机器学习:决策树与随机森林
决策树与随机森林
- 决策树
-
- 基本原理
- 优缺点
-
- 优点
- 缺点
- 使用决策树对鸢尾花分类
- 随机森林
-
- 基本原理
- 优缺点
-
- 优点
- 缺点
- 葡萄酒数据集的随机森林分类
决策树
基本原理
决策树算法是一种基于实例的算法,常用于分类与预测。决策树的构建是一种自上而下的归纳过程,用样本的属性作为节点,属性的取值作为分支的树形结构。因此,每棵决策树对应着从根节点到叶节点的一组规则。
基本思想:

决策树利用书的结构将数据二分类。包括三种节点:叶子节点、中间节点、根节点
决策树的问题主要集中在剪枝和训练样本的处理方面。决策森林在提高分类精度的同时解决了决策树面临的问题。决策森林由几种决策树的预测组合成一个最终的预测,其原理为应用集成思想提高决策树的准确率。通过构建森林,一棵决策树的错误可以由森林中的其他决策树弥补。
优缺点
优点
1、简单直观
2、基本上不需要预处理,不需要提前归一化、处理缺失值
3、决策树的代价是O(log2m)。m样本数
4、既可以处理离散值也可以处理连续值
5、能够处理多维度输出问题
6、相比于神经网络类的黑盒分类模型,决策树在逻辑上可以得到很好的解释
7、可以交叉验证的剪枝来选择模型,从而提高泛化能力
8、对于异常点的容错能力好,健壮性高
缺点
1、决策树算法非常容易过拟合,导致泛化能力不强。可以通过设置节点最少样本数量和限制决策树深度来改进。
2、决策树会因为样本发生一点点改动, 就会导致树结构的剧烈改变。这个可以通过集成学习之类的方法解决。
3、寻找最优的决策树是一个NP难问题,一般是通过启发式方法,容易陷入局部最优。可以通过集成学习之类的方法来改善。
4、有些比较复杂的关系,决策树很难学习,比如异或。一般这种关系可以换神经网络分类方法来解决。
5、如果某些特征的样本比例过大,生成决策树容易偏向于这些特征。这个可以通过调节样本权重来改善。
使用决策树对鸢尾花分类
先介绍一下数据Iris

import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris #导入类
from sklearn.tree import DecisionTreeClassifier
iris = load_iris() #获取数据集
iris_feature = iris.data #特征数据
iris_target = iris.target #分类数据
df = pd.DataFrame(iris_feature)
#一次便生成,再次生成报错,所以文件夹下已经生成数据集,后续不再运行
#df.to_csv('./iris.csv',header=False,index = False)
names = ['sepal length','sepal width','petal length','petal width']
dataset = pd.read_csv('./iris.csv',names = names)
print(dataset.describe())
#dataset.hist() #输出两两特征对比直方图
#决策树的拟合
clf = DecisionTreeClassifier()
clf.fit(iris.data,iris.target) # X y
#print(clf)
#预测
predicted = clf.predict(iris.data)
print(predicted)
X = iris.data
L1 = list(X[:,0]) #[x[0] for x in X]
L2 = list(X[:,1])
#只选取前两列数据,绘制模型预测结果
plt.scatter(L1,L2,c = predicted,marker = 'x')
plt.title('DTC')
plt.show()


随机森林
基本原理
随机森林分类(RFC)是由很多决策树分类模型组成的组合分类模型,且参数集是独立同分布的随机向量,在给定自变量X下,每个决策树分类模型都由一票投票权来选择最优的分类结果。RFC的基本思想是:首先,利用bootstrap抽样从原始训练集中抽取k个样本,且每个样本的样本容量都与原始训练集样; 其次,对k个样本分别建立k个决策树模型,得到k种分类结果:
最后,根据k种分类结果对每个记录进行投票决定其最终分类。

RF通过构造不同的训练集增加分类模型间的差异,从而提高组合分类模型的外推预测能力。通过k轮训练,得到一个分类模型序列,再用她们构成一个多分类模型系统,该系统的最终分类结果采用简单多数投票法。最终的分类决策为:
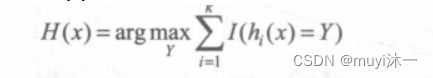
其中,H(x)表示组合分类模型,hi是单个决策树分类模型,Y表示目标变量,I()为示性函数。上式说明了使用多数投票决策的方式来确定最终的分类。
随机森林算法原理 = 决策树 + bagging原理 + 随机
随机森林和决策树一样既可以做分类又可以做回归(更多用来做分类问题) 随机森林是使用集成学习的思想将多颗决策树集成一种学习器的算法,中间利用到bagging的投票思想,少数服从多数进行集成学习 随机森林的随机思想体现在两方面:第一是在随机的抽取样本,假如有N个样本记录,那么对于每一颗决策树(随机森林的子树数量是由使用者自己决定的,子树数量越高效果越好,一般我们选择在处理器可以承受的情况下选择较大的子树)都进行有放回的取出N个样本。(这里面的值肯定会有重叠,但是没关系) 第二是随机的选取每颗子树所能选取的最大的特征数,一般我们选择的特征数要小于总特征数
优缺点
优点
1、在数据集上表现良好,两个随机性的引入,使得随机森林不容易陷入过拟合
2、在当前的很多数据集上,相对其他算法有着很大的优势,两个随机性的引入,使得随机森林具有很好的抗噪声能力
3、它能够处理很高维度的数据,并且不用做特征选择,对数据集的适应能力强:既能处理离散型数据,也能处理连续型数据,数据集无须规范化
4、可生成一个Proximities= (pij) 矩阵,用于度量样本之间的相似性: pij=aij/N, aij表示样本i和j出现在随机森林中同一个叶子节点的次数,N表示随机森林中树的颗数
5、在创建随机森林的时候,对generlization error使用的是无偏估计
6、训练速度快,可以得到变量重要性排序(两种:基于OOB误分率的增加量和基于分裂时的GINI下降量)
7、在训练过程中,能够检测到feature间的互相影响
8、容易做成并行化方法
9、实现比较简单
缺点
1、随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟
2、对于有不同取值属性的数据,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的
葡萄酒数据集的随机森林分类
在http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv 获取数据集
数据说明:
fixed acidity:非挥发性酸含量
volatile acidity:挥发性酸含量
citric acid:柠檬酸含量
residual sugar:参与糖分含量
chlorides:氯化钠含量
free sulfur dioxide:游离二氧化硫含量
total sulfur dioxide:总二氧化硫含量
density:密度
pH:酸碱度
sulphates:硫酸钾含量
alcohol:酒精浓度
quality:品质,3,4,5,6,7,8
import numpy as np
import pandas as pd
import urllib.request
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import pylab as plot
'''
这里没有使用书中的url获取数据的形式,而是直接下载的
'''
#先整理数据,分割保存
df = pd.read_csv('./winequality-red.csv',sep = ';')
#df.to_csv('./red.csv',index = False)
names = np.array(list(df.columns))
data = np.array(df)
xlist = data[:,0:-1]
labels = data[:,-1]
x = xlist
y = labels
#划分训练集测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=5)
#用来后续储存均方误差
mseoos = []
nt = []
#设定不同的决策树数量
ntreelist = range(50,500,10)
'''
建立随机森立模型
'''
for itrees in ntreelist:
depth = None
#设定要考虑的特征项的个数
maxfeat = 4
#n_estimators决策树的个数;max_depth树的最大深度;
#max_features寻找最佳分割时要考虑的特征数量
#oob_score是否使用袋外样本来估计泛化精度,默认False
rnf = RandomForestClassifier(n_estimators = itrees, max_depth = depth,
max_features = maxfeat, oob_score = False, random_state = 53)
rnf.fit(x_train,y_train)
pre_test = rnf.predict(x_test)
#计算预测值与实际值之间的均方误差
mseoos.append(mean_squared_error(y_test,pre_test))
nt.append(itrees)
#输出每次的均方误差
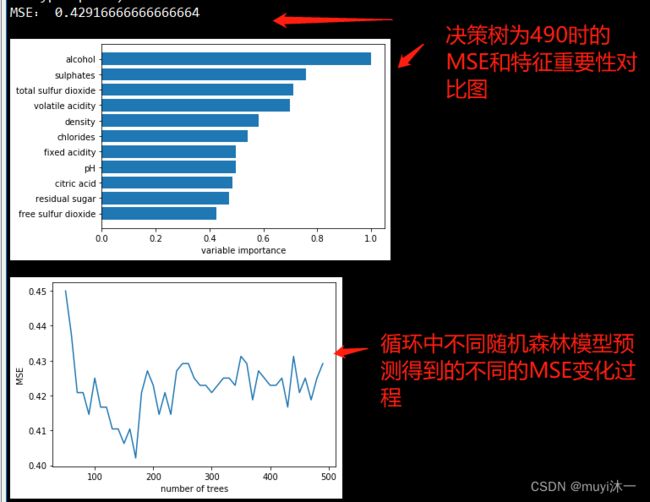
print("MSE:",mseoos[-1])
# print(mseoos[-1])
#用feature_importances_方法进行提取特征重要性,返回numpy数组
featureimportance =rnf.feature_importances_
#归一化
#进行归一化的目的是提升模型的收敛速度,提高模型的精度
featureimportance = featureimportance/featureimportance.max()
#argsort方法将归一化后的featureimportance从小到大排列返回索引
#返回array类型的索引
sorted_idx = np.argsort(featureimportance)
#arange(start,stop,step,dtype=None)
#根据start和stop指定的范围及step设定的步长,生成一个ndarry
barpos = np.arange(sorted_idx.shape[0]) + .5
#barh()表示绘制水平方向的条形图
plot.barh(barpos,featureimportance[sorted_idx],align = 'center')
#yticks设置或查询 y 轴刻度值
plot.yticks(barpos,names[sorted_idx])
plot.xlabel("variable importance")
plot.show()
#绘制均方误差的变化曲线
plot.plot(nt,mseoos)
plot.xlabel("number of trees")
plot.ylabel("MSE")
plot.show()