【机器学习】李宏毅 - 06 卷积神经网络CNN
文章目录
- 引言
- 观察 1:模型通过识别一些“特定模式”来识别物体,而“不是整张图片”
-
- 简化神经网络 1: 设定感受野(Receptive Field)
-
- Receptive Field的一般设置
- 观察 2: 同样的pattern,可能出现在图片的“不同位置”
-
- 简化神经网络 2: 不同的Receptive Field的神经元共享参数(Parameter Sharing),即权值共享
- 卷积层(Convolutional Layer)基本定义
- 多层卷积
- 总结
- 卷积层(Convolutional Layer)的优势
-
- 总结
- 观察 3: 图片降采样(Subsampling)不影响图片的辨析
-
- 简化神经网络:采用池化(Pooling)把图片变小,减小运算量。
- 典型分类网络结构CNN
- 案例:Alpha Go
- CNN的缺陷
引言
卷积神经网络常用于图像分类(Image Classification)中。
图像分类的基本步骤包括:首先把所有图片重新缩放(Rescale)成大小一样的图片;然后把每一个类别表示成一个 One-Hot Vector ;最后将图像的矩阵数据拉直(flatten)变成一个向量,输入到模型中。
显而易见,如果我们仍然使用完全连接网络(Fully Connected Network),那么假设输入的图片是 100 × 100 100\times100 100×100的大小,包含RGB三层数据,那么拉直后的向量长度是 100 × 100 × 3 100\times100\times3 100×100×3,假设我们有1000个神经元(Neuron),那么第一层的权重数目就高达 3 × 1 0 7 3 \times 10^7 3×107个!尽管参数的增加可以增强模型的弹性和能力,但是同样 增加了过拟合(Overfitting)的风险 !
因此我们需要重新考虑使用什么结构的神经网络,来有效减少参数的数目。
观察 1:模型通过识别一些“特定模式”来识别物体,而“不是整张图片”
神经元(Neuron) 不需要把整张图片当作输入,以识别鸟类为例,只需输入“鸟嘴”、“鸟眼”、“鸟足”的相关数据,就可以侦测出是不是符合某些关键的Pattern。
简化神经网络 1: 设定感受野(Receptive Field)
既然每个神经元只需要考察特定范围内的图像信息,那么我们把图像数据展平后输入到神经元中即可。
Receptive Field的多样性
- Receptive Field之间可以重叠;
- 一个Receptive Field可以有多个神经元“守备”;
- Receptive Field大小可以任意;
- Receptive Field可以只考虑RGB中的部分Channel;
- Receptive Field可以是长方形的;
- Receptive Field不一定相连。
Receptive Field的一般设置
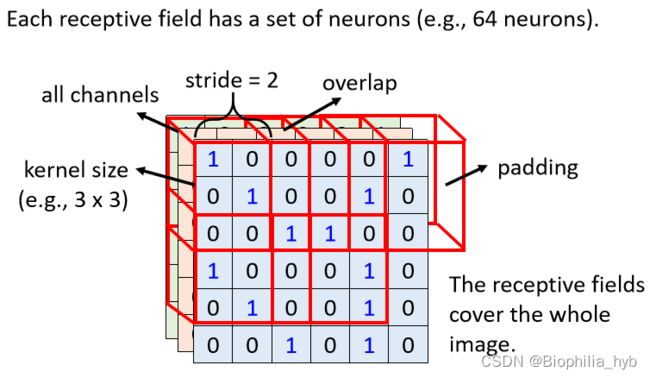
- 一般做影像辨识时会观察全部的RGB的Channel,所以描述Receptive Field时,无需说明Channel的个数,只需说明 高、宽 → \rightarrow → Kernal Size ,一般的kernal size不宜过大,通常设为 3 × 3 3\times 3 3×3。
- 每个Receptive Field会有不止一个神经元守备 → \rightarrow → 输出通道数/卷积核数目
- 不同Receptive Field之间的关系 → \rightarrow → Receptive Field可以 左右或上下平移 ,位移距离叫作stride,这个值属于超参数。一般而言,Receptive Field之间有重叠,是为了避免交界处的pattern被忽略。
- Receptive Field超出的部分需要被padding补值,可以补零、补平均值或是边缘值。
观察 2: 同样的pattern,可能出现在图片的“不同位置”
例如两张鸟类的图片,当我们观察它们的鸟嘴时,会发现不同图片中的鸟嘴位置不一样,但是此时侦测鸟嘴的神经元做的工作是类似的,如果我们让每一个神经元都具备侦测鸟嘴的功能,就会使参数更多,如何高效地处理这个问题呢?答案是: 共享参数 !
简化神经网络 2: 不同的Receptive Field的神经元共享参数(Parameter Sharing),即权值共享
方法:使两个神经元守备的Receptive Field不一样,但是参数一模一样。
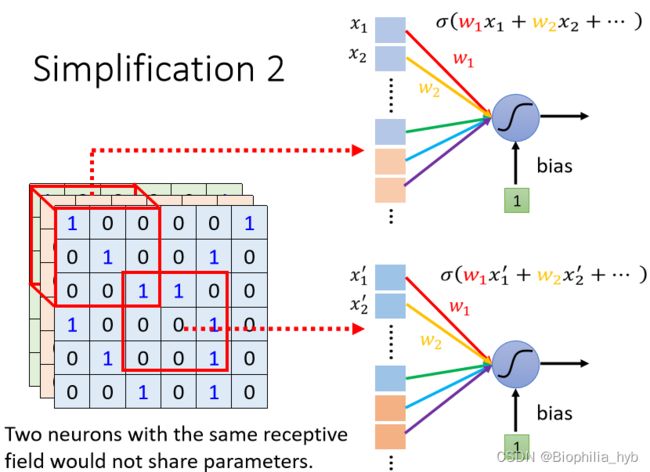
参数共享的设定:对于每个Receptive Field,都使用一组相同的神经元进行守备,这一组神经元被称作 filter ,对不同Receptive Field使用的filter参数相同。

卷积层(Convolutional Layer)基本定义
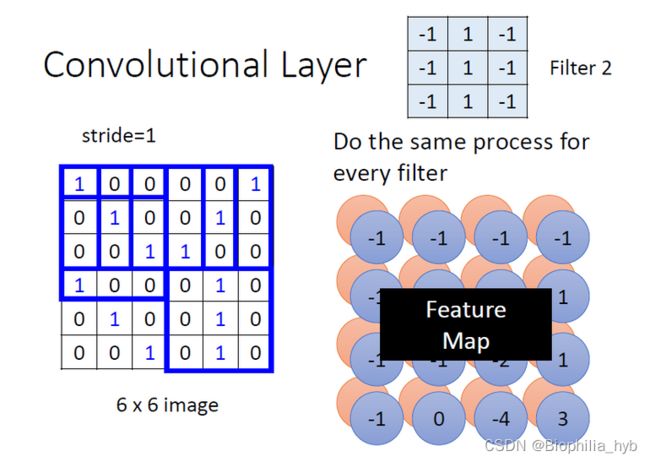
卷积层中有多个filter,可以抓取图片中的某一种特征,filter的参数就是神经元中的权重(weight)。不同的filter扫过一张图片,会和图片对应位置的数值进行内积计算,得到一个数值,遍历一遍后会产生内积后的“新图片”。每一个filter产生新图片的过程,也是产生图片的新channel的过程,最后形成了feature map。
多层卷积
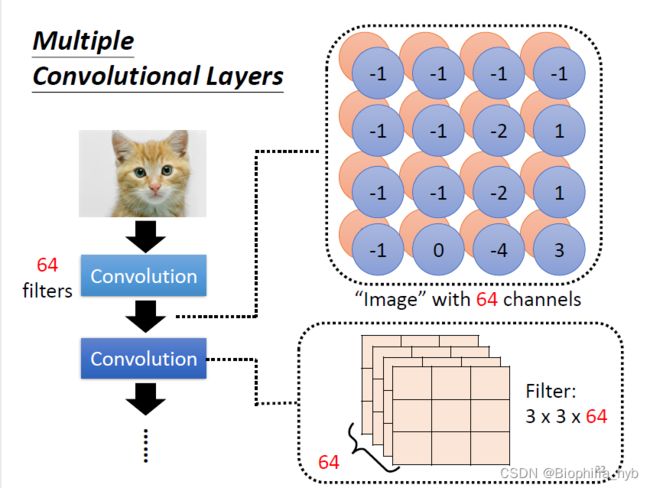
假设我们有64个filter,处理RGB图像,那么第一层卷积的结果,产生了一张 3 × 3 × 64 3\times3\times64 3×3×64的feature map,当我们继续下一层卷积时,需要对新产生的64个channel都进行处理。
多层卷积的功能在于,让 小卷积核看到大pattern。
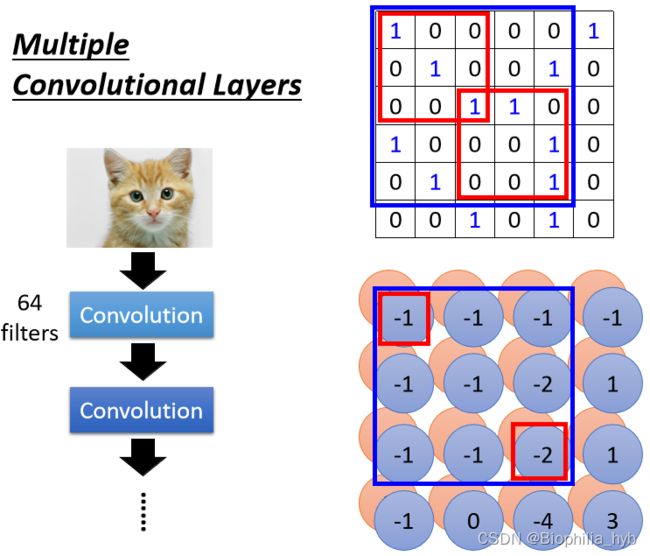
当我们在第二层卷积中观察 3 × 3 3\times3 3×3的范围时,会发现包含了原图中 5 × 5 5\times5 5×5范围内的pattern。因此当卷积层越来越深,即使只用了 3 × 3 3\times3 3×3的filter,看到的pattern也会变多。
总结
从神经元角度(Neuron)和滤波器角度(Filter)理解卷积:
不用看整体图片
- 神经元角度:只要考虑Receptive Field
- 滤波器角度:使用滤波器来侦测pattern
处理图片不同位置的相同pattern
- 神经元角度:守备不同Receptive Field的神经元可以共用参数
- 滤波器角度:使用滤波器“扫过”整张图片
卷积层(Convolutional Layer)的优势
卷积层是受限的“弹性变小”的完全连接神经网络(简称FC)
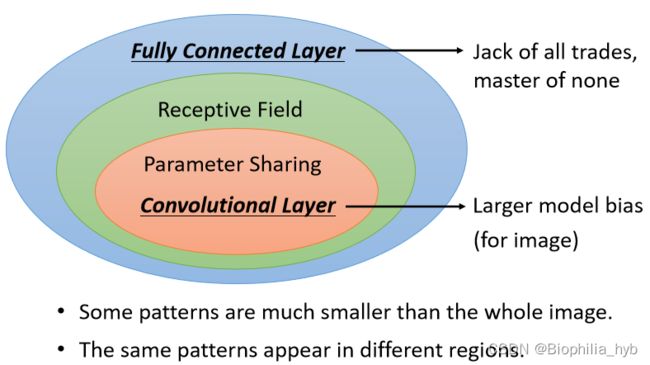
- FC可以通过学习,决定要看到的图片的范围,加上Receptive Field这一概念后,就只能看某一个范围。
- FC可以自由决定守备不同Receptive Field的各个神经元参数,加上参数共享的概念后,守备不同Receptive Field的同一个滤波器(Filter)参数相同。
总结
- 一般而言,模型偏差(Bias)小,模型的灵活性(Flexibility)很高的时候,模型比较容易过拟合(Overfitting),FC layer可以做各种各样的变化,但是可能无法在特定的任务上做好。
- 卷积神经网络(CNN)的偏差(Bias)比较大,但是它是专为影像设计的网络,所以针对影像识别分类可以表现优异。
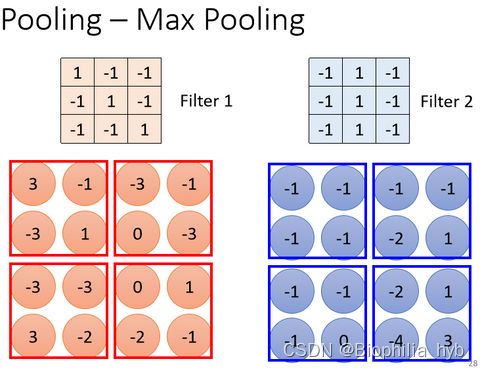
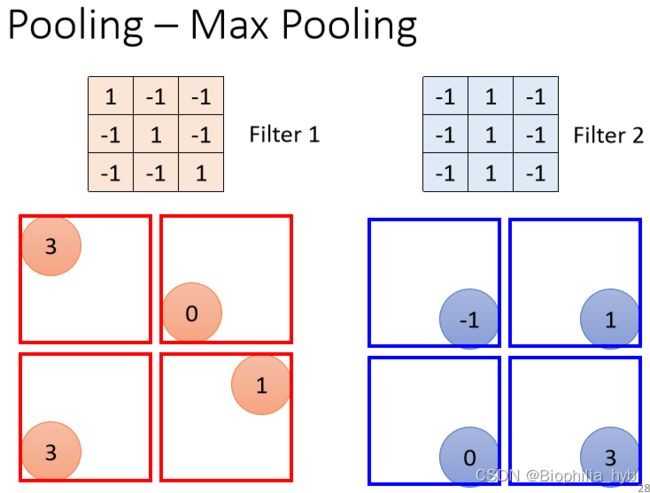
观察 3: 图片降采样(Subsampling)不影响图片的辨析
简化神经网络:采用池化(Pooling)把图片变小,减小运算量。
Pooling本身没有参数,它不是一个网络层,也没有需要学习的参数。作用类似于一个激活函数,是一个运算器(Operator)。
功能可以分为 Max Pooling 、 Avg Pooling ……
应用的范围大小是可以调整的。
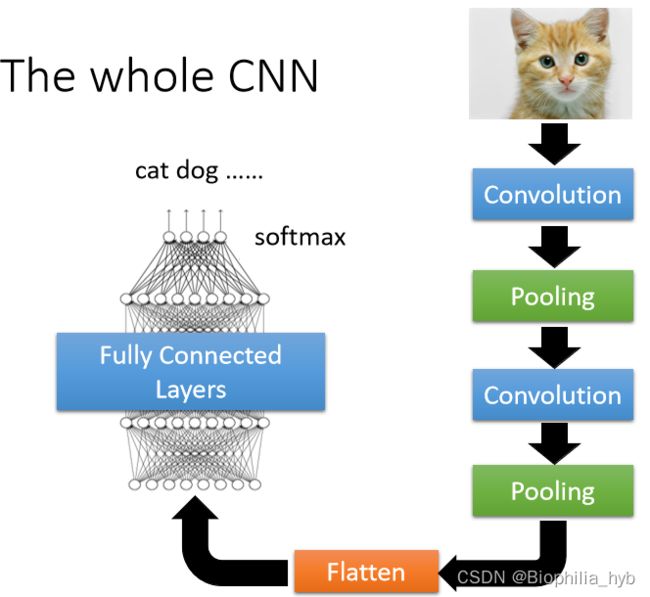
典型分类网络结构CNN
卷积(Convolution)-池化(Pooling)-卷积-池化(循环)-拉直(Flatten)- 完全连接网络(Fully Connected) - softmax
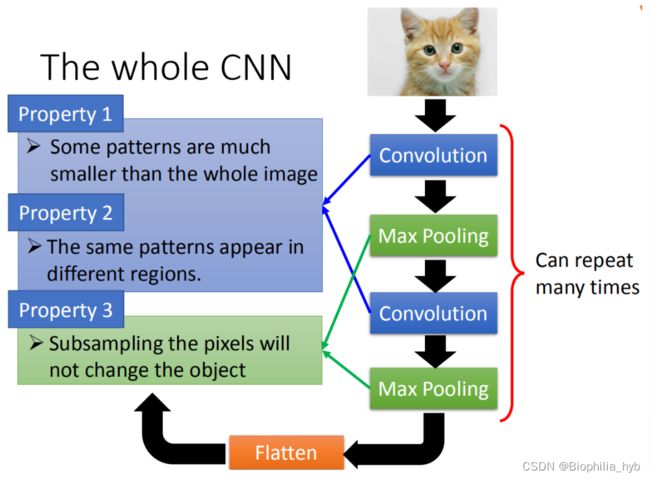
一般来说,卷积和池化交替使用就足够了,针对具体问题(如AlphaGo棋盘问题)池化是不必要的。而且如果在运算资源充足的情况下,池化可以不做,因为它会降低性能。
案例:Alpha Go
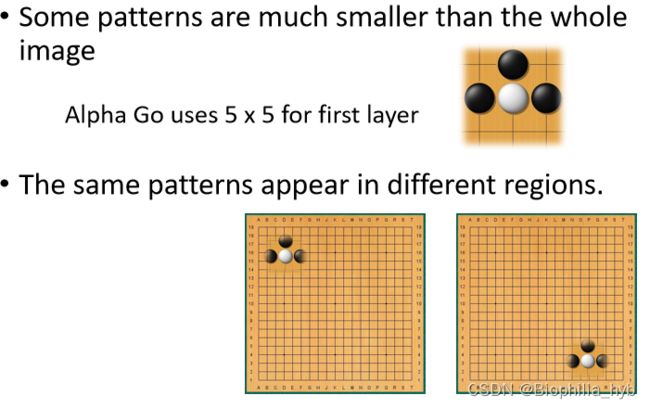
背景:把棋盘看成 19 × 19 19\times19 19×19的图片,用48个channels来描述。
方法:完全连接网络可以被使用在这个问题上,而CNN可以表现更加出色。
与图像辨识的共同点
-
一些pattern比整个棋盘图像小得多
-
同一个pattern会出现在棋盘的各个区域
与图像辨识的不同点 -
没有Pooling
CNN的缺陷
空间变换:没有尺度缩放不变性(Scaling invariant)和旋转不变性(Rotation invariant)
改善方法:数据增强,空间网络变换