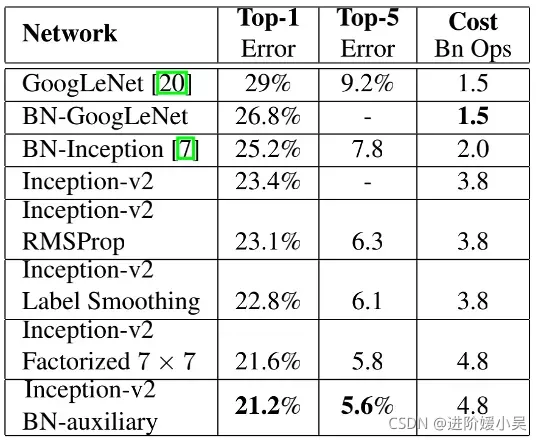
从v2开始,基于上个模型添加新trick ,最后一个模型称为inception-v3。

single-model、multi-crop实验结果比较对各种影响因素的累积影响。将我们的数字与ILSVRC2012分类基准上发布的最佳单模型推理结果进行比较。
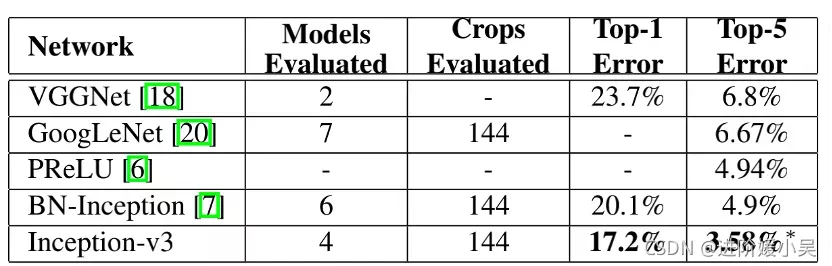
比较multi-model、multi-crop报告结果的集成评估结果。我们的数字与ILSVRC 2012分类基准上发布的最佳集成推理结果进行了比较。*所有结果,但报告的前5个集成结果都在验证集上。集成在验证集上产生了3.46%的top-5错误。
论文总结
Inception-V3的主要改进点:
- 采用RMSProp优化方法;
- 采用标签平滑正则化方法;
- 采用非对称卷积提取17x17特征图;
- 采用BN的辅助分类层;
关键点:
- 非对称卷积分解:减少参数计算,为卷积结构设计提供新思路;
- 高效特征图下降策略:利用stride=2的卷积与池化,避免信息表征瓶颈;
- 标签平滑:避免网络过度自信,减轻过拟合;
启发点:
- CNN的分类是CNN视觉任务的基础:在分类上表现好的CNN,通常在其他视觉任务中表现也好;
- GoogLe的很多论文的最优解均是通过大量实验得出,一般玩家难以复现;
- 非对称卷积分解在分辨率为12-20的特征图上效果好,且用1x7和7x1进行特征提取;
- 在网络训练初期,辅助分类层的加入并没有加快网络收敛,在训练后期,才加快网络的收敛;
- 移除两个辅助分类层的第一个,并不影响网络性能;
- 标签平滑参数设置,让非标签的概率保持在10-4左右。
