机器学习实验二 决策树
目录
一:决策树的定义
二:数学理论
信息熵:
信息增益:
增益率:
基尼指数:
三:决策树算法:
ID3算法:
四:可视化决策树:
首先先下载grhviapz:
下载pydot和sklearn:
注意下载sklearn之前要先安装numpy,scipy,matplotlib
1.数据集准备:
2.训练模型:
3.预测和绘制决策树:
4.输出决策树:
完整代码:
5.运行结果:
6.总结:
决策树算法优点
决策树算法缺点
一:决策树的定义
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。
举个例子:你的朋友邀请你去酒吧蹦迪,你觉得两个人去没意思,这时候你朋友说有个女的也一起同行。你就会问他这个女的漂亮吗?有钱吗?高的矮的?胖的瘦的?性格等等特征问题来决定你要不要去。这一系列的连续分析过程就和决策树很相似。
具体分析过程如下图所示:
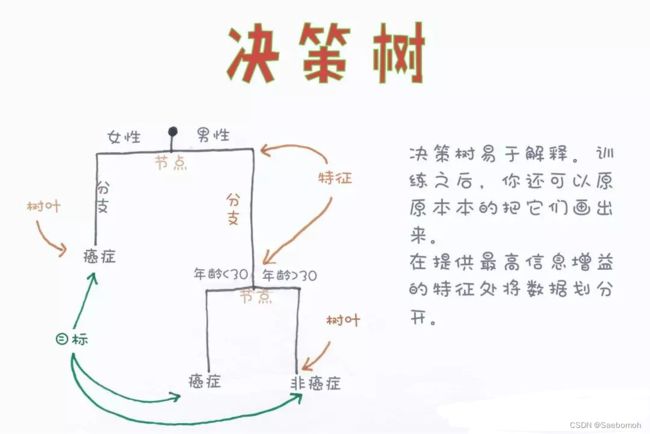
这时候我们就有一个问题了,到底是哪个条件优先考虑,哪个条件之后再考虑呢?还有怎么确定用特征中的哪个数值作为划分的标准。这就是决策树机器学习算法的关键了。
二:数学理论
分析这些之前我们需要学一些公式概念和定义:
信息熵:
定义:熵度量了事物的不确定性,越不确定的事物,它的熵就越大
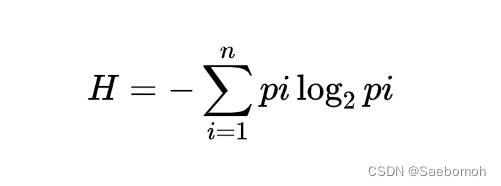
直观上说地理解,信息熵表示一个事件的确定性程度。信息熵度量样本的同一性,如果样本全部属于同一类,则信息熵为0;如果样本等分成不同的类别,则信息熵为1。
采用信息熵进行节点选择时,通过对该节点各个属性信息增益进行排序,选择具有最高信息增益的属性作为划分节点,过滤掉其他属性。
信息增益:

增益率:
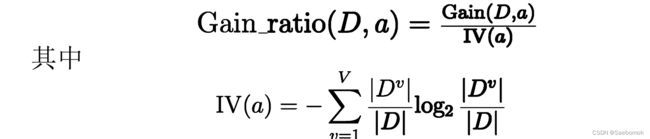
基尼指数:
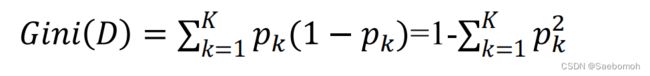
Gini(D)越小,数据集D的纯度越高;
三:决策树算法:
ID3算法:
ID3 算法是建立在奥卡姆剃刀(用较少的东西,同样可以做好事情)的基础上:越是小型的决策树越优于大的决策树。
思想从信息论的知识中我们知道:期望信息越小,信息熵越大,从而样本纯度越低。ID3 算法的核心思想就是以信息增益来度量特征选择,选择信息增益最大的特征进行分裂。算法采用自顶向下的贪婪搜索遍历可能的决策树空间(C4.5 也是贪婪搜索)。
其大致步骤为:
1 初始化特征集合和数据集合;
2 计算数据集合信息熵和所有特征的条件熵,选择信息增益最大的特征作为当前决策节点;
3 更新数据集合和特征集合(删除上一步使用的特征,并按照特征值来划分不同分支的数据集合);
4 重复 2,3 两步,若子集值包含单一特征,则为分支叶子节点。
划分标准ID3 使用的分类标准是信息增益,它表示得知特征 A 的信息而使得样本集合不确定性减少的程度。
四:可视化决策树:
我用的是pydot和graphviz包进行展示决策树,这包还能自动给你分类计算进行决策比较容易上手。
基于实验你要准备下载pydot,grhviapz,sklearn包
首先先下载grhviapz:
下载完成,点击安装,一直点NEXT就好了。然后去系统环境变量添加即可
![]()
最后导入anaconda,然后查看是否成功。
下载pydot和sklearn:
利用镜像资源:pip install -i https://pypi.tuna.tsinghua.edu.cn/pydot
pip install -i https://pypi.tuna.tsinghua.edu.cn/scikit-learn注意下载sklearn之前要先安装numpy,scipy,matplotlib
pip install -i https://pypi.tuna.tsinghua.edu.cn/numpy
pip install -i https://pypi.tuna.tsinghua.edu.cn/scipy
pip install -i https://pypi.tuna.tsinghua.edu.cn/matplotlib1.数据集准备:
为了更好实验,采用sklearn自带的鸢尾花数据集
from sklearn.datasets import load_iris #导入鸢尾花数据集
from sklearn import tree #导入决策树模块
iris = load_iris() #加载数据集
print(iris.DESCR) #显示数据集信息2.训练模型:
clf = tree.DecisionTreeClassifier()
#clf = tree.DecisionTreeClassifier(max_depth=2)#设置最深的树的层数
clf.fit(iris.data, iris.target)#训练决策树class sklearn.tree.DecisionTreeClassifier(*, criterion='gini', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, class_weight=None, ccp_alpha=0.0)[source]
(附上官方文档参数:sklearn.tree.DecisionTreeClassifier — scikit-learn 1.1.3 documentation)
3.预测和绘制决策树:
clf.predict(iris.data)#预测结果
tree.export_graphviz(clf, out_file='tree.dot')#画出决策树4.输出决策树:
import os
os.system('dot -T png tree.dot -o tree.png')
from IPython.display import Image
Image('tree.png')
完整代码:
from sklearn.datasets import load_iris #鸢尾花数据集
from sklearn import tree #决策树模块
import os
iris = load_iris() #加载数据集
print(iris.DESCR) #显示数据集信息
clf = tree.DecisionTreeClassifier()
clf.fit(iris.data, iris.target) #训练决策树
clf.predict(iris.data) #预测结果
tree.export_graphviz(clf, out_file='tree.dot') #画出决策树
os.system('dot -T png tree.dot -o tree.png')
from IPython.display import Image
Image('tree.png')
5.运行结果:
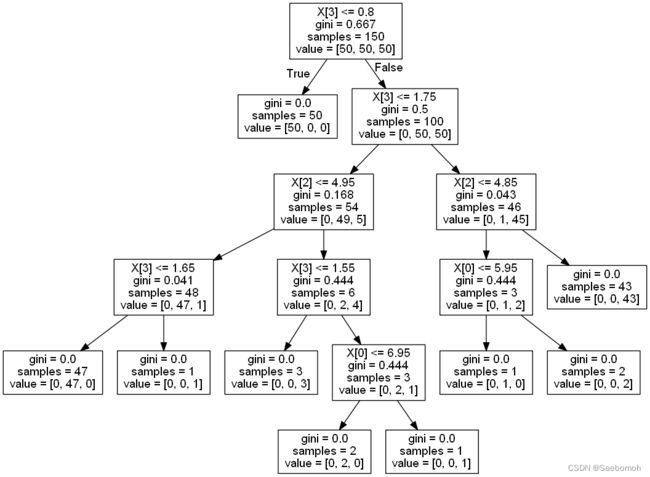
6.总结:
决策树算法优点:
简单直观,生成的决策树很直观。基本不需要预处理,不需要提前归一化,处理缺失值。使用决策树预测的代价是。m为样本数。既可以处理离散值也可以处理连续值。很多算法只是专注于离散值或者连续值。可以处理多维度输出的分类问题。相比于神经网络之类的黑盒分类模型,决策树在逻辑上可以得到很好的解释可以交叉验证的剪枝来选择模型,从而提高泛化能力。对于异常点的容错能力好,健壮性高。
决策树算法缺点:
决策树算法非常容易过拟合,导致泛化能力不强。可以通过设置节点最少样本数量和限制决策树深度来改进。决策树会因为样本发生一点点的改动,就会导致树结构的剧烈改变。这个可以通过集成学习之类的方法解决。寻找最优的决策树是一个NP难的问题,一般是通过启发式方法,容易陷入局部最优。可以通过集成学习之类的方法来改善。。如果某些特征的样本比例过大,生成决策树容易偏向于这些特征。这个可以通过调节样本权重来改善。
参考:
成长NLPer Jane,
人工智能爱好者社区 alpha