OpenCV-python:SVM(支持向量机)OCR手写识别
1.SVM理解
SVM按照百度百科的解释,他属于一种监督分类的方法,对数据进行二元分类,分类的标准就是决策边界。
看下面的图片就很容易能够理解。如果说要给红点和蓝点分类的话,以绿线作为分界线,那么找到一个最合适的绿线就是问题的关键。下面图的右边是找到的结果,它刚好在两边点的中间。这个时候,绿线就叫做最优超平面(决策边界),它和两边最近的点的距离叫做最大距离叫做边距。

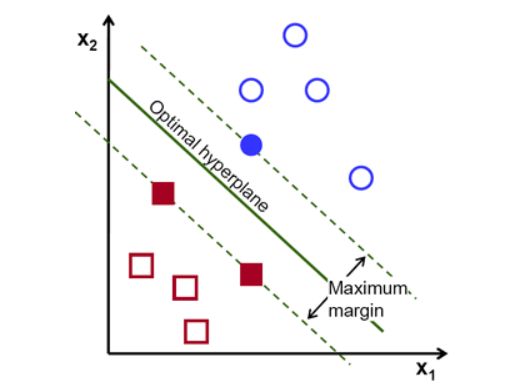
上面两张图的分类结果很明确,他们很明显可以用一条直线分开,这种叫做线形可分数据,但是现实生活中的点并不一定是刚好摆在一条线两边的。也有的会很乱,例如下面这种,它被称为非线形可分数据,下面分别进行讨论。

1.1线形可分数据
线形可分数据是SVM其他分类方法的基础,因为非线性可分数据也要转化为线形可分数据进行分类。方法如下:
还是拿下面这个图片作为举例:
①为了减轻工作量,我们不需要选择全部的点参与运算,在这个例子种,我们只选取实心点,也就是下图中的一个蓝色圆形和两个红色方形。
②我们把选好的蓝色圆形和两个红色方形称作支持向量。
③我们把选好的蓝色圆形和两个红色方形所在的绿色虚线称为支持平面。
④我们分别给红色和蓝色找一个绿色虚线,并且需要保证这两天虚线中间的距离尽可能大,如果有部分点偏离了直线划分的范围,我们要根据数据的整体情况决定是改变直线位置还是放弃一小部分点,保证两虚线距离足够大,被放弃的点可以理解为偏差。(本身有个公式,但是我确实没怎么理解,就不放了)

1.2非线形可分数据
对于非线形可分数据,例如一组数据是[-2,2],另一组是[-1,1],他们都是在X轴上面的点,按照但缺不能用X轴上的一个点把他们区分开来,但是如果我们把他们都用下(x,x^2)函数变化一下,前面的变成[(-2,4),(2,4)],后面的变成[(-1,1),(1,1)],这组新点却是很容易能被一个二维直线分开的。
该方法可以类比到高维数据,因此低维非线性可分数据在转化为高维数据后,是有可能被线形可分的。
具体计算会依赖一个理论:高维数据的特征可以从低维数据的点积得到,但是这里面的计算方法太复杂了,好在Open-CV里面的函数已经解决了这些问题,这里只是简单的从定性的角度理解了一下。
2.SVN手写字体识别代码
2.1数据准备
使用SVM训练图片样本,最关键的,首先要有训练样本,之后还要有检验样本。他们又分别包含了图片集和对应的结果,下面的示意更便于理解
训练样本:(图片,对应数字)
检验样本:(图片,对应数字)
下面代码使用的数据与上一个文章的数据一样,想要试练的可以直接去下载(也可以右键另存下面的图片)。Open-CV K近邻算法(k-Nearest Neighbour)OCR手写识别_Matrix_CS的博客-CSDN博客

2.2代码解析
首先介绍两个函数:①手写体矫正,②样本HOG生成函数(类似于直方图)
函数一代码如下,输入是一个图片,输出也是图片,但是它的形状被矫正了,例如![]() =>
=>![]()
## 这个函数用来给手写体做一个变形,变成正体
def deskew(img):
m = cv.moments(img)
if abs(m['mu02']) < 1e-2:
return img.copy()
skew = m['mu11']/m['mu02']
M = np.float32([[1, skew, -0.5*SZ*skew], [0, 1, 0]])
img = cv.warpAffine(img,M,(SZ, SZ),flags=affine_flags)
return img函数二代码如下,它生成了图片的HOG图,用来作为SVM的输入。
## 这个函数把图片分成四部分,分别成生成方向直方图,然后返回,用来作为SVM的输入
#这和K近邻算法是不一样的
def hog(img):
gx = cv.Sobel(img, cv.CV_32F, 1, 0)
gy = cv.Sobel(img, cv.CV_32F, 0, 1)
mag, ang = cv.cartToPolar(gx, gy)
bins = np.int32(bin_n*ang/(2*np.pi)) # quantizing binvalues in (0...16)
bin_cells = bins[:10,:10], bins[10:,:10], bins[:10,10:], bins[10:,10:]
mag_cells = mag[:10,:10], mag[10:,:10], mag[:10,10:], mag[10:,10:]
hists = [np.bincount(b.ravel(), m.ravel(), bin_n) for b, m in zip(bin_cells, mag_cells)]
hist = np.hstack(hists) # hist is a 64 bit vector
return hist下面进行完成的代码解析:
①读取数据:
#样本读取
img = cv.imread(cv.samples.findFile('digits.png'),0)
if img is None:
raise Exception("we need the digits.png image from samples/data here !")②把上面那个密密麻麻的图片分割成单独数字的小块,之后分成左右两部分,左边作为训练样本,右边作为检验样本
#把整张图片分成单独的图片,原数据是50行,100列
cells = [np.hsplit(row,100) for row in np.vsplit(img,50)]
# 左边为训练样本,右边为检验样本
train_cells = [ i[:50] for i in cells ]
test_cells = [ i[50:] for i in cells]③对训练样本进行一些处理,生成训练输入数据
#使用deskew函数,把倾斜的字体矫正
deskewed = [list(map(deskew,row)) for row in train_cells]
#生成图像的HOG图
hogdata = [list(map(hog,row)) for row in deskewed]
#序列化,变成输入数据
trainData = np.float32(hogdata).reshape(-1,64)
#把与图片对应的数字生成出来
responses = np.repeat(np.arange(10),250)[:,np.newaxis]④初始化SVM,设置训练参数
#实例化对象
svm = cv.ml.SVM_create()
#设置核函数
svm.setKernel(cv.ml.SVM_LINEAR)
#设置训练类型
svm.setType(cv.ml.SVM_C_SVC)
svm.setC(2.67)
svm.setGamma(5.383)⑤输入样本,开始训练
#输入样本,进行训练
svm.train(trainData, cv.ml.ROW_SAMPLE, responses)
#存储训练结果
svm.save('svm_data.dat')到这里,训练工作就结束了,下面开始检验训练精度,这里用到了svm.predict()函数
#对检验样本的手写体进行矫正
deskewed = [list(map(deskew,row)) for row in test_cells]
#生成检验样本的HOG图
hogdata = [list(map(hog,row)) for row in deskewed]
#检验样本序列化
testData = np.float32(hogdata).reshape(-1,bin_n*4)
#生成识别结果
result = svm.predict(testData)[1]下面计算匹配度:
mask = result==responses
correct = np.count_nonzero(mask)
print(correct*100.0/result.size)最终运行可以得到下面的结果,精度为93.8:

完整代码如下:
import cv2 as cv
import numpy as np
SZ=20
bin_n = 16 # Number of bins
affine_flags = cv.WARP_INVERSE_MAP|cv.INTER_LINEAR
## 这个函数用来给手写体做一个变形,变成正体
def deskew(img):
m = cv.moments(img)
if abs(m['mu02']) < 1e-2:
return img.copy()
skew = m['mu11']/m['mu02']
M = np.float32([[1, skew, -0.5*SZ*skew], [0, 1, 0]])
img = cv.warpAffine(img,M,(SZ, SZ),flags=affine_flags)
return img
## [deskew]
## 这个函数把图片分成四部分,分别成生成方向直方图,然后返回,用来作为SVM的输入,这点可K近邻算法是不一样的
def hog(img):
gx = cv.Sobel(img, cv.CV_32F, 1, 0)
gy = cv.Sobel(img, cv.CV_32F, 0, 1)
mag, ang = cv.cartToPolar(gx, gy)
bins = np.int32(bin_n*ang/(2*np.pi)) # quantizing binvalues in (0...16)
bin_cells = bins[:10,:10], bins[10:,:10], bins[:10,10:], bins[10:,10:]
mag_cells = mag[:10,:10], mag[10:,:10], mag[:10,10:], mag[10:,10:]
hists = [np.bincount(b.ravel(), m.ravel(), bin_n) for b, m in zip(bin_cells, mag_cells)]
hist = np.hstack(hists) # hist is a 64 bit vector
return hist
## [hog]
#样本读取
img = cv.imread(cv.samples.findFile('digits.png'),0)
if img is None:
raise Exception("we need the digits.png image from samples/data here !")
#把整张图片分成单独的图片,原数据是50行,100列
cells = [np.hsplit(row,100) for row in np.vsplit(img,50)]
# First half is trainData, remaining is testData
train_cells = [ i[:50] for i in cells ]
test_cells = [ i[50:] for i in cells]
###### Now training ########################
#使用deskew函数,把倾斜的字体矫正
deskewed = [list(map(deskew,row)) for row in train_cells]
#生成图像的HOG图
hogdata = [list(map(hog,row)) for row in deskewed]
#序列化,变成输入数据
trainData = np.float32(hogdata).reshape(-1,64)
#把与图片对应的数字生成出来
responses = np.repeat(np.arange(10),250)[:,np.newaxis]
#实例化对象
svm = cv.ml.SVM_create()
#设置核函数
svm.setKernel(cv.ml.SVM_LINEAR)
#设置训练类型
svm.setType(cv.ml.SVM_C_SVC)
svm.setC(2.67)
svm.setGamma(5.383)
#输入样本,进行训练
svm.train(trainData, cv.ml.ROW_SAMPLE, responses)
#存储训练结果
svm.save('svm_data.dat')
###### Now testing ########################
#对检验样本的手写体进行矫正
deskewed = [list(map(deskew,row)) for row in test_cells]
#生成检验样本的HOG图
hogdata = [list(map(hog,row)) for row in deskewed]
#检验样本序列化
testData = np.float32(hogdata).reshape(-1,bin_n*4)
#生成识别结果
result = svm.predict(testData)[1]
####### Check Accuracy ########################
mask = result==responses
correct = np.count_nonzero(mask)
print(correct*100.0/result.size)